







 文章介绍了如何使用Python实现深度优先搜索(DFS)和广度优先搜索(BFS)算法,以解决迷宫问题和在图结构中进行遍历,包括递归和非递归版本的示例。
文章介绍了如何使用Python实现深度优先搜索(DFS)和广度优先搜索(BFS)算法,以解决迷宫问题和在图结构中进行遍历,包括递归和非递归版本的示例。
模板
模板来源:蓝桥杯必备模板(python蓝桥杯)-CSDN博客
def dfs(参数):
if (越界不合法情况):
return
if (终点边界,输出答案):
return
for (循环枚举所有方案):
if(未被标记): # if (越界不合法情况): 也可以放这一块写
(标记)
dfs(下一层)
(还原标记) #回溯
"""此处以迷宫问题为例,讲解视频在原作者文章中 """
#M:map地图 G:go走过路径 q=deque():双向队列 q.popleft() 头节点从左边出队
from collections import deque #导入数据结构deque
q=deque([(0,0)]) #1.化队列,迷宫开始位置坐标(0,0)
n,m=map(int,input().split())
M=[[int(i) for i in input()] for j in range(n)] #模拟地图
G=[['']*m for i in range(n)] #记录到从起点到该点走过路径的方向(根据题意设置)
while q:
x,y=q.popleft()
if x==n-1 and y==m-1: #2.设置结束条件,输出答案
print(len(G[-1][-1]))
print(G[-1][-1])
break
for i,j,k in [(1,0,'D'),(0,-1,'L'),(0,1,'R'),(-1,0,'U')]:#3.下一步路,遍历可以走的四个方向,得到下一个坐标(a,b)。
a,b=x+i,y+j
#3.判断合理,判断坐标是否越界,是否之前遍历过。
if 0<=a<n and 0<=b<m and M[a][b]==0:
M[a][b]=1
#4.迭代赋值:判断合理就进行标记,然后添加到队列最后,路径表上增加此刻的方向。
q.append((a,b))
G[a][b]=G[x][y]+k
DFS
空间复杂度是n,不具有最短路效应,因为如果数据量一旦过大,递归树会越来越大最终导致爆栈。对于DFS而言,只要有解即可适合一些思路比较奇怪,对空间要求高的题目。
-
基本思想: 从起始节点开始,尽可能深地访问图的节点,直到达到最深处,然后回溯到上一个节点,再继续探索未访问的分支。
-
实现方式: 使用递归或栈来实现。递归是一种天然的深度优先搜索方法,而使用栈也可以手动模拟递归过程。
-
适用场景: 适合解决一些需要完整路径的问题,比如寻找路径、拓扑排序等。
python实现图的深度优先遍历(DFS)和广度优先遍历(BFS)算法_对像素进行dfs便利-CSDN博客
实现1
"""
实现1 图的非递归实现
"""
# 深度优先 Deep First Search
def DFS(graph, s):
stack = [] # 建立栈
stack.append(s) # 初始化栈,加头节点
data = [] # 存储遍历过的数字
data.append(s)
while stack: # 在栈不为空时
n = stack.pop() # 栈尾弹出
nodes = graph[n] # 找栈尾的孩子节点
for i in nodes[::-1]: # 遍历节点,如果没有遍历就加入栈,做标记
if i not in data:
stack.append(i)
data.append(i)
print(n,end=' ') # 打印
实现2
常见搜索算法(一):深度优先和广度优先搜索 - Python笔记 (notes-of-python.readthedocs.io)
"""
实现2,在图结构中的算法实现
"""
from collections import defaultdict
# 定义图结构
class Graph:
def __init__(self):
# 使用字典保存图
self.graph = defaultdict(list)
def addEdge(self, u, v):
# 用于给图添加边(连接)
self.graph[u].append(v)
def DFSTrav(self, v, visited):
# 标记已经访问过的节点
visited.append(v)
# 访问当前节点的相邻节点
for neighbour in self.graph[v]:
if neighbour not in visited:
self.DFSTrav(neighbour, visited)
# 递归实现
def DFS(self, v):
# 初始化保存已访问节点的集合
visited = []
# 递归遍历节点
self.DFSTrav(v, visited)
print(visited)
# 非递归实现
def DFS2(self, v):
# 初始化保存已访问节点的集合
visited = []
stack = []
stack.append(v)
visited.append(v)
while stack:
# 访问当前节点邻居节点的第一个节点,如果没有访问,标记为已访问并入栈
for i in self.graph[v]:
if i not in visited:
visited.append(i)
stack.append(i)
break
# 如果当前节点所有邻居节点都已访问,将当前节点弹出(出栈)
v = stack[-1]
if set(self.graph[v]) < set(visited):
stack.pop()
print(visited)
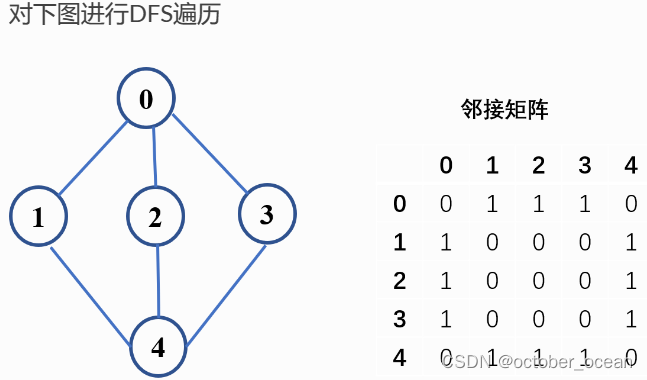
# 实例
if __name__ == "__main__":
# 新建图
graph = Graph()
graph.addEdge(0, 1)
graph.addEdge(0, 2)
graph.addEdge(0, 3)
graph.addEdge(1, 0)
graph.addEdge(2, 0)
graph.addEdge(3, 0)
graph.addEdge(1, 4)
graph.addEdge(2, 4)
graph.addEdge(3, 2)
graph.addEdge(4, 1)
graph.addEdge(4, 2)
graph.addEdge(4, 3)
# DFS遍历图:指定一个起点
graph.DFS(0)
graph.DFS2(0)"""
二叉树的递归实现
"""
class Solution:
def DFSTrav(self, node, visited):
# 标记已经访问过的节点
if node.val in visited:
return
visited.append(node.val)
# 访问当前节点的相邻节点
if node.left:
self.DFSTrav(node.left, visited)
if node.right:
self.DFSTrav(node.right, visited)
def dfs(self, root: TreeNode) -> List[List[int]]:
visited = []
# dfs
self.DFSTrav(root, visited)
print(visited)
"""
二叉树结构的非递归实现
"""
class Solution:
def dfs2(self, node):
visited = []
stack = []
stack.append(node)
visited.append(node.val)
while stack:
if not node.left and not node.right:
stack.pop()
node = stack[-1]
if node.left and node.left.val not in visited:
stack.append(node.left)
visited.append(node.left.val)
node = node.left
elif node.right and node.right.val not in visited:
stack.append(node.right)
visited.append(node.right.val)
node = node.right
else:
stack.pop()
print(visited)# 实例
if __name__ == "__main__":
root = TreeNode('A')
root.left = TreeNode('B')
root.right = TreeNode('C')
root.left.left = TreeNode('D')
root.left.left.right = TreeNode('G')
root.right.left = TreeNode('E')
root.right.right = TreeNode('F')
root.right.right.left = TreeNode('H')
solu = Solution()
solu.dfs(root)
solu.dfs2(root)BFS
放到树的遍历中而言,就是层序遍历(levelorder)
从根节点开始向下一层一层的搜索,具有最短路的特点,适用于需要找最短路的题目
BFS是连通图的一种遍历策略,沿着树(图)的宽度遍历树(图)的节点,最短路径算法可以采用这种策略,在二叉树中体现为一层一层的搜索,也就是层序遍历。
-
基本思想: 从起始节点开始,逐层访问图的节点,先访问当前层的所有节点,再逐层向下遍历。
-
实现方式: 使用队列来实现。从起始节点开始,将其放入队列,然后依次取出队列中的节点,并将其未访问的邻居节点放入队列。
-
适用场景: 适合解决一些需要最短路径或层级遍历的问题,比如最短路径、最小生成树等。
实现1
"""
实现1,很好的模板,我背
"""
def BFS(graph,q): #广度优先遍历,基于队列
queue=[] #建立队列
queue.append(q)
data=[] #记录已经遍历过的点
data.append(q)
while queue:
n=queue.pop(0) # 队列先进先出
nodes=graph[n]
for j in nodes:
if j not in data:
queue.append(j)
data.append(j)
print(n, end=' ')
"""
实现1的两个算法的一个实例
"""
