








import torch
# 显示是否使用GPU
print(torch.cuda.is_available())
# 查看成员以及手册
print(dir(torch))
print(dir(torch.AVG)) # =>abc
print(help(torch.AVG))
# pytorch的加载数据方法:
# 一、 Dataset:提供一种方式及其label
# 二、Dataloader:为网络提供不同的数据形式二、数据集加载 Dataset
from torch.utils.data import Dataset
import cv2
from PIL import Image
import os
# dataset代码实战
class MyData(Dataset):
def __init__(self, root_dir, label_path):
# 初始化操作
self.root_dir = root_dir
self.label_path = label_path
self.img_dir = os.path.join(self.root_dir, self.label_path)
self.img_path_list = os.listdir(self.img_dir)
print(self.img_path_list)
def __getitem__(self, index):
# 获取数据集元素的信息
img_path = self.img_path_list[index]
print("getitem:",img_path)
img = Image.open(os.path.join(self.img_dir ,img_path))
label = self.label_path
return img, label
def __len__(self):
# 返回长度
return len(self.img_path_list)
ant_dataset = MyData(r"E:\\data\\hymenoptera_data\\train","ants") # dataset
bee_dataset = MyData(r"E:\\data\\hymenoptera_data\\train","bees") # dataset
# img, label = ant_dataset[0]
# # 可以把dataset当成数组的新式,每次都会执行__getitem__函数获取对应index的信息:img、label
# print(img, label)
# img.show()
# 数据集拼接操作,两个数据集相加操作:
train_dataset = ant_dataset+bee_dataset
print(len(train_dataset),len(ant_dataset),len(bee_dataset)) 三、tensorboard的使用
from torch.utils.tensor
writer = SummaryWriter("logs2") # 自动创建
图片添加:writer.add_image("Tensor_img",transe_img )
低纬数据:writer.add_scalar("y=x",2*i,i)
# Tensorboard的使用:训练可视化:loss
# 以前只能在tf中使用
# 图像变化,transform的使用
from torch.utils.tensorboard import SummaryWriter # 写入、可视化操作(pip install )
writer = SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=x",2*i,i) #低纬数据
writer.close()
from torch.utils.tensorboard import SummaryWriter
# 创建实例化对象、并且指定保存文件路径(自动创建文件夹)
writer = SummaryWriter("logs2") # 创建保存文件
transe_img = tensor_trans(img)
print(transe_img)
# 添加
writer.add_image("Tensor_img",transe_img )
# 关闭
writer.close()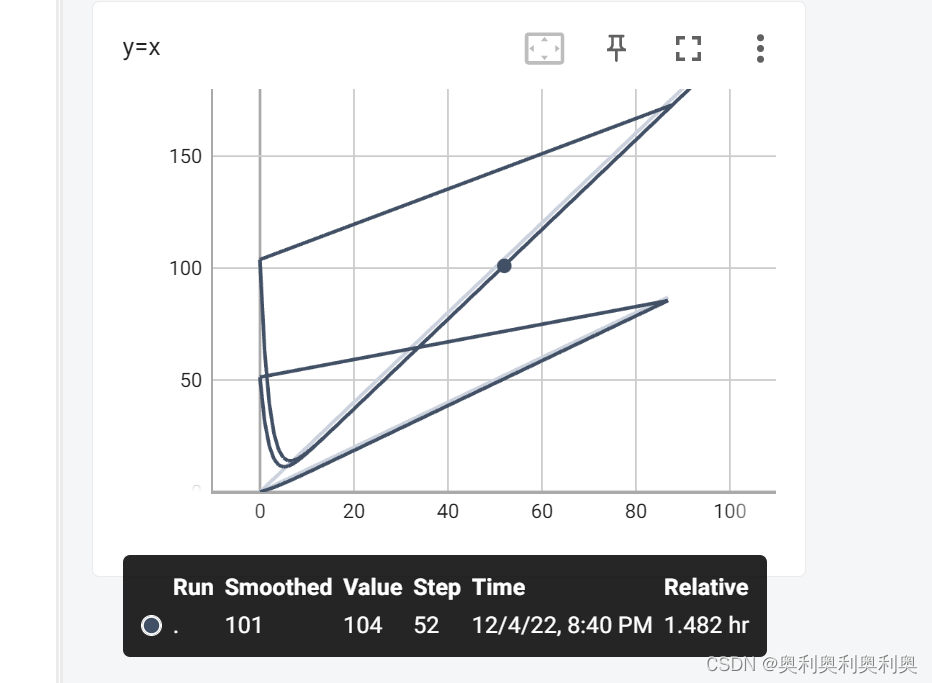

