










hi,我是逸尘,一起学java吧
目标(任务驱动)
1.请重点的熟练掌握集合的所有内容。
场景:在企业开发中数据存储和处理让你头疼不已,回想当年集合的内容你并没有学的很扎实,于是你准备回家熬夜打王者学集合内容。
集合和数组
集合可以看成容器,我们可以对容器进行操作,比如添加东西,拿出东西。说到容器我们还可以想到数组。但是与集合不同的是,数组是固定的,基本数据类型是确定的,在添加和拿出(删除)的时候需要移动下标,不太适合操作。
数组的适合场景是同一批数据类型且业务数据是固定的时候适合使用。
集合的存放内容是引用数据类型(如果要存基本数据类型需要用包装类),长度是可变的,它特别适合做元素的增删操作。
集合体系
从大的方面我们可以分为,单列和双列。
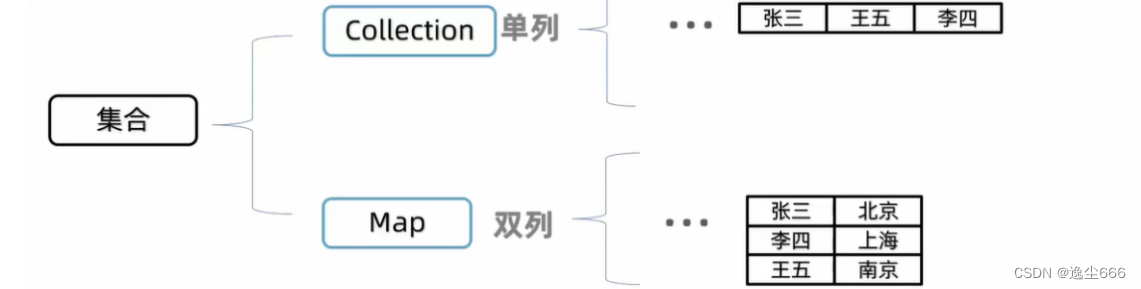
collection单列集合,每个元素(数据)只包含一个值。
map双列集合,每个元素包含两个值(叫键值对)。
collection单列体系
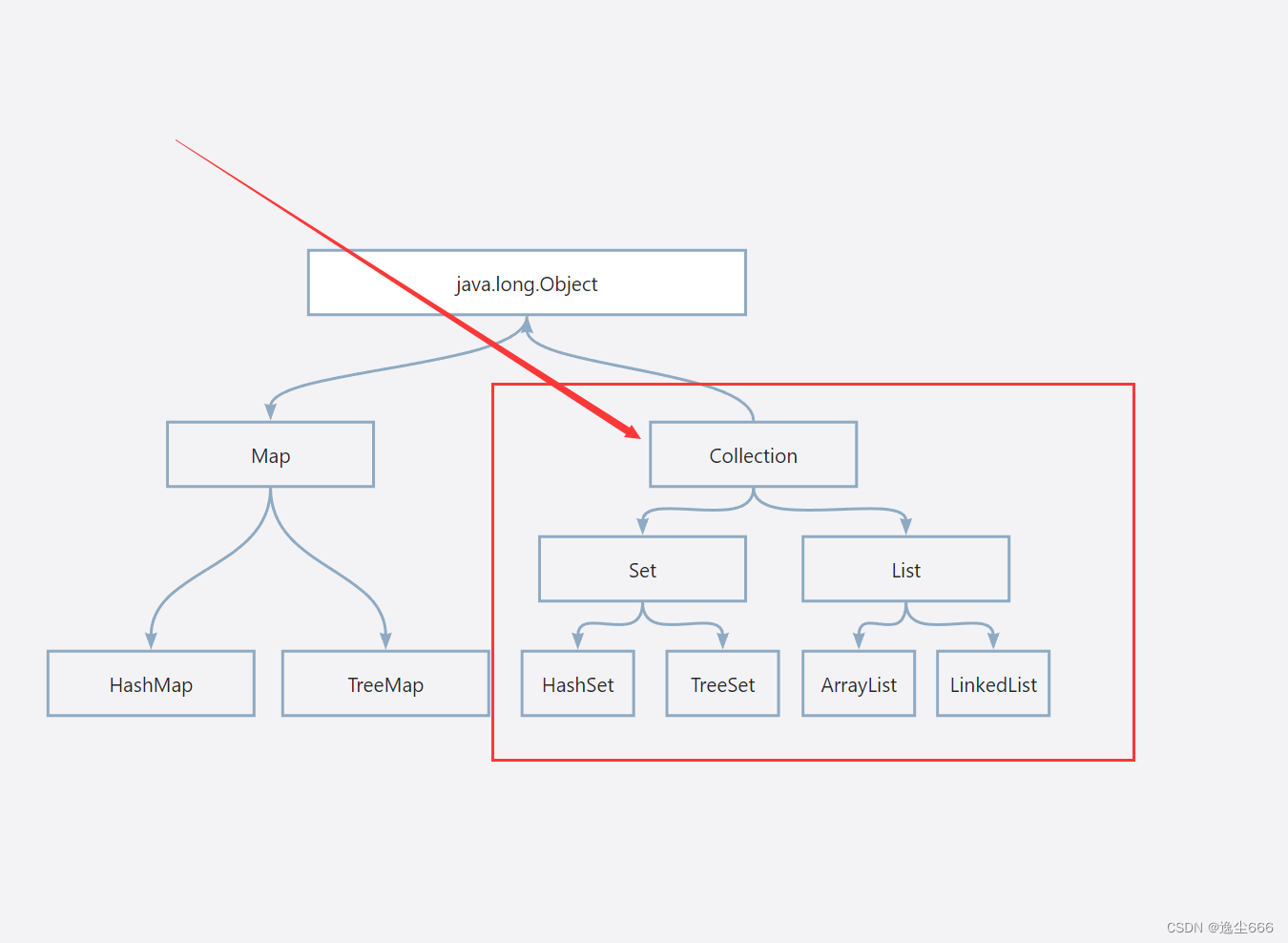
collection单列体系包括了两个集合系列,List和Set
List和Set主要区别在于其内的元素的顺序性,重复性和索引的操作规则是不一样的。
List集合
List接口 添加的元素是有序的,有可重复,有索引的(三有)它很类似于我们的数组。
他的常用的实现类有ArrayList和LinkedList。
ArrayList
我们说List接口一些特性类似于我们的数组,那么ArrayList就是实现了可变的数组,允许保存所有元素包括null,并且可以根据索引位置对集合进行快速随机访问。缺点就是向指定索引位置插入或者删除对象比较慢。
LinkedList
LinkedList是采用链表结构去保存对象,他和ArrayList正好作用功能相对,他在集合中插入和删除对象是比较好,但是对于随机访问集合的对象它的效率比较低。
Set集合
Set接口 添加的元素是无序的,不可重复,无索引的(三无)不按特定方式的排序只是简单的把元素对象加入集合,且不可重复。
他的常用的实现类有HashSet和TreeSet。
HashSet
