










我,完全的文科生,当时学python爬虫 完全摸不到头绪,各种资料一顿翻,一顿学,天天面对那个小黑框敲来敲去,很无聊,最后差点因为没有成就感而放弃!
直到有一天,看到了一个极简的爬虫项目,代码不超过10行,我照着敲了敲,一运行,就能迅速出结果,久违的新鲜感又回来了
因为怕忘了,就拿张纸,把代码一句一句的抄写下来,然后反复背诵,背写,背写敲
并给朋友一句句的解释每个代码是做什么的,原理是什么,为什么要这么做
反复练习,反复敲,时间长了,就形成肌肉记忆了,只要是浏览器能看到的,差不多就都能通过网页分析,然后就能抓下来,以后面试找工作也是一个非常好的加分亮点!
然后就开始学习抓取手机app中的内容,比如抓取发小曾经发过的朋友圈内容啥的,非常有意思
总之,爬虫基础打牢,遇到其他网络相关的问题,完全就不是问题了,这是万里python 长征的第一步,也是非常重要的一步!
下面是为了题主,亲自写的一个小教程,希望对你有帮助!
其实爬虫原理很简单,无非就是找到目标网站,把看到的内容抓下来嘛!
那我们设想个场景,当看到某不可描述的网站有很多好看的小姐姐,想把他们的美照都存下来,以供以后做电脑和手机壁纸怎么办?

一般小白会做以下操作:
- 打开某网站
- 找到好看的小姐姐照片
- 一张张的,右键 -> 图片另存为 -> 选择一个文件夹 -> 给照片取个名字 -> 存储,以此往复,当有上万张照片时,这样一顿操作下来,没有个几天是搞不定的,枯燥又无聊,估计都会得鼠标手了
那么学会 Python 后怎么做呢?
- 分析某网站,寻找规律,确认路径
- 撰写 Python代码
- 运行写好的Python文件,几分钟就搞定了
如果题主是完全的爬虫小白,但是了解一些 Python 和 HTML 基础语法,那也是极好的
所以,引用一句 Python名言,来表达我的观点:

好了,下面就开始严肃了,想让我放不可描述的网站是不可能的,对,我摊牌了,我说的网站就是百度老师

还是严肃一些吧,现在百度广告太多,有些小白同学难免会误入百度的深坑,如果大家没有FQ的条件的话,我还是推荐使用必应国际版,至少解决一些日常技术问题,及答案的精准性上会比百度强太多!

用它搜技术问题!
接下来设立个目标:获取 必应关于「如何入门 Python 爬虫?」的第一页的搜索结果标题和网址。
p.s.新手就别着急那个网站了,咱们先学走路,再学开车,你会了这个,那些普通的静态图片网站,你也就会了,原理都差不多的
回到正题,一般的小爬虫,可以分为三个步骤 :
- 查找HTML标签里包含的我们所需要的路径信息
- 在 python 程序里获取 百度的 html 响应
- 根据第一步,按照路径,从html 响应中提取所需的内容。
是不是很简单?听不懂也没关系,跟着我一步步做就完事了
首先,爬取的网址是这个,不要弄错了
如何入门 python 爬虫? - 国际版 Bing
第 1 步:找到目标内容的路径信息
打开谷歌浏览器,把上面这个网址打开,然后在界面空白的地方点击鼠标右键,选择最后那个「检查」。用控制面板上的小检查按钮,找到我们想要的 html 标签信息。

现找到每一个条目的路径:li.b_algo

找到目标标题和链接

复制对应的路径
1.1 由上图我们可以得到:
所有内容标题的路径:h2
所有内容链接的路径:cite
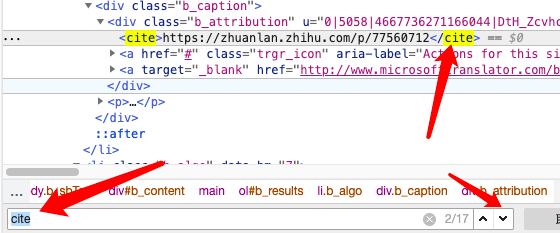
通过此查找,来检查,目标内容是否是想要的
第 2 步: 用Python来模拟,对必应的请求和响应
Python 中有许多方法可以做到模拟的网络请求,我一般是使用最人性化的Python包- Requests
p.s.如果获取的内容链接为空,那就是必应限制了,在 Get的时候,添加一个User-agent就可以了
#导入网络请求包
import requests
#模拟请求刚才的必应网址
response = requests.get('https://www.bing.com/search?q=%E5%A6%82%E4%BD%95%E5%85%A5%E9%97%A8+python+%E7%88%AC%E8%99%AB%3F')
#获取必应所返回的原始Html内容
htmlcontent = response.content
第 3 步:从原始 html 内容中提取所需信息
那么如何提取信息呢?Python已经给你准备好了相应的包了 - BeautifulSoup4
按照国际惯例,安装一下
pip3 install beautifulsoup4
htmlcontent 变量包含的是最原始的HTML,也就是文本格式,Python不能直接认识它,也不能直接用步骤1里的路径去找到目标的信息, BeautifulSoup帮我们解析了这个文本并解决了这个问题,这样Python通过它就可以认识路径了,就能实现我们的目标了
#导入BeautifulSoup包
from bs4 import BeautifulSoup
### 创建一个解析 ###
results_soup = BeautifulSoup(htmlcontent,'html.parser')
### 找到所有的条目,由于是li标签,且样式是b_algo###
search_results = results_soup.find_all("li",{"class":"b_algo"})
### 同样的找到条目下对应的标题和链接,标题是h2标签,链接是cite标签 ###
title_list = []
url_list = []
for result in search_results:
title_list.append(result.find('h2').text)
url_list.append(result.find('cite').text)
### 保存到CSV文件###
import pandas as pd
pd.DataFrame({'标题':title_list, '链接':url_list}).to_csv('如何入门 python 爬虫?-必应.csv')
输出结果:

以上,这个爬出来的结果表,对就可以进一步回答你的提问了,哈哈哈
最后呢,想下载图片怎么办?
试试下面这个下单个图片的代码,你自己获取图片链接,组成一个图片链接列表,然后循环下载就可以了
import requests
url = "http://craphound.com/images/1006884_2adf8fc7.jpg"
#获取图片相应
response = requests.get(url)
#判断一下状态码
if response.status_code == 200:
# 把图片内容写入文件
with open("/Users/apple/Desktop/sample.jpg", 'wb') as f:
f.write(response.content)
总之,学习Python爬虫还是要项目驱动的去反复练习,才能深入理解掌握,才能在解决实际问题上做到游刃有余
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









