






如图所示 目前运行了一个Python的终端,对应的是其中某些个Py文件
目前运行了一个Python的终端,对应的是其中某些个Py文件
现在在这个终端运行时,再让它同时运行别的Py文件
操作如下
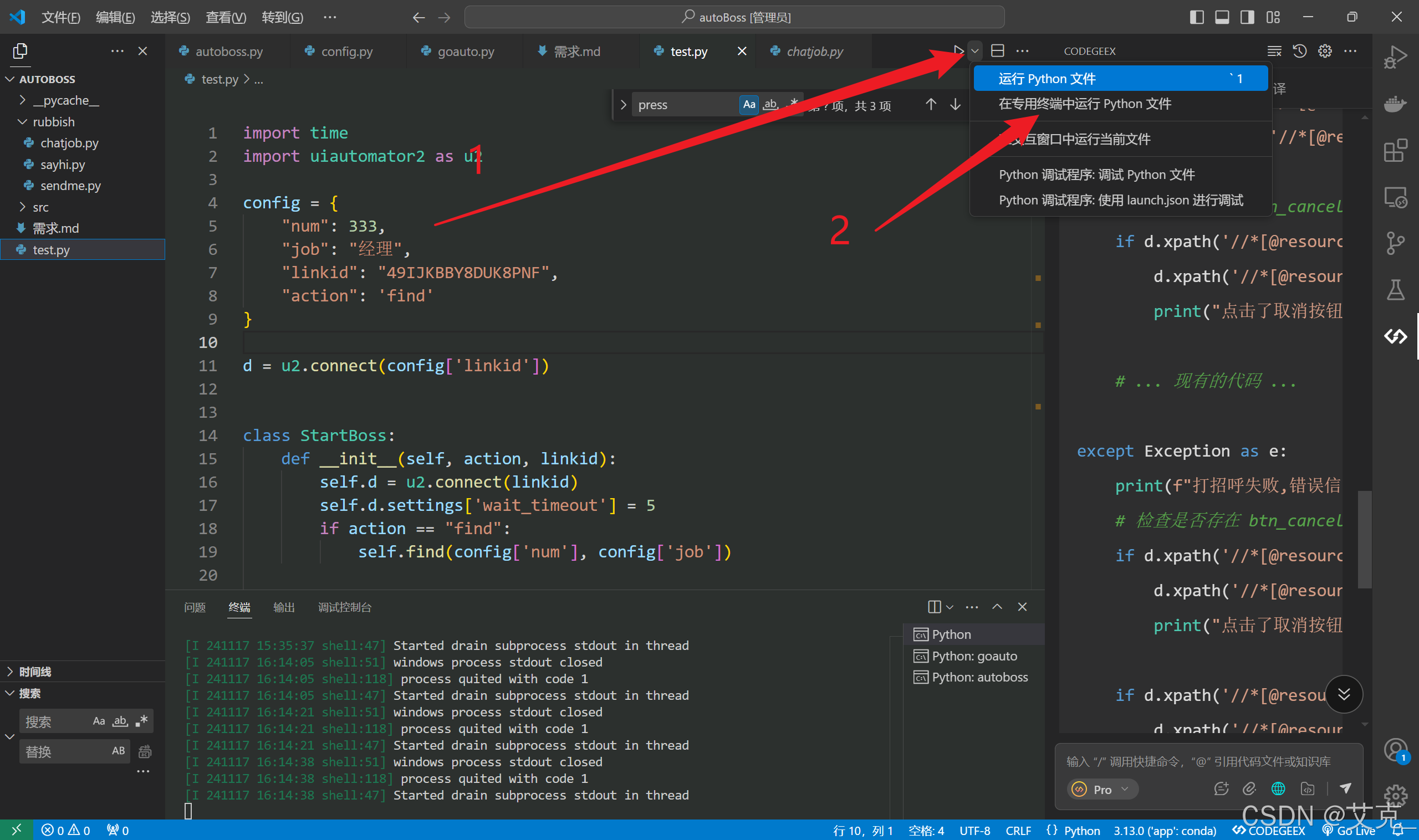
点击右上角运行三角符号后点击2箭头所指即可
总结:
想多加哪个py文件就点击哪个文件的专用终端运行
如图所示目前运行了一个Python的终端,对应的是其中某些个Py文件
现在在这个终端运行时,再让它同时运行别的Py文件
操作如下
点击右上角运行三角符号后点击2箭头所指即可
总结:
想多加哪个py文件就点击哪个文件的专用终端运行
 860
3026
860
3026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