由哈希表实现(实际上是一个HashMap),允许null元素的使用,不能保证顺序的永久不变,但是LinkedHashSet弥补了这个特点,它可以保证顺序。
TreeSet
TreeSet的顺序进行了改造,它是按照默认大小的升序排列,因为它还实现了java.util.sortedSet接口。
总结,三有list三无set,list是对索引的考虑(数组的随机访问能不能,插入的快不快),set是对顺序的考虑(顺序能不能进行排列是不是固定)。
Collection 的API
Collection接口是层次结构的根接口,构成Collection的单位称位元素,它不能单独使用,但是接口提供了一些方法用来操作这些元素,且set集合和list集合都是继承Collection接口,所以这些方法是通用的。
add(E e) 添加元素 remove(Object o)移除元素 isEmpty() 判断是否当前集合为空
iterator() 迭代器 size() 返回元素的个数 clear() 清空集合元素
这里我们着重说明一下迭代器,迭代器在java中的代表是lterator,迭代器是集合的专用遍历方式。
我们结合代码来看。
/**
* 迭代器的使用
*/
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class IteratorDemo {
public static void main(String[] args) {
//三有
Collection<String> lists=new ArrayList<>();
//添加
lists.add("A");
lists.add("B");
lists.add("C");
lists.add("D");
//删除
lists.remove("D");
Iterator<String> it = lists.iterator();
while(it.hasNext()){
//把指针往下调
String next= it.next();
System.out.println(next);
}
}
}
ps:我们可以按住ctrl点击方法进入查看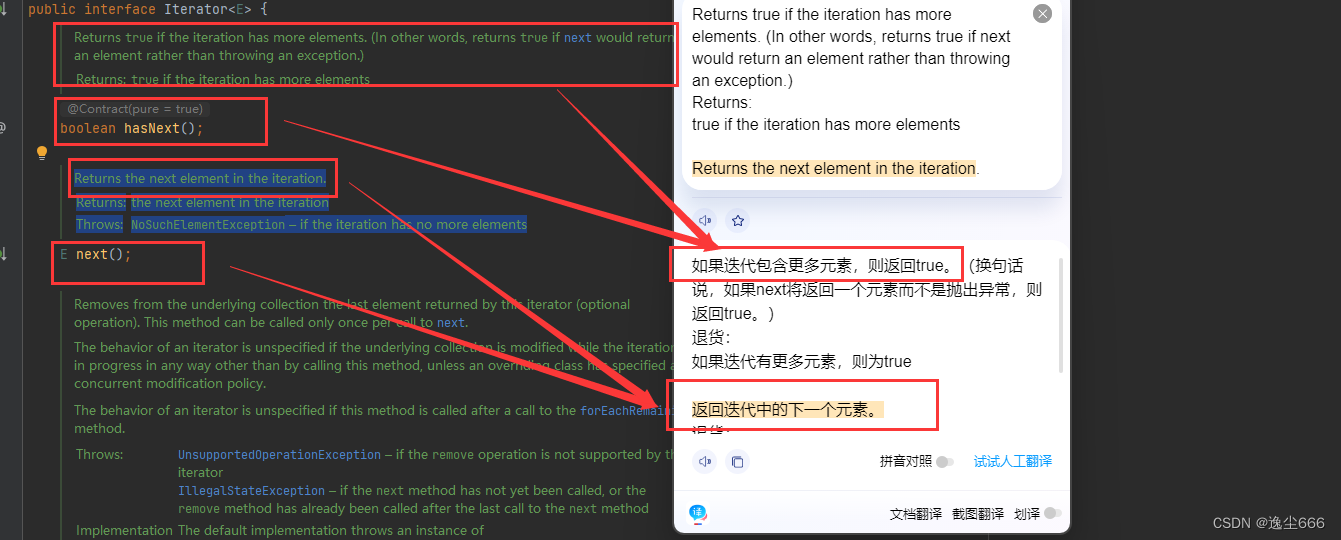
