









学会 Stable Diffusion 后怎么用 ?
Stable Diffusion就要应用落地提升生产力,接下来我以我的应用案例来给大家讲讲我是怎么应用落地的,其他行业的应用原理也是相通的,可以作为参考。

BDicon生成三维图标
BDicon是我炼制的用于B端风格三维渲染图生成的大模型,主要使用ControlNet进行精准线稿生成,之前有写过一篇文章详细介绍生成细节操作,这里仅展示生成成果和分析。

如何用Bdicon大模型低门槛生成B端三维图标
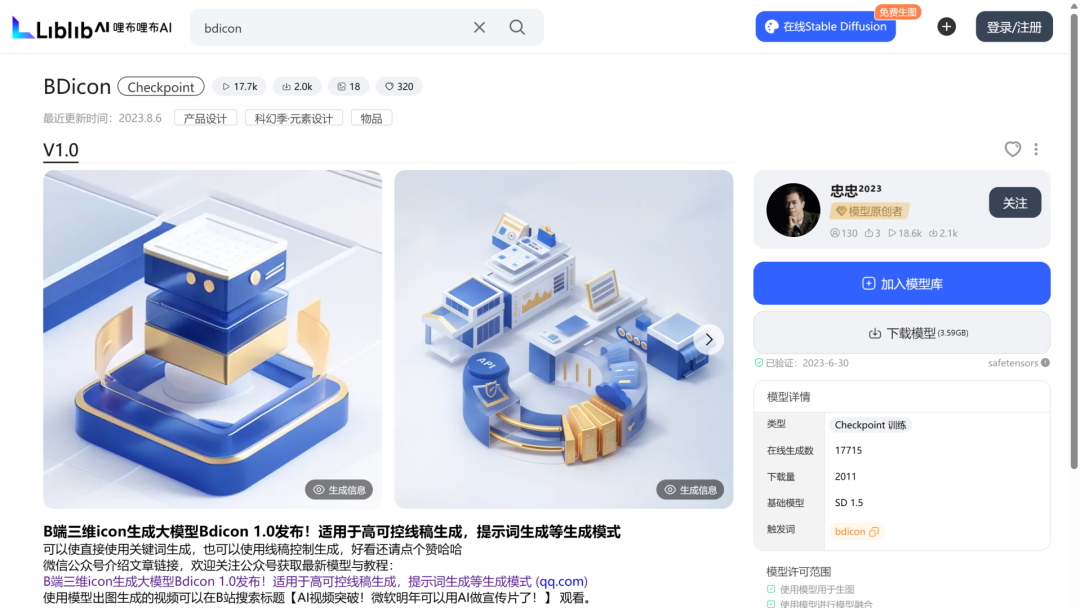
图中第一行是文生图生成的,目前仅有部分物品文生图效果比较好,更多的文生图优化还有待后续炼制XL版本模型来实现,XL的文生图能力要好上许多,能清晰认识更多物品和概念。
第二行和第三行都是基于线稿生成的图像,可以根据业务需求自行绘制线稿控制生成结果,真正应用于工作。

下图中是使用简单线稿进行生成的效果,整体已经不错了,但是有些细节造型会有些小扭曲,比如正确勾号,目前的实践解决方案是加大分辨率后出图细节就能得到明显改善。

下图的高分辨率图像的细节造型就有了明显改善,正确勾号造型正确了。但是高分辨率放大也带来了新的问题,比如用户头部多出的造型,和背景元素被重绘的更多更明显了,这些问题可以通过PSbeta的AI功能去解决。

