







《鬼炼狂魔》
别梦依依到谢家 小廊回合曲阑斜 多情只有春庭月 犹为离人照落花
两年AI游结束,有所得有所失
待重头,回归芯片行业
公司项目,已申请专利

深度学习作为新兴技术在图像领域蓬勃发展,因其自主学习图像数据特征避免了人工设计算法的繁琐,精准的检测性能、高效的检测效率以及对各种不同类型的图像任务都有比较好的泛化性能,使得深度学习技术在图像领域得到广泛应用,包括图像检测、图像分类、图像重构等。
深层神经网络中,中间某一层的输入是其之前的神经层的输出。因此,该层之前的神经层的参数变化会导致其输入的分布发生较大的差异。利用随机梯度下降算法更新参数时,每次参数更新都会导致网络中间每一层输入的分布发生改变。越深的层,其输入分布会改变的越明显。内部协变量偏移(Internal Covariate Shift):每一层的参数在更新过程中,会改变下一层输入的分布,神经网络层数越多,表现得越明显,为了解决内部协变量偏移问题,就要使得每一个神经层的输入的分布在训练过程要保持一致,即需要对输入数据进行标准化处理。
数据标准化,就是将原来分布范围不同的数据缩放在一个范围之内,一般来说是标准化到均值为0,标准差为1的标准正态分布,均值为0是为了让数据中心化,让各个维度的特征都平衡,标准差为1是为了让数据在各个维度上的长度都呈现一个单位向量(矩阵),也就是把原来大小范围分布不同的数据缩放成统一量纲,和拳击比赛一样,只有相同重量级的对手才能同台比赛,这里把数据的标准差缩放为1的意义就相当于把轻量级选手的体重加重,把重量级选手的体重减轻,让他们在同一个擂台上比赛,否则比赛就不公平。
在以深度学习为主的人工智能项目的实现过程中,对数据的数量和质量的要求都极高,一般来说,原始数据可以通过各种不同的渠道去收集,最终能够得到大量的数据,为了加快训练,消除对训练不利的因素,往往会使用数据标准化的方法来处理数据,因此一种有效的标准化方法能够极大提高数据的质量,提升神经网络的性能。
本专利提出了一种层次化标准化方法,考虑到不同维度数据相关度不同,分层次地对不同维度数据分次进行标准化,首先对数据关联度大的维度进行标准化,再以做过标准化的数据进行另一维度的标准化,每次标准化都会得到一组可学习的参数。
目录:
1.神经网络数据标准化
2.层次化数据标准化方法
神经网络数据标准化
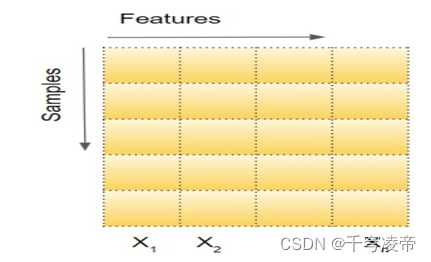