四、transforms工具包(浏览)、tensor的属性
from torchvision import transforms
# 一、 ctrl+tal=7: 显示脚本所有的内容
# 查看transforms.py、工具箱:totensor、resize
# 二、 transforms.ToTensor
from PIL import Image
img_path = "E:\\data\\hymenoptera_data\\train\\ants\\69639610_95e0de17aa.jpg"
img = Image.open(img_path)
print(img) # <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x333 at 0x1E2854F3D08>
# img.show()
tensor_trans = transforms.ToTensor()
print(tensor_trans) #ToTensor() 对象
transe_img = tensor_trans(img) # 转换
print(transe_img) # tensor([[[0.9294, 0.933……
print(transforms.ToTensor()(img)) # 等同上面的过程transform(ctrl+ Alt +7)显示的脚本属性功能

ipython运行后显示的tensor属性:包含grad等梯度下降所需的属性

五、 transforms工具箱的进一步了解
*补充知识(内置函数__call__():可以利用 对象名() 调用) tansforms实现变化的本质就是调用__call__()方法
class Person:
def __call__(self, name):
print("__call__","hello",name)
def hello(self,name):
print("hello",name)
p = Person()
p("hdl") #可以利用这种形式调用—__call__
p.hello("hdl2")Compose源码截取:transforms together(操作的集合)
class Compose(object):
"""Composes several transforms together.
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])
"""归一化操作:Normal
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
# 提前准备PIL图片、SummaryWriter文件
img_path = "E:\\data\\hymenoptera_data\\train\\ants\\69639610_95e0de17aa.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs4")
# 定义操作
T1_Totensor = transforms.ToTensor()
T2_Normalize1 = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
T3_Normalize2 = transforms.Normalize([3,4,5],[3,4,5])
T4_Normalize3 = transforms.Normalize([7,4,9],[1,3,6])
# 实现操作、获取图片
tensor_img = T1_Totensor(img)
normal_img1 = T2_Normalize1(tensor_img)
normal_img2 = T3_Normalize2(tensor_img)
normal_img3 = T4_Normalize3(tensor_img)
# 写入文件:add_image(tag, img_tensor, global_step=None)
writer.add_image("tensor_img", tensor_img)
writer.add_image("normal_img", normal_img1,1)
writer.add_image("normal_img", normal_img2,2)
writer.add_image("normal_img", normal_img3,3)normal_img可以看出图片变化情况

pycharm取消大小写匹配
Transforms.Resize((512,512)) #PIL->PIL
# Resize操作
T5_Resize512 = transforms.Resize((512,512)) # PIL -> PIL
print(img.size)
img512 = T5_Resize512(img)
print(img512.size)
tensor_img512 = T1_Totensor(img512)Transforms.Compose()
# Compose操作!
T6_Compose = transforms.Compose([T5_Resize512,T1_Totensor])
imgCompose = T6_Compose(img)
print(imgCompose.shape)
# 一步
print(transforms.Compose([T5_Resize512,T1_Totensor])(img).shape) #torch.Size([3, 512, 512])Transforms.RandomCrop 随机裁剪
# 随机裁剪
T7_RandomCrop = transforms.RandomCrop(50)
T8_RandomCropWH = transforms.RandomCrop((50,100))
T9_ComT7 = transforms.Compose([T7_RandomCrop,T1_Totensor])
T10_ComT8 = transforms.Compose([T8_RandomCropWH,T1_Totensor])
for i in range(10):
img_crop = T9_ComT7(img)
writer.add_image("crop",img_crop,i)
for i in range(10):
img_crop = T10_ComT8(img)
writer.add_image("crop2",img_crop,i) 
六、 datasets与transforms的联合使用
torchvision模块介绍(包含dataset、transforms)
# torchvision的各种模块
from torchvision import transforms # 图像操作
from torchvision import datasets # 数据集
from torchvision import models # 常见的神经网络,有的预训练好了
from torchvision import ops # 少见的操作
from torchvision import utils # 常见的小工具1. torchvision.datasets.CIFAR10 数据集的获取
import torchvision
# 获取dataset里面的数据集
train_set = torchvision.datasets.CIFAR10("./dataset",train=True,download=True) # 自动下载数据集
test_set = torchvision.datasets.CIFAR10("./dataset",train=False,download=True)
img, target = train_set[0]
print("shape",len(train_set)) # 50000
print("shape",len(test_set)) # 10000
# 无trainfrom:<PIL.Image.Image image mode=RGB size=32x32 at 0x223B27FDB88> 6
# 有trainfrom:tensor([[[0.2314,…… 6
# 将数据集写入tensorboard
writer = SummaryWriter("logs4")
for i in range(10):
img, target = train_set[i]
writer.add_image("dataset1",img,i)
dataset.CIFAR10参数:
- 1. 自动创建文件夹
- 2. 是否是训练集
- 3.是否从网上下载(先判断是否存在,可以点击函数进去查看下载地址)
- 4. transform:获取数据的批量操作