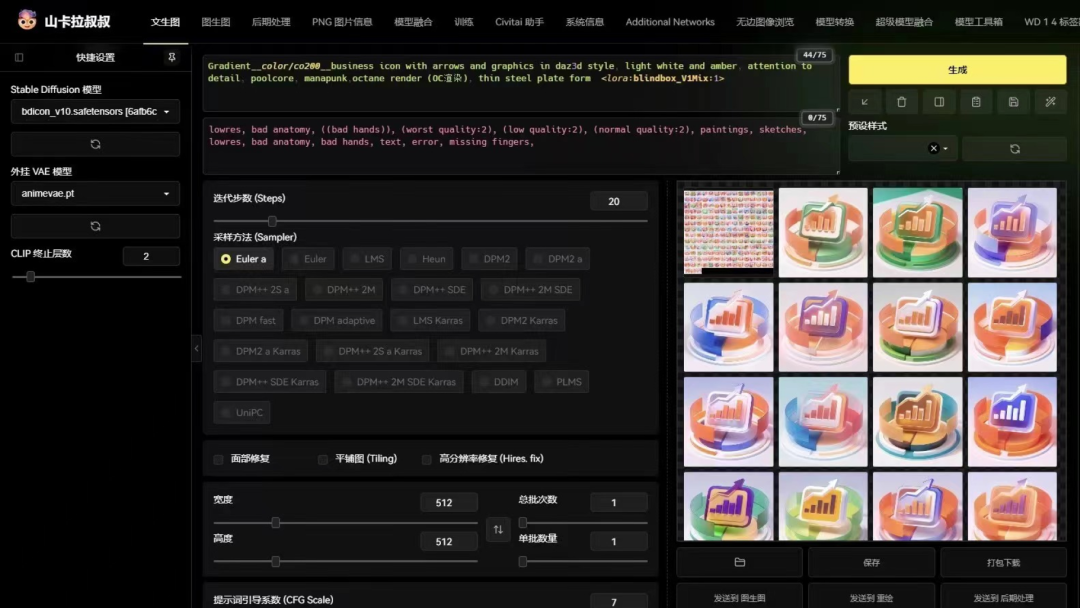
下方是BDicon的用户山卡拉叔叔的实践案例,虽然显卡只是1660s,但也有不错的效果。显卡只决定能不能跑,跑的有多快,生成的图片质量如何还是要看具体参数设置。

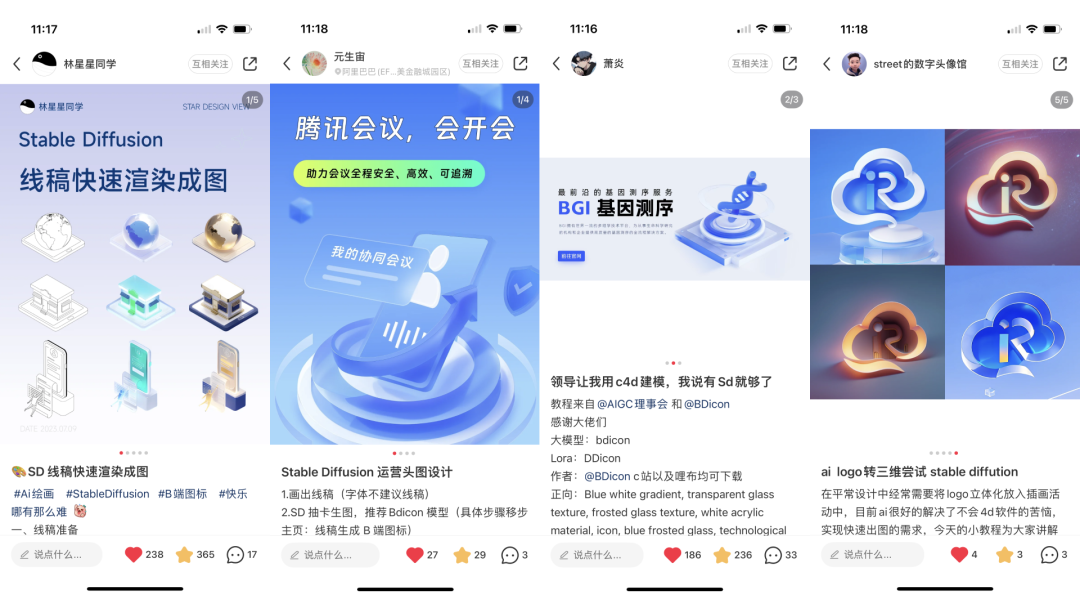
下方是小红书用户的实践案例,有了BDicon快速满足需求方有个图的需求,轻松下班哈哈
上方的都是简单线稿生成,接下来我们来看一下复杂线稿的生成效果,复杂线稿的具体参数需要对应调整,具体细节可以关注后续更新。

