







一、Re(正则表达式)库入门
1.正则表达式的语法
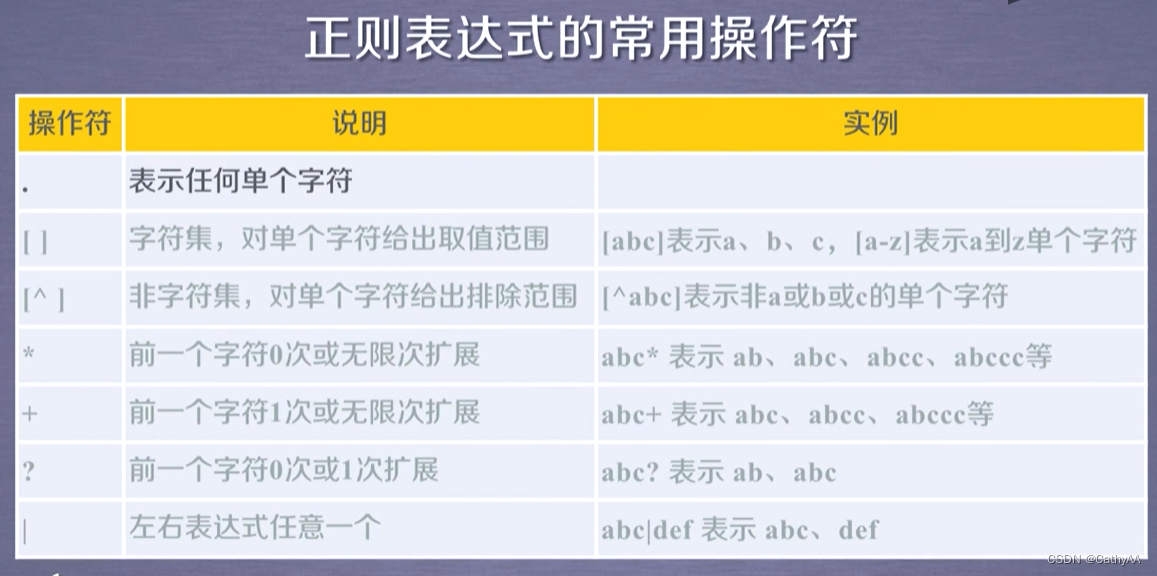

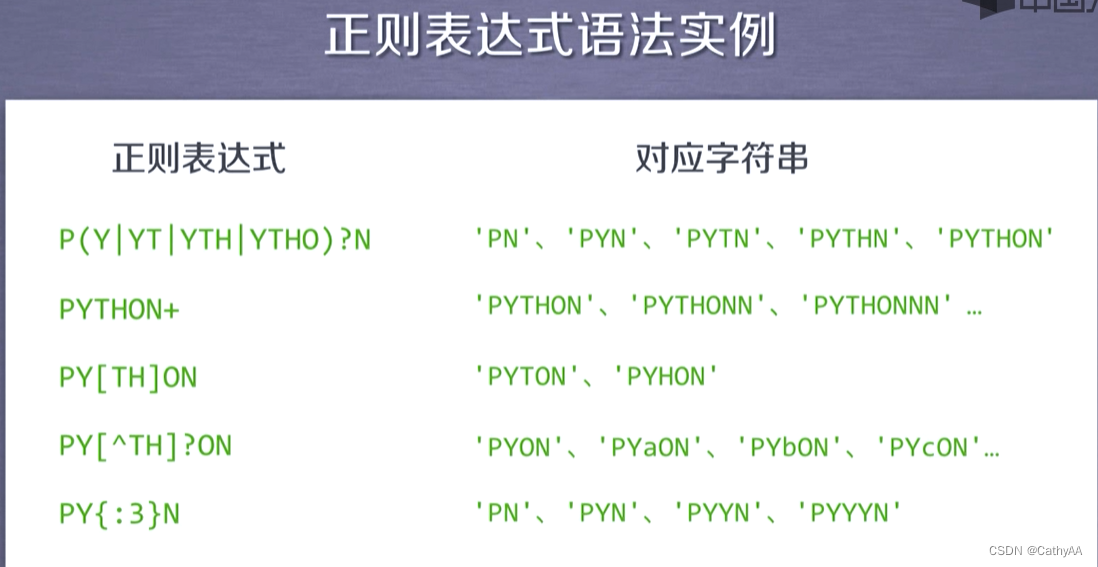
PY{:3}N代表将Y扩展0次至3次


二、Re库的基本使用




- 如果用string来表示,在所有的正则表达式中出现\的地方,都要增加额外的\

Re库主要功能函数:

①re.search
re.search(pattern, text) 在整个字符串 text 中搜索匹配项



②re.match
re.match(pattern, text) 只在字符串开头进行匹配

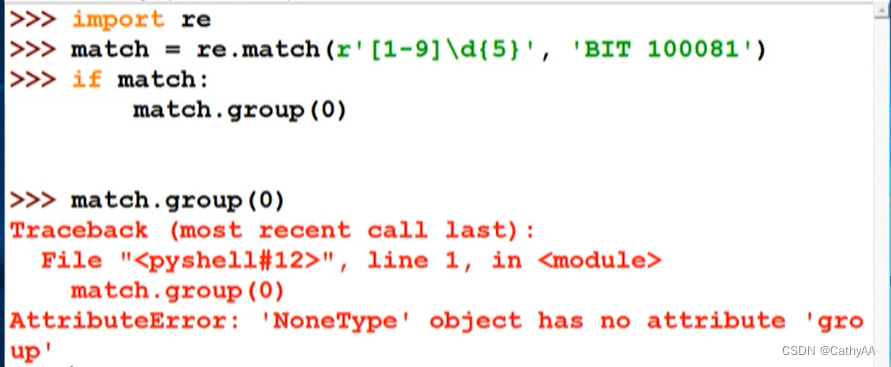
给定字符串的起始位置并不是数字,正则表达式匹配结果为空

③re.findall()


④re.split()

- 用一个正则表达式去匹配字符串,将匹配的部分去掉,去掉之后的部分分别作为分割的字符串元素放到一个列表里

- 设置maxsplit:

⑤re.finditer()

- 通过这个函数可以迭代地获得每一次正则表达式匹配的结果,并对这个结果单独进行处理

⑥re.sub()


Re库的另一种等价用法:

- 首先使用re.complie将一个正则表达式的字符串编译成一个正则表达式的类型,然后直接用pat调用那6个方法来获得相关结果。这种方法的好处是经过一次编译,当我们需要多次对正则表达式进行使用和匹配时,可以用这种方式来加快整个程序的进行
- re.compile函数:


三、Re库的match对象


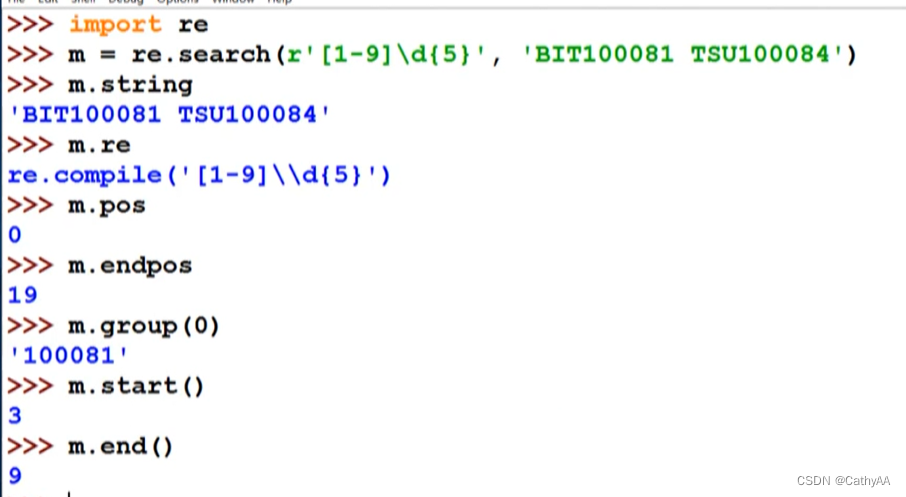
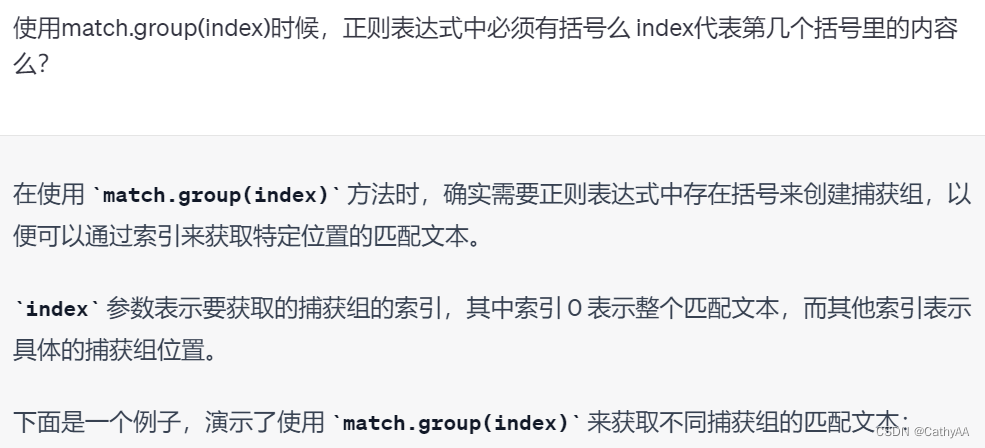
- match.group()的使用:
import re
text = "Hello, 42 is a number."
pattern = r"(\w+), (\d+)"
match = re.search(pattern, text)
if match:
full_match = match.group(0) # 获取整个匹配文本
first_group = match.group(1) # 获取第一个捕获组的文本
second_group = match.group(2) # 获取第二个捕获组的文本
print("Full Match:", full_match) # 输出:Hello, 42
print("First Group:", first_group) # 输出:Hello
print("Second Group:", second_group) # 输出:42
四、Re库的贪婪匹配和最小匹配
1.贪婪匹配


2.最小匹配


- 当有操作符可以匹配不同长度的时候,我们都可以在这个操作符的后面增加一个?来获得最小匹配的结果
五、 总结:
















 5925
5925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









