







神经网络(ANN):
人造神经元是整个网络的最小单位,他们构成神经网络的输入层、隐藏层、输出层。不同层的神经元按照不同的权重设置连接。输入层只起到传递数据的作用,他们将数据按配置的权重,传导至隐藏层相应的神经元。
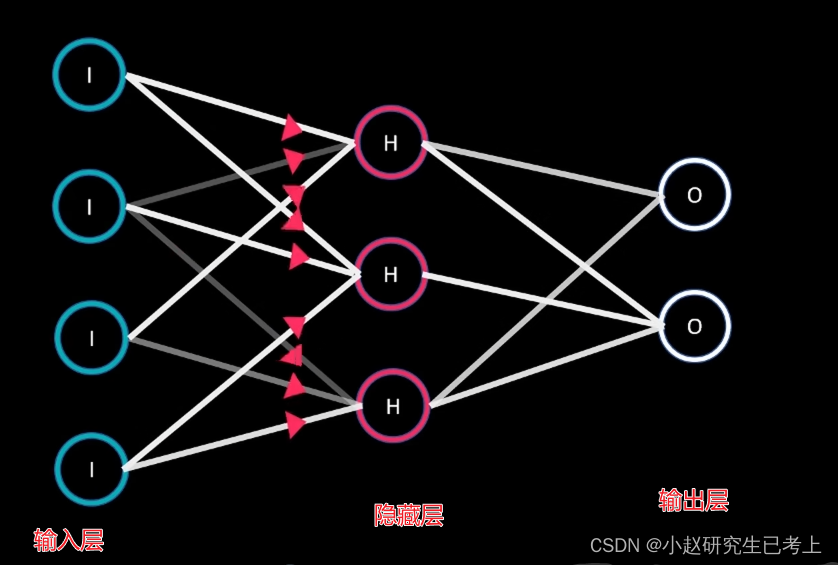
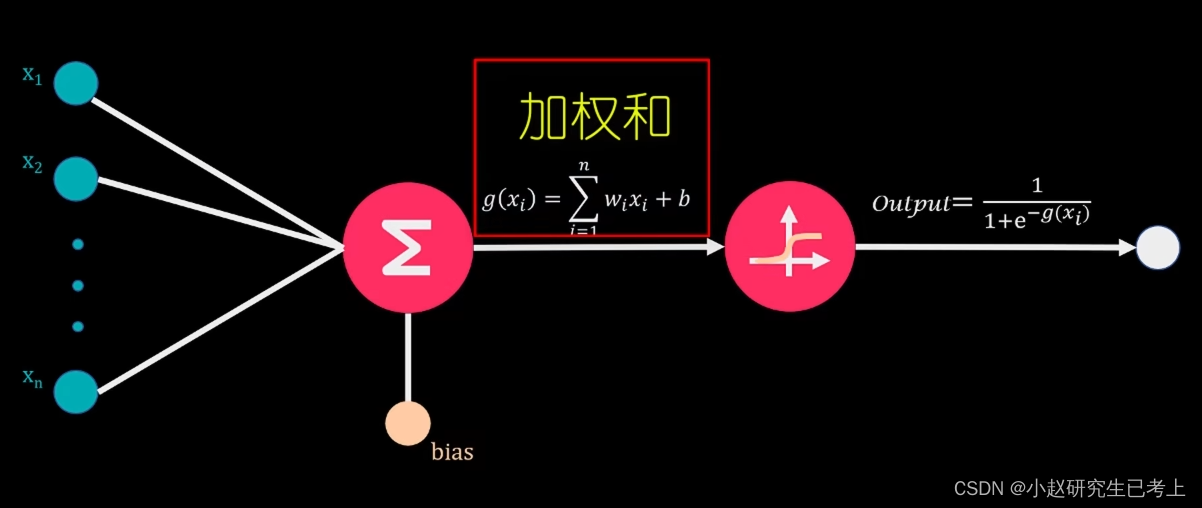
那么,隐藏层的那些神经元会被激活呢?这就涉及到另一个知识了——激活函数(Activationfunction)。我们单独拿出一个神经元出来介绍,其信号强度由上层传输的加权和所决定。激活函数会将该输入信号转化为该神经元的输出值。
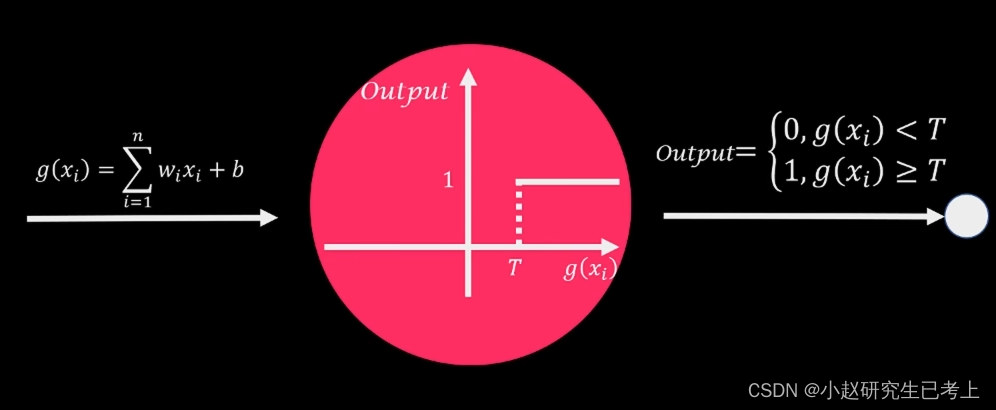
假如激活函数为简单的分段函数,当输入信号小于预设临界值时输出0,大于等于时输出1,该神经元被激活。但是这种函数面临着一个问题,当输入信号逐渐到达临界值时,输出值会出现从0直接变为1的情况。
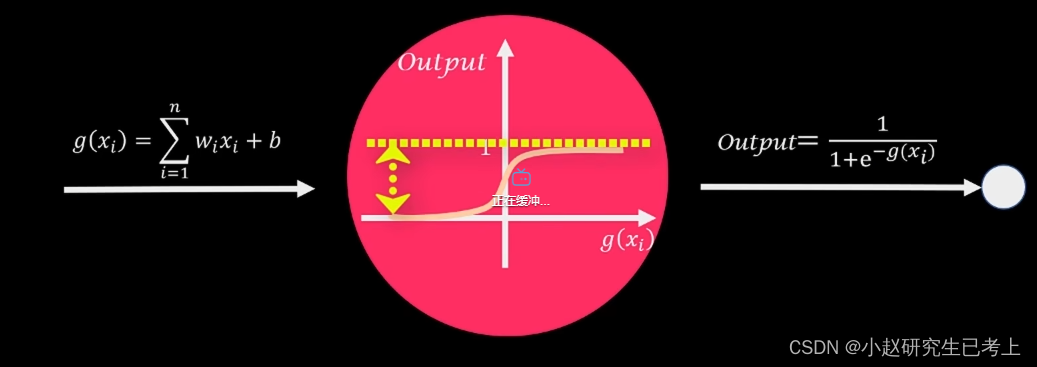
