







一、实验目的
1. 熟悉正则表达式常用的函数;
2. 掌握正则表达式的匹配方法。
二、实验环境
操作系统:Windows
主要软件:Jupyter notebook
三、实验内容
1. 统计输入的字符串中的英文字母、数字、空格和其他字符出现的次数。
(教材《Python程序设计与算法基础教程》第15章上机实践题:2)
提示:用不同的变量分别代表英文字母、数字、空格出现的次数,用总的字符串长度减去这几类字符的次数,剩下的即为其他字符出现的次数
2. 已知一个蛋白质的uniprot格式文件为ZN558_HUMAN.txt,请编程匹配蛋白质的ID、蛋白质名称、物种名称、所属的KEGG通路,把提取的结果输出到屏幕。
注意:实验数据“ZN558_HUMAN.txt”见QQ群文件。
提示:首先观察ZN558_HUMAN.txt文件,寻找蛋白质的ID、蛋白质名称、物种名称、所属的KEGG通路,这些信息所在的位置;再观察附近哪些字符能唯一确定这些信息的位置;最后写出对应正则表达式。可以使用search函数匹配正则表达式;使用group函数获取正则表达式中小括号所匹配到的内容。
输出结果:
ZN558_HUMAN Zinc finger protein 558 Homo sapiens (Human) hsa:148156
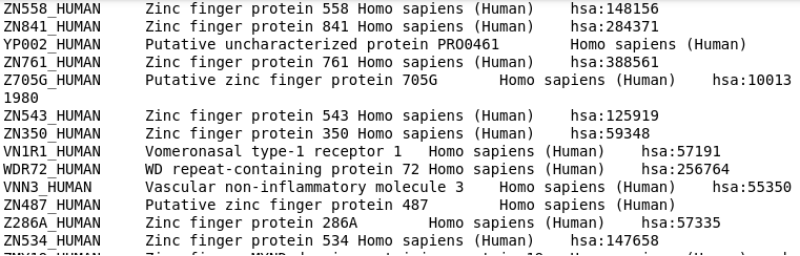
3. (选做) 读取uniprot_test.txt文件,统计这个文件中共有多少个蛋白质,并提取每个蛋白质的ID、蛋白质名称、物种名称、所属的KEGG通路,把提取的结果输出到屏幕。
注意:实验数据“uniprot_test.txt”见QQ群文件。
(输出格式如下图所示)
四、实验报告
1. 使用jupyter notebook文档填写实验报告,导出并提交pdf格式文件。
文件命名规则:”星期几+学号+姓名+实验4.pdf。
2. 记录实验步骤和实验结果
3. 记录实验中遇到的问题,如何解决的。
1
s = input('请输入字符串:\n')
letters,space,digit,others = 0,0,0,0
for char in s:
if char.isalpha():
letters += 1
elif char.isspace():
space += 1
elif char.isdigit():
digit += 1
else:
others += 1
print('字母个数 = %d,空格 = %d,数字 = %d,其他特殊字符 = %d' % (letters, space, digit, others))
2
import re
with open(r'C:\Users\Polo\Desktop\python 高级编程\ZN558_HUMAN.txt') as f:
for line in f:
line1 = re.search('([ID]+ {3})([A-Z0-9]{4,5}[_][A-Z]+)', line)
if line1 is not None:
print(line1.group(2), end='')
line2 = re.search('([R][ecNam: ]{8}[A-Za-z]+=)([A-Za-z0-9- ]+[ ]+[A-Z0-9]*[{A-Za-z0-9:|}]*)', line)
if line2 is not None:
print("\t", line2.group(2), end='')
line3 = re.search('([A-Za-z]+ {3})([A-Za-z]+[ ][A-Za-z]+[ ][(](.*?)?[)])', line)
if line3 is not None:
print("\t", line3.group(2), end='')
line4 = re.search('([KEG]+\S )([hsamu]+.[0-9]+)', line)
if line4 is not None:
print("\t", line4.group(2))
3
import re
num=0
with open(r'C:\Users\Polo\Desktop\python 高级编程\uniprot_test.txt') as f:
for line in f:
line1 = re.search('([ID]+ {3})([A-Z0-9]{4,5}[_][A-Z]+)', line)
if line1 is not None:
num+=1
if num == 1:
print('',"{:<11}".format(line1.group(2)), end='')
else:
print('\n',"{:<11}".format(line1.group(2)), end='')
line2 = re.search('([R][ecNam: ]{8}[A-Za-z]+=)([A-Za-z0-9- ]+[ ]+[A-Z0-9]*[{A-Za-z0-9:|}]*)', line)
if line2 is not None:
print("\t", "{:<62}".format(line2.group(2)), end='')
line3 = re.search('([A-Za-z]+ {3})([A-Za-z]+[ ][A-Za-z]+[ ][(](.*?)?[)])', line)
if line3 is not None:
print("\t","{:<20}".format(line3.group(2)), end='')
line4 = re.search('([KEG]+\S )([hsamu]+.[0-9]+)', line)
if line4 is not None:
print("\t", "{:<13}".format(line4.group(2)),end='')
print('\n总的蛋白质个数:',num)















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









