






本文的目的:
就是利用LSTM在可观测流域提取有用的信息从而为未观测的流域进行预测,结果表明,样本外LSTM平均优于SAC-SMA以及分布式模型NWM
数据:
实验数据来自公开可用的流域属性和气象学大样本研究的CAMELS数据集,CAMELS数据集由美国大陆671个流域组成,面积从4km到25000km不等。这些流域是在美国现有的流域选择的、因为它们大部分都可以从美国地质调查局国家水信息系统中获得长期的测量记录、CAMELS包括来自DAYment、Maurer、和NLDAS的日驱动数据、以及与土壤、气候、植被、地形和地质相关的几种静态流域属性。需要指出的是,这些流域属性来自地图、遥感产品和气候数据,这些数据在美国大陆和全球范围内准确或近似的使用。
实验设计:
使用LSTM以NLDLS气象强迫数据作为每个时间步长的输入。此外,在每个时间步长,气象输入随流域增加
设计了三种类型的LSTM模型:
- 没有静态特征的全局LSTM:只有气象强迫数据输入,没有流域属性的LSTM,同时在所有流域进行训练(没有k-fold验证)
- 具有静态特征的全局的LSTM:将气象强迫和流域属性作为输入的LSTM,同时在所有流域进行训练(没有k-fold验证)