为了平滑输出值,往往会选择不同的激活函数。例如sigmoid,其输出值位于[0-1]的区间内。
隐藏层的神经元输出值会根据相应权重流入输出层。输出层神经元根据激活函数输出最终值。
逆向参数调整方法

通过不断调整W1,W2,让Y、E集合的误差平方和最小。调整的方法即为逆向参数调整法(backpropagation)。调整过程中设计两个方法分别是梯度下降法(Gradient Descent)和链式法则(Chain Rule)。
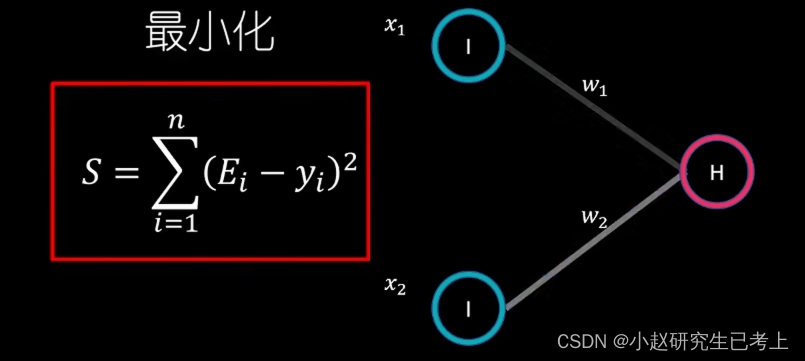
梯度下降法
低度下降法的核心在于,为了求得误差平方和的极小值,我们需要将w权重从初始值逐步移动到误差平方和函数S(W)的导数为0处。每次移动的幅度由S(W)的导数和学习系数的常数值eta值所决定。
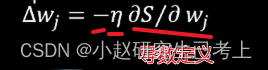
当厨师随机W值较大时,其最终输出误差也较大。根据导数进行计算,初始调整步幅也会较大。在步幅函数中eta之前有一个负号,这是由于步幅调整方向和导数值相反。导数为负时步幅为正,导数为正时步幅为负。