通过替换提示词,可以低成本快速更换色调,一个颜色耗时十分钟左右,比在三维软件中更改色调再重新渲染节约了数十倍的时间。虽然细节还有瑕疵,但要求不高的需求可以用了,要求高的需求也可以可以作为方向性参考与团队先过一遍,确定了再照着这个方向做,对齐双方预期,避免因为预想结果不同造成的反复修改。

微软风lora叠加风格
下图即是文章开头的视频中提到的微软风LoRA叠加到BDicon 上生成的效果,让成图结果带有了明显的柔彩质感。
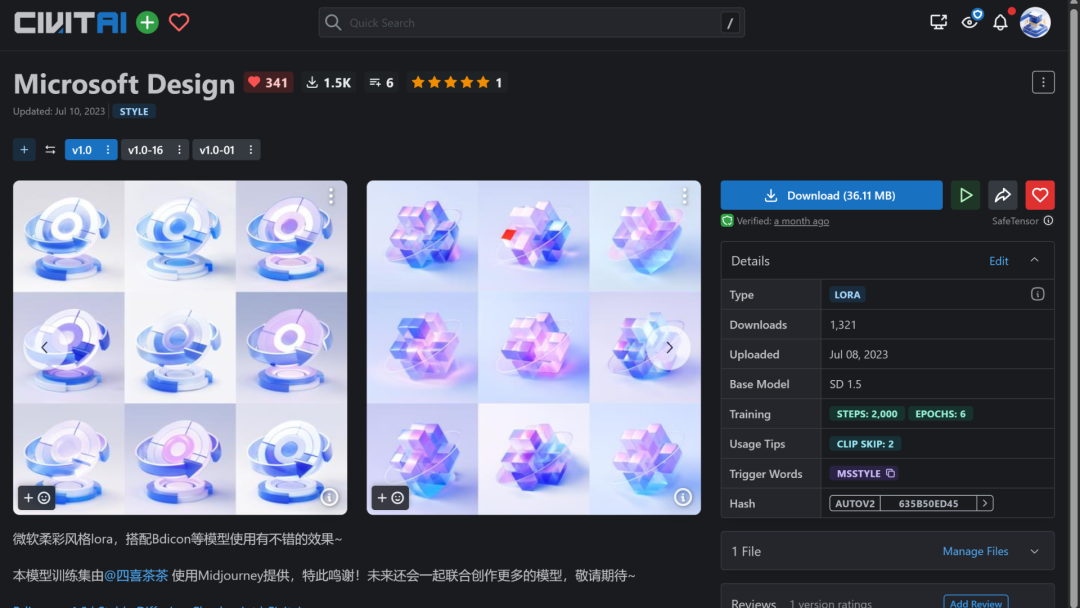

多叠加Lora也有机会出现神奇的效果,下方是BDicon的用户山卡拉叔叔叠加了blindbox, microsoft design,御火 V2,CGgame C4D bsw 等4个LoRA生成的效果,多样化了许多,这种LoRA叠加的权重设置没有明显通用的规则,往往需要靠着对各个LoRA的了解来设定和尝试最佳设置。
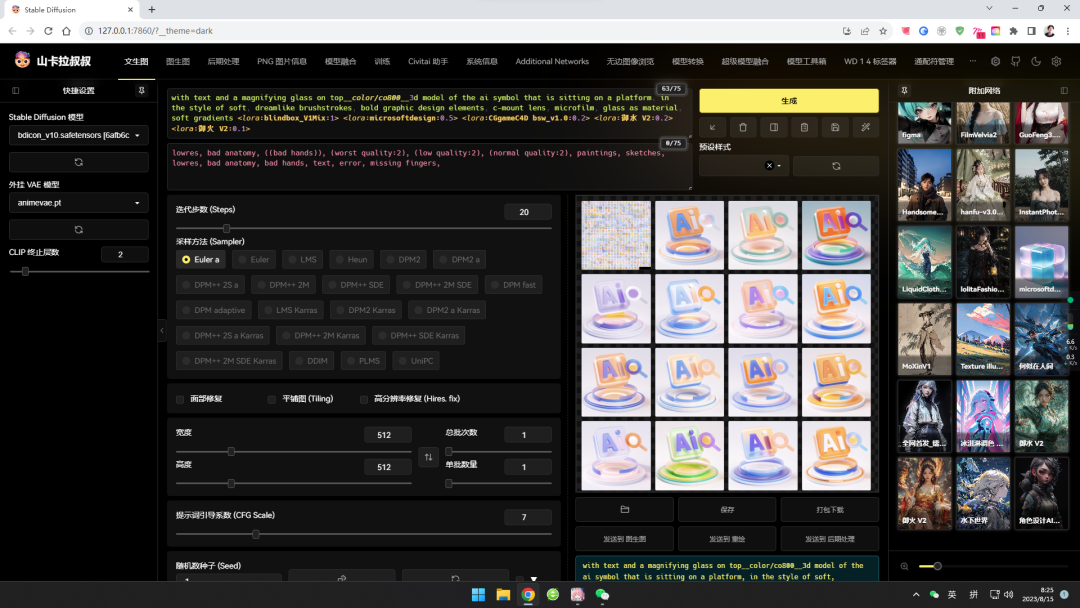

