






ComfyUI
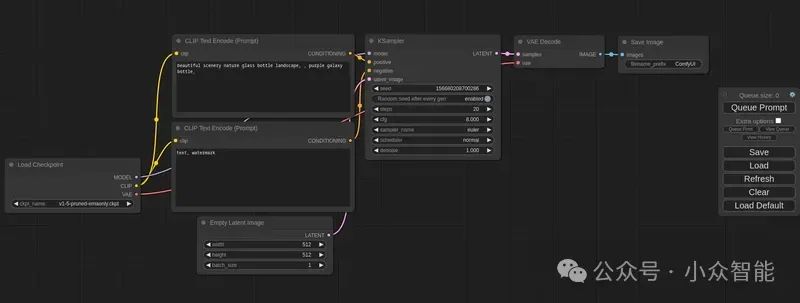
ComfyUI是一个基于节点的用户界面(GUI),专为Stable Diffusion设计,提供了一种更加直观、灵活的方式来操作和管理图像生成的过程。
为Windows和macOS设计的桌面客户端,它提供了一键安装的便利性,并拥有全新的用户界面。用户可以通过加入等待名单来获得早期访问权限。这款软件的主要优点在于它的易用性和现代化的界面设计,旨在提高用户的工作效率。
ComfyUI不仅是一个用户界面(UI),还是一个具有强大功能和高度模块化设计的系统,其GitHub页面描述它为“最强大且模块化的稳定扩散GUI、API和后端,带有图形/节点界面”。ComfyUI由Python、JavaScript和CSS编程语言开发,于2023年1月17日创建。ComfyUI以其低内存需求、快速启动和出图而闻名,适合那些需要精细控制和高度自定义的用户。
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

主要功能
-
**高度可定制性:**ComfyUI支持多种模型和模式,用户可以根据自己的项目需求选择合适的模型和模式。同时,用户可以通过调整模块连接来达到不同的出图效果,实现更精准的工作流定制和完善的可复现性。
-
快速启动和出图:ComfyUI对显存要求相对较低,启动速度快,出图速度快,能够大幅提高用户的工作效率。
-
高度自由度:ComfyUI提供了更高的生成自由度,用户可以通过自定义设置和插件来扩展其功能,满足各种复杂场景的开发需求。
-
流程分享:ComfyUI能够与web UI共享环境和模型,允许用户搭建自己的工作流程,并可以导出流程分享给别人。
-
轻量化:ComfyUI是一个轻量级的UI框架,能够方便地集成到已有的项目中,而不需要对现有的代码做大规模调整。
快速使用
Windows
有一个适用于 Windows 的可移植独立版本,它应该适用于在 Nvidia GPU 上运行或仅在 CPU 上运行在发布页面上。
下载的直接链接
只需下载,使用 7-Zip 解压并运行。确保将稳定扩散检查点/模型(巨大的 ckpt/safetensors 文件)放在:ComfyUI\models\checkpoints
如果您在提取它时遇到问题,请右键单击文件 -> properties -> unblock
如何在其他 UI 和 ComfyUI 之间共享模型?
请参阅 配置文件 来设置模型的搜索路径。在独立 Windows 版本中,您可以在 ComfyUI 目录中找到此文件。将此文件重命名为 extra_model_paths.yaml,并使用您最喜欢的文本编辑器对其进行编辑。
Jupyter 笔记本
要在 paperspace、kaggle 或 colab 等服务上运行它,您可以使用我的 Jupyter Notebook
手动安装(Windows、Linux)
请注意,某些依赖项尚不支持 python 3.13,因此建议使用 3.12。
Git clone 此存储库。
将你的 SD 检查点(巨大的 ckpt/safetensors 文件)放在:models/checkpoints
将 VAE 放入:models/vae
AMD GPU(仅限 Linux)
如果您还没有安装 rocm 和 pytorch,AMD 用户可以使用 pip 安装 rocm,这是安装稳定版本的命令:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.1
以下是使用 ROCm 6.2 安装 nightly 的命令,它可能会有一些性能改进:
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm6.2
英伟达
Nvidia 用户应使用以下命令安装稳定的 pytorch:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124
这是在 nightly 上安装 pytorch 的命令,它可能会提高性能:
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu124
故障 排除
如果您收到“Torch 未在启用 CUDA 的情况下编译”错误,请使用以下命令卸载 Torch:
pip uninstall torch
并使用上面的命令再次安装它。
依赖
通过在 ComfyUI 文件夹中打开终端来安装依赖项,然后:
pip install -r requirements.txt
在此之后,您应该已安装所有内容,并可以继续运行 ComfyUI。
这份完整版的AI绘画(SD、comfyui、AI视频)整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 8118
8118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









