






目录
ClassNotFoundException/NoClassDefFoundError出现原因及解决
线程池启动线程 submit 和 execute 方法有什么不同
Java基础
谈谈面向对象
面向对象是一种思想,再Java中有三大特性继承、封装、多态都是使用了该思想,举例!!!
枚举的使用
作用是定义一组常量,例如四季,12月份等。
public static void main(String[] args) {
//获取所有枚举
for (enums value : enums.values()) {
System.out.println(value);
}
//获取枚举值
System.out.println(enums.BLUCK);
//获取枚举索引
System.out.println(enums.BLUCK.ordinal());
//获取索引值
System.out.println(enums.valueOf("RED"));
}输出:
RED
BLUE
BLUCK
BLUCK
2
REDfinal修饰
类----不可继承
方法---不可重写
变量---基本数据类型值不可以改变,引用数据类型引用地址不可以改变
接口和抽象类
抽象类:方法可以是抽象,也可以是非抽象,可以有构造器
接口:JDK1.8之后可以被有static和default修饰的方法体,所有对象都被public修饰,变量被public static final 修饰,方法被public abstract修饰
java 中普通类继承,抽象类继承,接口类继承,子类一定要重写父类中的方法吗_GHLANCE的博客-CSDN博客
泛型
注意:(代码java基础)
泛型只能代表引用数据类型,不能表示基本数据类型
泛型方法得到的实际参数类型的占位符
栈的实现方式
数组的方式:先进后出
顺序插入,取时取len-1下标下的元素
序列化
序列化ID保证了对象唯一性
序列化:对象-》文件(通过实现Serializable接口+FileOutputStream流完成序列化 )
反序列化:文件-》对象
Math类
Java Number & Math 类 | 菜鸟教程 (runoob.com)
Character 类
Java Character 类 | 菜鸟教程 (runoob.com)
强引用、软引用、弱引用、虚引用
强、软、弱、虚引用的区别和使用 - 知乎 (zhihu.com)
ClassNotFoundException/NoClassDefFoundError出现原因及解决
(205条消息) ClassNotFoundException/NoClassDefFoundError出现原因及解决_爱叨叨的程序狗的博客-CSDN博客
在List集合下实现线程安全
(205条消息) Java的List如何实现线程安全?_java 线程安全的list_我的需求呢的博客-CSDN博客
final关键字
- 它修饰的类不能被继承。
- 它修饰的成员变量是一个常量。
- 它修饰的成员方法是不能被子类重写的。
为什么局部内部类和匿名内部类只能访问 final 的局部变量?
追究其根本原因就是作用域中变量的生命周期导致的;
首先需要知道的一点是: 内部类和外部类是处于同一个级别的,内部类不会因为定义在方法中就会随着方法的执行完毕就被销毁。
这里就会产生问题:当外部类的方法结束时,局部变量就会被销毁了,但是内部类对象可能还存在(只有没有人再引用它时,才会死亡)。这里就出现了一个矛盾:内部类对象访问了一个不存在的变量。为了解决这个问题,就将局部变量复制了一份作为内部类的成员变量,这样当局部变量死亡后,内部类仍可以访问它,实际访问的是局部变量的"copy"。这样就好像延长了局部变量的生命周期。我们可以通过反编译生成的 .class 文件来实验:
class OutClass {
private int age = 12;
public void outPrint(final int x) {
class InClass {
public void InPrint() {
System.out.println(x);
System.out.println(age);
}
}
new InClass().InPrint();
}
}报错:
Cannot refer to a non-final variable x inside an inner class defined in a different method
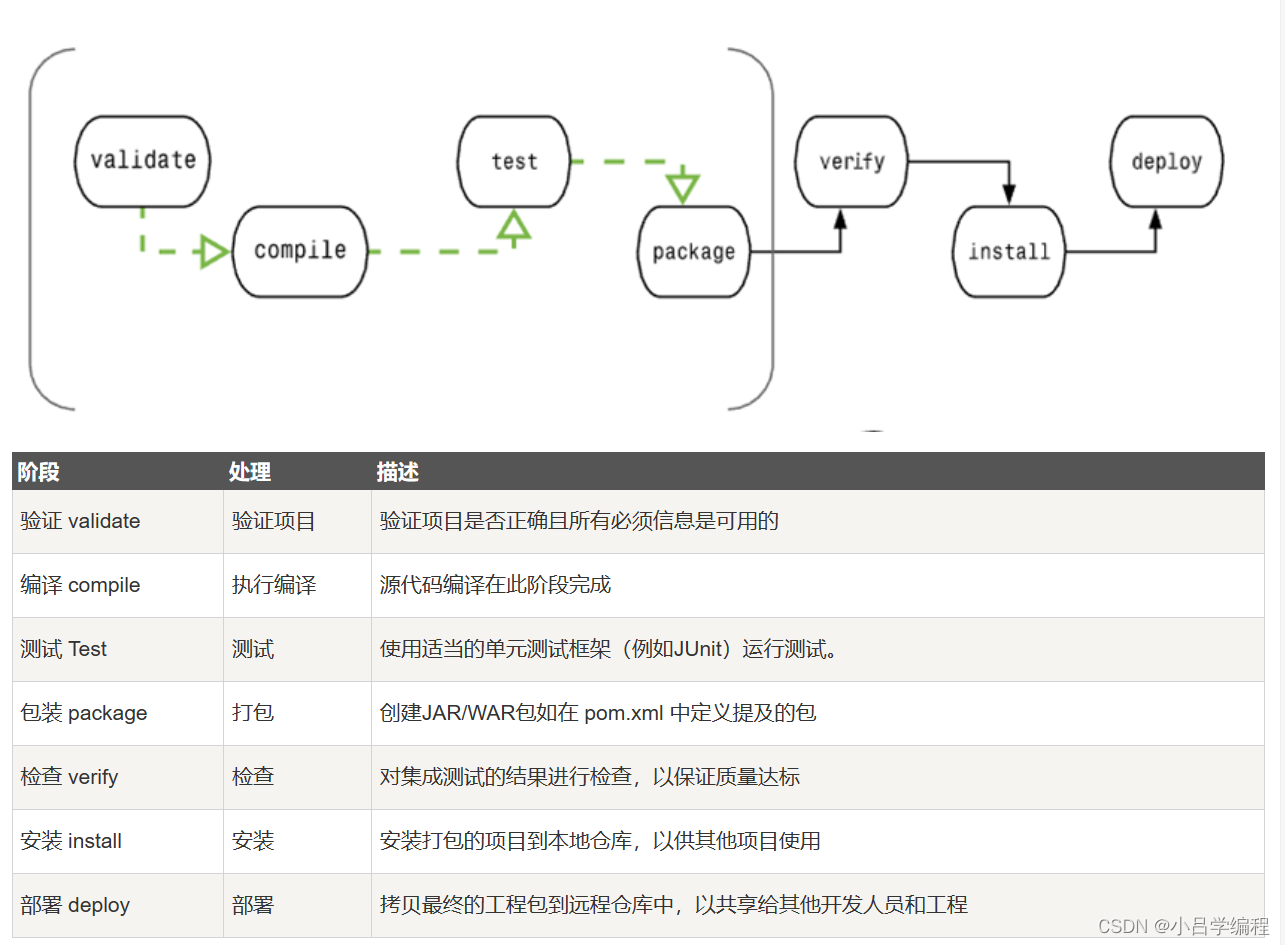
Maven的生命周期
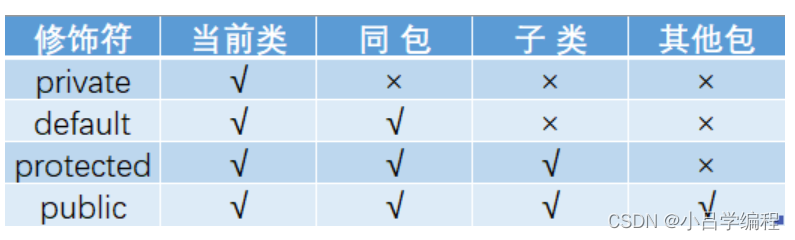
Java中的访问修饰符
空指针异常
当指针指向的内存地址是不存在的就会出现空指针异常
java中什么是空指针异常以及为什么会产生空指针异常_天上的云川的博客-CSDN博客
空指针异常主要原因以及解决方案_空指针异常是什么原因_小羊咩恩的博客-CSDN博客
Object类
Java Object 类是所有类的父类,也就是说 Java 的所有类都继承了 Object,子类可以使用 Object 的所有方法。
Java Object 类 | 菜鸟教程 (runoob.com)
重写equals不重写hashCode会怎样?