训练模型满足特定需求
SD之于MJ的一大区别就是自主训练模型满足特定需求,例如我的BDicon和微软风模型就是为了满足B端设计所需的三维模型的特定需求而训练的。市场上的人像模型、游戏模型、IP模型、电商营销模型也都是如此为了满足各自特定的需求而训练的,下方是我写的一些训练模型和应用模型相关经验的文章,有兴趣的可以前往本号文章列表查阅。
**

Dreambooth 官方炼丹教程万字详解-Epochs\Batch size\学习率 等超参数调优 (一)

Dreambooth 官方炼丹教程详解-影响显存的高级设置(二)
接下来我以得到AIGC专家海辛转发推荐的微软风LoRA为案例,向大家展示不打标的极简炼丹术的训练思路。本思路可以适用于各种画风迁移到SD的需求,不仅局限于MJ出品的画风,任何训练集的画风都可以的。

这是MJ生成的微软风图标训练集,本次使用了100多张这样的图片作为训练集提供给SD进行学习,并未进行打标处理,分辨率也是1024。

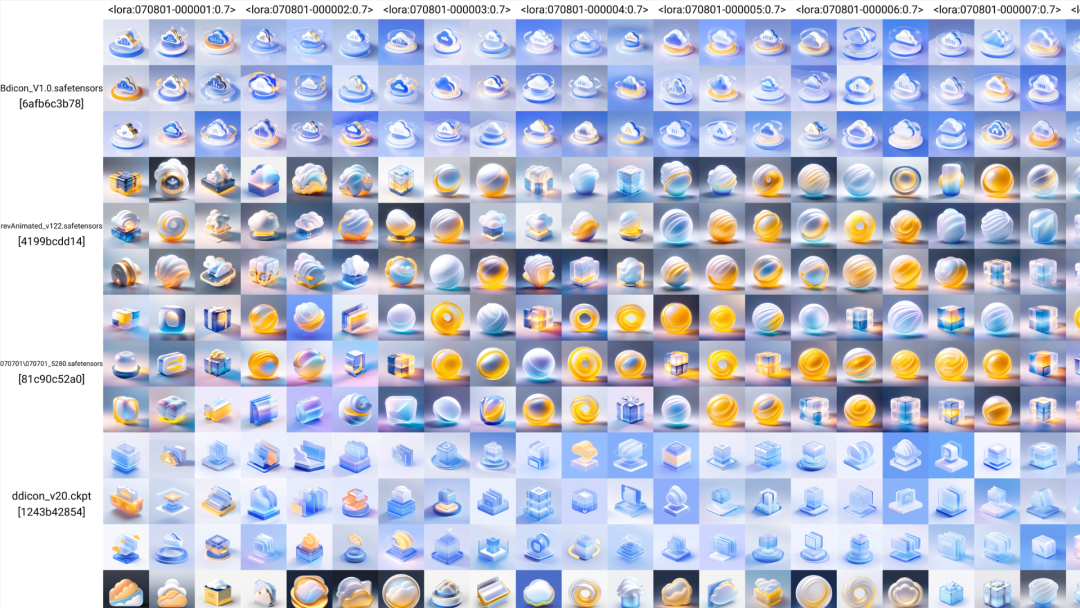
