






《一剪梅·寥落风》
大梦初醒已千年 凌乱罗衫 料峭风寒 放眼难觅旧衣冠 疑真疑幻 如梦如烟
看朱成碧心迷乱 莫问生前 但惜因缘 魂无归处为情牵 贪恋人间 不羡神仙

使用pytorch实现DenseNet,完成完整的代码框架,从建立数据集、设置参数、训练网络到推理测试。本文使用DenseNet-BC结构,并加入了dropout机制;
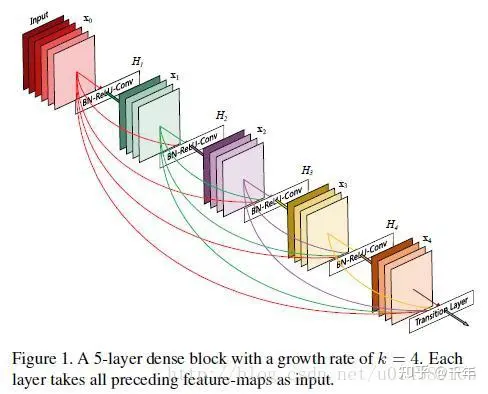
DenseNet的几个优点:
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递
3、更有效地利用了feature
4、一定程度上减少了参数数量
代码放在GitHub上,路径如下:
关于DenseNet的网络结构这里就不展开了,可以参考:
者的硬件配置是Ubuntu18.04+CUDA10.1+cuDNN8.5+GeForce RTX Titan 24G *2
看着很屌,其实一般,只能跑最小的net121,且batch_size最大只能12。
目录:
- 代码文件结构;
- DenseNet神经网络结构代码实现;
- 建立自己的数据集;
- 训练网络;
- 推理;
1.代码文件结构
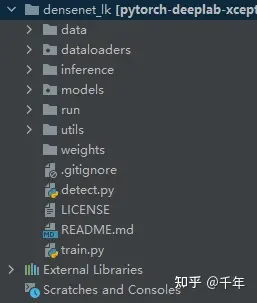
代码文件结构
代码文件结构如上图:
- data:数据集图片,包括训练集和验证集;
- dataloader:建立数据集的模块;
- inference:测试数据集;
- models:模型文件模块;
- utils:一些功能模块;
- run:存放训练结果,包括生成的权重文件、可视化文件;
- weight:存放用于测试的权重文件;
- detect.py:推理代码;
- train.py:训练代码;
data目录:
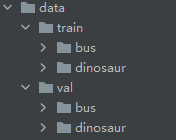
data目录下存放数据集,目录如上图,DenseNet属于图像分类网络,这里就简单做个二分类,使用公交车(bus)照片和恐龙(dinosaur)照片。train为训练数据集,val为验证数据集,这两个子目录下各自存放需要分类的照片,一类数据单独放在一个文件夹里。
dataloader目录:
cfg.py:配置文件,用于设置数据集路径、类别数目、类别名称;
##数据集的类别
NUM_CLASSES = 2
#数据集的存放位置
DATASET_DIR = r'/media/jzdyjy/EEB2EF73B2EF3EA9/workstore/lekang/densenet_lk/data'
TRAIN_DATASET_DIR = r'/media/jzdyjy/EEB2EF73B2EF3EA9/workstore/lekang/densenet_lk/data/train'
VAL_DATASET_DIR = r'/media/jzdyjy/EEB2EF73B2EF3EA9/workstore/lekang/densenet_lk/data/val'
TEST_DATASET_DIR = r'/media/jzdyjy/EEB2EF73B2EF3EA9/workstore/lekang/densenet_lk/inference/image'
#这里需要加入自己的最终预测对应字典,例如:'0': '花'
labels_to_classes = {
'0' : 'bus',
'1' : 'dinosour'
}__init__.py:生成训练数据集和验证数据集的迭代对象。
def make_data_loader(args, **kwargs):
if args.dataset == 'oled_data':
# 构建数据提取器,利用dataloader
# 利用torchvision中的transforms进行图像预处理
mean = [0.49139968, 0.48215841, 0.44653091]
stdv = [0.24703223, 0.24348513, 0.26158784]
train_transforms = transforms.Compose([
transforms.Resize(args.img_size),
transforms.RandomRotation(10),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=stdv)
])
val_transforms = transforms.Compose([
transforms.Resize(args.img_size),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=stdv)
])
##ImageFolder对象可以将一个文件夹下的文件构造成一类
# 所以数据集的存储格式为一个类的图片放置到一个文件夹下
# 然后利用dataloader构建提取器,每次返回一个batch的数据,在很多情况下,利用num_worker参数
# 设置多线程,来相对提升数据提取的速度
"""
if args.use_sbd:
sbd_train = sbd.SBDSegmentation(args, split=['train', 'val'])
train_set = combine_dbs.CombineDBs([train_set, sbd_train], excluded=[val_set])
"""
num_class = cfg.NUM_CLASSES
train_set = datasets.ImageFolder(cfg.TRAIN_DATASET_DIR, transform=train_transforms)
val_set = datasets.ImageFolder(cfg.VAL_DATASET_DIR, transform=val_transforms)
train_loader = DataLoader(train_set, batch_size=args.batch_size, shuffle=True, **kwargs)
val_loader = DataLoader(val_set, batch_size=args.batch_size*2, shuffle=False, **kwargs)
