










前言
简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML、JS、CSS代码返回给浏览器,这些代码经过浏览器解析、渲染,将丰富多彩的网页呈现我们眼前;
博主今天有个小目标—带领大家正式入坑爬虫!
想要学习爬虫却一直迟迟不敢下手,或者对爬虫感兴趣想要好好学一学这门技术的童鞋们,欢迎入坑!

1.爬虫是什么
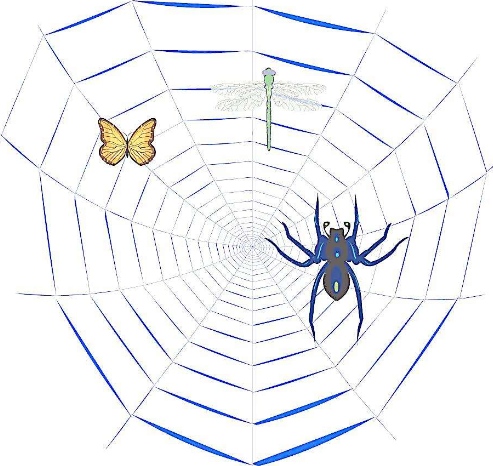
如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛;
沿着网络抓取自己的猎物(数据)爬虫指的是:向网站发起请求,获取资源后分析并提取有用数据的程序;
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用;
2.爬虫的应用
- 搜索引擎
百度、谷歌等搜索引擎都是基于爬虫技术
(PS:爬虫大佬)
- 采集数据

-
模拟操作
爬虫也被广泛用于模拟用户操作,测试机器人,灌水机器人等。
-
软件测试
爬虫之自动化测试虫师
虫师
-
网络安全
短信轰炸
web漏洞扫描
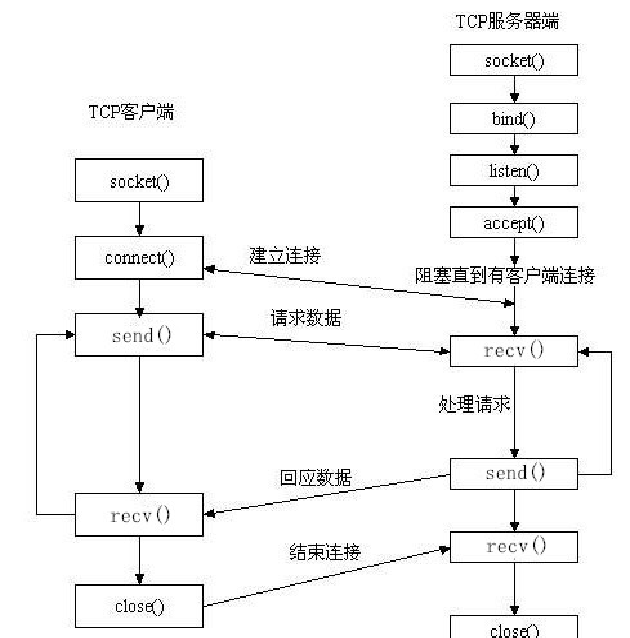
3.爬虫的基本流程
用户获取网络数据的方式:
方式1:浏览器提交请求—>下载网页代码—>解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2;
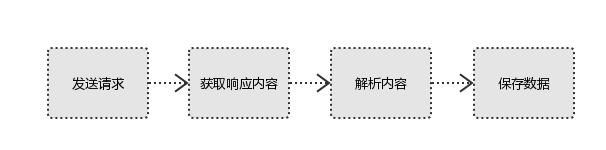
1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)
文件