这是训练完模型后进行XY轴测试模型效果的截图,将不同训练成果叠加于不同底模之上,即可直观的感受到不同的表现,然后再根据各方面表现筛选效果最好的那一个,作为最终成品LoRA文件发布。
当然,很难一次训练就得到最佳成果,往往需要从基础参数开始,多次调整训练参数才能得到满意的成果。
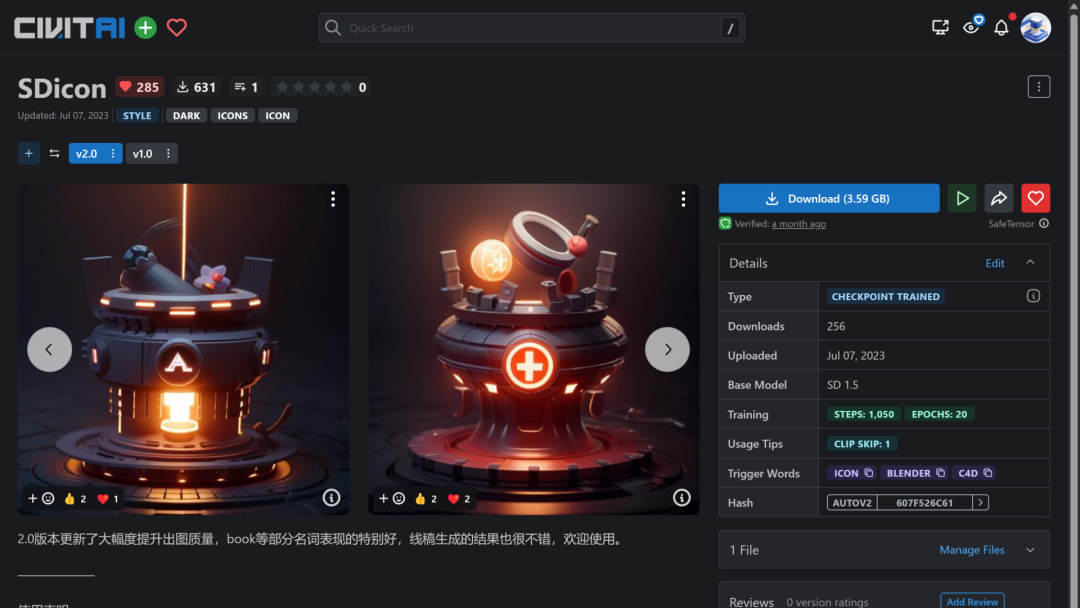
下图是我训练的另一个暗橙色风格的大模型SDicon,使用了50张素材左右的训练集进行训练,Ckpt大模型的训练并不一定比LoRA难,但对电脑性能和硬盘空间的需求是确定性的更多,一次训练产生几十G的文件很正常。

利用SD做其他有趣的事
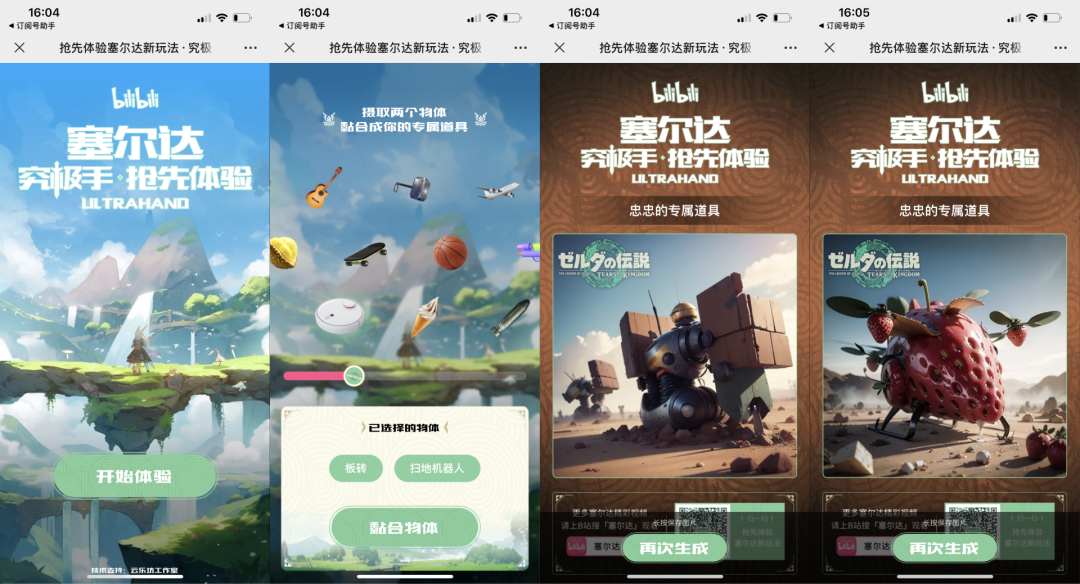
学会SD后,除了应用于正经工作提效以外,我们还可以做些有趣的事情。例如利用SD的AI能力融合现实中无法融合的物体,轻松五分钟产出以前需要用PS辛苦的合成五小时的融合创意图。
我将这种融合创意图应用于我和B站合作的H5小游戏的效果也挺有意思,这次小游戏为了呼应《塞尔达·王国之泪》游戏上线而做的融合玩法收到的反响还不错,游玩次数也突破了10W+,并且加上多次推翻修改的制作成本依旧只有传统PS合成方式的几十分之一,详情可以看我写的这篇总结文章

