









Stable Diffusion入门使用技巧及个人试用实例系列文章已经更新5篇了,今天准备给大家更新第六篇,个人如何最简单的训练lora。
先看最终炼丹效果吧:
暗黑女生:

提示词:
((masterpiece)),((best quality)), ((intricate)),((exquisite face)),((HD quality)),((masterpiece)),((best quality)),(Exquisite Face)
A young woman with a dark and mysterious vibe, dressed in black or deep, rich colors. Her clothing style might include gothic or alternative elements, such as lace, chokers, and dark makeup. Her hair could be styled in an unconventional way, possibly with unique colors or accessories, and her expression may convey a sense of enigma or intrigue.lora:xgirl-000008:1
可爱粉色系女生:

提示词:
((masterpiece)),((best quality)), ((intricate)),((exquisite face)),((HD quality)),((masterpiece)),((best quality)),(Exquisite Face)
A lovely young woman with a sweet and charming appearance, her eyes sparkling with warmth and her smile bright and inviting. She might be wearing a cute and colorful outfit, with soft pastel hues and playful patterns. Her hair could be styled in a way that adds to her adorable demeanor, such as braids, pigtails, or soft curls. She may exude a sense of happiness and friendliness, making those around her feel at ease and uplifted.lora:xgirl-000008:1
紫色酷女孩:

提示词:
( watercolor (medium), drawing, IrisCompiet:1.2), ((masterpiece)),((HD quality)), ((best quality)),((exquisite face))painting of a beautiful girl, full body,dark eyes, simple background ((rainbow theme)), sfw,colorfullora:xgirl-000005:1
下面是详细教程哦:
1.部署服务
(以下部署教程由我们开发小哥哥整理,此处必须点赞👍)
1.1 下载源代码
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
1.2构建镜像
docker compose build
1.2 修改docker-compose⽂件
需要部署在可以访问外⽹的机器上,并默认机器上有GPU
根据服务器对外暴露端⼝修改端⼝号
version: “3.8”
services:
kohya-ss-gui:
container_name: kohya-ss-gui
image: kohya-ss-gui:latest
