







成绩:30%(平时作业)+ 70%(大作业)
第一课
1.1自然语言处理概述
NLP组成:
自然语言识别NLP=自然语言理解NLU+自然语言生成NLG
自然语言NLP的发展阶段:
萌芽期:香农、图灵
符号主义(基于规则)
时间:1956~1980
原理:基于逻辑推断、每步都需要具体的表达
方法:规则系统、专家系统
缺点:规则不完善,没有科学基础,规则非黑即白,缺失了语言的灵活性
连接主义(基于概率方法)
时间:1980~1999
原理:仿生学派,更形象,类似黑盒,无需给出规定,无需梳理
方法:决策树(速度快、所需数据小)、贝叶斯、SVM、感知机
深度学习
时间:2000年至今
原理:结合简单的统计机器学习算法解决
自然语言处理面临的困难:
歧义
断句 :做手术的张老师
知识的获取、表达及运用(上下文句子的暗示)
上下文理解
计算问题
中国+首都 = 北京
自然语言的主要研究任务:
序列标注
分类(SVM、机器学习方法)
文本分类
情感倾向分类
3. 关系判断:相似度、语言推理
特征嵌入:针对自然语言的技术:语言-》统一值阈的向量-》相似度矩阵
正在拥抱 -蕴含-》表达爱意
4.语言生成:文本摘要(长文压缩)、语言翻译
文本摘要:摘要机:一定比例的内容保留
分词方法:
①基于词典的分词方法(最大匹配算法、最短路径算法)
词表库:对当前的语句匹配、生成最大
②基于统计的分词方法
中文
分词工具:jieba、pyhanlp
实验1. 自然语言项目环境搭建
Jupyter、Pycharm、tensorflow框架、AIStudio paddle、(Spyder)
https://aistudio.baidu.com/
jieba、matplotlib、sklearn、tensorflow
jieba
jieba是优秀的中文分词第三方库,由于中文文本之间每个汉字都是连续书写的,我们需要通过特定的手段来获得其中的每个词组,这种手段叫做分词,我们可以通过jieba库来完成这个过程。
jieba.1 四种分词方式
精确模式
全局模式
搜索模式
paddle模式
import jieba
print(jieba.lcut("乒乓球拍卖完了"))
print(jieba.lcut("乒乓球拍卖完了",cut_all=True))
print(jieba.lcut_for_search("乒乓球拍卖完了"))
print(jieba.lcut("乒乓球拍卖完了",use_paddle=True))
print("--------------")
A = jieba.cut("乒乓球拍卖完了")
for i in A:
print(i)
A = jieba.cut("乒乓球拍卖完了",cut_all=True)
for i in A:
print(i)
A = jieba.cut_for_search("乒乓球拍卖完了")
for i in A:
print(i)
A = jieba.lcut("乒乓球拍卖完了",use_paddle=True)
for i in A:
print(i)
print("------迭代器转换成字符串与列表--------")
A = jieba.cut("乒乓球拍卖完了")
A_str = " ".join(A)
print(A_str)
A_list = A_str.split()
print(A_list)jieba.2 词频统计Demo
import jieba
txt = open(r"E:\data\wenzhang.txt", encoding="utf-8").read()
words = jieba.lcut(txt)
counts = {}
print(words)
for word in words:
# 过滤
if len(word) == 1:
continue
# 统计
else:
counts[word] = counts.get(word, 0)+1
# dict.get(key[, value]) 参数:key -- 字典中要查找的键。value -- 可选,如果指定键的值不存在时,返回该默认值。
items = list(counts.items()) # 变成字典
print(items)
items.sort(key=lambda x:x[1], reverse=True) # https://blog.csdn.net/weixin_44769957/article/details/109479281
print(items)
for i in range(15):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))jieba.3 停用词过滤
停用词下载:
# 加载停用词表
import jieba
# 停用词的下载
stopwords_file = r'./stopword.txt'
with open(stopwords_file, "r",encoding='utf-8') as words:
stopwords = [i.strip() for i in words]
stopwords.extend(['.', '(', ')', '-', '——', '(', ')', ' ', ',']) # 此处可以添加一些停用词表中没有的停用词
print(stopwords)
print(len(stopwords))
wenzhangpath = r'E:\data\wenzhang.txt'
fd = open(wenzhangpath,'r',encoding='utf-8')
str = fd.read()
wordlist = jieba.lcut(str)
print(wordlist)
print(len(wordlist))
# 过滤掉停用表的词语长度为1的值
wordlist_cut = [i for i in wordlist if (not i in stopwords) and len(i) >= 2]
print(wordlist_cut)
print(len(wordlist_cut))
counts = {}
for i in wordlist_cut:
counts[i] = counts.get(i,0) + 1
print(counts)
counts = list(counts.items())
counts.sort(key = lambda x:x[1], reverse=True)
print(counts)paddlepaddle
paddlepaddle.1 地址
飞桨AI Studio - 人工智能学习实训社区 (baidu.com)
官网:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
运行平台:https://aistudio.baidu.com/
paddlepaddle.2 Fluid安装
pip安装、docker容器、按个人需求编译
Spyder
Spyder.1
Tensorflow
Tensorflow.1
词法分析
1 过程
分词_过滤(是否标注词性)
词频统计(TF-IDF、TextRank)
关键词排序
2 分词实例之词频统计
2.1 词频分析
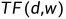
import jieba
import jieba.posseg as psg
import re
# TF-IDF
# TextRank
# 统计词频
path = r"E:\data\NLP\cehua.txt"
file = open(path,encoding='utf-8')
data = file.read()
# 去空格
data = data.replace(" ", "").replace("\n", "")
print(data)
# 分词
words = jieba.lcut(data)
print(words)
# 去除停用词
stoppath = r"E:\data\NLP\stoplist.txt"
stoplist = open(stoppath,encoding="utf-8").read().split()
words_cut = [i for i in words if words not in stoplist and len(i) > 1]
print(words_cut)
counts = {}
for i in words_cut:
counts[i] = counts.get(i,0)+1
counts = list(counts.items())
counts.sort(key= lambda x:x[1],reverse=True)
print(counts)
print("重要排名"," 词"," 出现频次")
for i in range(15):
print(i+1,counts[i][0],counts[i][1])词频统计运行结果