随着调整,误差函数逐步趋近于极值位置导数绝对值逐渐趋近于0,步幅不断缩小。所以这里eta值学习系数的设置也需要仔细考虑。太小了,学习速度太慢,耗时太长,相反eta值如果设置太大,则有可能跳过极值点(有多个极值点还有可能会漏掉最优解),在实际应用中我们往往会设置一些循环退出条件。
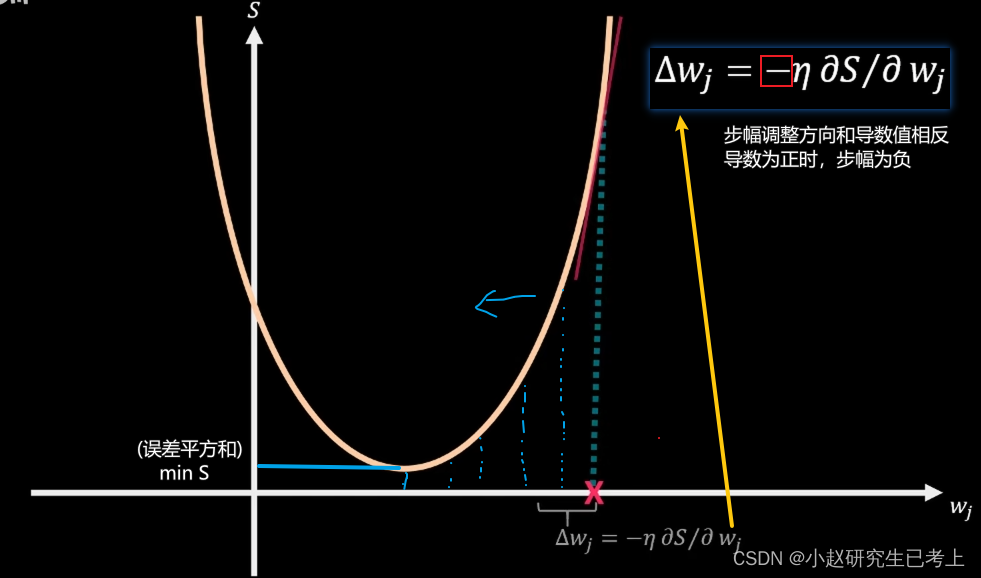
横坐标为w(权重),纵坐标S为误差平方和。
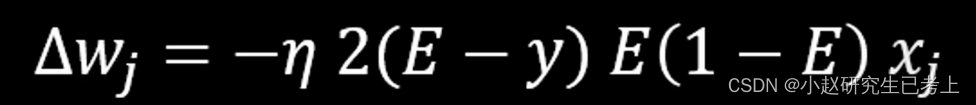
在对S(W)的求导过程中需要使用链式法则(复合函数求导)。

激活函数的必要性
为什么要使用激活函数呢?来看下面的小例子。
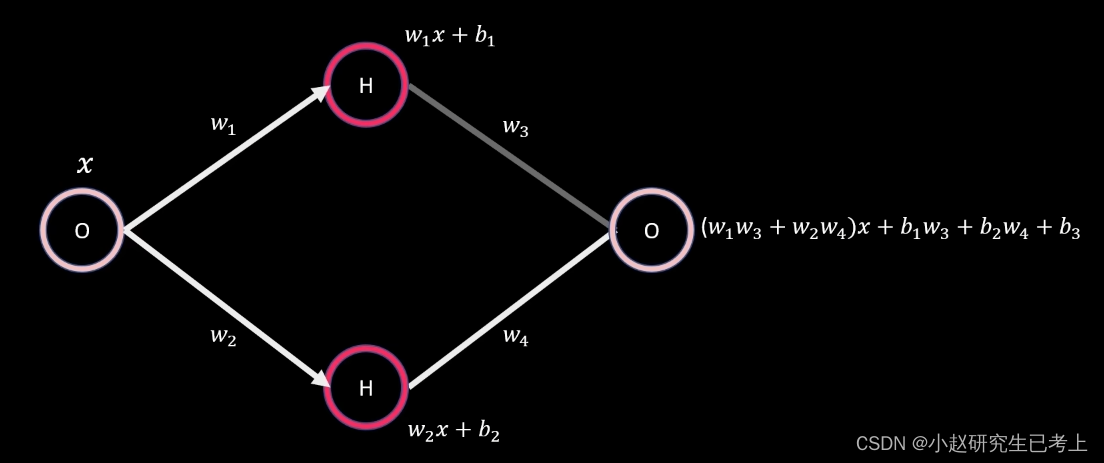
我们来看这个网络,在没有激活函数的情况下,无论我们怎么调整权重和偏差,其输出值仍为线性。加入更多隐藏层本质也是一样的。
在真实世界中,大多数系统是非线性的,如果要模拟复杂的系统,则必须借助非线性的激活函数了。
通过使用sigmoid函数,我们便可以来模拟一些非线性函数了。
