






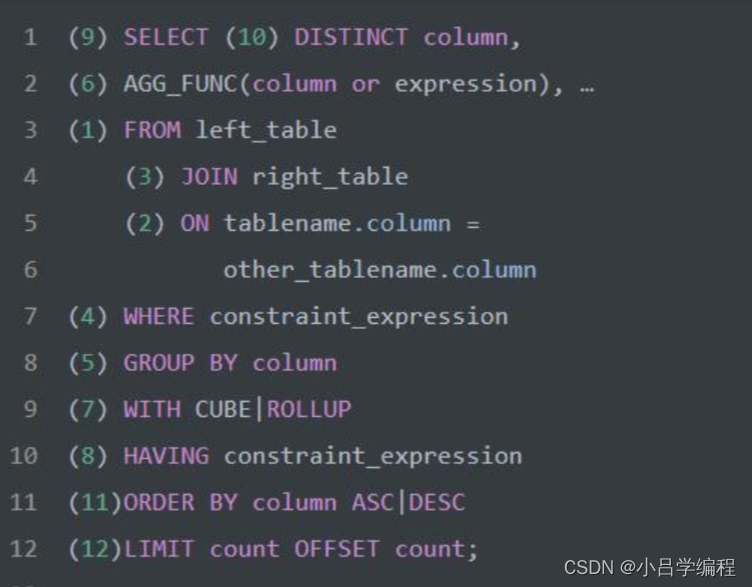
SQL执行顺序
- FROM 子句:指定要查询的表或视图。
- WHERE 子句:筛选满足特定条件的行。
- GROUP BY 子句:将结果按照指定的列进行分组。
- HAVING 子句:筛选满足特定条件的分组。
- SELECT 子句:选择要返回的列。
- ORDER BY 子句:按照指定的列对结果进行排序。
- LIMIT 或 OFFSET 子句:限制查询结果的数量或跳过指定数量的行。
left join on and 和 inner join on and的多条件查询区别
参考文档:left join on and 和 inner join on and的多条件查询区别_not back的博客-CSDN博客
在left on后面用and的话 只会作为右表的判断条件不影响左表
-- 查询一个课程包含那些题
SELECT c.id,t.title,t.id from course c left JOIN topical t ON t.course_id=c.id and t.id !=37 WHERE c.id!=4wm_contact和group_contact 返回一个字符串结果,该结果由分组中的值连接组合而成
作用:函数返回一个字符串结果,该结果由分组中的值连接组合而成。
wm_contact:用于Oracle数据库
group_contact:用于mysql数据库
-- 查询一个课程包含那些题
SELECT c.id,GROUP_CONCAT(t.title) from course c left JOIN topical t ON t.course_id=c.id GROUP BY c.id

position 返回substr字符串在str出现的位置
返回substr字符串在str出现的位置,没有返回0
SELECT * from menu WHERE position(2 IN menuRight)>0 distinct 去重
MySQL 数据库去重(distinct) - 知乎 (zhihu.com)
and和or使用注意事项
and的优先级大于or的优先级
正确理解 MySQL and 与 or 优先级_sql 中and 和 or 优先级_猴哥一一的博客-CSDN博客
all()逻辑运算所有
IFNULL(expr1,expr2),如果expr1的值为null,则返回expr2的值,如果expr1的值不为null,则返回expr1的值
SELECT
NAME,
salary
FROM
employees
WHERE
salary > ALL ( SELECT salary FROM employees WHERE department_id = 6 )
ORDER BY
salary;
ifnull() 判空
IFNULL(expr1,expr2),如果expr1的值为null,则返回expr2的值,如果expr1的值不为null,则返回expr1的值。
dense_rank()排名
语法
DENSE_RANK ( ) OVER ( [ <partition_by_clause> ] < order_by_clause > )
PARTITION BY 分组,ORDER BY 排序
例子
select dense_rank() over(partition by gc_no order by gs_scoure desc )a, * from test
NOT EXISTS() 不存在
select name as Customers
from Customers c
where not EXISTS(select * from Orders o where c.id=o.customerId)
DATE_FORMAT() 格式化日期
DATE_FORMAT(NOW(),'%Y-%m-%d')
2023-09-09
MySQL DATE_FORMAT() 函数 | 菜鸟教程 (runoob.com)
DATEDIFF() 计算时间差
作用:计算时间差(天数)
1.结果为 1
SELECT DATEDIFF(day,'2008-12-29','2008-12-30') AS DiffDate2.结果为 -1
SELECT DATEDIFF(day,'2008-12-30','2008-12-29') AS DiffDateselect
w1.id
from Weather w1,Weather w2
where
DATEDIFF(w1.recordDate,w2.recordDate)=1
and w1.Temperature>w2.Temperature
sum() 求和
用来计算一列的总值
select
question_id survey_log
from SurveyLog
group by question_id
order by sum(action='answer')/sum(action='show') desc
limit 1
SQL中的sum函数的妙用——行列转换 - 知乎 (zhihu.com)
SQL Sum()函数 - SQL教程 (yiibai.com)
CASE WHEN THEN ELSE END函数
select
date_format(b.pay_date,"%Y-%m") pay_month,
b.department_id department_id,
(case
when b.avgDep<a.avgAll then 'lower'
when b.avgDep>a.avgAll then 'higher'
else 'same'
end) as comparison
from
(
select s1.pay_date,avg(amount) avgAll from Salary s1 group by s1.pay_date
) as a,
(
select e.department_id ,s.pay_date,avg(s.amount) avgDep from Salary s inner join Employee e on e.employee_id =s.employee_id group by pay_date,e.department_id