return train_loader, val_loader, num_class
else :
raise NotImplementedErrordatasets:存放一些对数据进行处理的代码,计划是之后做优化用,暂时用不到,可以不用管。
inference目录:
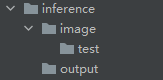
该目录存放需要测试的图片,即测试集数据,图片放在inference/test下面,结果会保存在output下面,路径可以自定义,在推理代码文件detect.py里修改。
models目录:
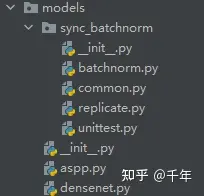
该目录下放的是模型相关代码文件。
- 两个空文件_init_.py用于把所在文件夹打包成一个module,方便调用。
- densenet.py是模型主文件;
- aspp.py是空洞空间卷积池化金字塔(atrous spatial pyramid pooling),打算之后用于网络优化改进用,这一版没用到,可以不用管;
- batchnorm.py是批次归一化代码;
- replicate.py用于DataParallel技术,提升训练速度;Note:有没有高手知道这么用DistributedDataParallel的;
- common.py和unittest.py放一些公共函数;
utils目录:
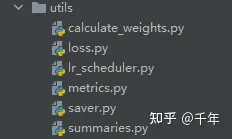
- calculate_weights.py:label权重计算,后期优化用,暂时没用到;
- lr_scheduler.py:学习率变化策略,包括cos、poly和step;
- loss.py:损失函数优化策略,包括Focal和CS;
- metrics.py:不用;
- saver.py:保存文件,包括checkpoint的.pth.tar文件,训练过程中acc的变化txt文件,训练参数的txt文件;
- summaries.py:tensorboard相关文件;
2.DenseNet神经网络结构代码实现
DenseNet神经网络代码主要在models/densenet.py里。
class Bottleneck(nn.Module):
def __init__(self, nChannels, growthRate, drop_rate, training):
super(Bottleneck, self).__init__()
interChannels = 4*growthRate
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, interChannels, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(interChannels)
self.conv2 = nn.Conv2d(interChannels, growthRate, kernel_size=3, padding=1, bias=False)
self.drop_rate = drop_rate
self.training = training
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat((x, out), 1)
if self.drop_rate > 0:
out = F.dropout(out, p=self.drop_rate, training=self.training)
return out
class SingleLayer(nn.Module):
def __init__(self, nChannels, growthRate):
super(SingleLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, growthRate, kernel_size=3, padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = torch.cat((x, out), 1)
return out
class Transition(nn.Module):
def __init__(self, nChannels, nOutChannels, drop_rate, training):
super(Transition, self).__init__()
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, nOutChannels, kernel_size=1, bias=False)
self.drop_rate = drop_rate
self.training = training
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = F.avg_pool2d(out, 2)
if self.drop_rate > 0:
out = F.dropout(out, p=self.drop_rate, training=self.training)
return out
class DenseNet(nn.Module):
def __init__(self, backbone, compression, num_classes, bottleneck, drop_rate, training):
super(DenseNet, self).__init__()
if backbone == 'net121' :
growthRate = 32
nDenseBlocks1 = 6
nDenseBlocks2 = 12
nDenseBlocks3 = 24
nDenseBlocks4 = 16
elif backbone == 'net161' :
growthRate = 32
nDenseBlocks1 = 6
nDenseBlocks2 = 12
nDenseBlocks3 = 36
nDenseBlocks4 = 24
elif backbone == 'net169' :
growthRate = 48
nDenseBlocks1 = 6
nDenseBlocks2 = 12