问:重写equals不重写hashCode会怎样? - 知乎 (zhihu.com)
String中常用方法
Java String 类 | 菜鸟教程 (runoob.com)
String s1 = new String("woshibendan");
System.out.println(s1.substring(2, 9));
System.out.println(s1.concat("ha"));
System.out.println(s1.indexOf("s"));
System.out.println(s1.endsWith("dan"));
System.out.println(s1);
System.out.println(s1.matches("[a-g]"));
System.out.println(s1.replace("wo", "ta"));
System.out.println(Arrays.toString(s1.toCharArray()));
System.out.println(s1.contains("wo"));
System.out.println(s1.toUpperCase());shibend
woshibendanha
2
true
woshibendan
false
tashibendan
[w, o, s, h, i, b, e, n, d, a, n]
true
WOSHIBENDAN
synchronized锁修饰静态方法和普通方法的区别
synchronized关键字修饰代码块_赶路人儿的博客-CSDN博客
JAVA----静态方法上加锁 和 非静态方法加锁 区别_java 静态方法加锁和非静态_NO0b的博客-CSDN博客
常见的异常
(1)NullPointerException 当应用程序试图访问空对象时,则抛出该异常。
(2)SQLException 提供关于数据库访问错误或其他错误信息的异常。
(3)IndexOutOfBoundsException指示某排序索引(例如对数组、字符串或向量的排序)超出范围时抛出。
(4)NumberFormatException当应用程序试图将字符串转换成一种数值类型,但该字符串不能转换为适当格式时,抛出该异常。
(5)FileNotFoundException当试图打开指定路径名表示的文件失败时,抛出此异常。
(6)IOException当发生某种I/O异常时,抛出此异常。此类是失败或中断的I/O操作生成的异常的通用类。
(7)ClassCastException当试图将对象强制转换为不是实例的子类时,抛出该异常。
(8)ArrayStoreException试图将错误类型的对象存储到一个对象数组时抛出的异常。
(9)IllegalArgumentException 抛出的异常表明向方法传递了一个不合法或不正确的参数。
(10)ArithmeticException当出现异常的运算条件时,抛出此异常。例如,一个整数“除以零”时,抛出此类的一个实例。
(11)NegativeArraySizeException如果应用程序试图创建大小为负的数组,则抛出该异常。
(12)NoSuchMethodException无法找到某一特定方法时,抛出该异常。
(13)SecurityException由安全管理器抛出的异常,指示存在安全侵犯。
(14)UnsupportedOperationException当不支持请求的操作时,抛出该异常。
(15)RuntimeExceptionRuntimeException 是那些可能在Java虚拟机正常运行期间抛出的异常的超类。
Stream流出现空指针异常
避免通过stream出现空指针异常,主动抛出的,使用orElse给一个预知的默认值,通过默认值处理当前数据
线上问题:stream获取值抛出空指针及源码分析_stream findfirst 空指针_天然玩家的博客-CSDN博客
Linux常用命令
移除文件目录以及所包含的文件
rm -rf 目录名字
- r 就是向下递归,不管有多少级目录,一并删除
- -f 就是直接强行删除,不作任何提示的意思
压缩文件备份
tar -zcvf ../../../../seeyon20230509.tar.gz seeyon
日志输出
tail -f
ls 列出当前目录下所有的文件和目录
cd ~ 回到自己的主目录
cd .. 回到当前目录的上一级目录
mkdir 创建目录(-p多级目录)
touch 创建一个或多个空文件
cat 要查看的文件名 (-n显示行号)
vim 编辑一个文件
线程
线程池启动线程 submit 和 execute 方法有什么不同
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
execute是Executor接口的方法,而submit是ExecutorService的方法,并且ExecutorService接口继承了Executor接口。
execute只接受Runnable参数,没有返回值;而submit可以接受Runnable参数和Callable参数,并且返回了Future对象,可以进行任务取消、获取任务结果、判断任务是否执行完毕/取消等操作。其中,submit会对Runnable或Callable入参封装成RunnableFuture对象,调用execute方法并返回。
线程池 shutDown 和 shunDownNow的区别
线程中run()和strart()方法的区别
strart():创建一个新的线程,创建好后线程处于就绪状态,等待被CPU调度
run():执行线程中的方法,当CPU调度到该线程时就会执行run方法,执行完后run()方法后,该线程也就终止了
runnable和callable的区别
runnable没有返回值,而实现callable接口的任务线程能返回执行结果
callable接口实现类中的run方法允许异常向上抛出,可以在内部处理,try catch,但是runnable接口实现类中run方法的异常必须在内部处理,不能抛出
用户线程和守护线程的区别
当用户线程执行完后,守护线程也会自动结束
并发和并行
并发:同一个CPU执行多个任务,按照时间片交替执行
并行:多个CPU上同时处理同个任务
线程的生命周期
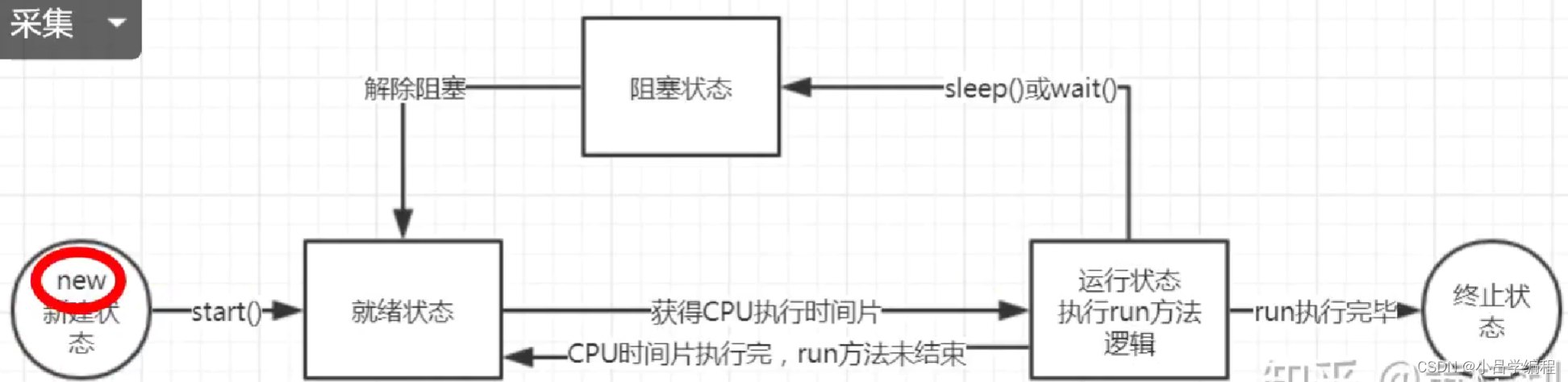
线程中seelp()和wait()方法的区别
| 位置 | 使用 | 唤醒 | 释放锁 | |
| seelp | Thread类 | 任何代码中都可以使用 | 自动唤醒 | 不释放锁 |
| wait | Object类 | 只能再同步方法块或同步方法中使用 | notify()方法唤醒 | 释放锁 |
其他
servlet生命周期
- 客户端发送请求
- Servlet容器负责解析请求,并创建Servlet实例
- Servlet容器调用Servlet的init方法
- Servlet容器调用Servlet的service方法
- Servlet容器将Servlet的响应结果返回给客户端
- 当Servlet重新加载或容器重启时,会调用Servlet的destroy方法
注意:
当Servlet已经被创建后再有请求过来,不会进行Servlet的创建和初始化
Servlet虽然是单例模式,但是依旧可能出现线程不安全的问题
JSP和servlet的区别和联系
servlet是服务端的Java程序,负责处理客户端请求。Jsp是servlet的一个扩展,jsp最后依旧会被编译成Java文件,class文件
XSS是什么如何预防
XSS:跨站点脚本攻击
其原理是王网页中添加恶意的执行脚本,比如js脚本
当用户点击或者浏览时,基本执行,从而达到攻击用户的目的
比如盗取cookie等
预防主要是通过拦截,比如说再前端使用富文本框,后端拦截数据,将一些可疑的字段进行替换和屏蔽
Spring
spring IOC
控制反转
优点:实现代码的解耦合
Srpring Aop

数据库
事务并发执行可能出现的问题
更新丢失、脏读、不可重复读、幻读

并发问题时丢失更新怎么做
乐观锁+版本号

数据库设计的三大范式
第一范式:列不可分
第二范式:要有主键
第三范式:不可存在传递依赖(一个order订单表只保存user_id,不保存user_name)
SQL注入
由于字符串拼接造成的,mybatis中preparedStatement对象和#防止sql注入
网络
http请求中状态码有哪些?
