







- 安装Python
安装完成后,在cmd中输入python查看python版本
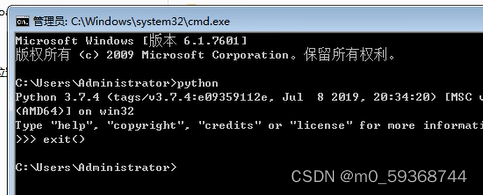
输入exit()退出
- 点击pyCharman-community-….exe安装社区版
点击next
点击Browse…选择存放位置,点击next
如图选择点击next
 点击install,等待安装如图
点击install,等待安装如图
- 基于Scrapy框架的网络爬虫开发流程
- 首先在cmd中,输入pip install pywin32在创建项目之前需要配置能够实现访问windows的API。 因为Windows是不允许程序直接访问硬件的,所以我们需要通过一个媒介,实现传递,这里就是我们经常能够用到的Pywin32模块,下面来给大家介绍基本的使用技巧,一起来详细了解下吧。 Pywin32安装: pip install pywin32
- 在使用scrapy之前需要安装Scrapy在cmd中输入pip install scrapy
- 可能还有一些操作忘记了
- 创建scrapy爬虫项目
- 打开pyCharm软件,创建一个项目取一个名字sina_spider
- 在终端中导入scrapy 依然输入pip install scrapy
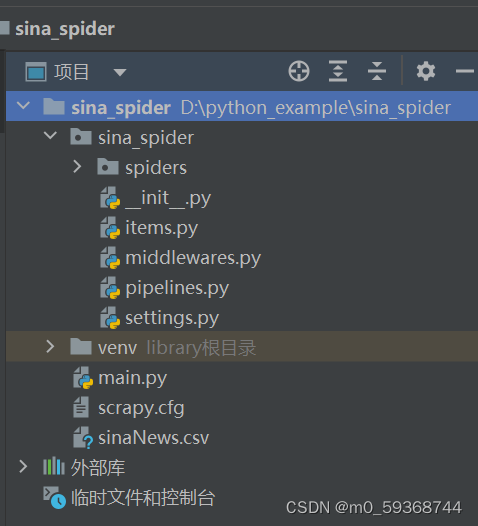
- 进入打算新建爬虫的目录中,使用scrapy startproject sina_spider(这里就是新建爬虫项目的名字,要与上面新建项目名字相同),创建好的目录如下图没有sinaNews.csv
-
- 创建爬虫文件,包含要爬取的网站名,输入命令:scrapy genspider sinaSpider(爬虫文件夹名) www.sina.com.cn(待爬取的网站)

-
- 修改settings.py 文件的ROBOTSTXT_OBEY=False获取网站不希望被爬取的部分
- 编写parse()方法
- 运行爬虫程序并保存抓取数据
- 本例爬虫的文件名是sinaSpider.py保存格式是csv,找到项目名的目录,输入cmd打开cmd命令框输入命令scrapy crawl sinaSpider(爬虫文件名) -o sinaNews.csv(保存数据文件名和格式)

-
- 如果最后有如下错误

- 可按如图操作修改版本至22.10.0版本或其他
- 解决用excel查看乱码问题,首先用记事本打开csv文件点击另存为修改为所有文件和ANSI,重新用excel打开csv文件查看,问题解决。















 2743
2743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