向深度学习模型输入数据时,标准做法是将数据归一化为零均值和单位方差。假设输入数据由几个特征 x1、x2、…xn 组成。每个特征可能具有不同的值范围。例如,特征 x1 的值可能介于 1 到 5 之间,而特征 x2 的值可能介于 1000 到 99999 之间。因此,对于每个特征列,我们分别取数据集中所有样本的值并计算均值和方差。然后使用下面的公式对值进行标准化。
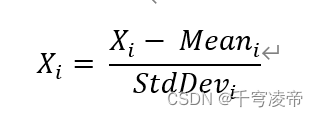
在下图中,可以看到归一化数据的效果。原始值(蓝色)现在以零(红色)为中心。这确保所有特征值现在都在相同的比例上。
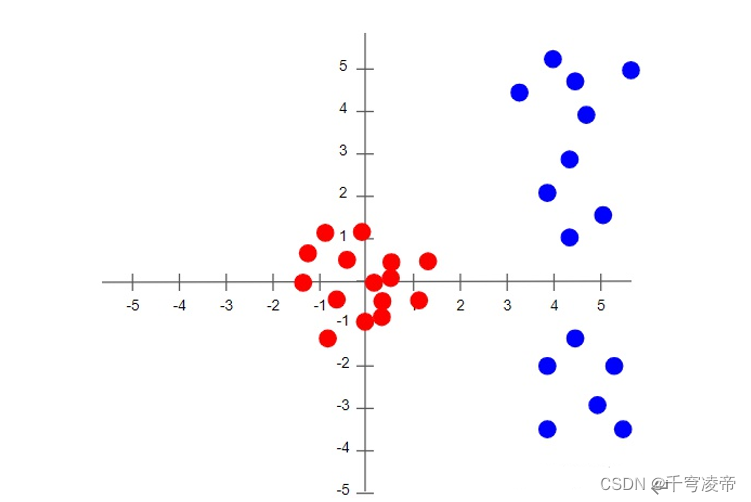
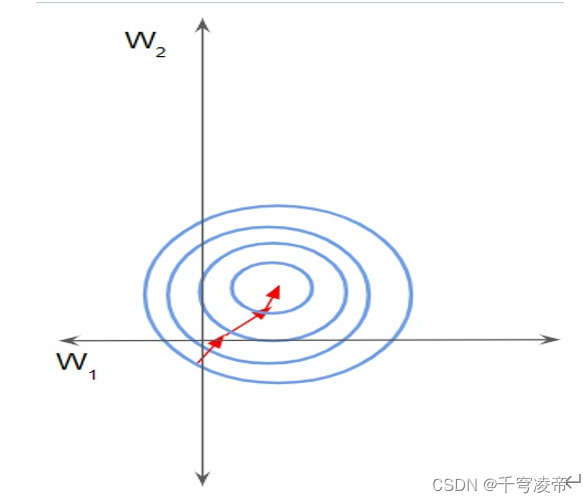
为了理解没有归一化会发生什么,让我们看一个例子,其中只有两个在截然不同的尺度上的特征。由于网络输出是每个特征向量的线性组合,这意味着网络学习每个特征的权重,这些特征也在不同的尺度上。否则,大特征只会淹没小特征。然后在梯度下降过程中,为了“移动指针”为损失,网络必须对一个权重与另一个权重进行较大的更新。这会导致梯度下降轨迹沿一维来回振荡,从而需要更多的步骤才能达到最小值。
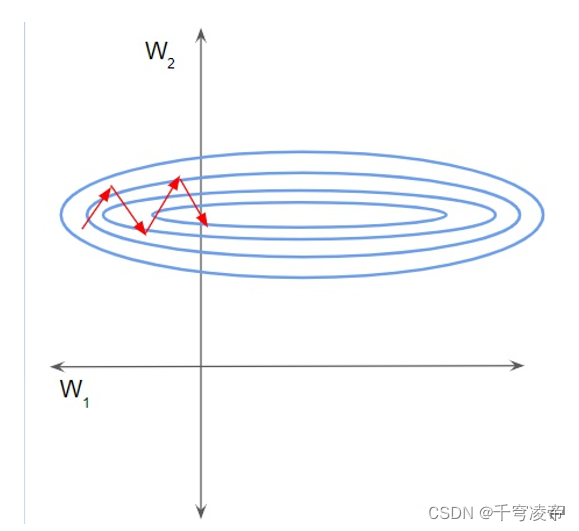
在这种情况下,损失景观看起来像一条狭窄的峡谷。我们可以沿两个维度分解梯度。它在一个维度上是陡峭的,而在另一个维度上则要平缓得多。由于梯度大,我们最终对一个权重进行了更大的更新。这会导致梯度下降反弹到斜坡的另一侧。另一方面,沿第二个方向的较小梯度导致我们进行较小的权重更新,从而采取较小的步长。这种不均匀的轨迹需要更长的时间才能使网络收敛。相反,如果特征在相同的尺度上,损失景观会更像碗一样均匀。然后梯度下降可以平稳地下降到最小值。
层次化数据标准化方法
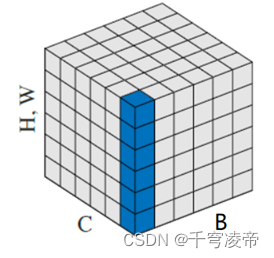