nDenseBlocks3 = 32
nDenseBlocks4 = 32
elif backbone == 'net201' :
growthRate = 32
nDenseBlocks1 = 6
nDenseBlocks2 = 12
nDenseBlocks3 = 48
nDenseBlocks4 = 32
else :
print('Backbone {} not available.'.format(backbone))
raise NotImplementedError
nChannels = 2*growthRate
self.conv1 = nn.Conv2d(3, nChannels, kernel_size=3, padding=1, bias=False)
self.dense1 = self._make_dense(nChannels, growthRate, nDenseBlocks1, bottleneck, drop_rate, training)
nChannels += nDenseBlocks1 * growthRate
nOutChannels = int(math.floor(nChannels * compression))
self.trans1 = Transition(nChannels, nOutChannels, drop_rate, training)
nChannels = nOutChannels
self.dense2 = self._make_dense(nChannels, growthRate, nDenseBlocks2, bottleneck, drop_rate, training)
nChannels += nDenseBlocks2 * growthRate
nOutChannels = int(math.floor(nChannels * compression))
self.trans2 = Transition(nChannels, nOutChannels, drop_rate, training)
nChannels = nOutChannels
self.dense3 = self._make_dense(nChannels, growthRate, nDenseBlocks3, bottleneck, drop_rate, training)
nChannels += nDenseBlocks3 * growthRate
nOutChannels = int(math.floor(nChannels * compression))
self.trans3 = Transition(nChannels, nOutChannels, drop_rate, training)
nChannels = nOutChannels
self.dense4 = self._make_dense(nChannels, growthRate, nDenseBlocks4, bottleneck, drop_rate, training)
nChannels += nDenseBlocks4 * growthRate
self.bn1 = nn.BatchNorm2d(nChannels)
self.fc = nn.Linear(nChannels, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
def _make_dense(self, nChannels, growthRate, nDenseBlocks, bottleneck, drop_rate, training):
layers = []
for i in range(int(nDenseBlocks)):
if bottleneck:
layers.append(Bottleneck(nChannels, growthRate, drop_rate, training))
else:
layers.append(SingleLayer(nChannels, growthRate))
nChannels += growthRate
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.trans1(self.dense1(out))
out = self.trans2(self.dense2(out))
out = self.trans3(self.dense3(out))
out = self.dense4(out)
#out = torch.squeeze(F.avg_pool2d(F.relu(self.bn1(out)), 8))
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = F.log_softmax(self.fc(out), dim=1)
return out- 顶层类class DenseNet(nn.Module):包含神经网络构建函数__init__和DenseNet block块构建函数_make_dense以及前向传播函数forward;
- _make_dense函数:调用class Bottleneck(nn.Module)和class SingleLayer(nn.Module)构建block块;
- class Transition(nn.Module):block和block之间的连接层;
- Bottleneck和Transition都加入了dropout机制;
结构如下图:

本文实现论文中DenseNet-BC的四种结构,DenseNet-121、DenseNet-161、DenseNet-169和DenseNet-201,如下图:

3.建立自己的数据集
本文是图像分类神经网络,因此数据集生成相对简单,使用ImageFolder对象可以将一个文件夹下的文件构造成一类,所以数据集的存储格式为一个类的图片放置到一个文件夹下,然后利用dataloader构建提取器,每次返回一个batch的数据,在很多情况下,利用num_worker参数设置多线程,来相对提升数据提取的速度。
把需要分类的图片按照类别放置在data目录下train和val文件夹下,每一类图片分别放在一个文件夹下。
4.训练网络
先看一下训练代码文件train.py.