build:
context: .
ports:
界⾯端⼝
- 7861:7860
tensorboard对应端⼝
- 7862:6066
tty: true
ipc: host
environment:
CLI_ARGS: “”
SAFETENSORS_FAST_GPU: 1
tmpfs:
- /tmp
volumes:
- ./dataset:/dataset
- ./.cache/user:/home/appuser/.cache
- ./.cache/triton:/home/appuser/.tritonLora
- ./.cache/config:/app/appuser/.config
- ./.cache/nv:/home/appuser/.nv
- ./.cache/keras:/home/appuser/.keras
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: [‘0’]
capabilities: [gpu]
1.3 启动服务并在浏览器访问,根据上⾯的配置,浏览器访问 服务器
ip:7861
docker-compose up -d
2. 训练Lora
**
**
2.1 数据集准备
1、挑选需要训练的数据集,并对数据集进⾏预处理,本次我选了29张类似风格的图片

2、在web ui界⾯选择train→ preprocess images
3、source directory:输⼊预先准备好的图⽚在容器内地址
4、destination directory: 处理后图⽚地址
5、设置处理后的宽度和⾼度
6、按需选择下⾯的功能,此处选择了auto focal point crop和use deepbooru for
caption
7、点击开始处理process
注:source directory可能会在处理时报错,没有权限,需要chmod 或者chown

2.2 Dreambooth LoRA