# 该函数返回的是一整个txt文件里的内容,按照空格分开再拼起来,因此最终结果没有空格
def get_content(path):
with open(path, 'r', encoding='gbk', errors='ignore') as f:
content = ''
for l in f:
l = l.strip()
content += l
return content
def get_TF(words, topK=10):
tf_dic = {}
for w in words:
tf_dic[w] = tf_dic.get(w, 0) + 1
return sorted(tf_dic.items(), key = lambda x: x[1], reverse=True)[:topK]
def stop_words(path):
with open(path, 'r', encoding='UTF-8') as f:
return [l.strip() for l in f]
stop_words(r'E:\data\NLP\data\data\stop_words.utf8')
files = glob.glob(r'E:\data\NLP\data\data\*.txt')
corpus = [get_content(x) for x in files] # 返回以文档内容为元素的列表
sample_idx = random.randint(0, len(corpus))
# 随机抽取一个文档、分词、去停用词
split_words = [x for x in jieba.cut(corpus[sample_idx]) if x not in stop_words(r'E:\data\NLP\data\data\stop_words.utf8')]
print('样本'+str(sample_idx)+":"+corpus[sample_idx])
print('样本分词效果:'+'/ '.join(split_words))
print('样本的topK(10)词:'+str(get_TF(split_words)))运行结果