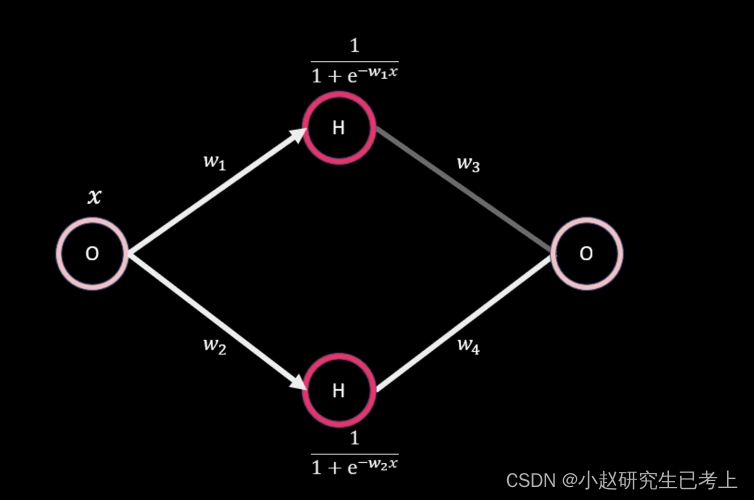
根据通用近似定理,神经网络中至少需要一层隐藏层和足够的神经元,利用非线性的激活函数,便可以模拟任何复杂的连续函数。
激活函数的选择
sigmoid函数

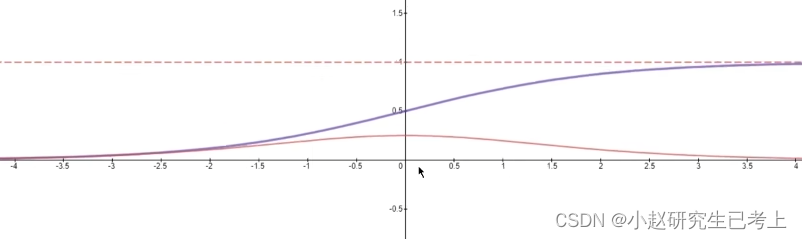
特点:
1.其输出值落于[0-1]的连续区间
2.输入值从横坐标左侧移动到右侧的过程中。其输出值呈现从平缓到加速再到平缓的特点。
3 sigmoid函数的导数值落于[0-0.25]的连续区间。
在神经网络模型中sigmoid函数其实有很大的局限性。
在逆向参数调整back propagation过程中。使用链式法则chain。可以推导出下面的公式。并对深度神经网络模型的权重调整幅度进行计算。

根据我们之前谈到的sigma函数特征的第三点,多个小于0.25的值相乘后,会严重影响最终权重调整幅度。这也就会导致在神经网络模型的训练中,第一层的初始权重之后,很难通过back propagation再产生变化,这个问题被称为梯度消失。另外,考虑到sigmoid函数在进行指数。计算时需要消耗较多的算力资源,因此在平时的神经网络模型中,它通常不被使用。