补充
还记得我们的forEach吗,他可以遍历数组,同样可以遍历集合
在jdk5后的forEach相当于迭代器的简化版写法。

map双列体系
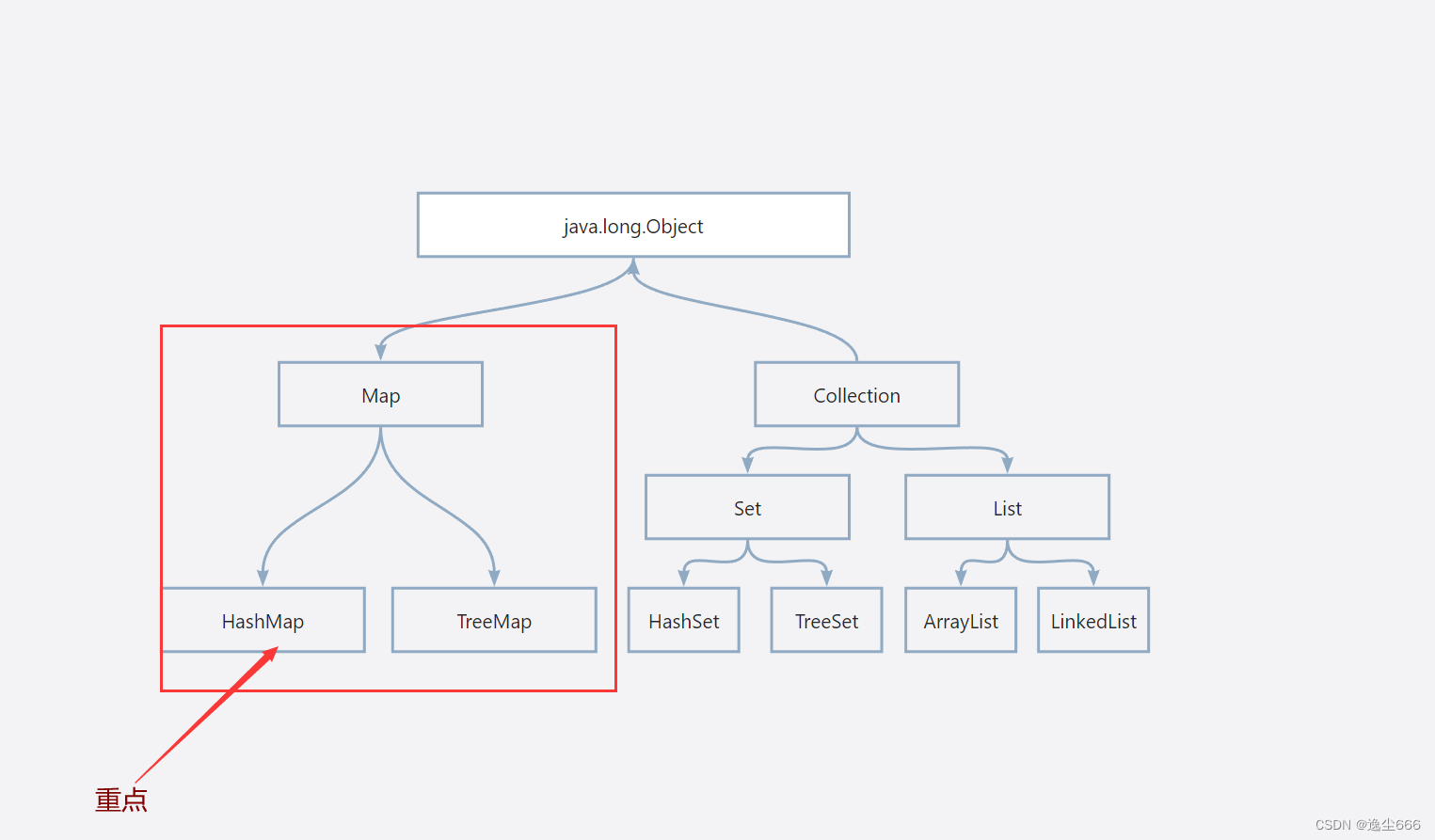
map双列体系没有其他集合系列了,Map体系的接口就是Map,常用的实现类是HashMap
在Map集合中,我们提供的是key到value的映射存储关系,也叫键值对,键和值是要一 一对应的,比如说
王中汪火腿 5元
康氏傅冰红茶 3元
可不可薯片 6元、
这样的关系
所以map集合也被称为"键值对集合"。
Map集合的特点是由键决定的,值可以重复(不做要求),键值对可以是null,后面重复的键对应的值会覆盖前面键的值。
对比我们的collection集合格式

Map集合
HashMap
hashMap是基于哈希表的Map接口实现的,基于哈希表,增删改的性能都比较好,依赖于hashcode和equals方法保证键的唯一。它基本和Map体系一致,键无序,不重复,无索引,值不做要求。linkedHashMap在此基础上把元素键有序化。
TreeMap
键排序,不重复,无索引,值不做要求。它还实现了java.util.sortedSet接口,他的性能和HashMap相比稍差,且键不能为null。
Map的API
Map接口提供了key映射到值的对象,一个映射不能包含重复的key,每个key最多也只能映射到一个值,Map接口还提供了下面的方法
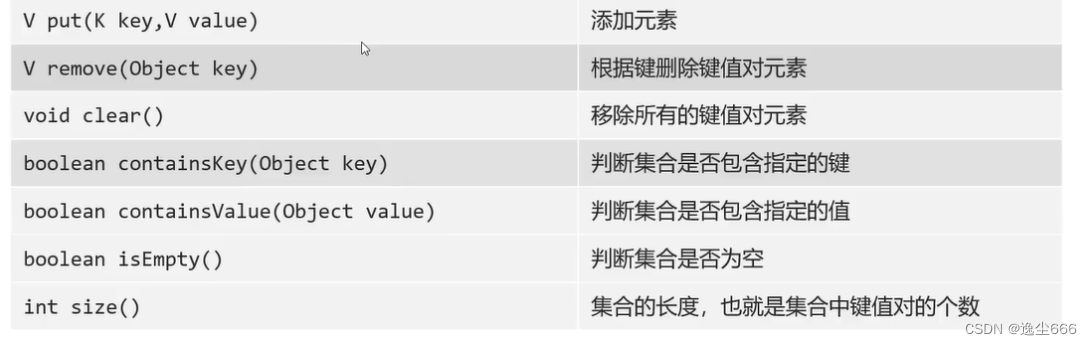
get()如果有值返回对象对应的值
entrySet() 把map转化为set类型的的键值对存储
遍历Map值
方法一 键找值
先获取map集合全部的键(形成一个key的set集合)
遍历键的set集合,然后通过键提取对应值。
package com.yd.yc;
import java.util.HashMap;
import java.util.Set;
public class MapDemo {
public static void main(String[] args) {
HashMap<String, String > mapOne = new HashMap<>();
mapOne.put("S991","逸学java");
mapOne.put("S992","逸学Springboot");
mapOne.put("S993","逸学java实战");
//获取所有键的set集合
Set<String> keySet = mapOne.keySet();
System.out.println(keySet);
//遍历set集合
for (String key : keySet){
//用key取出value
String value=mapOne.get(key);
System.out.println(value);
}
}
}
方法二 键值对取值
先把map集合转换成set集合,set集合中每个元素都是键值对实体类型了。
遍历set集合,然后提取键以及提取值。
package com.yd.yc;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class demo {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put("菊花茶","3元");
map.put("大瓶冰红茶","4元");
map.put("脉动","5元");
//通过一个方法获取所有键值对对象的集合,返回Set集合
Set<Map.Entry<String, String>> entries = map.entrySet();
System.out.println(entries);
// keys.for 遍历每一个单列集合,得到每一个键
for (Map.Entry<String, String>entry : entries) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"="+value);
}
}
}当然我们在这边并没有使用Lambda表达式来作为遍历,我们将在下一小结开始讲解更简单的遍历集合方式。
















 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