2.2 TF-IDF
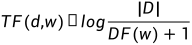

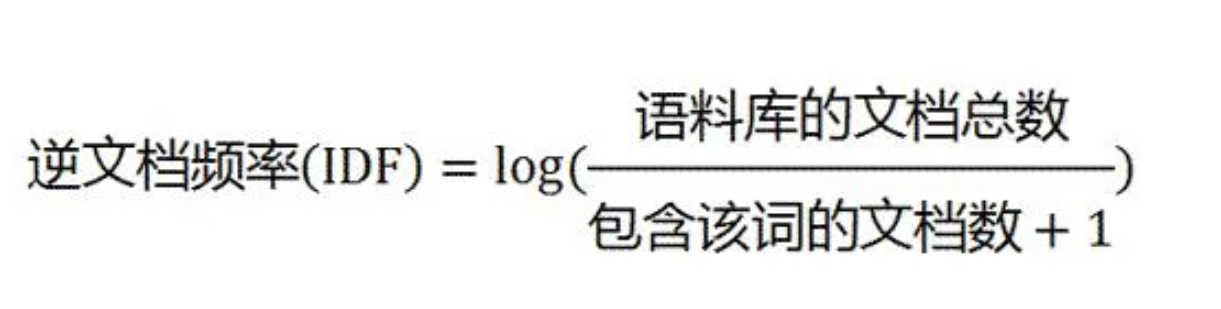
机器学习:生动理解TF-IDF算法 - 知乎 (zhihu.com)
2.3 TextRank
jieba.ananlyse.textrank(text,keyword)
重要的词的定义:通常与其他词同时出现的词
不需要大规模训练的语料库(比对TF-IDF)
无监督学习,适应性扩展能力强
计算快
关键词提取和摘要算法TextRank详解与实战 - 知乎 (zhihu.com)
TextRank算法详细讲解与代码实现(完整) - 方格田 - 博客园 (cnblogs.com)
import jieba
import jieba.analyse.textrank as textrank
for x, w in jieba.analyse.textrank(data, topK=20, withWeight=True, allowPOS=('ns', 'n', 'vn', 'n')):
print(x, w)TextRank运行结果

比对词频统计结果

3 实体识别
3.1 日期实体识别
import re
from datetime import datetime,timedelta
from dateutil.parser import parse
import jieba.posseg as psg
UTIL_CN_NUM = {
'零': 0, '一': 1, '二': 2, '两': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9,
'0': 0, '1': 1, '2': 2, '3': 3, '4': 4,
'5': 5, '6': 6, '7': 7, '8': 8, '9': 9
}
UTIL_CN_UNIT = {'十': 10, '百': 100, '千': 1000, '万': 10000}
def cn2dig(src):
if src == "":
return None
m = re.match("\d+", src)
if m:
return int(m.group(0))
rsl = 0
unit = 1
for item in src[::-1]:
if item in UTIL_CN_UNIT.keys():
unit = UTIL_CN_UNIT[item]
elif item in UTIL_CN_NUM.keys():
num = UTIL_CN_NUM[item]
rsl += num * unit
else:
return None
if rsl < unit:
rsl += unit
return rsl
def parse_datetime(msg):
if msg is None or len(msg) == 0:
return None
try:
dt = parse(msg, fuzzy=True)
return dt.strftime('%Y-%m-%d %H:%M:%S')
except Exception as e:
m = re.match(
r"([0-9零一二两三四五六七八九十]+年)?([0-9一二两三四五六七八九十]+月)?([0-9一二两三四五六七八九十]+[号日])?([上中下午晚早]+)?([0-9零一二两三四五六七八九十百]+[点:\.时])?([0-9零一二三四五六七八九十百]+分?)?([0-9零一二三四五六七八九十百]+秒)?",
msg)
if m.group(0) is not None:
res = {
"year": m.group(1),
"month": m.group(2),
"day": m.group(3),
"hour": m.group(5) if m.group(5) is not None else '00',
"minute": m.group(6) if m.group(6) is not None else '00',
"second": m.group(7) if m.group(7) is not None else '00',
}
params = {}
for name in res:
if res[name] is not None and len(res[name]) != 0:
tmp = None
if name == 'year':
tmp = year2dig(res[name][:-1])
else:
tmp = cn2dig(res[name][:-1])
if tmp is not None:
params[name] = int(tmp)
target_date = datetime.today().replace(**params)
is_pm = m.group(4)
if is_pm is not None:
if is_pm == u'下午' or is_pm == u'晚上' or is_pm =='中午':
hour = target_date.time().hour
if hour < 12:
target_date = target_date.replace(hour=hour + 12)
return target_date.strftime('%Y-%m-%d %H:%M:%S')
else:
return None
#时间提取
def time_extract(text):
time_res = []
word = ''
keyDate = {'今天': 0, '明天':1, '后天': 2}
for k, v in psg.cut(text):
if k in keyDate:
if word != '':
time_res.append(word)
word = str((datetime.today() + timedelta(days=keyDate.get(k, 0))))
elif word != '':
if v in ['m', 't']:
word = word + k
else:
time_res.append(word)
word = ''
elif v in ['m', 't']:
word = k
if word != '':
time_res.append(word)
result = list(filter(lambda x: x is not None, [check_time_valid(w) for w in time_res]))
final_res = [parse_datetime(w) for w in result]
return [x for x in final_res if x is not None]
text1 = "我要住到明天下午三点"
print(text1, time_extract(text1), sep=':')
text2 = '预定28号的房间'
print(text2, time_extract(text2), sep=':')
text3 = '我要从26号下午4点住到11月2号'
print(text3, time_extract(text3), sep=':')
text4 = '我要预订今天到30日的房间'
print(text4, time_extract(text4), sep=':')
text5 = '今天是30号呵呵'
print(text5, time_extract(text5), sep=':')时间词性标注运行结果