(203条消息) 常见接口状态码状态码_接口响应状态码_前端-卡布达的博客-CSDN博客
Http和https之前的区别
HTTP 是超文本传输协议,信息是明文传输,HTTPS 则是具有安全性的 SSL 加密传输协议。
HTTP 和 HTTPS 使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443
集合在遍历的时候可以随意添加删除吗?解决方案有什么?
Java中,直接对集合(如
List,Set)进行遍历时,如果尝试在遍历过程中修改集合的内容(添加、删除元素),则可能会抛出ConcurrentModificationException异常。
例如:以下代码会抛出ConcurrentModificationException异常
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
for (String item : list) {
if ("B".equals(item)) {
list.remove(item); // 这里会导致 ConcurrentModificationException
}
}
解决方案:
1.可以使用迭代器迭代的方式对数据进行修改和删除
ListIterator<String> listIterator = list.listIterator();
while (listIterator.hasNext()) {
String item = listIterator.next();
if ("B".equals(item)) {
listIterator.remove(); // 安全删除
} else if ("A".equals(item)) {
listIterator.add("D"); // 安全添加
}
}2.逆序遍历,以避免因删除操作导致的索引变化问题
import java.util.ArrayList;
import java.util.List;
public class CollectionRemoveExample {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
list.add("B");
// 逆序遍历,以避免因删除操作导致的索引变化问题
for (int i = list.size() - 1; i >= 0; i--) {
if ("B".equals(list.get(i))) {
list.remove(i); // 删除指定索引处的元素
}
}
// 打印剩余的集合元素
System.out.println(list);
}
}
为什么要逆序遍历?

spring中全局处理异常,有什么注解,说一下你的看法?
在Spring框架中,全局处理异常通常是通过@ControllerAdvice注解实现的。这个注解允许你在一个全局的位置定义一个或多个类作为控制器的增强,它们能应用到所有的@RequestMapping方法上。结合@ExceptionHandler注解,可以很容易地处理整个应用程序的异常。
例如,下面的代码展示了如何使用@ControllerAdvice和@ExceptionHandler来处理全局异常:
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
public ResponseEntity<String> handleException(Exception e) {
// 日志记录异常信息
// 返回包含错误详情的响应体
return new ResponseEntity<>("An error occurred: " + e.getMessage(), HttpStatus.INTERNAL_SERVER_ERROR);
}
@ExceptionHandler(SpecificException.class)
public ResponseEntity<String> handleSpecificException(SpecificException e) {
// 处理特定异常
return new ResponseEntity<>("A specific error occurred: " + e.getMessage(), HttpStatus.BAD_REQUEST);
}
// 可以继续添加更多的异常处理方法
}
在这个例子中,GlobalExceptionHandler类被标记为@ControllerAdvice,这意味着它会应用到所有的控制器上。在类内部,你可以定义多个方法并使用@ExceptionHandler来指明它们各自处理的异常类型。
使用@ControllerAdvice和@ExceptionHandler进行全局异常处理有以下几点优势:
- 集中管理:提供了一个集中的地方来处理所有控制器抛出的异常。
- 代码复用:可以避免在每个控制器里重复编写异常处理代码。
- 一致性:确保对于相同异常类型的处理是一致的,并且提供了统一的错误响应格式。
- 解耦:减少了业务逻辑代码和错误处理代码之间的耦合。
谈一谈你对死锁的理解?
预防死锁和解决死锁两个方面考量
死锁是指多个进程或事务在执行过程中,因争夺资源而造成的一种僵局现象。每个进程都持有一些资源并等待其他资源,这些资源又被其他进程持有,如果没有外部干预,这些进程无法向前推进。在数据库管理系统和操作系统中,都可能发生死锁。
数据库中的死锁通常涉及两个或更多的事务,它们相互等待对方释放锁定的资源。具体来说,在MySQL这样的数据库系统中,死锁可能发生在以下情况:
1. 两个或更多事务同时锁定了一部分共享资源,并且每个事务在完成之前需要获取对方已锁定的资源。
2. 事务在不同的顺序请求资源。
例如,在数据库中:
- 事务A锁定了数据行1,事务B锁定了数据行2。
- 事务A需要对数据行2进行操作,而事务B需要对数据行1进行操作。
- 因此,A等待B释放数据行2的锁,而B等待A释放数据行1的锁。
- 这会导致它们无限等待对方,从而形成死锁。为了处理死锁,数据库管理系统通常会实施一个死锁检测机制,并且采用两种主要方法之一解决死锁:
1. 超时:进程等待资源的时间超过了某个阈值后,就会释放它持有的所有资源并重新尝试操作。
2.死锁检测与解决:数据库系统周期性地运行死锁检测算法。如果检测到死锁,就会选择一个或多个事务来回滚,以便其他事务可以继续执行。系统选择回滚哪个事务可能取决于多种因素,例如事务已经执行的时间、事务的大小或优先级等。
为了避免死锁,可以采用以下预防措施之一:
- 确保事务按照相同的顺序请求资源。
- 将大事务分解成多个小事务,以减少长时间持有资源的情况。
- 使用SELECT ... FOR UPDATE或LOCK IN SHARE MODE来显式锁定涉及更新的记录,以减少隐式锁可能导致的死锁。
- 对数据库应用适当的索引以减少锁的范围。
- 增加重试机制,在事务因锁等待失败后进行重试。
- 增加重试机制,在事务因锁等待失败后进行重试。
TCP建立连接和关闭连接?TCP什么机制保证数据不丢失?出现问题如何解决?
TCP (Transmission Control Protocol) 是一种可靠的、面向连接的协议,它确保了数据在网络中正确、完整地从一个设备传输到另一个设备。TCP连接的建立和关闭都使用了一个控制消息的交换过程,通常被称为TCP三次握手(建立连接)和四次挥手(关闭连接)。
### TCP建立连接:三次握手 (Three-way Handshake)
1.SYN
- 客户端发送一个TCP段,段的标志位中SYN置为1,选择一个初始序列号x,并向服务器端发起连接请求。
- SYN代表同步序列编号(Synchronize Sequence Numbers)。2. SYN-ACK:
- 服务器接收到客户端的SYN请求后,需确认客户端的SYN(ACK=x+1),同时自己也发送一个SYN请求,这个SYN请求包含服务器的初始序列号y。
- 这样的段的标志位中SYN和ACK都被置为1。3.ACK:
- 客户端确认服务器的SYN(ACK=y+1),这个确认信息包含在ACK段中。
- 当服务器接收到这个ACK后,连接建立就完成了。在线路建立后,TCP传输可以进行两端数据的双向传输。
TCP关闭连接:四次挥手 (Four-way Handshake)
1. FIN:
- 当传输结束后,如果客户端想关闭连接,它会发送一个FIN段给服务器。
- FIN表示发送端已完成发送任务。2. ACK:
- 服务器收到这个FIN后,发送一个ACK给客户端。3. FIN:
- 一旦服务器也完成了数据的发送,它发送一个FIN给客户端来关闭这个方向的连接。4. ACK:
- 客户端收到后,回送一个ACK确认,并开始等待足够的时间以确保服务器接收到这个确认消息。这个“足够的时间”通常是指设置一个时间等待计时器(TIME_WAIT),以确保服务器接收到客户端的最终ACK。在这段时间内,确保了即使最后的ACK丢失,也可以重新传送FIN来终止连接。这个过程也确保了旧的连接在短时间内不会和新的连接混淆。
以上就是TCP建立和关闭连接的过程。这些机制确保了TCP的连接是可靠且有序的。
TCP(传输控制协议)通过以下几个关键特性和机制来确保数据的可靠传输,即保证数据不会丢失:
1. 序列号与确认应答(Sequence Numbers and Acknowledgments):
- TCP为每个发送的字节流分配一个序列号,并且接收方会发送确认回应(ACK)来告知发送方哪些数据已经被成功接收。
- 如果发送方没能收到ACK,它会假设数据丢失并重新发送这些数据。2. 数据段重传(Retransmissions):
- 如果因为超时(数据段在网络中丢失或延迟超出预定的时间)或收到重复的ACK(表明数据段可能丢失),TCP会重新发送任何未被确认的数据。4. 流量控制(Flow Control)
- TCP使用窗口大小来控制发送给接收方的数据量,以确保接收方有足够的缓冲空间来处理传入的数据,从而避免数据丢失。5.拥塞控制(Congestion Control)
- 拥塞控制通过算法如慢启动(Slow Start)和拥塞避免(Congestion Avoidance)、快重传(Fast Retransmit)和快恢复(Fast Recovery)来确保网络中的数据包不会因为网络拥塞而丢失。6. 保持活动探测(Keep-alive Check)
- TCP会定期发送保持活动探测数据,以检查另一端是否仍然可达和活动。这确保了即使在没有数据交换的情况下,连接也不会因为一方崩溃而永久打开状态。
如果出现TCP连接问题,可以采取以下手段进行诊断和解决:
1.检查网络连接
- 首先要检查基础的网络连接,包括网络接口、路由器、物理线路等是否正常工作。2. 使用网络诊断工具
- 使用`ping`检查网络连接是否可达。
- 使用`traceroute`(Linux)或`tracert`(Windows)跟踪数据包的路径到目的地,以确定连接中断的地点。
- 使用`netstat`检查本地端口的状态,查看是否正确监听和建立连接。
- 使用`tcpdump`或`Wireshark`等抓包工具来查看TCP交换的详细信息。3. 确认防火墙设置
- 确认本地和远程防火墙设置是否允许TCP连接的端口通信。4. 检查TCP设置
- 查看操作系统的TCP设置,包括窗口大小、重传尝试次数、时间等参数是否合理配置。
大文件上传异步处理失败怎么处理?重试是无脑重试还是阶梯重试?