- PUB LSTM:将气象强迫和流域属性作为输入的LSTM,有k-fold验证(k=12)进行训练和测试
1,2对比是有没有静态特征输入,评估流域属性的价值,2,3对比告诉我们由于样本外的预测和样本内的预测丢失了多少信息,pub是未计量盆地预测
LSTM输入包括5个气象驱动数据和27个静态流域属性数据:
- 气象驱动数据:最高气温、最低气温、降水、辐射、蒸汽压
- 静态流域属性数据:降水、潜在蒸散发、干旱指数、降雨季节性等
结果
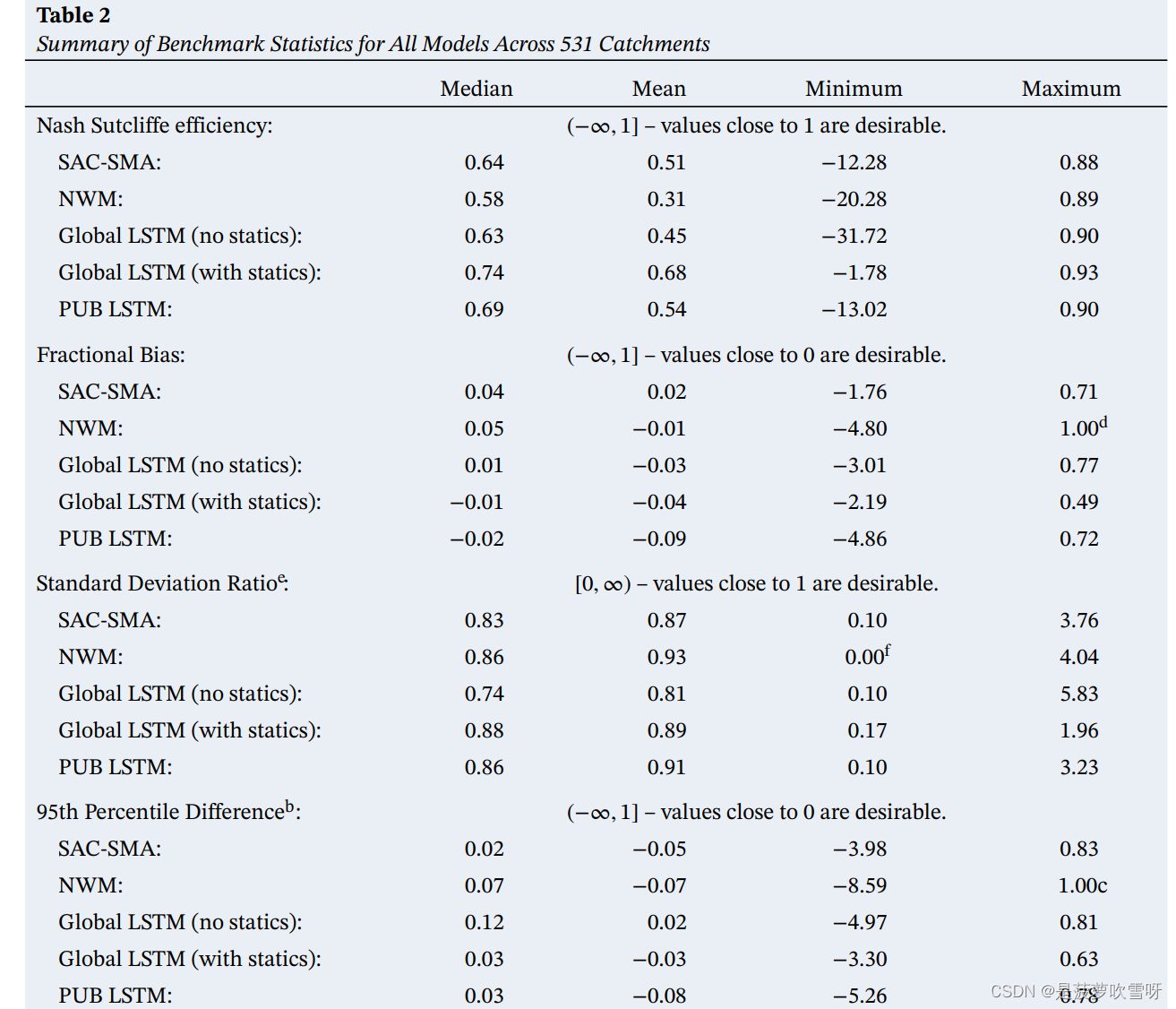
- 样本外PUB LSTM在样本外超过一半流域表现的与样本内一样好
- PUB LSTM的NSE在531个流域中有307个(58%)高于SAC-SMA,在531个流域中有347个(66%)高于NWM。PUB LSTM的平均NSE和最大NSE得分也高于基准模型。
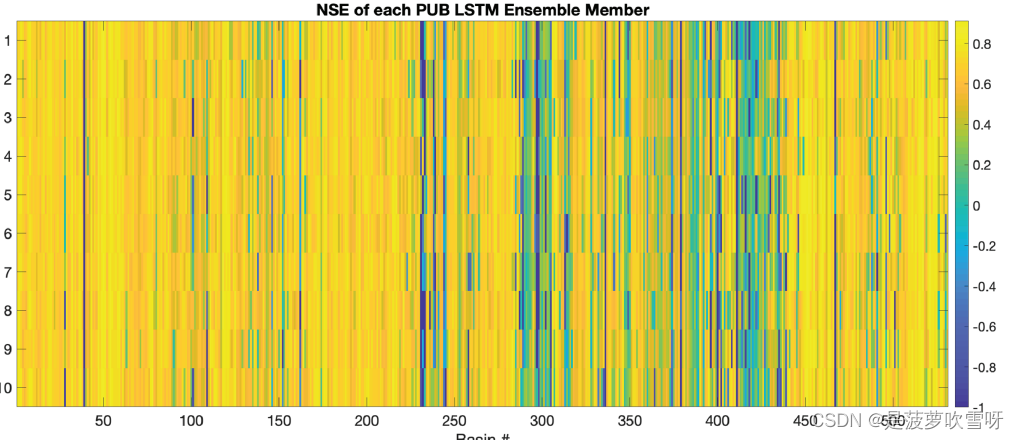
具有静态流域属性的全局LSTM模型要比其它模型更好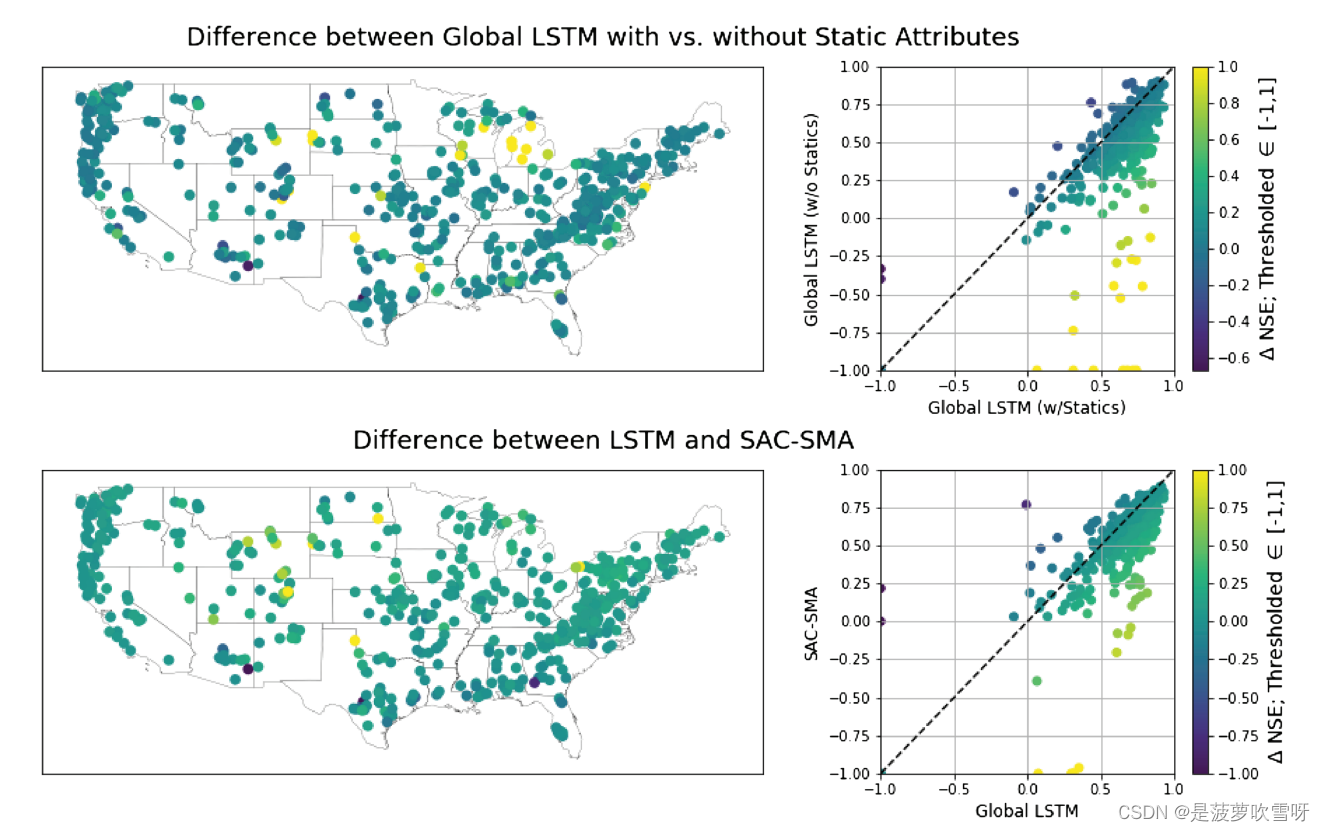















 1119
1119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