机器学习方法在文本中的利用
机器学习概念与原理
相对比词性理解提升为认知性的理解
依赖指令的方法:通过一定的步骤来判别(无需数据)
依赖数据的方法(机器学习):
归纳、统计是核心
核心思想:走的人(数据)多了(训练),便有了路(模型)
相关性而非因果性
冰激凌和犯罪率高度相关而非因果
训练过程
求解特定函数的参数
弊端:无因果关系、不可解释性
目标函数loss决定方向,反向传播实际执行
sklearn简介
sklearn中的datasets数据集 - 知乎 (zhihu.com)
混淆矩阵定义
混淆矩阵Confusion Matrix - 知乎 (zhihu.com)

TP(True Positive):将正类预测为正类数,真实为0,预测也为0
FN(False Negative):将正类预测为负类数,真实为0,预测为1
FP(False Positive):将负类预测为正类数, 真实为1,预测为0
TN(True Negative):将负类预测为负类数,真实为1,预测也为1

ROC曲线:真正率/假正率
一个随机分类的模型:真正率 = 假正率,模型不关心实际的类型
朴素贝叶斯分类器
垃圾邮件分类
文本学习
数据分配
训练集(训练集、验证集)+测试集
验证集的作用:验证训练集中上模型的参数是否最优
第5章 人工神经网络
1epoch:一次完整的训练

MLP前馈神经网络
前向传播:激活函数
反向传播:目标函数、梯度下降
BP网络:通过BP算法进行优化得到的MLP网络
神经网络1:多层感知器-MLP - 知乎 (zhihu.com)
梯度下降的思想:局部最优不等于全局最优
demo!手写数字模型
1. model.compile编译函数参数:
optimizer = 'adam' 随机梯度下降
learning_rate = 0.001
loss
metrics = ['accuracy'] # 评估指标:精确率
2. model.fit参数
batch
epoch
= 1 # 显示所有的调试信息
第6章 词嵌入与词向量
1. 去停用词
2. One-Hot编码
(1)无法得出词之间的联系,每个词都是独立的
(2)会造成梯度灾难
3. 词嵌入(Word-Embedding)
(1)考虑上下文
(2)维度为128或256
(3)Word2Vec
(4)基于词向量的相似度分析
(5)类比推理