4.http协议 请求与响应
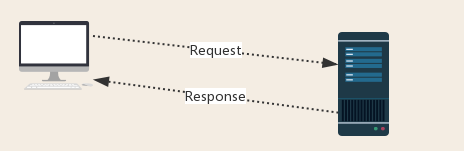
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
5.爬虫实例
利用socket下载一张图片
- socket学习
socket国外翻译为插座;同时,由于其具备了“套接"和“字"的概念,所以又称为套接字。
知识补给站
知识补给站:(混个眼熟就行了!)
- Socket是一种进程间通信机制提供一种供应用程序
- 访问通信协议的操作系统调用,使得网络读写数据
- 和读写本地文件一样容易;Socket是一序列的“指令” ;
- 已经具备了“套接”(建立网络通讯或进程间通讯)和“字”(可交互的有序指令串)的概念。
(1)使用socket简单建造一个服务端:
import socket# 服务器对象server = socket.socket()'''等同于:server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)socket.AF_INET:使用IPV4;socket.SOCK_STREAM:创建一个socket套接字。'''
# 1.绑定服务器server.bind(("0.0.0.0",8800)) #0.0.0.0是允许所有人来访问;8800是端口号
# 2.监听server.listen(5)
while True: # 3.等待连接 # accept是一个阻塞的方法(你不来我就不动!),等待连接,每建立一个连接就会创建一个单独的通道。# conn:通道参数;addr:通道地址。conn,addr=server.accept()
# 4.接收数据 data=conn.recv(1024) print(data)
response="HTTP/1.1 200 OK\r\nContent-Type: text/html;charset=utf-8;\r\n\r\n我很帅!"
# 5.发送数据 conn.send(response.encode()) print("已经响应")
# 6.关闭server.close()
在本地浏览器中输入:127.0.0.1:8800即可访问到此服务端:
(2)使用socket简单建造一个客户端:
(爬取百度首页整个界面)
import socket
# 建立服务器对象 通过打印这个client服务器对象可知:默认使用的是IPV4,协议是TCP。
client=socket.socket()
# 1.建立连接
client.connect(("www.baidu.com",80))
# 构造请求报文
data=b"GET / HTTP/1.1\r\nHost: www.baidu.com\r\n\r
# 2.发送请求
client.send(data)
res=b""
# 3.接收数据
temp=client.recv(4096)
while temp:
print("*"*50)
res += temp
temp = client.recv(4096)
print(temp.decode())
# 4.断开连接
client.close()
2.实战:使用socket来爬取一张漂亮MM的图片:
我们来爬爬搜狗
(1)首先分析网页
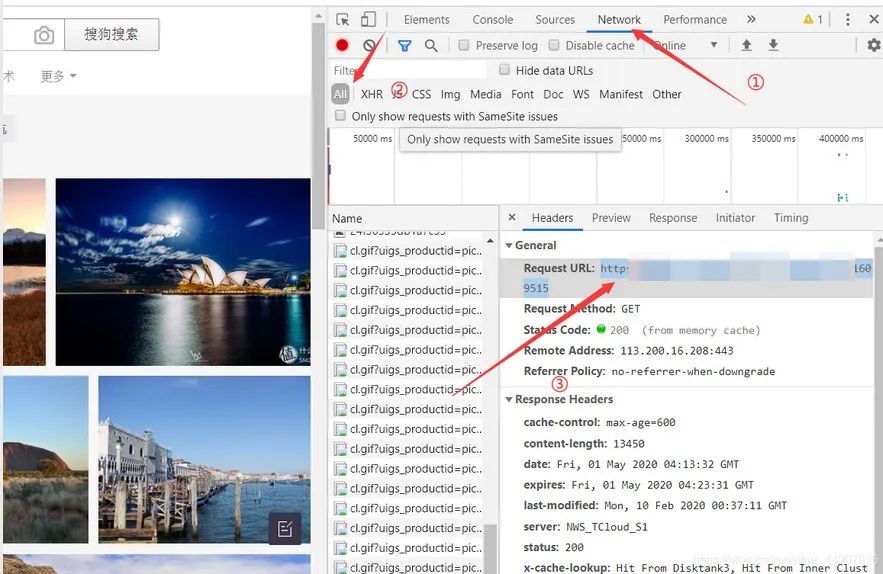
而我们要爬取的图片的URL就在头信息里的Request URL中。CV大法即可!
上述源码放在百度云盘上了需要可以微信扫描下方CSDN官方认证二维码免费领取