class Trainer(object):
def __init__(self, args):
self.args = args
# Define Saver
self.saver = Saver(args)
self.saver.save_experiment_config()
# Define Tensorboard Summary
self.summary = TensorboardSummary(self.saver.experiment_dir)
self.writer = self.summary.create_summary()
# Define Dataloader
kwargs = {'num_workers': args.workers, 'pin_memory': True}
self.train_loader, self.val_loader, self.nclass = make_data_loader(args, **kwargs)
# Define network
model = DenseNet(
backbone = args.backbone,
compression = args.compression,
num_classes = cfg.NUM_CLASSES,
bottleneck = args.bottleneck,
drop_rate = args.drop_rate,
training = args.training
)
print(model)
# Print number of parameters
num_params = sum(p.numel() for p in model.parameters())
print("Total parameters: ", num_params)
# Define Optimizer
if args.adam :
optimizer = torch.optim.Adam(
model.parameters(),
lr = args.lr,
betas = (0.9, 0.999),
eps = 1e-08,
weight_decay = args.weight_decay
)
else :
optimizer = torch.optim.SGD(
model.parameters(),
lr = args.lr,
momentum = args.momentum,
weight_decay = args.weight_decay,
nesterov = args.nesterov
)
# Define Criterion
# whether to use class balanced weights
#if args.use_balanced_weights:
# classes_weights_path = os.path.join(cfg.DATASET_DIR, args.dataset+'_classes_weights.npy')
# if os.path.isfile(classes_weights_path):
# weight = np.load(classes_weights_path)
# else:
# weight = calculate_weigths_labels(args.dataset, self.train_loader, self.nclass)
# weight = torch.from_numpy(weight.astype(np.float32))
# print("[Note] : Weigths Balanced is used!!!")
#else:
# weight = None
self.criterion = SegmentationLosses(weight=None, cuda=args.cuda).build_loss(mode=args.loss_type)
self.model, self.optimizer = model, optimizer
# Define Evaluator
# self.evaluator = Evaluator(self.nclass)
# Define lr scheduler
self.scheduler = LR_Scheduler(args.lr_scheduler, args.lr, args.epochs, len(self.train_loader))
# Using DataParallel
if args.cuda:
self.model = torch.nn.DataParallel(self.model, device_ids=self.args.gpu_ids)
patch_replication_callback(self.model)
self.model = self.model.cuda()
print("[Note] : DP mode is used!!!")
# Resuming checkpoint
self.best_pred = 0.0
if args.resume is not None:
if not os.path.isfile(args.resume):
raise RuntimeError("[Note] : no checkpoint found at '{}'" .format(args.resume))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
if args.cuda:
self.model.module.load_state_dict(checkpoint['state_dict'])
print("[Note] : Resume CUDA is used!!!")