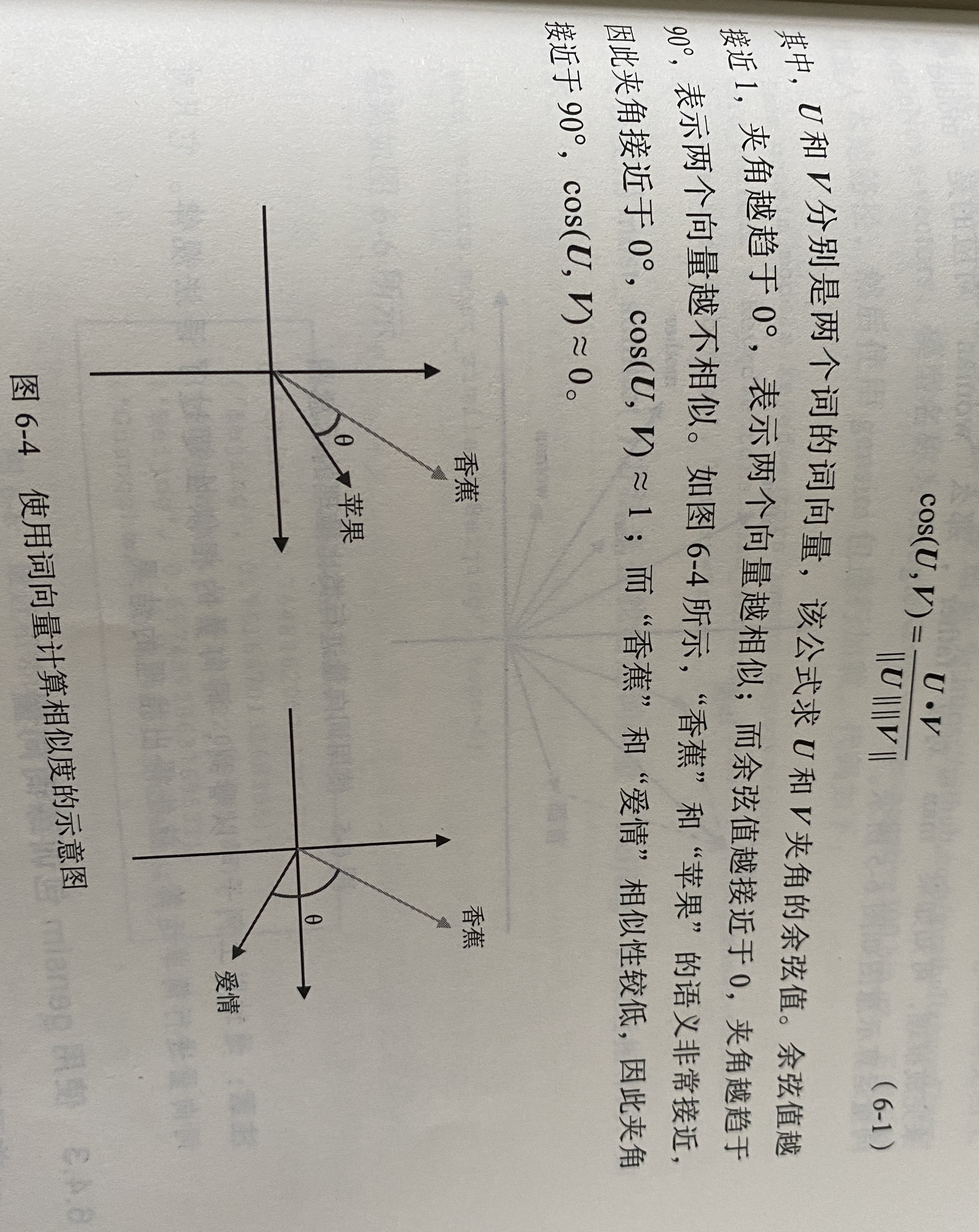
基于词向量的相似度分析
















 2551
2551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