- 选择Dreambooth LoRA
- Pretrained model:此处填写本地模型的地址
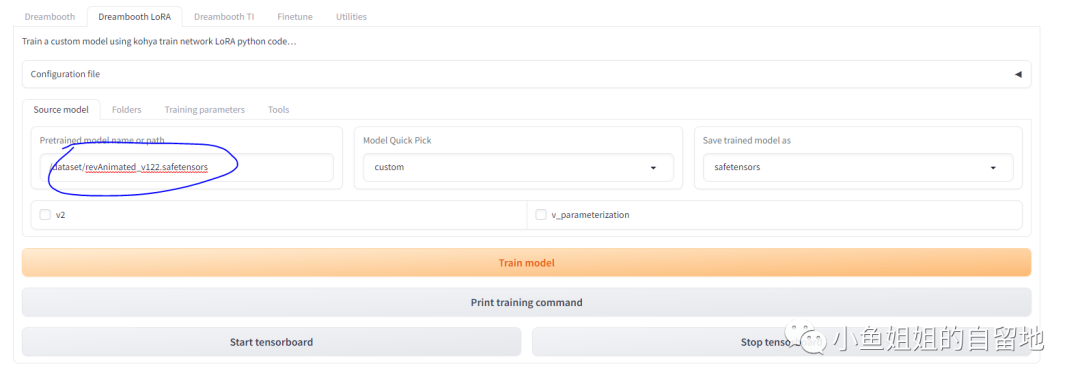
2.3 Tools界⾯
- 选择Tools
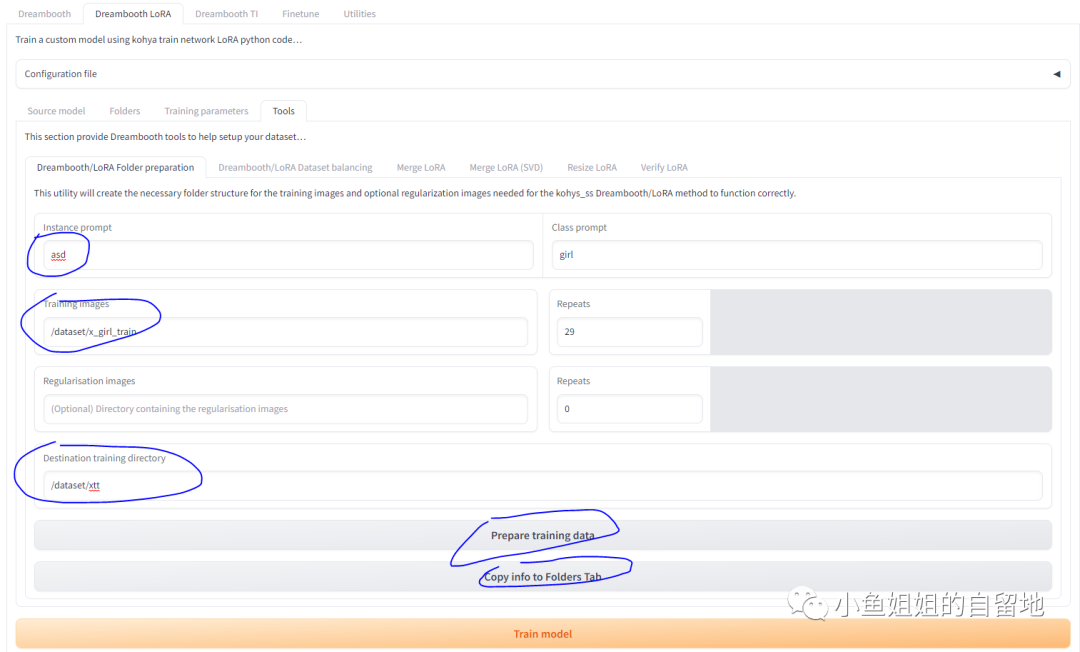
- Instance Prompt:此处直接填写了默认的asd
- Class prompt:根据你训练的类型填写Lora模型训练步骤(基于kohya_ss)
- Training images:预处理完毕的训练集在容器内的路径
- Repeats:图⽚重复数
- Repeats:此处没有⽤到Regularisation images,所以repeat填了0
- Destination:训练结果保存的⽬录,容器内地址,此处⽂件夹f6可以不存在,后⾯会
⾃动创建
- Prepare:点击会创建7所填写的地址,会⾃动创建⽬录f6,并根据上⾯的设置,构建
基础⽬录,
最终⽣成的模型会保存在容器内的/dataset/xtt中
- Copy Info:点击会将配置的⽬录⽂件⾃动填写在Folder⻚⾯中
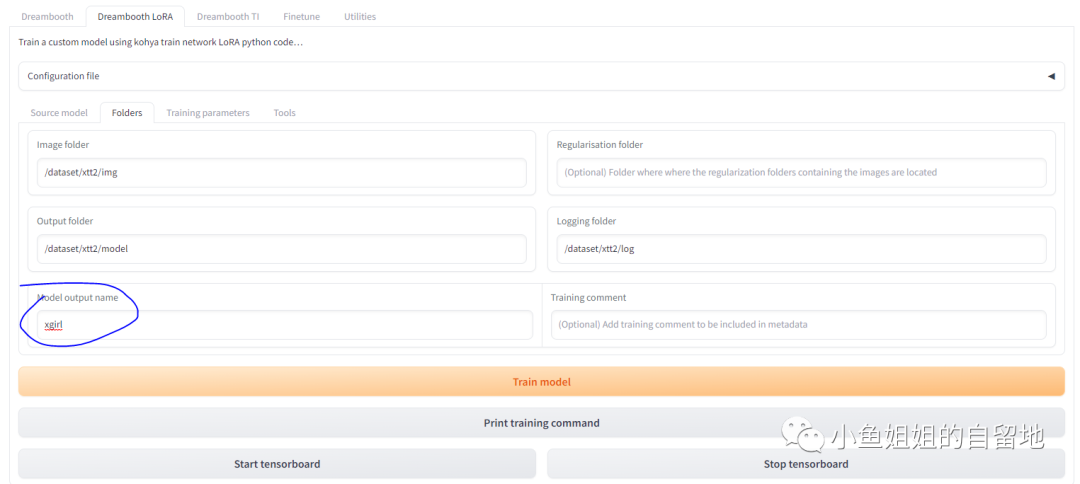
2.4 Folders界⾯
- 选择Folders
- 输⼊模型最终输出名称
2.4 Training parameters界⾯(最关键)
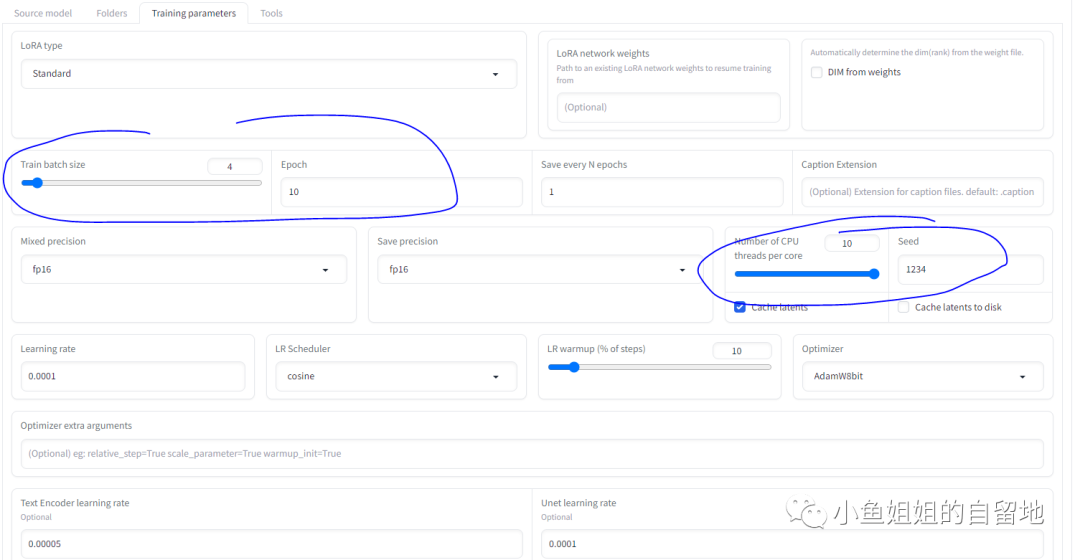
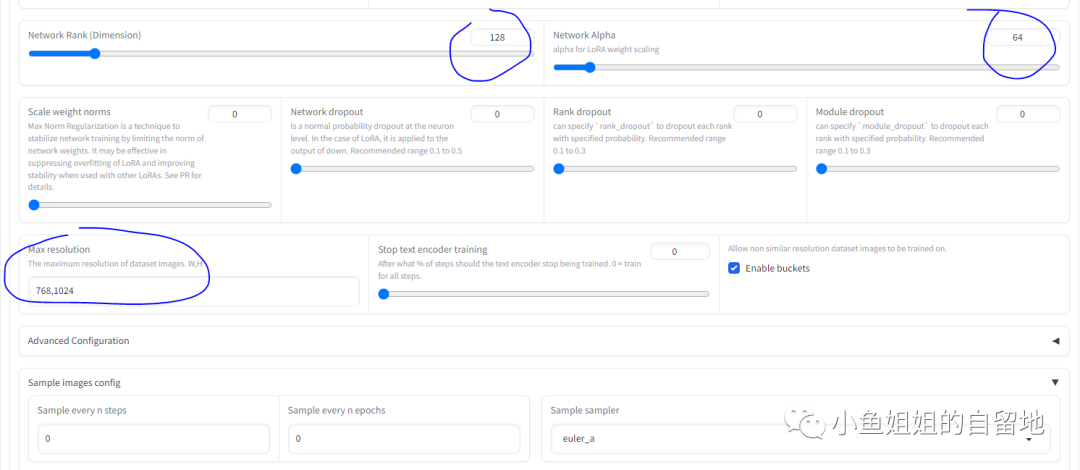
公式:step = 图⽚数量 * repeat * epoch / batch size
主要修改了6个地⽅,batch size, epoch, number of cpu, seed, network rank,
network alpha,可以根据⾃⼰的机器和个⼈ 实际情况进⾏修改。
最核心的超参数:
微调模型时最重要的超参数就是:学习率(learning Rate),epoch,batch size,steps,
epoch:表示训练过程中使用所有样本数据的遍数
batch size:指的是在一次迭代(更新模型权重)中使用的训练样本的数量
steps/iterations:更新模型权重的次数
举例说明:假设训练样本图像200张,batch size为4,那么每1遍epoch的steps为:样本数 200/batch size 4 =50步。Number of Steps per Epoch = (Total Number of Training Samples) / (Batch Size)
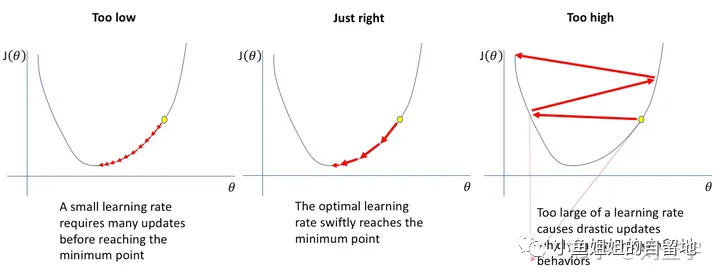
learning Rate:拟合数据过程中每次迭代的步长,相当于模型训练/微调过程中通向目标地的步子大小,步子太小了速度会很慢,太大的话容易振荡甚至直接爆炸。见图3
设置图⽚采样,⽅便查看效果图
此处设置每1个epoch,第150 step 按照prompt⽣成图⽚Lora模型训练步骤(基于kohya_ss)
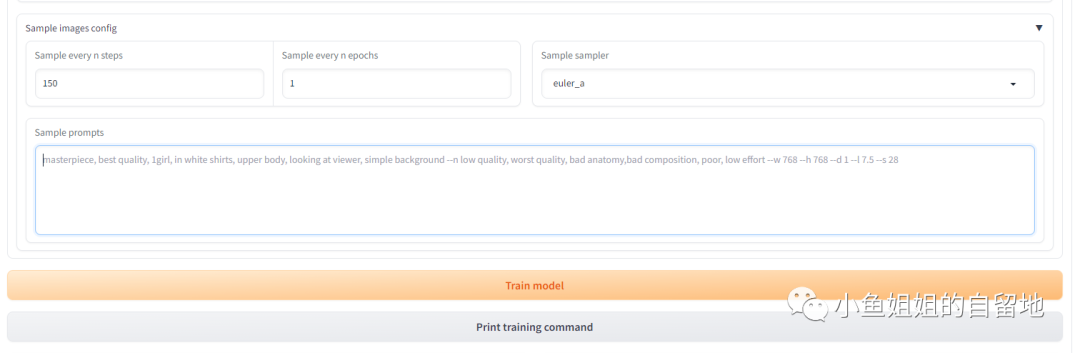
⽣成的图⽚和使⽤的sample prompt都会保存在容器内的/dataset/xtt2中
2.5. 训练
1 点击 train model开始训练
2 查看⽇志
#进⼊容器查看⽇志
docker logs -f --tail=200 container_id
3. 查看对比Lora模型(基于X/Y/Z plot)
3.1 放置模型
将训练好的模型放⼊stable diffusion的Lora⽬录下
3.2 lora选择
可以看到此处已经可以看到自己训练完成的lora,为什么有多个lora,因为epoch设置了10个,就生成了10个。
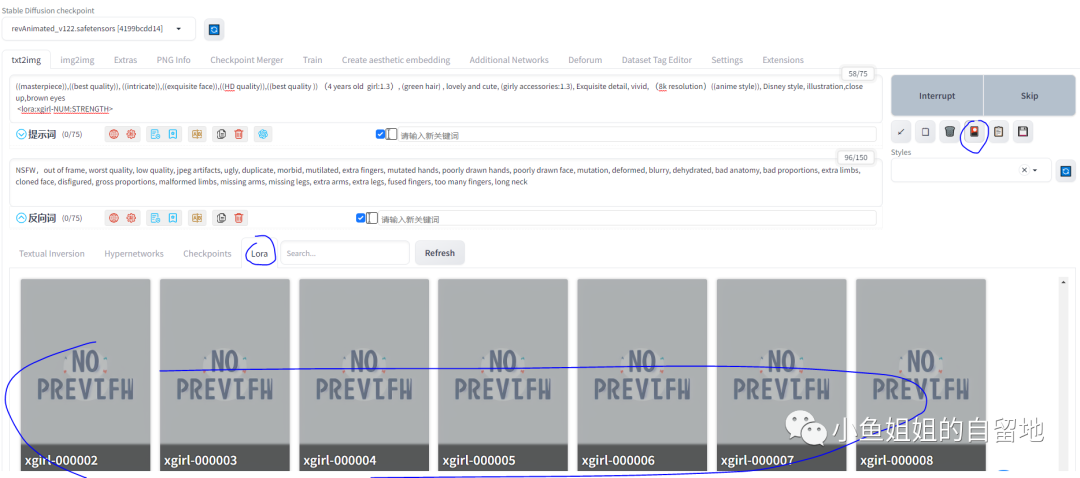
3.3 XYZ plot设置对比lora效果
设置XYZ plot具体修改如下:
1、不同采样器+不同epoch的对比可以按如下设置对比:
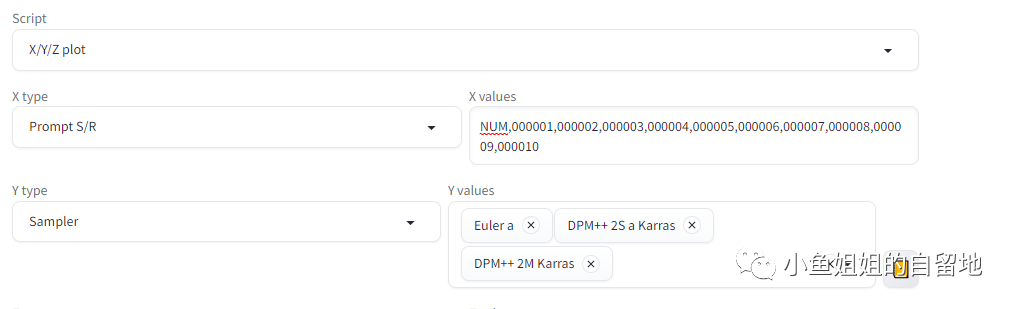
Script:选择X/Y/Z plot
X type:Prompt S/R (搜索替换)
X values:
NUM,000001,000002,000003,000004,000005,000006,000007,000008,000009,000010
Y type:Sampler
Y values:选择你需要的采样器
填入关键词后点击生成可查看对比效果:
本来Lora格式为 lora:xgirl-000003:1
我们⽤变量NUM来代替000010,修改后如下
修改前:lora:xgirl-000003:1
修改后:lora:xgirl-NUM:1
输入prompt可以参考如下:

输出结果可以参考如下图:

然后可以选择自己需要保留的lora。
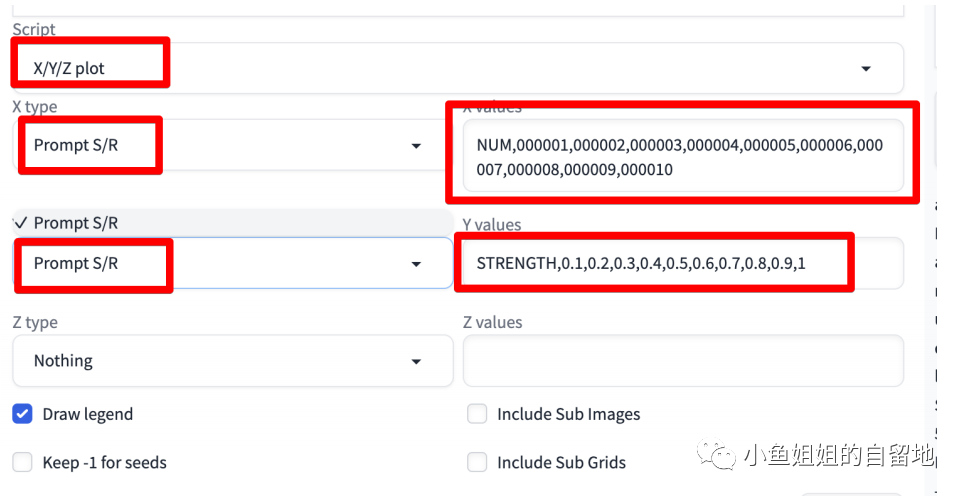
如果你想同时不同lora权重的话,可以按如下方式设置:
Y type:Prompt S/R
Y values:
STRENGTH,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1
本来Lora格式为 lora:xgirl-000003:1
我们⽤变量NUM来代替000010,修改后如下
修改前:lora:xgirl-000003:1
修改后:lora:xgirl-NUM:STRENGTH
输入prompt可以参考如下:

设置XYZ plot可设置如下:
4、设置最终lora,开始出图
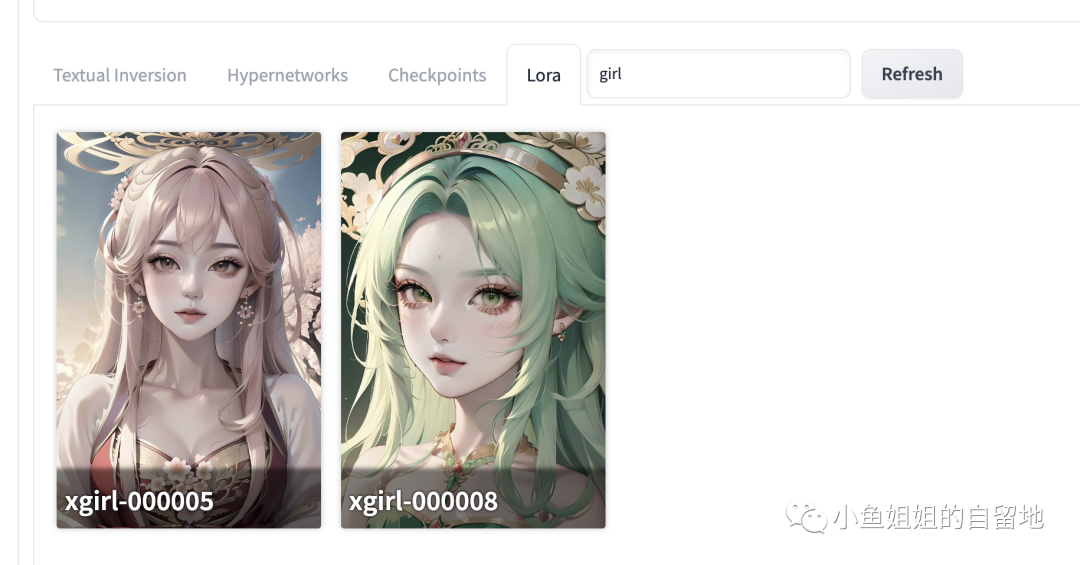
恭喜你看完啦,你们也可以试试哦。
彩蛋:下面是一些之前训练的敦煌风:(大家觉得有木有一点像呀?哈哈)


关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









