







文章目录
0. 引言
正则表达式本质上是一门语言,一门专用于匹配字符串的语言。
那么对于正则表达式这个语言工具而言,我们只需要了解其两个方面:
- 怎么读
满足能够看懂别人的正则表达式需求。 - 怎么写
满足能够按照给定需求写出对应正则表达式。
我们以一个例子开始,看看你现在能否读懂这个正则表达式:
^a(0\d{2,19}){9}\1-(?:\d{8})|b[xyt]*(ab)+[^uwv]?xy$|(\$|\\\.)*(?=\sfat)|yng(?!ubx)agi
1. 正则表达式基本知识框架
正则表达式所有概念如下,
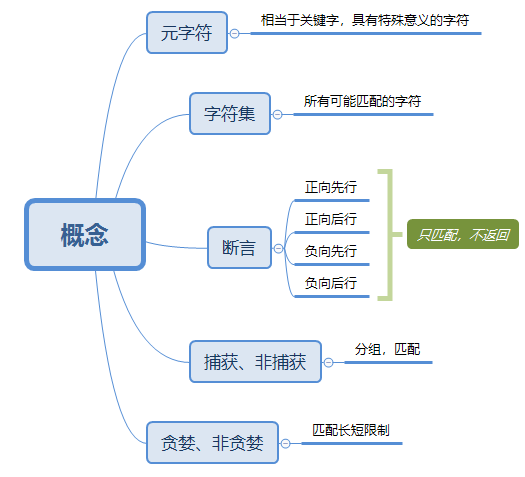
以上概念,可以完成字符串匹配的所有闭环操作。
1.1 元字符
元字符和所有其他语言中的关键字一样,都有其特殊意义和特殊作用。个数不多,必须要记住的。