七、 DataLoader(torch.utils.data)
实现批量抽取:
img, target = train_set[0],
img1, target1 = train_set[1],
img2, target2 = train_set[2],
img3, target3 = train_set[3]
打包返回
imgs = img,img1,img2,img3
targets = target, target1, target2, target3
# dataloader: 从dataset取数据的工具,可迭代对象
from torch.utils.data import DataLoader
test_Loader = DataLoader(dataset=test_set, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
i = 0
for data in test_Loader:
imgs, targets = data # torch.Size([4, 3, 32, 32]) tensor([5, 6, 2, 8])
writer.add_images("loader1", imgs, i) # 添加多张图片:add_images
i+=1
print("第{}次迭代".format(i)) # 157次迭代,157*64=10000
writer.close()


参数介绍:
- dataset:dataset对象,从里面取数据
- batch_size:一次取多少张
- shuffle(False):是否打乱
- num_workers(0):多线程,默认为0,仅主线程工作
- drop_last(Ture):最后不满batch_size的样本是否丢弃
分两批取数据
for epoch in range(2):
i = 0
for data in test_Loader:
imgs, targets = data # torch.Size([4, 3, 32, 32]) tensor([5, 6, 2, 8])
writer.add_images("loader:Epoch_{}".format(epoch), imgs, i) # 添加多张图片:add_images
i+=1

八、torch.nn(Netual Net):卷积池化
nn各模块介绍
略
nn.Module第一个网络
import torch
from torch import nn
class Net1(nn.Module):
def __init__(self):
super(Net1, self).__init__()
# 通常在这里定义变化的方法
def forward(self,input):
# 可使用 output = 网络对象名(input)
print("forward run")
output = input+1
return output
n1 = Net1()
x = torch.tensor(1.0) # tensor(1.)
o = n1(x) #tensor(2.)
print(o)卷积操作演示:torch.nn.functional.conv2d
(用于2维数据,conv1d,conv3d不常用)
import torch.nn.functional as F
input = torch.tensor([
[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]
])
kernel = torch.tensor([
[1,2,1],
[0,1,0],
[2,1,0]
])
print(input.shape)
print(kernel.shape)
input = torch.reshape(input, [1,1,5,5])
kernel = torch.reshape(kernel, (1,1,3,3))
print(input.shape)
print(kernel.shape)
import torch.nn.functional as F
output = F.conv2d(input, kernel, stride=1)
print(output)
'''tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])'''
output = F.conv2d(input, kernel, stride=2)
print(output)
'''tensor([[[[10, 12],
[13, 3]]]])'''
output = F.conv2d(input, kernel, stride=1, padding=1)
print(output)
'''tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])'''
卷积类:torch.nn.Conv2d
Conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0,dilation=1,groups=1,bias=True,padding_mode="zeros")
# in_channels=3,
# out_channels=6,
# kernel_size=3,
# stride=(1),
# padding=(0),
# dilation=(1),
# groups=(1),
# bias=(True),
# padding_mode=("zeros")搭建卷积(torch.nn.Conv2d)网络
import torch
import torchvision
from torch import nn
import torchvision
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Net2_conv(nn.Module):
def __init__(self):
super(Net2_conv, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1,padding=0)
def forward(self, input):
x = self.conv1(input)
return x
n2 = Net2_conv()
print(n2)
writer = SummaryWriter("logs5")
step = 0
for data in dataloader:
imgs, targets = data
output = n2(imgs) # torch.Size([64, 3, 32, 32]) -> torch.Size([64, 6, 30, 30])
# torch.Size([64, 6, 30, 30]) -》 torch.Size([-1, 3, 30, 30])
output = torch.reshape(output, (-1,3,30,30)) # torch.Size([128, 3, 30, 30])
writer.add_images("input",imgs,step)
writer.add_images("output",output,step) # 卷积后的图像:超过3个通道不知道怎么显示:尺寸变换
step = step+1注意
- 搭建卷积层的Conv2d来自 torch.nn,而上一个实例(基于过程的卷积变换)的conv2d来自torch.nn.functional
- (91条消息) Pytorch中torch.nn.conv2d和torch.nn.functional.conv2d的区别_那记忆微凉的博客-CSDN博客_nn.functional.con2d
- tensorboard显示的图片只能是三通道的,超过的可以通过torch.reshape变换