) as b
where a.pay_date=b.pay_dateselect......for update会锁表还是锁行
select......for update会锁表还是锁行。_select 会加锁吗_油锅里的猪的博客-CSDN博客
在高并发的情况下,删除查询数据状态再删除时,查询都是可用再多个线程操作就会出现问题
distinct去重、round取整
语法:distinct a,b //组合去重
round(2.998,2) //保留两位小数
select
round(
(ifnull((b.c2/a.c1),0)),2
)
as accept_rate
from
(
select count(distinct sender_id ,send_to_id) c1 from FriendRequest
) as a,
(
select count(distinct requester_id,accepter_id) c2 from RequestAccepted
) as bunion和union all合并
MySQL UNION 操作符 | 菜鸟教程 (runoob.com)
注意:当求取数量最多的数据可以对数据进行排序后再通过limit 1取出第一条数据
# Write your MySQL query statement below
select
id,
count(*) as num
from
( select requester_id as id from RequestAccepted
union all
select accepter_id from RequestAccepted
) as res
group by id
order by count(*) desc
limit 1EXTRACT() 返回日期的单独部分
函数用于返回日期/时间的单独部分,比如年、月、日、小时、分钟等等。
SELECT EXTRACT(YEAR FROM OrderDate) AS OrderYear, EXTRACT(MONTH FROM OrderDate) AS OrderMonth, EXTRACT(DAY FROM OrderDate) AS OrderDay FROM Orders WHERE OrderId=1
对一张表进行两次join
1440. 计算布尔表达式的值 - 力扣(LeetCode)
# Write your MySQL query statement below
select
e.*,
(case
when e.operator='=' and v1.value=v2.value then 'true'
when e.operator='>' and v1.value>v2.value then 'true'
when e.operator='<' and v1.value<v2.value then 'true'
else 'false'
end
) as value
from
Expressions e
inner join
Variables v1 on e.left_operand =v1.name
inner join
Variables v2 on e.right_operand =v2.nameuninall+join+子查询实现
SELECT t.team_id, t.team_name, IFNULL(score,0) num_points
FROM
(
SELECT team_id, SUM(score) score
FROM (
SELECT host_team team_id,
SUM(CASE
WHEN host_goals>guest_goals THEN 3
WHEN host_goals<guest_goals THEN 0
ELSE 1
END) score
FROM matches
GROUP BY host_team
UNION ALL
SELECT guest_team team_id,
SUM(CASE
WHEN host_goals>guest_goals THEN 0
WHEN host_goals<guest_goals THEN 3
ELSE 1
END) score
FROM matches
GROUP BY guest_team
) b
GROUP BY team_id
) a
RIGHT JOIN teams t ON t.team_id=a.team_id
ORDER BY num_points DESC, t.team_id;
if 判断
select sale_date,sum(if(fruit='apples',sold_num,-sold_num)) as diff from Sales
group by sale_date
order by sale_date1699. 两人之间的通话次数 - 力扣(LeetCode)
表: Calls
+-------------+---------+ | Column Name | Type | +-------------+---------+ | from_id | int | | to_id | int | | duration | int | +-------------+---------+ 该表没有主键(具有唯一值的列),它可能包含重复项。 该表包含 from_id 与 to_id 间的一次电话的时长。 from_id != to_id
编写解决方案,统计每一对用户 (person1, person2) 之间的通话次数和通话总时长,其中 person1 < person2 。
以 任意顺序 返回结果表。
返回结果格式如下示例所示。
示例 1:
输入: Calls 表: +---------+-------+----------+ | from_id | to_id | duration | +---------+-------+----------+ | 1 | 2 | 59 | | 2 | 1 | 11 | | 1 | 3 | 20 | | 3 | 4 | 100 | | 3 | 4 | 200 | | 3 | 4 | 200 | | 4 | 3 | 499 | +---------+-------+----------+ 输出: +---------+---------+------------+----------------+ | person1 | person2 | call_count | total_duration | +---------+---------+------------+----------------+ | 1 | 2 | 2 | 70 | | 1 | 3 | 1 | 20 | | 3 | 4 | 4 | 999 | +---------+---------+------------+----------------+ 解释: 用户 1 和 2 打过 2 次电话,总时长为 70 (59 + 11)。 用户 1 和 3 打过 1 次电话,总时长为 20。 用户 3 和 4 打过 4 次电话,总时长为 999 (100 + 200 + 200 + 499)。
select
if(from_id>to_id,to_id,from_id) person1,
if(from_id<to_id,to_id,from_id) person2,
count(*) call_count,
sum(duration) total_duration
from
Calls
group by person1,person2abs()绝对值
select
distinct a.seat_id
from cinema a , cinema b
where
abs(a.seat_id - b.seat_id) = 1
and a.free = true and b.free = true order by a.seat_id ;列转行和行转列
表:Products
+-------------+---------+ | Column Name | Type | +-------------+---------+ | product_id | int | | store1 | int | | store2 | int | | store3 | int | +-------------+---------+ 在 SQL 中,这张表的主键是 product_id(产品Id)。 每行存储了这一产品在不同商店 store1, store2, store3 的价格。 如果这一产品在商店里没有出售,则值将为 null。
请你重构 Products 表,查询每个产品在不同商店的价格,使得输出的格式变为(product_id, store, price) 。如果这一产品在商店里没有出售,则不输出这一行。
输出结果表中的 顺序不作要求 。
查询输出格式请参考下面示例。
示例 1:
输入: Products table: +------------+--------+--------+--------+ | product_id | store1 | store2 | store3 | +------------+--------+--------+--------+ | 0 | 95 | 100 | 105 | | 1 | 70 | null | 80 | +------------+--------+--------+--------+ 输出: +------------+--------+-------+ | product_id | store | price | +------------+--------+-------+ | 0 | store1 | 95 | | 0 | store2 | 100 | | 0 | store3 | 105 | | 1 | store1 | 70 | | 1 | store3 | 80 | +------------+--------+-------+ 解释: 产品 0 在 store1、store2、store3 的价格分别为 95、100、105。 产品 1 在 store1、store3 的价格分别为 70、80。在 store2 无法买到。
1、列转行
SELECT product_id, 'store1' store, store1 price FROM products WHERE store1 IS NOT NULL
UNION
SELECT product_id, 'store2' store, store2 price FROM products WHERE store2 IS NOT NULL
UNION
SELECT product_id, 'store3' store, store3 price FROM products WHERE store3 IS NOT NULL;2、行转列
SELECT
product_id,
SUM(IF(store = 'store1', price, NULL)) 'store1',
SUM(IF(store = 'store2', price, NULL)) 'store2',
SUM(IF(store = 'store3', price, NULL)) 'store3'
FROM
Products1
GROUP BY product_id ;保留两位小数ROUND或者FORMAT
//四舍五入 12.23
FORMAT(12.2343,2)
Mysql窗口函数
【精选】MYSQL窗口函数(Rows & Range)——滑动窗口函数用法_mysql滑动窗口函数_Avasla的博客-CSDN博客
相应题型
SELECT
visited_on,
sum_amount amount,
ROUND( sum_amount / 7, 2 ) average_amount
FROM (
select visited_on,sum(amount) OVER ( ORDER BY to_days(visited_on) RANGE BETWEEN 6 PRECEDING AND current ROW ) sum_amount from Customer