else:
self.model.load_state_dict(checkpoint['state_dict'])
if not args.ft:
self.optimizer.load_state_dict(checkpoint['optimizer'])
self.best_pred = checkpoint['best_pred']
print("[Note] : Loaded checkpoint '{}' (epoch {})".format(args.resume, checkpoint['epoch']))
# Clear start epoch if fine-tuning
if args.ft:
args.start_epoch = 0
def training(self, epoch):
train_loss = 0.0
self.model.train()
tbar = tqdm(self.train_loader)
num_img_tr = len(self.train_loader)
print("num_img_tr = %d" %(num_img_tr))
for i, (image, target) in enumerate(tbar) :
if self.args.cuda:
image, target = image.cuda(), target.cuda()
self.scheduler(self.optimizer, i, epoch, self.best_pred)
self.optimizer.zero_grad()
output = self.model(image)
loss = self.criterion(output, target)
#loss = F.cross_entropy(output, target)
loss.backward()
self.optimizer.step()
train_loss += loss.item()
tbar.set_description('Train Loss: %.5f' % (train_loss / (i + 1)))
self.writer.add_scalar('Train/Total_loss_iter', loss.item(), i + num_img_tr * epoch)
# Show 10 * 3 inference results each epoch
# if i % (num_img_tr // 10) == 0:
# global_step = i + num_img_tr * epoch
# self.summary.visualize_image(self.writer, self.args.dataset, image, target, output, global_step)
self.writer.add_scalar('Train_loss/Total_epoch', train_loss, epoch)
print('[Epoch/Total Epochs: %d/%d, numImages: %5d]' % (epoch, self.args.epochs, i * self.args.batch_size + image.data.shape[0]))
print('Total Train Loss: %.5f' % train_loss)
if self.args.no_val:
# save checkpoint every epoch
is_best = False
self.saver.save_checkpoint({
'epoch' : epoch + 1,
'state_dict' : self.model.module.state_dict(),
'optimizer' : self.optimizer.state_dict(),
'best_pred' : self.best_pred,
}, is_best)
def validation(self, epoch):
self.model.eval()
tbar = tqdm(self.val_loader, desc='\r')
Acc = 0.0
#Acc_class = 0.0
val_loss = 0.0
for i, (image, target) in enumerate(tbar) :
if self.args.cuda:
image, target = image.cuda(), target.cuda()
with torch.no_grad():
output = self.model(image)
loss = self.criterion(output, target)
val_loss += loss.item()
tbar.set_description('Val Loss: %.5f' %(val_loss / (i + 1)))
#pred = output.data.cpu().float()
pred = output.data.max(1)[1] # get the index of the max log-probability
Acc += (pred == target).sum().float()/self.args.batch_size
#All_acc += len(target)
# Add batch sample into evaluator
#self.evaluator.add_batch(target, pred)
# Fast test during the training
Acc /= len(tbar)
self.writer.add_scalar('val/total_loss_epoch', val_loss, epoch)
self.writer.add_scalar('val/Acc', Acc, epoch)
#self.writer.add_scalar('val/Acc_class', Acc_class, epoch)
print('Validation:')
print('[Epoch / Total Epochs: %d/%d, numImages: %5d]' % (epoch, self.args.epochs, i * self.args.batch_size + image.data.shape[0]))
print("Acc:{}".format(Acc))
print('Total Val Loss: %.5f' %val_loss)
new_pred = Acc
if new_pred > self.best_pred:
is_best = True
self.best_pred = new_pred
self.saver.save_checkpoint({
'epoch' : epoch + 1,
'state_dict' : self.model.module.state_dict(),
'optimizer' : self.optimizer.state_dict(),
'best_pred' : self.best_pred,
}, is_best)
def main():
# 命令行交互,设置一些基本的参数
parser = argparse.ArgumentParser(description="PyTorch DenseNet Training")
parser.add_argument('--backbone', type=str, default='net121', choices=['net121', 'net161', 'net169', 'net201'],
help='backbone name')
parser.add_argument('--growthRate', type=int, default=12, help='number of features added per DenseNet layer')
parser.add_argument('--compression', type=int, default=0.7, help='network output stride')