AI绘画商用案例:Stable Diffusion 生成B站塞尔达H5小游戏梗图

SD的放大能力还能用于放大MJ生成的图片,将不足2k的图放大为5k超清并且合理的增加细节,可以有效提升图片的品质水平。
下图是我生成的银河舰队系列战舰,使用MJ生成图片后再到SD里添加细节和放大,最后在剪映里组合成视频,最终相关视频全网播放量50W+,收获了2W多个赞,也算是很有趣的经历了。

与视频生成AI Gen-2 联动
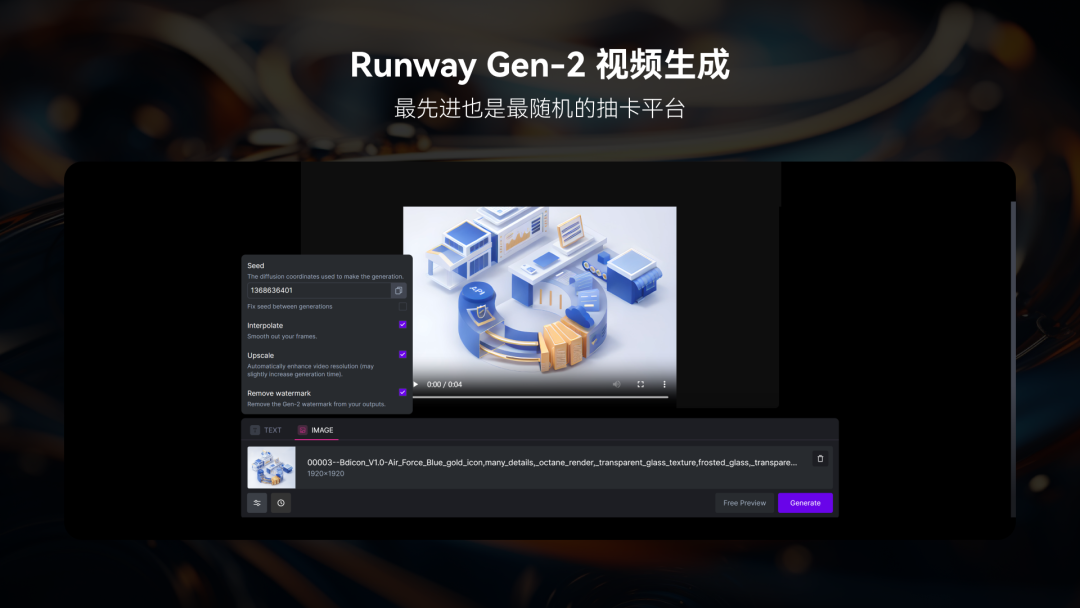
SD生成图片还可以进一步放入视频生成AI Gen-2里进行图生视频的处理,出来的结果也挺有惊喜的。感觉现在AI视频的发展程度已经到达MJ早期V1的阶段了感觉,技术突破应该就在这几年了,下方是使用Gen-2生成的一些视频,可以感受一下AI视频技术的突破。
总结
以上就是为什么要学SD,怎么学SD,学了SD怎么应用落地等几个问题的回答了,更多实践案例及落地细节敬请期待后续课程更新,祝大家都能愉快的学会SD,生成出最棒的作品哈哈~
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