处理大文件上传异步处理失败时,可以采取以下策略来处理:
记录失败信息:在异步处理失败时,记录失败的文件上传任务信息,包括文件信息、上传状态、错误原因等,以便后续处理和排查问题。
重试机制:实现重试机制可以尝试重新上传失败的文件。在选择重试策略时,可以考虑以下两种方式:
无脑重试:每次失败直接重试上传,适用于上传过程中失败的原因是偶发的、瞬时的情况。这种方式简单直接,但可能会导致过多的重试请求。
阶梯重试:设置重试次数和重试间隔,逐步增加重试间隔。例如,第一次失败后等待1分钟后重试,第二次失败后等待5分钟后重试,依次类推。这种方式可以防止短时间内频繁重试,有助于避免对服务端造成压力。
监控与报警:实现监控机制,及时发现异常情况并发送报警通知,以便及时处理问题。
人工介入处理:如果重试多次仍然无法成功,可能需要人工介入处理。例如,检查上传文件和服务端环境是否正常,或者通过日志分析等方式排查问题。
优化上传流程:考虑优化上传流程,例如增加断点续传功能、分片上传、压缩文件等,以确保大文件上传的稳定性和效率。
在选择重试策略时,需要根据具体情况综合考虑,阶梯重试相对于无脑重试更加稳妥,因为它可以减少系统的负载和提高系统稳定性。然而,重试次数和重试间隔也需要根据实际情况来设置,以平衡重试次数和上传任务的处理效率。
项目中JWT工作原理 以及登录时候账号密码传进来的安全措施(MD5?)
JWT(JSON Web Token)是由三部分组成的字符串,这三部分分别是头部(Header)、载荷(Payload)和签名(Signature):
头部(Header):头部通常由两部分组成,分别是令牌的类型(typ)和所使用的加密算法(alg)。头部用于描述JWT的元数据信息,并且会通过Base64编码进行编码。
示例头部:
复制代码
{ "typ": "JWT", "alg": "HS256" }载荷(Payload):载荷包含了要传输的声明(Claim),声明是关于实体(通常是用户)和其他数据的一种JSON对象。载荷中通常包含三种类型的声明:
- 注册声明(Registered Claim):预定义的一些声明,如Issuer(iss)、Subject(sub)、Expiration Time(exp)、Not Before(nbf)、Issued At(iat)和Audience(aud)等。
- 公共声明(Public Claim):自定义的声明,根据需要添加到载荷中。
- 私有声明(Private Claim):用于在双方之间共享信息,不会被注册声明覆盖。
示例载荷:
{ "sub": "1234567890", "name": "John Doe", "admin": true }签名(Signature):签名是使用头部指定的加密算法对头部、载荷和密钥进行签名生成的一段字符串,用于验证JWT的真实性和完整性。签名的生成方式是将Base64编码的头部和载荷以及密钥进行签名生成签名部分。
示例签名:
HMACSHA256( base64UrlEncode(header) + "." + base64UrlEncode(payload), secret )最终,将编码后的头部、载荷和签名通过点号(.)连接起来,形成最终的JWT字符串。JWT的结构如下所示:
base64UrlEncode(Header) + "." + base64UrlEncode(Payload) + "." + SignatureJWT的设计使其具有高度的灵活性和安全性,可以在网络中安全地传输声明信息,并且可以轻松地进行验证和解码。
JWT(JSON Web Token)是一种用于在网络间传递声明的令牌(Token)标准。其工作原理如下:
用户登录:用户使用用户名和密码进行登录验证,服务端验证用户身份,如果验证成功,则生成一个包含用户身份信息的JWT。
JWT生成:服务端生成JWT,将用户的身份信息(如用户ID)和其他必要的信息(如过期时间、签名等)进行编码,然后使用密钥对其签名,最后将编码后的JWT返回给客户端。
请求携带JWT:客户端收到JWT后,将其存储在本地(如LocalStorage或Cookie)或者每次请求时携带在请求的Header中。
请求验证:客户端每次请求时需要在Header中携带JWT,服务端收到请求后对JWT进行验证,验证通过后,认为用户是经过身份验证的,可以进行相应的操作。
关于账号密码传输的安全措施,一般包括以下几个方面:
HTTPS协议:使用HTTPS协议进行数据传输,通过SSL/TLS加密数据,防止数据在传输过程中被窃取或篡改。
密码加密:在用户登录时,对用户输入的密码进行加密处理,一种常见的做法是使用哈希算法对密码进行加密,例如MD5、SHA-1、SHA-256等。但需要注意的是,单独使用MD5等哈希算法可能存在碰撞和彩虹表攻击,推荐使用加盐(Salt)和多次迭代(Iterations)的方式增加密码的安全性。
密码传输加密:在用户输入账号密码传输至服务端时,使用安全的传输协议(如HTTPS)确保数据传输过程中的安全。
防止暴力破解:采取措施限制用户登录尝试次数,如验证码验证、增加延时等,防止暴力破解。
综上所述,结合JWT的工作原理和密码传输的安全措施,可以有效保障用户账号密码在登录过程中的安全性。
D5(Message Digest Algorithm 5)是一种常用的哈希算法,通常用于生成密码的哈希值。在用户登录时,通常会将用户输入的密码使用MD5进行加密处理,然后将加密后的哈希值存储到数据库中。当用户再次登录时,系统会将用户输入的密码进行MD5加密后,与数据库中存储的哈希值进行比对来验证用户身份。
虽然MD5在过去被广泛使用,但由于其存在一些安全性漏洞,现在不再推荐单独使用MD5来加密密码,主要原因包括:
碰撞攻击:MD5算法存在碰撞的风险,即不同的输入可能会生成相同的哈希值,这可能会被恶意用户利用。
彩虹表攻击:MD5的哈希值是固定长度的,攻击者可以通过预先生成的彩虹表来快速破解哈希值,从而得到原始密码。