parser.add_argument('--bottleneck', type=str, default=True, help='network output stride')
parser.add_argument('--drop_rate', type=int, default=0.5, help='dropout rate')
parser.add_argument('--training', type=str, default=True, help='')
parser.add_argument('--dataset', type=str, default='oled_data', choices=['oled_data'],
help='dataset name (default: pascal)')
parser.add_argument('--use_sbd', action='store_true', default=True, help='whether to use SBD dataset (default: True)')
parser.add_argument('--workers', type=int, default=8, metavar='N', help='dataloader threads')
parser.add_argument('--img_size', type=int, default=(320, 320), help='train and val image resize')
parser.add_argument('--loss_type', type=str, default='focal', choices=['ce', 'focal'],
help='loss func type (default: ce)')
# training hyper params
parser.add_argument('--epochs', type=int, default=None, metavar='N',
help='number of epochs to train (default: auto)')
parser.add_argument('--start_epoch', type=int, default=0, metavar='N', help='start epochs (default:0)')
parser.add_argument('--batch_size', type=int, default=None, metavar='N', help='input batch size for \
training (default: auto)')
parser.add_argument('--test_batch_size', type=int, default=None, metavar='N', help='input batch size for \
testing (default: auto)')
#parser.add_argument('--use_balanced_weights', action='store_true', default=True,
# help='whether to use balanced weights (default: False)')
# optimizer params
parser.add_argument('--adam', default=False, help='use torch.optim.Adam() optimizer')
parser.add_argument('--lr', type=float, default=0.001, metavar='LR', help='learning rate (default: auto)')
parser.add_argument('--lr_scheduler', type=str, default='poly', choices=['poly', 'step', 'cos'],
help='lr scheduler mode: (default: poly)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M', help='momentum (default: 0.9)')
parser.add_argument('--weight_decay', type=float, default=5e-4, metavar='M', help='w-decay (default: 5e-4)')
parser.add_argument('--nesterov', action='store_true', default=True, help='whether use nesterov (default: False)')
# cuda, seed and logging
parser.add_argument('--no_cuda', action='store_true', default=False, help='disables CUDA training')
parser.add_argument('--gpu_ids', type=str, default='0,1', help='use which gpu to train, must be a \
comma-separated list of integers only (default=0)')
parser.add_argument('--seed', type=int, default=1, metavar='S', help='random seed (default: 1)')
# checking point
parser.add_argument('--resume', type=str, default=None, help='put the path to resuming file if needed')
parser.add_argument('--checkname', type=str, default=None, help='set the checkpoint name')
# finetuning pre-trained models
parser.add_argument('--ft', action='store_true', default=True, help='finetuning on a different dataset')
# evaluation option
parser.add_argument('--eval_interval', type=int, default=1, help='evaluation interval (default: 1)')
parser.add_argument('--no_val', action='store_true', default=False, help='skip validation during training')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
if args.cuda:
try:
args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]
except ValueError:
raise ValueError('Argument --gpu_ids must be a comma-separated list of integers only')
# default settings for epochs, batch_size and lr
if args.epochs is None:
epoches = {
'oled_data' : 100,
'cityscapes' : 200,
'pascal' : 50,
}