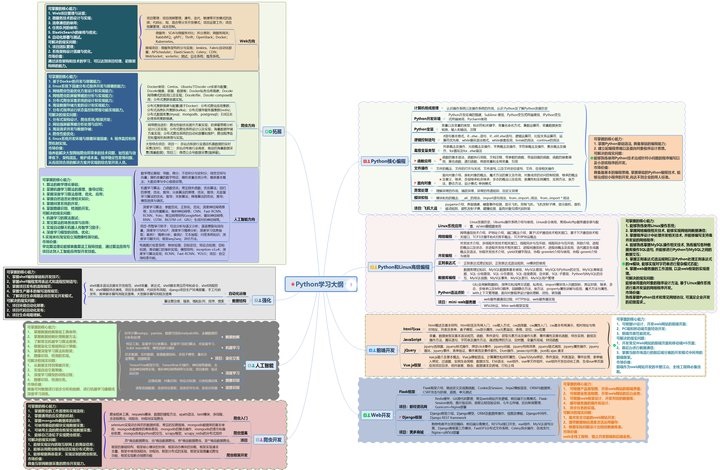
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具

三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、python副业兼职与全职路线
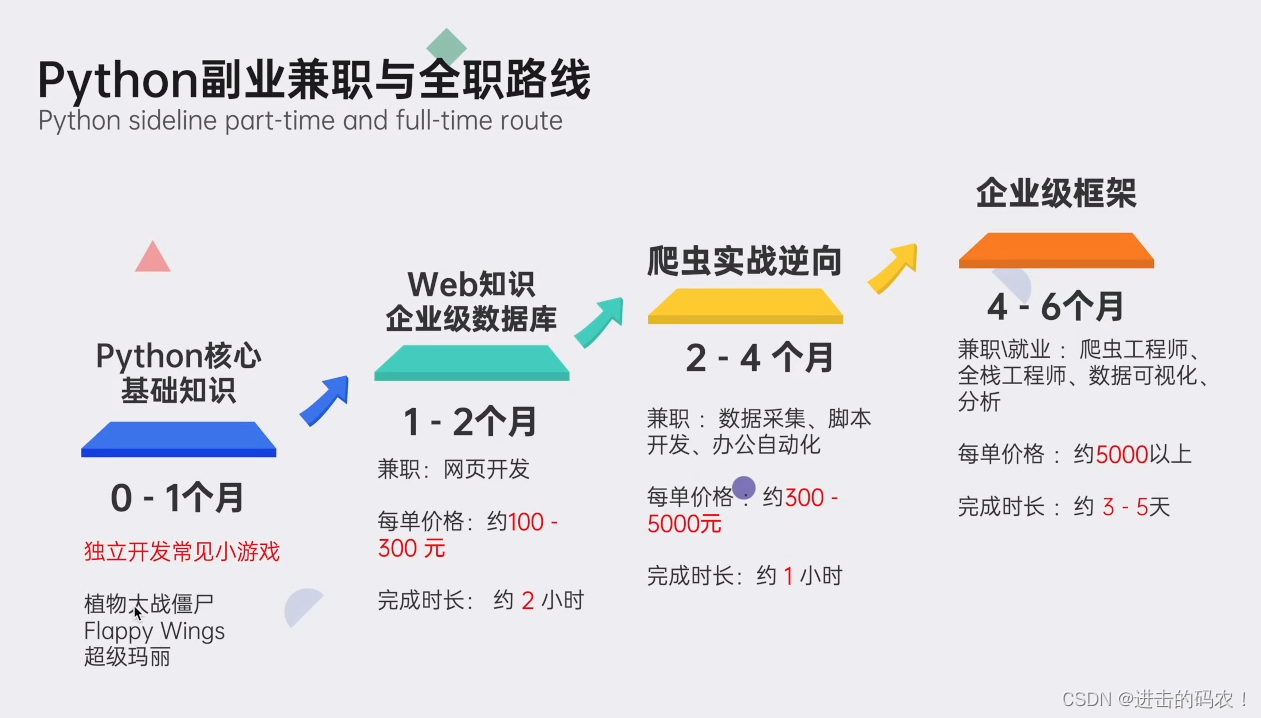

👉[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]](安全链接,放心点击)















 1805
1805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