可以看出相邻两列的图片来自同一个卷积源
最大池化(下采样)类:torch.nn.MaxPool2d
pool1 = MaxPool2d(kernel_size=3,stride=1,padding=0,dilation=1,return_indices=False)
# kernel_size=3,
# stride=1, 默认和kernel_size一样
# padding=0,
# dilation=1, 空洞卷积,可以不设置
# return_indices=False 用到少,可以不了解
# ceil_mode=False ceil 或者 floor 模式ceil_mode区别与padding的区别
print("---ceil mode---")
input = torch.tensor([
[1,2,0,3,1],
[0,1,2,3,1],
[1,2,10,0,0],
[5,2,3,1,1],
[2,1,0,1,1]
],dtype=torch.float)
input = torch.reshape(input,(-1,1,5,5))
print(input)
pool3 = MaxPool2d(kernel_size=3,stride=3,padding=0)
pool4 = MaxPool2d(kernel_size=3,stride=3,padding=0,ceil_mode=True) # ceil_mode补在后面
pool5 = MaxPool2d(kernel_size=3,stride=3,padding=1) # padding补在前面
print(pool3(input))
print(pool4(input))
print(pool5(input))
'''
---ceil mode---
tensor([[[[ 1., 2., 0., 3., 1.],
[ 0., 1., 2., 3., 1.],
[ 1., 2., 10., 0., 0.],
[ 5., 2., 3., 1., 1.],
[ 2., 1., 0., 1., 1.]]]])
tensor([[[[10.]]]])
tensor([[[[10., 3.],
[ 5., 1.]]]])
tensor([[[[ 2., 3.],
[ 5., 10.]]]])'''MaxPool封装类且显示
代码略