1.2 字符集
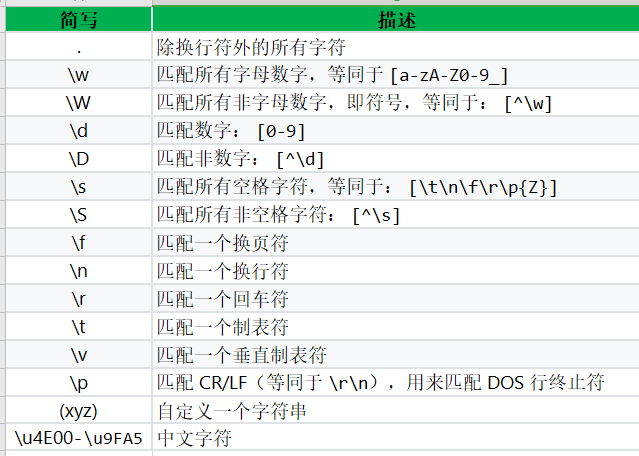
字符集整理了可以匹配的所有字符,在这里你可以找到所有想要匹配的字符。
1.3 断言
正则表达式光有匹配不够,匹配只能找到“符合规则的字符”,并返回。
但是我想找到“符合规则的字符1”的前边或后边的“符合规则的字符2”,返回字符2,那么就需要断言。
用作断言的字符1只做匹配规则并不返回,弥补元字符功能的不足。
举个例子,我只想找到只在“fat”前出现的“the”,如下图:
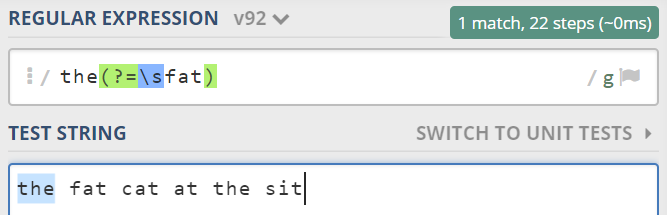
参考在线正则匹配网址regular expressions。
1.3.1 正向先行
(?=pattern)
匹配pattern表示式前边的字符, 即字符2规则写在pattern前边。
例如:匹配pattern前边的the,如下图实现,
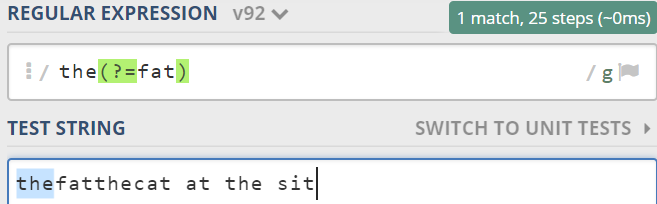
1.3.2 正向后行
(?<=pattern)
匹配pattern表达式后边的字符,即字符2规则写在pattern后边。
例如:匹配pattern后边的the,如下图,
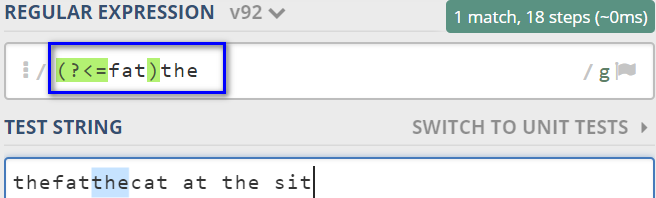
1.3.3 负向先行
(?!pattern)
匹配除去pattern表达式前边的字符,即返回所有不在pattern前边的字符2。
例如,匹配返回除去fat前的所有的the:
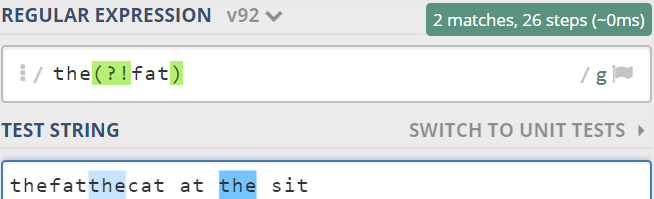
1.3.4 负向后行
(?<!pattern)
匹配除去pattern表达式后边的字符,即返回所有不在pattern后边的字符2。
例如:匹配返回除去fat后的所有the:
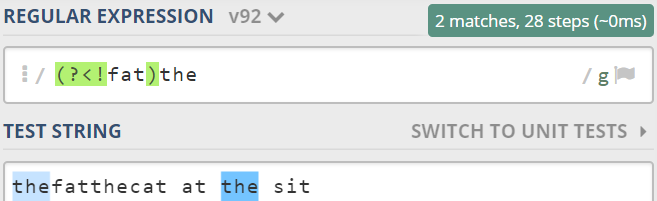
1.4 捕获和非捕获
捕获首先是基于小括号这个关键字的,每个小括号可以自定义一个字符。捕获是正则自动给小括号内容编组并编号,方便后边使用。
它是用来满足根据待匹配字符串中的内容来组织匹配规则的。
例如:找到两个相连的"以t开头以f结尾"的重复字符。
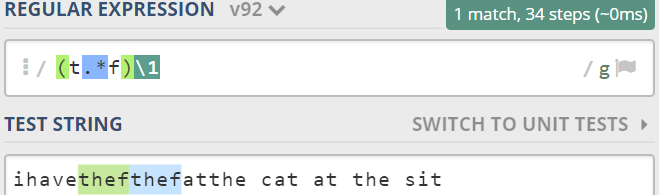
捕获和非捕获的区别在于是否指定分组,存入内存当中,用作其他匹配的引用。
- 如果仅仅用作自定义匹配,而不需要后边继续引用,则使用非捕获。
- 如上图,使用\1的分组,则需要捕获。
1.5 贪婪和非贪婪
贪婪尽量长的匹配,非贪婪匹配尽量短,非贪婪?放在数量词后边,进行限制。
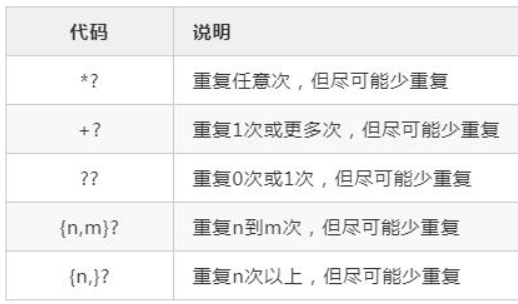
贪婪匹配如下:
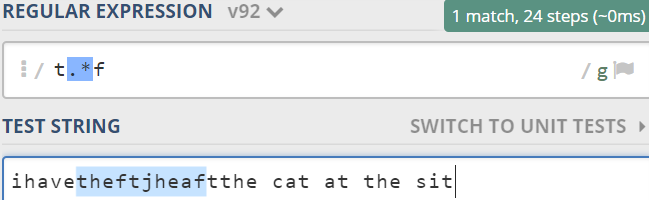
非贪婪匹配如下:
2. 怎么读
正则匹配的程序实现本质上是一个递归过程,递归问题是把原问题分解成最小子问题来依次解决,最终得到答案。
所以读正则表达式,第一步也是最关键的一步就是拆解成最小匹配串。
- 看有没有 | ,| 两遍的匹配串可直接拆分。
- 看有没有小括号,每对小括号包裹起来的,看成自定义子串,做单个字符看待。
- 小括号处理完毕后,剩下的就是字符集和限定符了,从左到右依次分析。
如下图,就是开头问题的分析结果,参考regexper网址:

3. 怎么写
读和写本质上是互逆过程,先完成最小子串需求,然后不断拼接成目标规则串。
- 拆解需求,拆解成能够用最小子串表达的匹配模式
- 将匹配模式拼接到一起
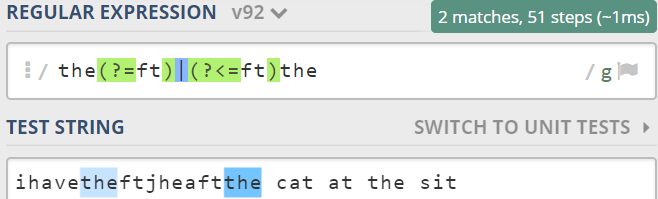
例如:找到与“ft”相邻的the。
- . 拆解需求
(1) 找到ft的前边the
(2) 找到ft的后边the
(3) 取或 - 正向先行the(?=ft) 和 正向后行(?<=ft)the
- 两者取或。 the(?=ft)|(?<=ft)the
如下图所示:
4. 参考文献
本文是基于以下参考文献学习的结果,属于精简版,详细请打开链接学习。















 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