因此,在使用MD5进行密码加密时,应该结合其他安全措施来增强密码的安全性,例如:
加盐(Salt):在对密码进行MD5加密之前,使用一个随机生成的盐值与密码进行组合,然后再进行MD5加密。盐值可以使相同的密码在不同用户之间生成不同的哈希值,增加破解的难度。
多次迭代(Iterations):对密码进行多次MD5加密,每次都使用不同的盐值,增加破解的难度。
使用更安全的哈希算法:替代MD5,可以选择更安全的哈希算法,如SHA-256、SHA-512等。
结合其他安全措施:除了密码哈希,还应该采取其他安全措施,如HTTPS传输、防止暴力破解等,来保护用户密码的安全。
综上所述,MD5加密是一种单向哈希算法,可以用于密码加密,但应该结合其他安全措施来增强密码的安全性,防止常见的攻击手段。
JDBC的流程步骤
JDBC(Java Database Connectivity)是Java语言用于执行与数据库交互的标准API。通过JDBC,Java应用程序可以连接到不同的数据库,并执行SQL查询、更新和管理数据库。下面是使用JDBC进行数据库操作的一般流程步骤:
加载数据库驱动程序:在使用JDBC之前,需要加载适合数据库的驱动程序。可以通过
Class.forName("com.mysql.cj.jdbc.Driver")来加载MySQL数据库的驱动程序。建立数据库连接:使用数据库连接字符串、用户名和密码来建立与数据库的连接。可以通过
Connection connection = DriverManager.getConnection(url, username, password)来获取数据库连接对象。创建SQL语句:使用SQL语句来执行数据库操作,如查询数据、更新数据等。可以通过
Statement、PreparedStatement或CallableStatement来创建相应的SQL语句对象。执行SQL语句:通过执行SQL语句对象的
executeQuery()(用于SELECT操作)、executeUpdate()(用于INSERT、UPDATE、DELETE操作)等方法来执行SQL语句。处理结果集:如果执行的SQL语句是SELECT语句,需要通过结果集对象来获取查询结果。可以使用
ResultSet对象来遍历查询结果并获取数据。关闭资源:在使用完数据库连接、SQL语句和结果集后,需要手动关闭这些资源,以释放数据库连接和节省资源。可以通过
close()方法来关闭连接、语句和结果集。以下是一个简单的示例代码,演示了使用JDBC连接到MySQL数据库、执行查询、获取结果和关闭资源的流程:
import java.sql.*;
public class JDBCDemo {
public static void main(String[] args) {
try {
// 加载MySQL驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");
// 建立数据库连接
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydatabase", "username", "password");
// 创建并执行SQL查询
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT * FROM users");
// 处理查询结果
while(resultSet.next()) {
System.out.println(resultSet.getInt("id") + " " + resultSet.getString("name"));
}
// 关闭资源
resultSet.close();
statement.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
mybatis的流程步骤
MyBatis是一个持久层框架,用于简化Java应用程序与数据库之间的交互。MyBatis的核心原则是将SQL语句和Java方法解耦,提供了一种通过简单的XML或注解配置来映射Java对象和SQL语句的方式。下面是MyBatis的基本流程步骤:
配置文件:首先,需要创建MyBatis的配置文件,其中包含数据库连接信息、映射文件路径、类型别名等配置信息。
映射文件:创建映射文件,该文件定义了Java对象和数据库表之间的映射关系,包括SQL语句、参数映射、结果映射等。
定义数据模型:定义Java对象或POJO(Plain Old Java Object)类,用于映射数据库表的记录。
SqlSessionFactory的创建:通过MyBatis提供的SqlSessionFactoryBuilder来加载配置文件,创建SqlSessionFactory对象。
SqlSession的获取:通过SqlSessionFactory对象获取SqlSession实例,SqlSession提供了对数据库的增删改查等操作。
执行SQL语句:在SqlSession中调用相应的方法执行SQL语句,如select、insert、update、delete等。
返回结果:执行SQL语句后,MyBatis会将查询结果封装成Java对象或集合,并返回给调用者。
提交事务:在需要的情况下,可以通过SqlSession提交事务,保证操作的原子性和一致性。
关闭SqlSession:在完成数据库操作后,需要手动关闭SqlSession,释放资源。
总的来说,MyBatis的流程是先配置文件、映射表、定义数据模型,然后创建SqlSessionFactory,获取SqlSession执行SQL语句,返回结果,提交事务,最后关闭SqlSession。通过这些步骤,开发人员可以方便地进行数据库操作,提高开发效率。
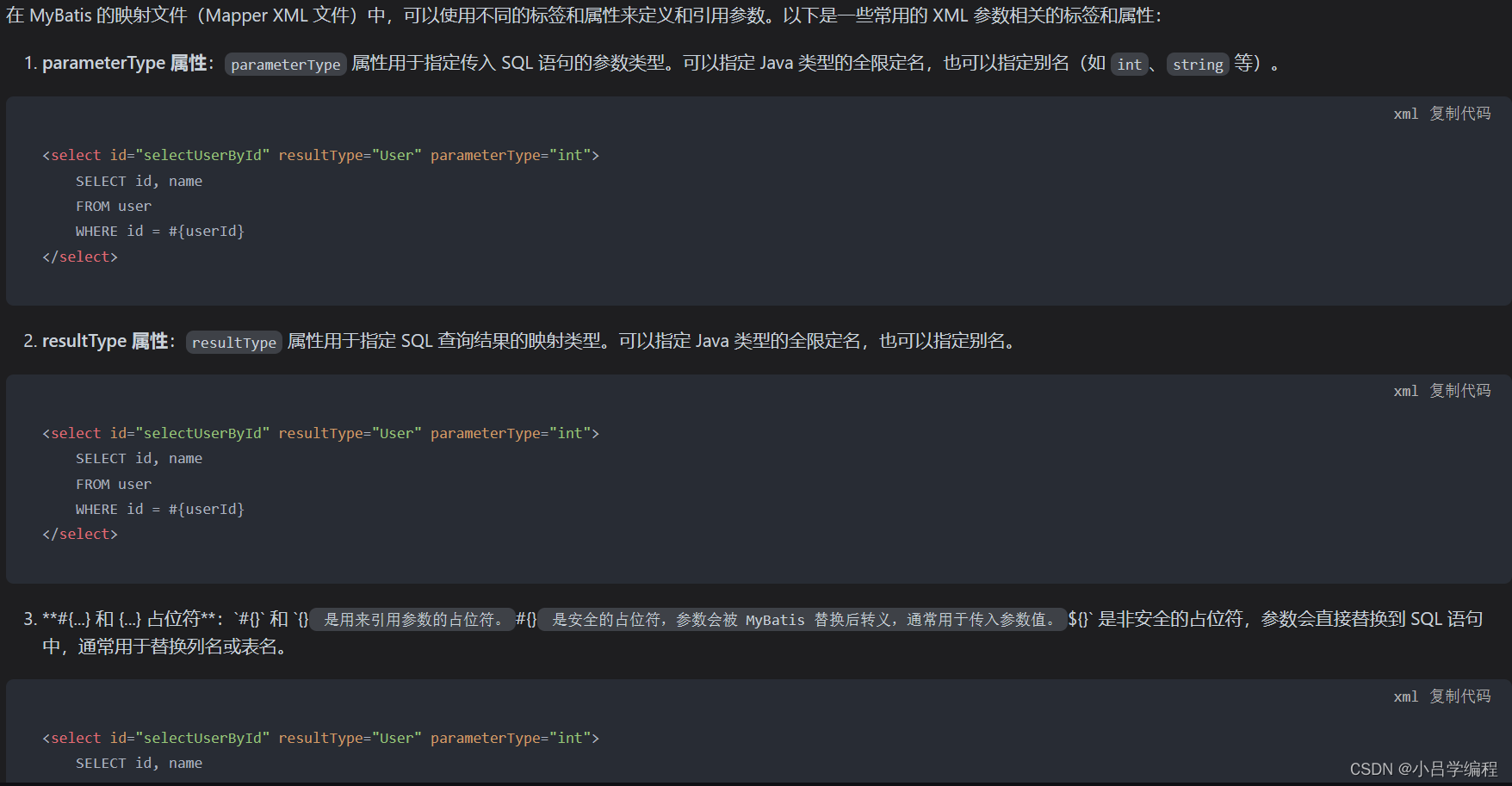
MyBatis 映射文件xml参数有哪些?