args.epochs = epoches[args.dataset.lower()]
if args.batch_size is None:
args.batch_size = 4 * len(args.gpu_ids)
if args.test_batch_size is None:
args.test_batch_size = args.batch_size
if args.lr is None:
lrs = {
'coco' : 0.1,
'cityscapes' : 0.01,
'pascal' : 0.007,
}
args.lr = lrs[args.dataset.lower()] / (4 * len(args.gpu_ids)) * args.batch_size
if args.checkname is None:
args.checkname = str(args.backbone) + '_' + str(args.batch_size) + '_' + str(args.epochs)
print(args)
torch.manual_seed(args.seed)
trainer = Trainer(args)
print('Starting Epoch:', trainer.args.start_epoch)
print('Total Epoches:', trainer.args.epochs)
for epoch in range(trainer.args.start_epoch, trainer.args.epochs):
trainer.training(epoch)
if not trainer.args.no_val and epoch % args.eval_interval == (args.eval_interval - 1):
trainer.validation(epoch)
trainer.writer.close()
if __name__ == "__main__":
main()- 准备数据集;
- 在dataloaders/cfg.py里配置分类数目和类型名称;
- 设置train.py里的参数,可以使用pycharm后者命令行方式,主要参数如下:
- batch_size:每批次图片数目;
- epochs:迭代次数;
- backbone:网络结构;
- workers:多线程数目;
- loss_type:损失函数优化策略;
- img_size:图片缩放大小;
- lr:初始学习率
- lr_scheduler:学习率优化策略;
- adam:是否使用Adam损失函数,默认为SDGM;
- gpu_ids:GPU数量;
作者一般只用3个参数,其他的都是默认值,pycharm设置如下图:

命令行方式如下图:
python train.py --backbone net201 --batch_size 32 --epochs 2000之后便是训练过程,如下图:
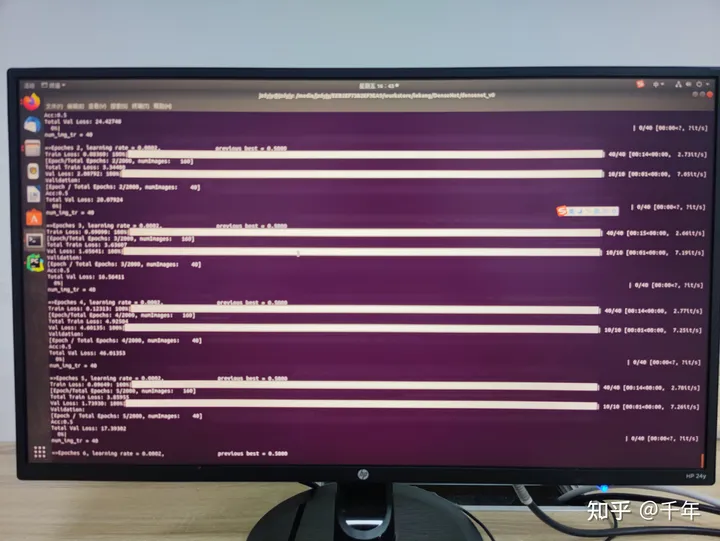
训练结束后,会在run目录下生成结果文件夹,结构如下图:
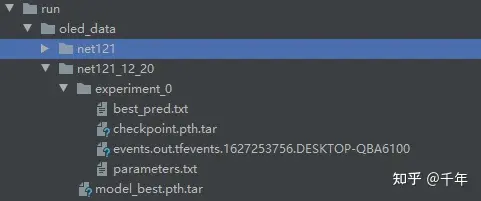
每次训练后会生成一个experiment_*文件夹,
checkpoint.pth.tar:训练过程中检查点阈值保存文件;
best_pred.txt:保存Acc的值;
http://events.out.xxx:tensorboard可视化文件;
parameter.txt:本次训练神经网络各个参数值
model_best.pth.tar:最佳Acc对应的阈值保存文件
5.推理测试:
训练完成之后,可以使用detect.py来测试新数据集,先看一下detect.py代码:
def main():
parser = argparse.ArgumentParser(description="PyTorch DenseNet Detecting")
parser.add_argument('--in_path', type=str, default='inference/image/test', help='image to test')
parser.add_argument('--out_path', type=str, default='inference/output', help='mask image to save')
parser.add_argument('--backbone', type=str, default='net121', choices=['net121', 'net161', 'net169', 'net201'],
help='backbone name (default: net121)')
parser.add_argument('--growthRate', type=int, default=12, help='number of features added per DenseNet layer')
parser.add_argument('--compression', type=int, default=0.7, help='network output stride')
parser.add_argument('--bottleneck', type=str, default=True, help='network output stride')
parser.add_argument('--drop_rate', type=int, default=0.5, help='dropout rate')
parser.add_argument('--training', type=str, default=True, help='')
parser.add_argument('--weights', type=str, default='weights/model_best.pth.tar', help='saved model')
parser.add_argument('--num_classes', type=int, default=2, help='')
parser.add_argument('--no_cuda', action='store_true', default=False, help='disables CUDA training')
parser.add_argument('--gpu_ids', type=str, default='0,1', help='use which gpu to train, must be a \
comma-separated list of integers only (default=0)')
parser.add_argument('--img_size', type=int, default=(360, 360), help='crop image size')
parser.add_argument('--sync_bn', type=bool, default=None, help='whether to use sync bn (default: auto)')
parser.add_argument('--save_dir', action='store_true', default='inference/output', help='save results to *.txt')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
print(torch.cuda.is_available())
webcam = args.in_path.isnumeric() or args.in_path.endswith('.txt') or args.in_path.lower().startswith(
('rtsp://', 'rtmp://', 'http://'))
results = 'result' + '_' + str(datetime.datetime.now().strftime("%Y%m%d_%H%M%S")) + '.txt'