sigmoid函数适用于隐藏层较少的神经网络模型。
Tanh函数

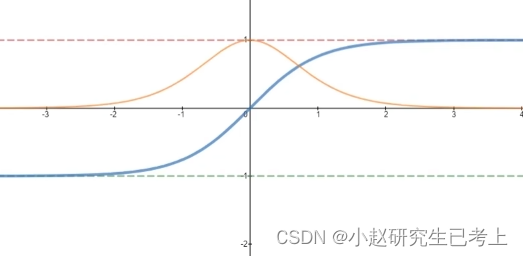
我们对比一下两者特征,其值落于-1到1的区间内。另外,其导数值落于0到1区间。大于sigmoid0-0.25的导数区间。因此可以相对缓解梯度消失的问题。在平时激活函数的选择上tanh是优于sigmoid函数的。
ReLU
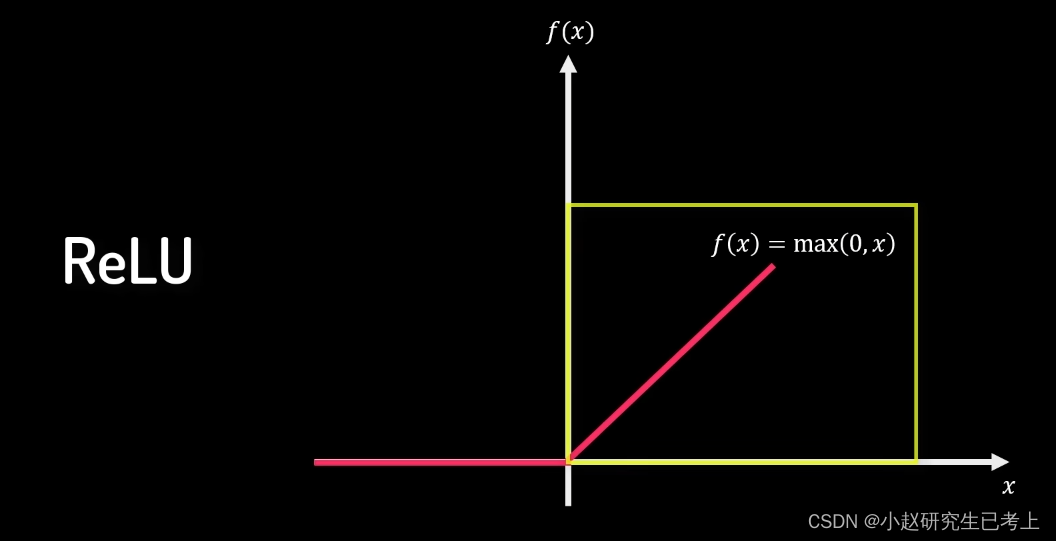
首先它是一个非线性函数。其在>0时展示的线性特征能够很好的解决梯度消失的问题。另外,相较前两者,它也能够带来更高效的计算。最后,根据通用近似定理,其整体的非线性又能够在神经网络中拟合任何复杂的连续函数。
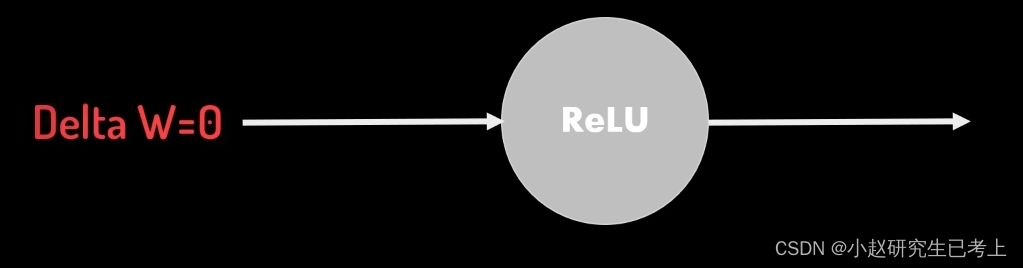
不过,当输入值为负数时。其输出值和导数均为零,这意味着该神经元处于熄灭状态且在逆向参数调整过程中不产生梯度调整值。