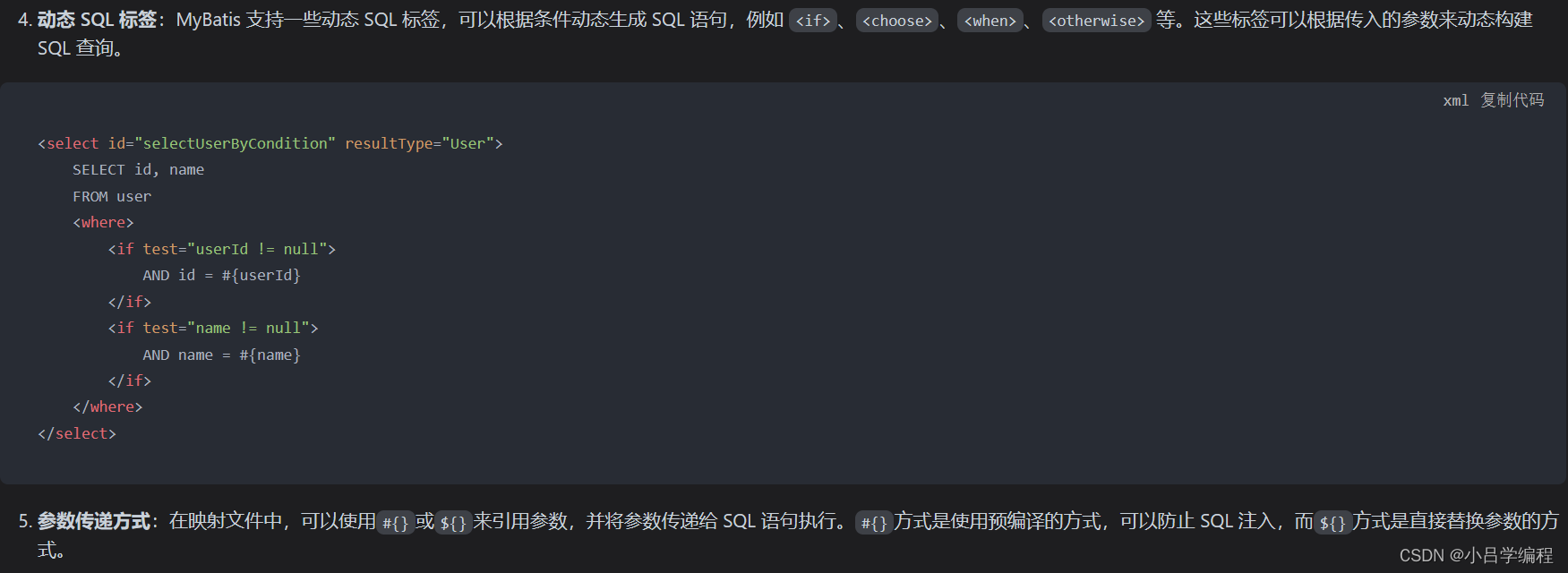
Concurrent并发包下有哪些类
Atomic 包:
AtomicInteger、AtomicLong、AtomicBoolean:提供原子操作的整数、长整数和布尔类型。AtomicReference、AtomicStampedReference:提供原子引用类型的操作。Locks 锁:
ReentrantLock:可重入锁,提供与 synchronized 关键字类似的锁功能。ReadWriteLock、ReentrantReadWriteLock:读写锁,允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。Collections 集合:
ConcurrentHashMap:线程安全的哈希表实现。CopyOnWriteArrayList、CopyOnWriteArraySet:支持并发读写的列表和集合。Executors 线程池:
Executor、ExecutorService:执行器接口和执行器服务接口。ThreadPoolExecutor、ScheduledThreadPoolExecutor:线程池实现类,支持定时执行任务。CountDownLatch、CyclicBarrier、Semaphore:分别用于控制线程等待、同步协作和并发访问的工具类。
AtomicInteger的用法代码实例
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicIntegerExample {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(0); // 创建初始值为 0 的 AtomicInteger 对象
// 使用 get() 方法获取当前值
System.out.println("初始值:" + atomicInteger.get());
// 使用 incrementAndGet() 方法递增并获取新值
int newValue = atomicInteger.incrementAndGet();
System.out.println("递增后的值:" + newValue);
// 使用 compareAndSet() 方法进行比较和设置操作
int expectedValue = 1;
int updateValue = 5;
boolean success = atomicInteger.compareAndSet(expectedValue, updateValue); // 若当前值等于期望值,则更新为新值
if (success) {
System.out.println("比较并设置成功,新值为:" + atomicInteger.get());
} else {
System.out.println("比较并设置失败,当前值为:" + atomicInteger.get());
}
}
}
ConcurrentHashMap是如何实现线程安全的
ConcurrentHashMap是 Java 并发包中提供的线程安全的哈希表实现,它通过一些技术和机制来保证多线程环境下的线程安全性。以下是ConcurrentHashMap是如何实现线程安全的几个关键点:
分段锁(Segment):
ConcurrentHashMap使用了分段锁的机制,将整个哈希表分成多个段(Segment),每个段拥有自己的锁。当需要对某个键值对进行操作时,只需要锁住对应段,而不是整个哈希表,这样可以提高并发性能。读写分离:
ConcurrentHashMap允许多个线程同时进行读取操作,不会阻塞。在读取操作时,不需要加锁,只有在写入操作时才需要加锁。这种读写分离的设计提高了并发读取性能。CAS 操作:
ConcurrentHashMap使用 CAS(Compare and Swap)操作来保证原子性。CAS 是一种乐观锁机制,通过比较当前值和期望值来判断是否进行更新操作,避免了加锁的开销,提高了并发性能。
怎末使用Sentinel实现限流,限流算法有哪些?
限流操作是一种控制系统中的流量,以确保其在可接受范围内工作的方法。常见的限流算法包括:
令牌桶算法:系统以恒定的速率往令牌桶中放入令牌,每当请求到来时,需要从令牌桶中获取令牌,如果没有足够的令牌,则请求会被限流。
漏桶算法:类似于一个水桶,系统以恒定速率往桶中加水,当请求到来时,需要从桶中取水,如果桶已满,则请求被限流。
计数器算法:系统对请求进行计数,当请求到达一定数量时触发限流,如设置一个阈值,超过该阈值则限制请求通过。
这些算法通常用于网络通信中或者分布式系统中,以确保系统不被过多请求压垮。不同的情况下可能需要选择不同的限流算法来确保系统稳定运行。
要使用Sentinel实现限流,可以按照以下步骤进行:
引入Sentinel依赖:首先,在项目的
pom.xml文件中添加Sentinel的依赖,以便在项目中使用Sentinel的功能。配置限流规则:在代码中配置限流规则,可以通过注解或者手动代码方式配置。可以定义资源名称、限流阈值、限流策略等。
初始化Sentinel:在应用启动时,需要初始化Sentinel,可通过调用相应的初始化方法完成,确保限流规则生效。
使用限流功能:在需要限流的地方,例如接口方法或者服务调用处,使用Sentinel提供的API来实现限流控制,确保系统在高压力情况下能够稳定运行。
监控和调优:通过Sentinel的可视化监控界面查看限流情况,根据实际情况对限流策略进行调整和优化,以保证系统的性能和稳定性。
通过以上步骤,可以在Java应用中使用Sentinel实现灵活和强大的限流功能,有效地保护系统免受高负载的影响。Sentinel提供了丰富的功能和配置选项,可以根据实际需求进行定制化的限流策略。
策略模式
以下是一个使用策略模式的简单Java代码示例:
首先,定义一个策略接口
PaymentStrategy:public interface PaymentStrategy { void pay(double amount); }然后,实现两种具体的支付策略:
CreditCardPaymentStrategy和PaypalPaymentStrategy:public class CreditCardPaymentStrategy implements PaymentStrategy { @Override public void pay(double amount) { System.out.println("Paid " + amount + " using Credit Card"); } } public class PaypalPaymentStrategy implements PaymentStrategy { @Override public void pay(double amount) { System.out.println("Paid " + amount + " using Paypal"); } }接下来,定义一个上下文类
PaymentContext,用于执行支付操作并持有当前使用的支付策略:public class PaymentContext { private PaymentStrategy paymentStrategy; public PaymentContext(PaymentStrategy paymentStrategy) { this.paymentStrategy = paymentStrategy; } public void executePayment(double amount) { this.paymentStrategy.pay(amount); } }最后,我们可以在客户端代码中使用策略模式:
public class Client { public static void main(String[] args) { PaymentContext paymentContextCreditCard = new PaymentContext(new CreditCardPaymentStrategy()); paymentContextCreditCard.executePayment(100.0); PaymentContext paymentContextPaypal = new PaymentContext(new PaypalPaymentStrategy()); paymentContextPaypal.executePayment(50.0); } }在上面的示例中,我们定义了两种支付策略:CreditCardPaymentStrategy 和 PaypalPaymentStrategy,并在客户端代码中通过 PaymentContext 来执行支付操作,并根据需要选择不同的支付策略。这样可以方便地切换支付策略,而不需要修改客户端代码。这就是策略模式的简单实现示例。
SQL中的varchar和char
在SQL中,
CHAR和VARCHAR是用于存储字符串数据类型的两种不同方式。它们在使用场景和性能上有所不同,理解它们的区别对于数据库设计和优化非常重要。以下是对CHAR和VARCHAR的详细说明。CHAR 数据类型
CHAR(固定长度字符类型)用于存储定长的字符串。无论存储的数据实际长度是多少,都会占用指定的固定长度空间。如果存储的数据长度小于定义的长度,会用空格填充剩余空间。特点:
- 固定长度:无论实际存储的数据长度是多少,
CHAR类型都会占用定义时指定的固定长度。- 填充空格:如果存储的数据长度小于定义的长度,会用空格(
' ')填充。- 性能:由于是固定长度,
CHAR在处理定长数据时性能较好,尤其适用于长度固定的字段,例如国家代码、邮政编码等。- 浪费空间:对于长度变化较大的数据,
CHAR可能会浪费存储空间。示例:
CREATE TABLE Users (
username CHAR(10) -- 无论实际用户名长度是多少,都占用10个字符的空间
);
INSERT INTO Users (username) VALUES ('Alice');
-- 实际存储的值是 'Alice ',后面有五个空格