神经网络的输入数据一般维度为B*C*H*W,其中B是批次(Batch),每次输入一批而不是单个数据,每个数据以张量(C*H*W)的形式存在,C是通道数(Channel),H和W是数据高度和宽度(Height,Weight),比如一张240*240的3通道彩色图片的张量表示为3*240*240,每次向神经网络输入10张图片为一批,则输入数据维度为10*3*240*240。每个输入数据的同一通道内像素之间的关系最为紧密,不同批次输入数据同一通道内的像素属于同一关系层,且神经网络中的卷积核,对于同一个输入数据的同一通道像素以及不同输入数据之间的相同通道像素,使用同一个卷积层进行卷积操作,而输入数据的不同通道的像素则使用不同的卷积层进行卷积操作。
基于以上原理,本专利首先对各个输入数据的HW维度进行独立标准化,然后在B维度再进行一次标准化,分层次地对B、H、W做标准化处理,产生两组可学习的偏移参数,对各个输入数据不同通道C的数据不做处理,减少计算量、保持数据分布以及降低过拟合风险。分层次标准化,每次可以精准地处理单个维度数据,避免多个维度上不同分布数据的干扰,第二次标准化在第一次标准化基础上进行,排除了前一次维度数据的干扰,每个维度的标准化都有对应的可学习偏移量,提高了标准化的准确性。
第一步,对于输入数据张量B*C*H*W,对于不同的批次(Batch)和不同通道(Channel)的数据,在HW维度各自进行标准化,首先计算HW维度的均值μHW和方差σ2HW,然后将HW维度上的每个数据值减去均值并除以方差的平方根,其中ε为一很小的数值,最后增加一个缩放因子γHW和偏移量βHW。
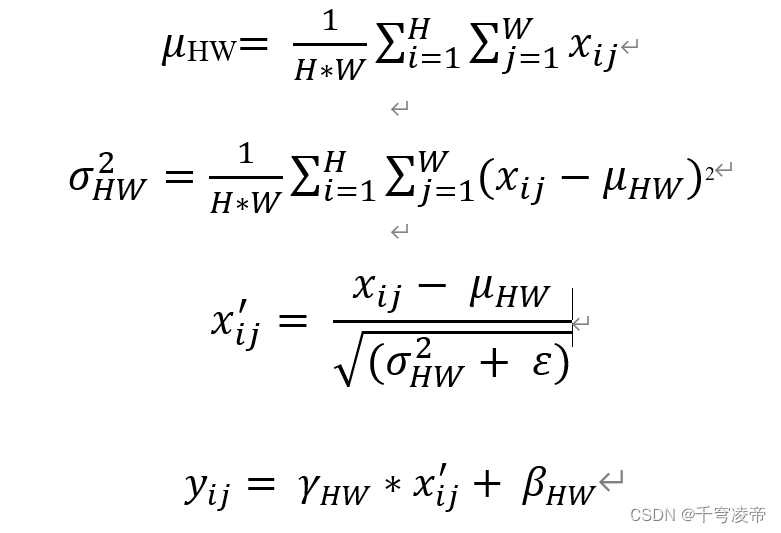
第二步,对于经过了HW维度标准化的数据,在不同批次之间相同通道之间再进行一次标准化。首先计算B维度的均值μB和方差σ2B,然后将B维度上的每个数据值减去均值并除以方差的平方根,其中ε为一很小的数值,最后增加一个缩放因子γB和偏移量βB。
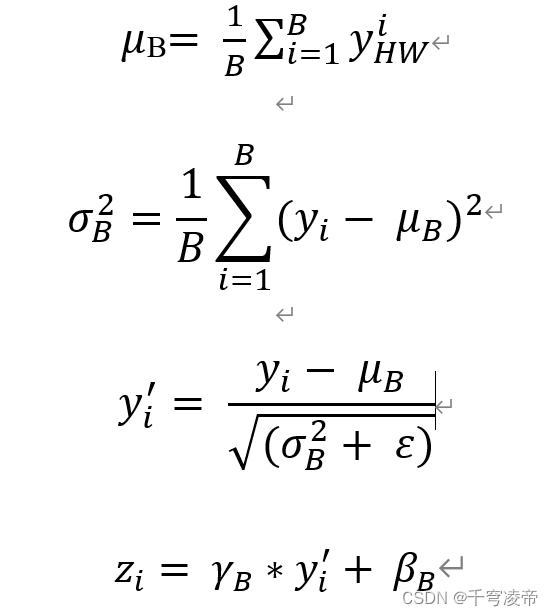
两组可学习参数独立控制HW维度和B维度标准化后的数据分布,可以在两个层次上相互协作,更好的调节标准化的效果。
1.本专利改进了一般标准化方法只在单一维度进行,或是将几个维度数据混在一起进行标准化处理,本专利基于输入张量各个维度数据相关度,依次对HW维度和B维度进行独立标准化,对于数据相关性小的C维度不做处理;
2.对输入数据分层次进行标准化,优先数据相关度紧密的维度,排除其他维度数据的影响;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