Leaky ReLU
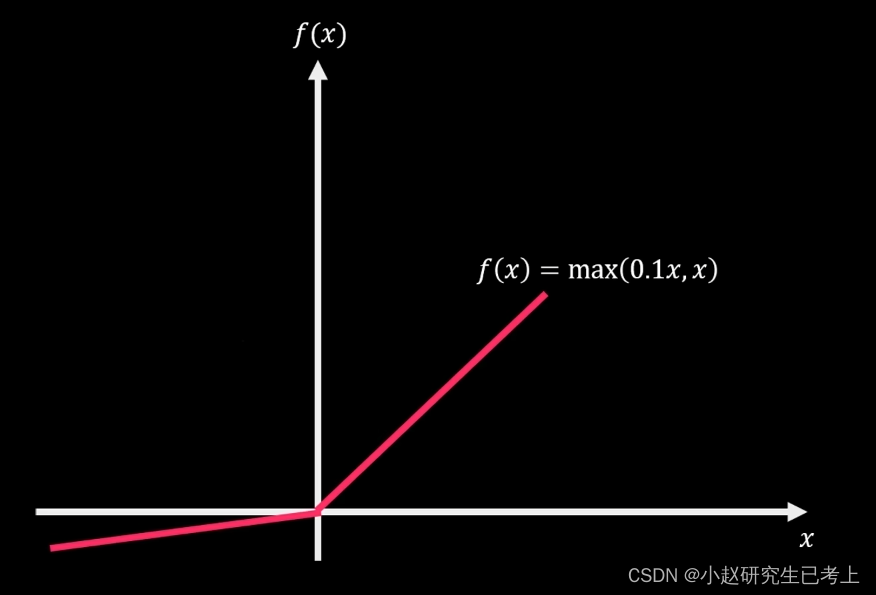
在负数部分通过添加了一个及哦啊小斜率的线性部分,使负数区域内也能产生梯度调整值
在神经网络模型中激活函数的选择如下

但是Tanh和Sigmoid函数在RNN中还是有一席之地的。
输出层激活函数的选择
隐藏层的数据通过输出层的激活函数转换成业务要求的表达形式。因此,输出层激活函数的选择是以业务要求为导向的。
二分类问题
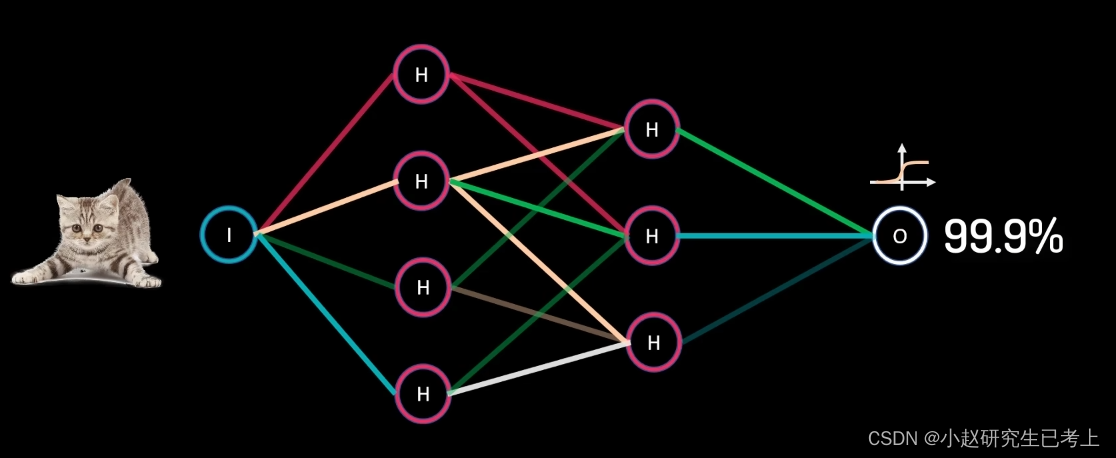
如果我们要判断图中的动物是否是猫是猫的概率,我么可以用Sigmoid函数返回是猫的概率作为最终输出。
Sigmoid函数被用于二分类问题,因为它可以将任何实数转换到0到1之间的概率,非常适合用于预测结果的概率计算。
多分类问题
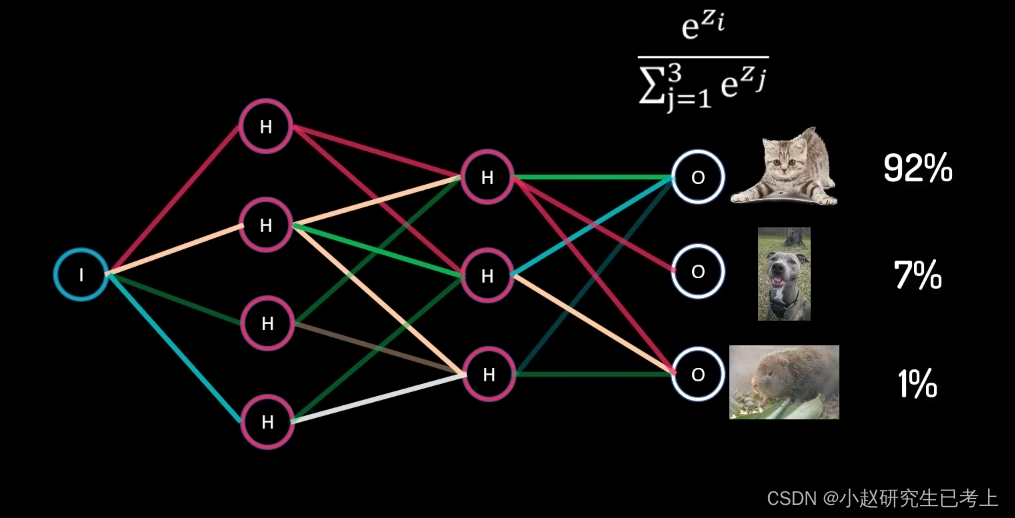
在该类问题中样本只能属于一种类别。当我们希望返回图片中的动物分别是猫、狗和竹鼠的概率时,我们可以使用Softmax函数返回属于每个类别的概率,其概率总和为1.