VARCHAR 数据类型
VARCHAR(可变长度字符类型)用于存储变长的字符串。存储的数据长度是实际数据的长度加上一个额外的字节(用来存储该长度)。如果存储的数据长度小于或等于定义的长度,就只占用实际数据的空间。特点:
- 可变长度:
VARCHAR类型根据实际数据的长度进行存储,不会占用额外的固定空间。- 无填充:
VARCHAR不会用空格填充未使用的空间。- 灵活性:适用于长度不固定的字段,如名字、地址、描述等。
- 性能:由于需要额外存储长度信息,并且数据长度不固定,
VARCHAR的性能在某些情况下可能不如CHAR,但非常适合存储变长数据以节省空间。示例:
CREATE TABLE Users (
username VARCHAR(10) -- 只占用实际用户名长度的空间
);
INSERT INTO Users (username) VALUES ('Alice');
-- 实际存储的值是 'Alice',没有额外的空格
在这种情况下:
username列会为每个用户名占用10个字符的空间,即使实际用户名长度小于10。description列会根据实际描述的长度来占用空间,不会浪费额外的存储空间。总结来说,
CHAR和VARCHAR各有优缺点,选择哪种数据类型应根据具体使用场景来决定。理解它们的区别有助于优化数据库的性能和存储效率。
补充:一个汉字占用多少字符,和字节
在计算机处理中,字符和字节是两个不同的概念,用于存储和表示数据。对于中文汉字,占用的字符和字节数取决于所使用的编码方式。
字符和字节的区别
- 字符:字符是文字或符号的基本单位,表示一个独立的文字或符号,如一个字母、一个汉字等。
- 字节:字节是计算机存储数据的基本单位。一个字节通常等于8位(bit)。
中文汉字在不同编码方式下的占用
ASCII编码
- ASCII编码:仅用于表示英文字符和一些控制字符,不支持中文汉字。每个字符占用1个字节。
GB2312编码
- GB2312编码:是中国国家标准简体中文字符集,用于表示简体中文字符。每个中文汉字占用2个字节。
GBK编码
- GBK编码:是GB2312的扩展,支持更多汉字和一些其他字符。每个中文汉字占用2个字节。
UTF-8编码
- UTF-8编码:是一种可变长度的Unicode编码方式,用于表示世界上所有的字符。中文汉字在UTF-8中通常占用3个字节。
UTF-16编码
- UTF-16编码:是一种定长或变长的Unicode编码方式。大多数中文汉字在UTF-16中占用2个字节,但一些稀有汉字可能占用4个字节。
UTF-32编码
- UTF-32编码:是一种固定长度的Unicode编码方式,每个字符(包括中文汉字)占用4个字节。
示例
假设我们使用不同的编码方式存储中文汉字“汉”:
GB2312编码:
汉 -> 2个字节GBK编码:
汉 -> 2个字节UTF-8编码:
汉 -> 3个字节UTF-16编码:
汉 -> 2个字节UTF-32编码:
汉 -> 4个字节总结
- 一个中文汉字在大多数情况下被视为一个字符。
- 一个中文汉字占用的字节数取决于所使用的编码方式:
- 在GB2312和GBK编码下,通常占用2个字节。
- 在UTF-8编码下,通常占用3个字节。
- 在UTF-16编码下,通常占用2个字节(但有些复杂字符可能占用4个字节)。
- 在UTF-32编码下,占用4个字节。
理解这些编码方式的差异对于处理多语言文本、存储和传输数据是非常重要的。
CurrentHashMap和HashMap区别,以及CurrentHashMap的使用场景
public static void main(String[] args) throws InterruptedException {
//基本操作
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
// 添加键值对
map.put("key1", 1);
map.put("key2", 2);
// 获取值
Integer value1 = map.get("key1"); // 返回 1
System.out.println(value1);
// 移除键值对
map.remove("key2");
// 检查键是否存在
boolean containsKey1 = map.containsKey("key1"); // 返回 true
boolean containsKey2 = map.containsKey("key2"); // 返回 false
// 检查值是否存在
boolean containsValue1 = map.containsValue(1); // 返回 true
boolean containsValue2 = map.containsValue(2); // 返回 false
System.out.println(containsKey1);
System.out.println(containsKey2);
System.out.println(containsValue1);
System.out.println(containsValue2);
//高级操作
// 如果键不存在,则添加键值对
map.putIfAbsent("key1", 11);
map.putIfAbsent("key3", 33);
// 替换键的值
map.replace("key1", 1, 2);
// 计算并添加键值对
map.computeIfAbsent("key2", key -> 2);
// 计算并更新键值对
map.computeIfPresent("key1", (key, value) -> value + 1);
// 使用默认值
Integer value = map.getOrDefault("key3", 0); // 返回 0
System.out.println(map);
//遍历
map.put("key1", 1);
map.put("key2", 2);
// 使用 forEach 方法
map.forEach((key, value2) -> {
System.out.println(key + ": " + value2);
});
// 使用迭代器
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
//多线程情况下并发访问
HashMap<String, Integer> map1 = new HashMap<>();
Runnable task1 = () -> {
for (int i = 0; i < 1000; i++) {
map.put("k" + i, i);
map1.put("k" + i, i);
}
};
Runnable task2 = () -> {
for (int i = 0; i < 1000; i++) {
map.put("k" + i, i);
map1.put("k" + i, i);
}
};
Thread thread1 = new Thread(task1);
Thread thread2 = new Thread(task2);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("Map size: " + map.size());
System.out.println("Map1 size: " + map1.size());
}运行结果:
1
true
false
true
false
{key1=3, key2=2, key3=33}
key1: 1
key2: 2
key3: 33
key1: 1
key2: 2
key3: 33
Map size: 1003
Linux怎么把一个文件传到另一台服务器
在Linux中,将文件从一台服务器传输到另一台服务器可以通过多种方法完成,其中一些最常用的方法包括使用
scp(secure copy)、rsync和sftp。以下是这些方法的具体说明和使用例子:1. 使用
scp命令
scp命令是基于 SSH 的,它用于在两台服务器之间安全地复制文件和目录。这是一个简单而且广泛使用的选择。基本语法:
scp [OPTION] [user@]SRC_HOST:]file1 [user@]DEST_HOST:]file2例子: 假设您想把本地文件
example.txt传输到远程服务器的/home/username目录,您可以使用:scp example.txt username@remote_host:/home/username/这里,
username是远程服务器的用户名,remote_host是远程服务器的IP地址或者主机名。2. 使用
rsync命令
rsync是一个更为强大的工具,它用于同步文件和目录到远程系统。rsync可以有效地更新只在文件的一部分发生变化的文件,而不需要重新传输整个文件。基本语法:
rsync [OPTION]... SRC [SRC]... [user@]DEST_HOST:DEST例子
rsync -avz example.txt username@remote_host:/home/username/这里
-a是归档模式,-v表示详细模式,-z表示压缩数据。3. 使用
sftp命令
sftp(SSH File Transfer Protocol) 是另一种基于SSH的文件传输工具,它提供了一个交互式的界面。使用方式:
sftp username@remote_host连接后,您可以使用
put命令上传文件:put local_file.txt /remote/directory/remote_file.txt注意:
- 确保您在远程服务器上有足够的权限来写入目标目录。
- 对于
scp和sftp,您可能需要输入远程服务器用户的密码,除非您已经设置了SSH密钥认证。- 如果防火墙阻止了这些端口,您可能需要先在服务器上开放SSH端口(通常是22)。
使用这些工具可以有效地在Linux服务器之间传输文件,选择哪个工具取决于您的具体需求,比如是否需要加密传输,是否频繁同步大量数据等。
了解哪些加密算法,对称加密算法和非对称加密算法的区别,https中有哪些加密算法?