results_file = os.path.join(args.save_dir, results)
if args.cuda:
try:
args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]
except ValueError:
raise ValueError('Argument --gpu_ids must be a comma-separated list of integers only')
if args.sync_bn is None:
if args.cuda and len(args.gpu_ids) > 1:
args.sync_bn = True
else:
args.sync_bn = False
model_s_time = time.time()
# Define network
model = DenseNet(
backbone = args.backbone,
compression = args.compression,
num_classes = args.num_classes,
bottleneck = args.bottleneck,
drop_rate = args.drop_rate,
training = args.training
)
labels2classes = cfg.labels_to_classes
ckpt = torch.load(args.weights, map_location='cpu')
model.load_state_dict(ckpt['state_dict'])
model = model.cuda()
model_u_time = time.time()
model_load_time = model_u_time-model_s_time
print("model load time is {}s".format(model_load_time))
# for i, (image, target) in enumerate(test_loader) :
# s_time = time.time()
# print(image.path)
# print(target)
#
# model.eval()
# if args.cuda:
# image = image.cuda()
#
# with torch.no_grad():
# out = model(image)
# prediction = torch.max(out, 1)[1]
#
# u_time = time.time()
# img_time = u_time-s_time
# label = labels2classes[str(prediction.cpu().numpy()[0])]
#
# #print("image:{} label:{} time: {} ".format(image, label, img_time))
# print("label:{} time: {} ".format(label, img_time))
# composed_transforms = transforms.Compose([
# transforms.Resize(args.img_size),
# transforms.ToTensor()
# ])
#
# for name in os.listdir(args.in_path):
# s_time = time.time()
# image = Image.open(args.in_path+"/"+name).convert('RGB')
# target = Image.open(args.in_path + "/" + name).convert('L')
# sample = {'image': image, 'label': target}
#
# tensor_in = composed_transforms(sample)['image'].unsqueeze(0)
#
# model.eval()
#
# if args.cuda:
# tensor_in = tensor_in.cuda()
# with torch.no_grad():
# out = model(tensor_in)
# prediction = torch.max(out, 1)[1]
#
# u_time = time.time()
# img_time = u_time-s_time
# label = labels2classes[str(prediction.cpu().numpy()[0])]
#
# print("image:{} label:{} time: {} ".format(name, label, img_time))
if args.cuda :
model.half()
if webcam :
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(args.in_path, img_size=args.img_size)
else:
dataset = LoadImages(args.in_path, img_size=args.img_size)
all_s_time = time.time()
for path, image, im0s, vid_cap in dataset :
image = torch.from_numpy(image).cuda()
image = image.half() if args.cuda else image.float() # uint8 to fp16/32
image /= 255.0 # 0 - 255 to 0.0 - 1.0
if image.ndimension() == 3:
image = image.unsqueeze(0)
s_time = time.time()
model.eval()
with torch.no_grad():
out = model(image)
prediction = torch.max(out, 1)[1]
u_time = time.time()
img_time = u_time-s_time
label = labels2classes[str(prediction.cpu().numpy()[0])]
print("label: {} time: {}s".format(label, img_time))
with open(results_file, 'a') as f:
f.write("%s %s \n" % (path, label))
all_e_time = time.time()
all_time = all_e_time - all_s_time
print("Total time is {}s".format(all_time))
print("Detect is done.")
if __name__ == "__main__":
main()把训练好的model_best.pth_tar放在weights文件夹下,配置detect.py里的模型推理参数,就可以开始推理,结果会在inference/out下生成一个txt文件,里面是推理的图片路径及推理结果。
作者实测可以正常训练及推理测试,不过由于模型对GPU显存要求较高,跑不了太大的网络,batch_size无法设太高,作者的训练结果不尽如人意。
这版只是重现论文中的神经网络模型,并没有加以优化,目前作者在进行优化工作,尝试添加最新的神经网络技术,比如特征金字塔,空洞卷积,通道交错融合等,以期提高分类精度,降低显存消耗,提升速度等,到时候再发出来。
最近很多有优秀国漫,斗破苍穹第四季,百妖谱第二季,元龙第二季,推一波。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