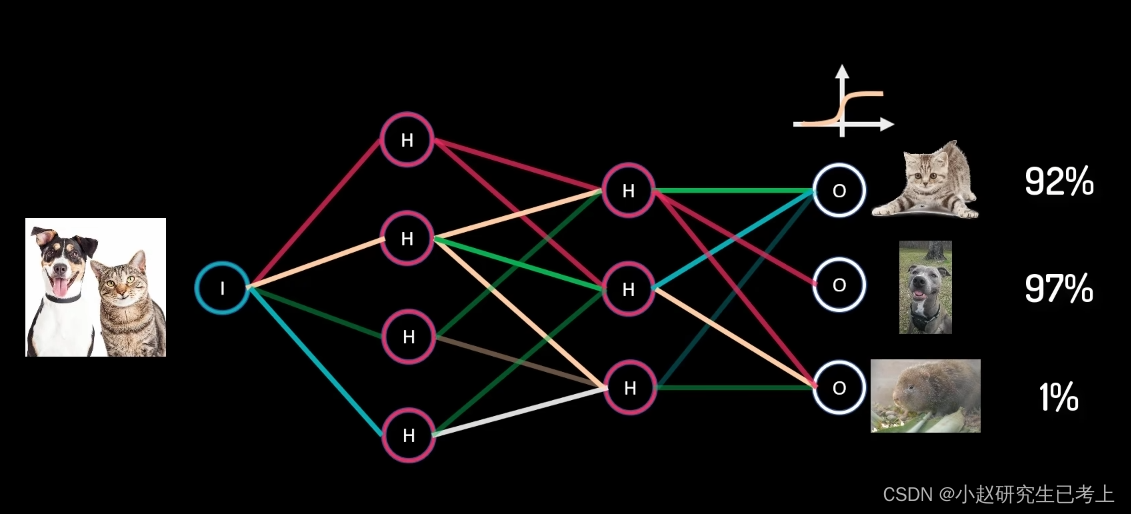
多标签问题
某个样本可以同时属于多个类别。我们可以计算图片中分别出现猫、狗、竹鼠的概率。这里也可以使用sigmoid函数对每个类别单独进行计算。
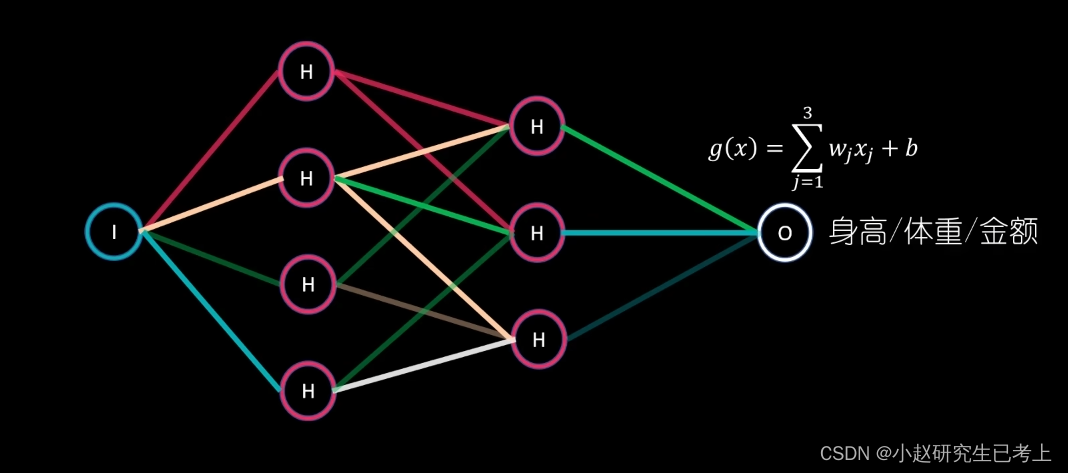
线性回归问题
当我们面临的问题是要预测绝对的数值时,比如身高体重等。那么最后就可以直接使用线性函数作为激活函数
全连接神经网络MINST手写体识别:
*MINST数据集中的图像被编码为 Numpy 数组,而标签是一个数字数组,范围从 0 到 9
加载MINST数据集
#载入Minst数据集
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images.shape#训练集形状形状
test_images.shape#测试集形状
train_images是一个由6000个矩阵组成的数组,每个矩阵由28*28个整数组成。每个这样的矩阵都是一张灰度图像,元素的取值范围为0~255.(UInt8 [0 : 255])。
接下来我们要将训练数据 train_images 和 train_labels 提供给我们的神经网络。然后网络将图像与标签关联起来。最后,我们将要求网络对 test_images 产生预测,并验证这些预测是否与test_labels 中的标签相匹配。
网络架构
from keras import models
from keras import layers
network = models.Sequential()#创建一个顺序模型,这意味着网络中的每一层都是顺序堆叠的,没有分支。
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
#添加一个全连接层(Dense),该层有512个神经元。使用ReLU作为激活函数。input_shape=(28 * 28,)指定输入数据的形状。
network.add(layers.Dense(10, activation='softmax'))
#再添加一个全连接层,这次有10个神经元,对应于MNIST数据集中的10个类别(数字0到9)。使用softmax激活函数,这通常用于多类分类问题的输出层,因为它将输出转换为概率分布。我们的网络由两个 Dense 层顺序组成。
第一层有512个神经元。使用ReLU作为激活函数。input_shape=(28 * 28,)指定输入数据的形状。
第二层(也是最后一层)是一个10路的“softmax”层,该层有10个神经元,对应于MNIST数据集中的10个类别(数字0到9)。使用softmax激活函数,这通常用于多类分类问题的输出层,因为它将输出转换为概率分布。
编译步骤