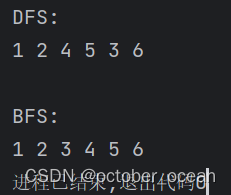
if __name__ == '__main__':
graph = {
'1': ['2', '3'],
'2': ['4', '5'],
'3': ['6'],
'4': [],
'5': [],
'6': []
}
print("DFS:")
DFS(graph, '1')
print('\n')
print("BFS:")
BFS(graph, '1')
实现2
"""
实现2:图结构的BFS
"""
def BFS(self, v):
# 新建一个队列
queue = []
# 将访问的节点入队
queue.append(v)
visited = []
visited.append(v)
while queue:
# 节点出队
v = queue.pop(0)
# 访问当前节点的相邻节点,如果没有访问,标记为已访问并入队
for i in self.graph[v]:
if i not in visited:
queue.append(i)
visited.append(i)
print(visited)"""
实现2:二叉树的BFS
"""
def bfs(self, root: TreeNode) -> List[List[int]]:
visited = []
if not root:
return visited
queue = [root]
while queue:
length = len(queue)
level = []
for i in range(length):
node = queue.pop(0)
# 存储当前节点
level.append(node.val)
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
visited.append(level)
print(visited)
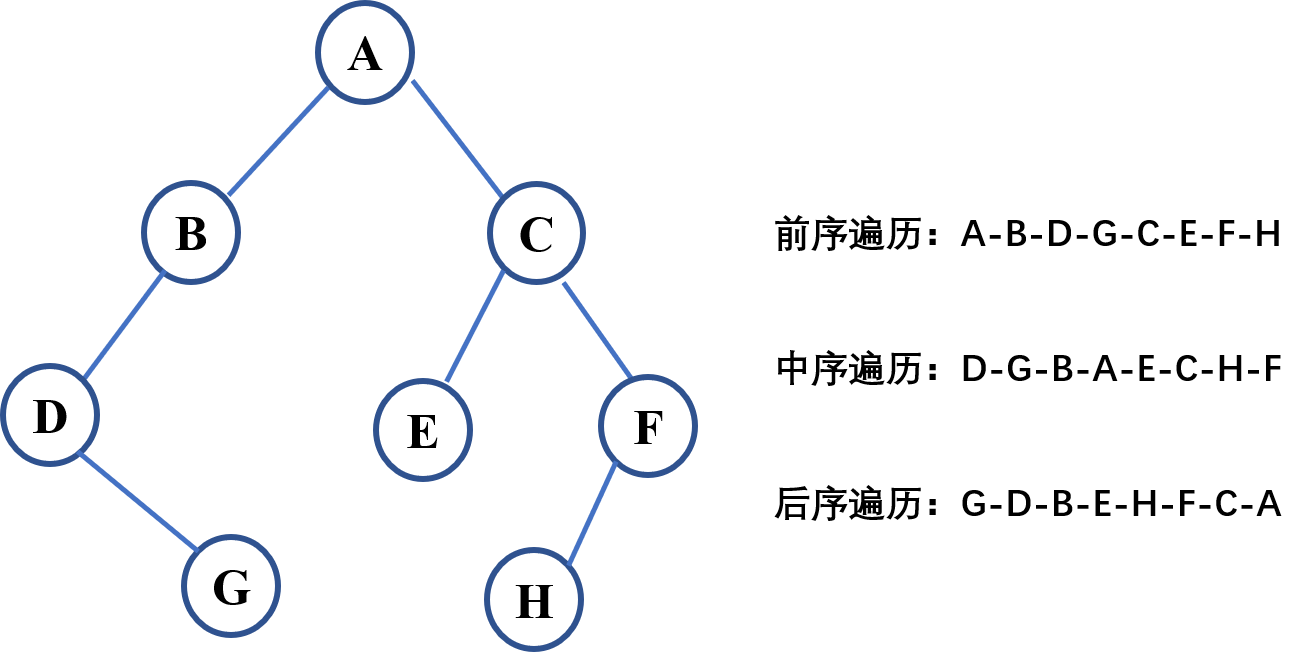
return visited二叉树的前序、中序、后序遍历
前序、中序和后序遍历都可以看作是DFS,对下面的二叉树进行遍历:
class BinaryTree:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
class BinaryTreeTraversal:
def preorder(self,root, traverse_path=[]):
# 前序遍历
if root == None:
return traverse_path
traverse_path.append(root.val)
self.preorder(root.left, traverse_path)
self.preorder(root.right, traverse_path)
return traverse_path
def inorder(self,root, traverse_path=[]):
# 中序遍历
if root == None:
return traverse_path
self.inorder(root.left, traverse_path)
traverse_path.append(root.val)
self.inorder(root.right, traverse_path)
return traverse_path
def postorder(self,root, traverse_path=[]):
# 后序遍历
if root == None:
return
self.postorder(root.left, traverse_path)
self.postorder(root.right, traverse_path)
traverse_path.append(root.val)
return traverse_path
if __name__ == "__main__":
root = BinaryTree('A')
root.left = BinaryTree('B')
root.right = BinaryTree('C')
root.left.left = BinaryTree('D')
root.left.left.right = BinaryTree('G')
root.right.left = BinaryTree('E')
root.right.right = BinaryTree('F')
root.right.right.left = BinaryTree('H')
Traversal = BinaryTreeTraversal()
print(Traversal.preorder(root)) #['A', 'B', 'D', 'G', 'C', 'E', 'F', 'H']
print(Traversal.inorder(root)) #['D', 'G', 'B', 'A', 'E', 'C', 'H', 'F']
print(Traversal.postorder(root)) #['G', 'D', 'B', 'E', 'H', 'F', 'C', 'A']















 6565
6565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