) t1 WHERE DATEDIFF(visited_on, ( SELECT MIN( visited_on ) FROM Customer )) >= 6 group by visited_on in函数
1070. 产品销售分析 III - 力扣(LeetCode)
# Write your MySQL query statement below
select
product_id , year as first_year, quantity , price
from
Sales
where
(product_id , year) in
(
select
product_id ,min(year) year
from
Sales
group by
product_id
)
count 搭配case的是使用
count(*)不记录空值null
【精选】sql分组查询group by结合count,sum统计语句的实现(附带sql详细分析步骤)_sql group by sum_盛夏温暖流年的博客-CSDN博客
# Write your MySQL query statement below
select
s.user_id,
round(
count(case when action='confirmed' then s.user_id end)/count(s.user_id),2) as confirmation_rate
from
Signups s
left join
Confirmations c
on s.user_id =c.user_id
group by c.user_id
构造不存在的列
表: Accounts
+-------------+------+ | 列名 | 类型 | +-------------+------+ | account_id | int | | income | int | +-------------+------+ 在 SQL 中,account_id 是这个表的主键。 每一行都包含一个银行帐户的月收入的信息。
查询每个工资类别的银行账户数量。 工资类别如下:
"Low Salary":所有工资 严格低于20000美元。"Average Salary": 包含 范围内的所有工资[$20000, $50000]。-
"High Salary":所有工资 严格大于50000美元。
结果表 必须 包含所有三个类别。 如果某个类别中没有帐户,则报告 0 。
按 任意顺序 返回结果表。
查询结果格式如下示例。
示例 1:
输入: Accounts 表: +------------+--------+ | account_id | income | +------------+--------+ | 3 | 108939 | | 2 | 12747 | | 8 | 87709 | | 6 | 91796 | +------------+--------+ 输出: +----------------+----------------+ | category | accounts_count | +----------------+----------------+ | Low Salary | 1 | | Average Salary | 0 | | High Salary | 3 | +----------------+----------------+ 解释: 低薪: 有一个账户 2. 中等薪水: 没有. 高薪: 有三个账户,他们是 3, 6和 8.
SELECT
'Low Salary' AS category,
SUM(CASE WHEN income < 20000 THEN 1 ELSE 0 END) AS accounts_count
FROM
Accounts
UNION
SELECT
'Average Salary' category,
SUM(CASE WHEN income >= 20000 AND income <= 50000 THEN 1 ELSE 0 END)
AS accounts_count
FROM
Accounts
UNION
SELECT
'High Salary' category,
SUM(CASE WHEN income > 50000 THEN 1 ELSE 0 END) AS accounts_count
FROM
Accounts
字符串函数
SELECT SUBSTRING('Another #HappyDay with good vibes!', INSTR('Another #HappyDay with good vibes!', '#'),INSTR('Another #HappyDay with good vibes!', ' ')+1);ANY_VALUE函数
ANY_VALUE(sale_date) AS any_sale_date:返回每组中任意一个sale_date
SELECT
product_id,
SUM(quantity) AS total_quantity,
ANY_VALUE(sale_date) AS any_sale_date
FROM
sales
GROUP BY
product_id;
SELECT 1 的用法
SELECT *
FROM departments
WHERE EXISTS (
SELECT 1
FROM employees
WHERE departments.department_id = employees.department_id
AND employees.employee_id = 123
);
这里的
EXISTS子句返回TRUE或FALSE,取决于子查询是否返回任何行。SELECT 1是常见的优化方式,因为不需要实际返回列数据。















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