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])优化器(optimizer)是用于在训练过程中调整网络权重以最小化损失函数的算法,基于训练数据和损失函数来更新网络。
损失函数(loss)是衡量模型预测值与实际值之间差异的函数,指导网络如何朝正确的方向前进。
在训练和测试过程中要监控的指标(metrics),在这里,我们只关心准确率,即模型正确预测的样本数占总样本数的比例。
图像数据预处理
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255将训练图像数据集的形状从(60000, 28, 28)改变为(60000, 784)。这样做是为了将每个28x28像素的图像转换为一个长度为784(28 * 28)的向量。
全连接层(Dense层)期望输入是一个固定大小的向量。在Keras中,这意味着每个样本必须是一个一维向量。
如果输入数据的形状是(60000, 28, 28),那么它表示的是一个三维数组,其中每个样本是一个28x28像素的图像。全连接层不能直接处理这种三维输入(CNN可以)。
然后图像数据的类型从默认的整数类型转换为float32类型,并将所有像素值除以255,将像素值从范围[0, 255]归一化到范围[0, 1]。这种归一化有助于神经网络更快地学习和收敛。
对测试集进行同样处理。
from tensorflow.keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)导入了to_categorical函数,它可以将类别标签转换为one-hot编码向量。
to_categorical函数将训练标签数组转换为一个矩阵,其中每一行是一个one-hot编码向量。对于MNIST数据集,它有10个类别(数字0到9),所以转换后的矩阵形状将是(60000, 10)。例如,如果原始标签是数字3,那么对应的one-hot编码向量将是[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]。
这种转换是必要的,因为多分类问题中的神经网络通常期望标签以one-hot编码的形式提供,特别是当使用categorical_crossentropy作为损失函数时。
训练与验证
network.fit(train_images, train_labels, epochs=5, batch_size=128)
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc:', test_acc)

调用fit函数拟合模型,可以看到在测试集上的精度达到98.01%。















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