马赛克效果
卷积、池化实例
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d # ide不会自动跳出来
from torch.nn import functional as F # 网络函数
pool2 = MaxPool2d(kernel_size=3,stride=2,padding=0)
Conv2 = Conv2d(in_channels=2,out_channels=6,kernel_size=3,stride=1,padding=1)
input_2c = torch.tensor([[
[1,9,4,3,1],
[0,1,3,3,1],
[1,2,4,1,1],
[5,9,3,1,1],
[2,1,3,1,2]
],[
[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]
]],dtype=torch.float)
print(input_2c.shape)
# 进行尺寸变换
input_2c = torch.reshape(input_2c, (-1,2,5,5))
print(input_2c.shape)
# 卷积
print(input_2c)
c1 = Conv2(input_2c)
print(c1)
# 池化
p2 = pool2(c1)
print(p2)
'''
torch.Size([2, 5, 5])
torch.Size([1, 2, 5, 5])
tensor([[[[1., 9., 4., 3., 1.],
[0., 1., 3., 3., 1.],
[1., 2., 4., 1., 1.],
[5., 9., 3., 1., 1.],
[2., 1., 3., 1., 2.]],
[[1., 2., 0., 3., 1.],
[0., 1., 2., 3., 1.],
[1., 2., 1., 0., 0.],
[5., 2., 3., 1., 1.],
[2., 1., 0., 1., 1.]]]])
tensor([[[[-2.2907, 0.6559, -0.7646, -0.7562, -1.1576],
[-0.8386, -2.6403, -0.5418, -1.7951, -1.3938],
[ 1.9008, 0.4555, -1.8671, -1.0641, -0.2608],
[-2.1864, -1.9413, -2.5838, -1.4475, -0.2992],
[-2.5110, -3.4703, 0.1753, -1.4927, -0.5876]],
[[ 1.0946, -0.7269, 0.1711, 1.1262, 0.7737],
[-1.4987, 3.0075, 3.5465, 2.2300, 2.0772],
[ 2.1894, 2.1974, 1.6480, 1.8914, 1.7143],
[ 1.1717, 0.0812, 2.0946, 2.1961, 1.1034],
[-0.6496, 3.4469, 2.4359, 1.2677, 0.4762]],
[[ 0.7047, 0.9810, 1.5999, -0.1848, 0.3020],
[-0.6710, -1.8417, -0.7621, 0.7972, 1.0421],
[-1.2203, -1.5126, -0.5202, 0.6926, 0.1244],
[ 0.0421, 0.9590, 0.9514, 0.9153, -0.2190],
[-0.6120, -0.1753, 1.3838, 0.7169, 0.4746]],
[[ 0.8233, 1.0168, -0.3366, -0.1060, -1.0978],
[ 1.2184, -0.8210, -0.1070, -1.3816, -1.4632],
[ 0.7650, 0.3353, -1.7909, -2.3939, -1.3328],
[ 2.3357, 0.4226, -0.9722, -1.4251, -0.3074],
[ 0.8805, -1.8809, -1.5423, -0.6330, -0.5163]],
[[ 0.7763, 0.3317, 1.8480, 0.8667, 1.4605],
[-1.3310, -1.9593, -0.8368, 0.2694, 0.5210],
[ 0.7591, 1.2289, -0.1031, -0.2403, -0.5819],
[ 0.7325, 1.6032, 0.9441, 0.2003, 0.3054],
[-1.7175, -1.7592, -1.7294, -0.0057, 0.1171]],
[[ 0.9174, 1.6437, -0.3393, 0.6732, 0.8526],
[ 1.0696, 0.1523, 1.6466, 2.0369, 1.3866],
[ 1.9595, 1.3317, 3.1937, 1.3519, 0.8722],
[ 2.4039, 2.7570, -0.1210, 1.7176, 0.0777],
[ 1.3237, 1.5973, 1.6101, 1.0416, 0.5371]]]],
grad_fn=<MkldnnConvolutionBackward>)
tensor([[[[ 1.9008, -0.2608],
[ 1.9008, 0.1753]],
[[ 3.5465, 3.5465],
[ 3.4469, 2.4359]],
[[ 1.5999, 1.5999],
[ 1.3838, 1.3838]],
[[ 1.2184, -0.1060],
[ 2.3357, -0.3074]],
[[ 1.8480, 1.8480],
[ 1.6032, 0.9441]],
[[ 3.1937, 3.1937],
[ 3.1937, 3.1937]]]], grad_fn=<MaxPool2DWithIndicesBackward>)
'''
padding层:略、在maxpool层可以实现
九、非线性激活
激活函数的意义:提高网络的泛化能力……
ReLU函数

Sigmoid函数

import torch
from torch import nn
from torch.nn import ReLU
input = torch.Tensor([[1,-0.5],[-1,3]])
input = torch.reshape(input,(-1,1,2,2))
print(input.shape)
class ReLU_Demo(nn.Module):
def __init__(self):
super(ReLU_Demo, self).__init__()
self.relu = ReLU()
def forward(self,input):
x = self.relu(input)
return x
print(r(torch.tensor(-10.0)))
r = ReLU_Demo()
o = r(input)
print(o)
'''
torch.Size([1, 1, 2, 2])
tensor([[[[1., 0.],
[0., 3.]]]])
tensor(0.)
'''
class ReLU_Demo(nn.Module):
def __init__(self):
super(ReLU_Demo, self).__init__()
self.relu = ReLU()
def forward(self,input):
x = self.relu(input)
return x
class Sigmoid_Demo(nn.Module):
def __init__(self):
super(Sigmoid_Demo, self).__init__()
self.sig = Sigmoid()
def forward(self ,input):
x = self.sig(input)
return x
r = ReLU_Demo()
s = Sigmoid_Demo()
from torchvision import datasets
import torchvision
# 获取数据
dataset = datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
datalo = DataLoader(dataset=dataset, batch_size=64,shuffle=False)
writer = SummaryWriter("sigmoid")
step = 0
for data in datalo:
imgs, targets = data
simgs = s(imgs)
rimgs = r(imgs)
writer.add_images("scr", imgs, step)
writer.add_images("sigmoid", simgs, step)
writer.add_images("Relu", rimgs, step)
step = step + 1
writer.close()















 3210
3210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