HTTPS(HyperText Transfer Protocol Secure)是一种通过加密和认证保护数据传输安全的网络协议。HTTPS使用加密算法来保护通过网络传输的数据。以下是一些常见的加密算法和协议被用于HTTPS中:
1. 对称加密算法
对称加密算法使用相同的密钥来加密和解密数据。在HTTPS中,对称加密算法通常用于加密传输过程中的数据。一些常见的对称加密算法包括:
- AES(Advanced Encryption Standard):目前是最常用的对称加密算法之一。
- DES(Data Encryption Standard):已经被AES取代,但仍然有一定的应用。
- 3DES(Triple Data Encryption Standard):是DES的改进版本,提供更强的安全性。
2. 非对称加密算法
非对称加密算法使用一对密钥:公钥和私钥。数据由公钥加密,只能由对应的私钥解密。在HTTPS中,非对称加密算法用于建立安全连接和传送对称密钥。一些常见的非对称加密算法包括:
- RSA(Rivest-Shamir-Adleman):广泛使用于数字签名和密钥交换。
- ECC(Elliptic Curve Cryptography):提供相同安全性的情况下更短的密钥长度。
3. 散列算法(哈希算法)
散列算法用于生成数据的固定大小的散列值,通常用于验证数据完整性。在HTTPS中,散列算法常用于数字签名和生成摘要。一些常见的散列算法包括:
- SHA-256:SHA-2家族中的一种,生成256位散列值。
- MD5:已经不安全,不推荐使用。
- SHA-1:已经不安全,不推荐使用。
4. 密钥交换算法
在HTTPS连接建立时,需要使用密钥交换算法来安全地交换对称密钥。一些常见的密钥交换算法包括:
- Diffie-Hellman(DH):用于安全地交换密钥而不泄露密钥本身。
- ECDH(Elliptic Curve Diffie-Hellman):基于椭圆曲线的密钥交换算法。
总的来说,HTTPS使用一系列加密算法来保护数据传输的机密性、完整性和身份认证。这些加密算法的选择往往取决于安全性需求、性能要求和标准化的考量。不断地更新和替代弱加密算法是保障数据安全的重要举措。
对称加密算法和非对称加密算法各有其优点和缺点,它们通常在不同的场景中使用,以满足不同的安全需求和解决不同的安全问题。以下是为什么同时存在对称加密和非对称加密算法的原因:
1. 密钥管理
- 对称加密算法:对称加密算法使用相同的密钥来加密和解密数据,因此密钥管理相对简单。然而,由于需要双方共享相同的密钥,密钥交换的安全性和密钥分发是一个挑战。
- 非对称加密算法:非对称加密算法使用一对密钥:公钥和私钥。公钥可以公开分享,而私钥必须保持机密。这种模式可以解决密钥交换和分发的问题,提供更好的密钥管理。
2. 安全性
- 对称加密算法:对称加密算法在加密和解密速度方面效率高,但由于双方共享相同密钥,如果密钥被泄露,整个通信就会受到威胁。
- 非对称加密算法:非对称加密算法提供更好的安全性,因为公钥可以公开分享,私钥保持私密。即使公钥泄露,数据仍然安全,只有拥有私钥的一方才能解密数据。
3. 数字签名和身份验证
- 非对称加密算法:非对称加密算法用于数字签名和身份验证。发送方使用自己的私钥对数据签名,接收方使用发送方的公钥验证数据的来源和完整性。
4. 性能
- 对称加密算法:对称加密算法通常比非对称加密算法更快,因为它们使用相同的密钥加密和解密数据。
- 非对称加密算法:非对称加密算法通常比对称加密算法慢,但在特定场景下提供更好的安全性和功能。
综上所述,对称加密算法和非对称加密算法在不同的安全需求和场景中起着不同的作用,它们通常结合使用以提供更全面的安全保护。通过结合这两种加密算法,可以在保障数据传输的安全性的同时提高效率和灵活性。
springboot如何封装了一个错误的类,是如何封装的呢?(有哪些属性?错误码/错误信息)
/**
* 全局异常处理
*/
@Slf4j
@RestControllerAdvice
public class GlobalExcepitonHandler {
/**
* 处理Assert的异常
*/
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(value = IllegalArgumentException.class)
public Result handler(IllegalArgumentException e) throws IOException {
log.error("Assert异常:-------------->{}",e.getMessage());
return Result.fail(e.getMessage());
}
/**
* @Validated 校验错误异常处理
*/
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(value = MethodArgumentNotValidException.class)
public Result handler(MethodArgumentNotValidException e) throws IOException {
log.error("运行时异常:-------------->",e);
BindingResult bindingResult = e.getBindingResult();
ObjectError objectError = bindingResult.getAllErrors().stream().findFirst().get();
return Result.fail(objectError.getDefaultMessage());
}
@ResponseStatus(HttpStatus.BAD_REQUEST)
@ExceptionHandler(value = RuntimeException.class)
public Result handler(RuntimeException e) throws IOException {
log.error("运行时异常:-------------->",e);
return Result.fail(e.getMessage());
}
}
如果要深拷贝一个数组,如何实现效果最好?
深拷贝基本类型数组:
使用
Arrays.copyOf()
int[] original = {1, 2, 3, 4, 5}; int[] copy = Arrays.copyOf(original,original.length);使用循环遍历
int[] original = {1, 2, 3, 4, 5};
int[] copy = new int[original.length];
for (int i = 0; i < original.length; i++) {
copy[i] = original[i];
}对象数组:
使用序列化
面向对象
生活场景示例:图书馆管理系统
场景描述: 假设你需要设计一个简单的图书馆管理系统。该系统需要处理图书的入库、借阅和归还过程。图书馆中的每本书和每位用户都应该是对象。
关键概念:
- 类和对象:图书、用户
- 属性:书名、作者、ISBN号;用户的姓名、用户ID
- 方法:借书、还书、搜索书籍
- 继承:特化图书类型(如参考书、小说等)
- 封装:隐藏内部实现,提供公共接口
- 多态性:对不同类型的用户(如学生、教师)执行借书操作
class Book {
private String title;
private String author;
private String ISBN;
public Book(String title, String author, String ISBN) {
this.title = title;
this.author = author;
this.ISBN = ISBN;
}
public String getTitle() {
return title;
}
public String getAuthor() {
return author;
}
public String getISBN() {
return ISBN;
}
}
class User {
private String name;
private int userId;
public User(String name, int userId) {
this.name = name;
this.userId = userId;
}
public void borrowBook(Book book) {
System.out.println(name + " borrowed the book: " + book.getTitle());
}
public void returnBook(Book book) {
System.out.println(name + " returned the book: " + book.getTitle());
}
}
public class Library {
public static void main(String[] args) {
Book book1 = new Book("Java Programming", "James Gosling", "123456789");
User user1 = new User("Alice", 001);
user1.borrowBook(book1);
user1.returnBook(book1);
}
}
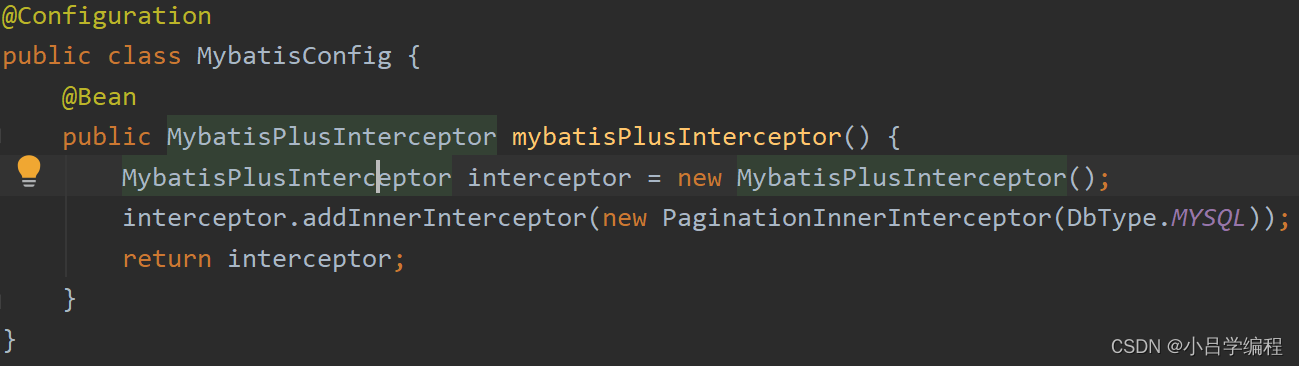
项目中如何将第三方的类注入Bean中
使用 @Configuration 和 @Bean 注解
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









