







一、推荐的技术方法
推荐系统简单来说就是, 高效地达成用户与意向对象的匹配。而技术上实现两者匹配,简单来说有两类方法:
【注】文末提供交流群
1.1 基于分类方法
分类的方法很好理解,预测用户对该类别是否有偏好。
-
可以训练一个意向物品的多分类模型,预测用户偏好哪一类物品。
-
或者将用户+物品等全方面特征作为拼接训练二分类模型,预测为是否偏好(如下经典的CTR模型,以用户物品特征及对应的标签 0或 1 构建分类模型,预测该用户是否会点击这物品,)。

基于分类的方法,精度较高,常用于推荐的排序阶段(如粗排、精排)。
1.2 基于相似度方法
利用计算物与物或人与人、人与物的距离,将物品推荐给喜好相似的人。
-
如关联规则推荐,可以将物与物共现度看做为某种的相似度;
-
协同过滤算法可以基于物品或者基于用户计算相似用户或物品;
-
以及本文谈到的双塔模型,是通过计算物品与用户之间的相似度距离并做推荐。
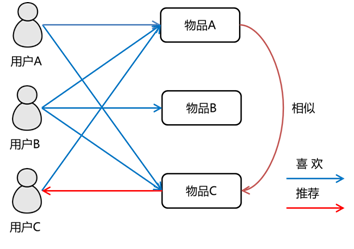
利用相似度的方法效率快、准确度差一些常用于推荐中的粗排、召回阶段。
2. DSSM双塔模型
2.1 DSSM模型的原理
DSSM(Deep Structured Semantic Models)也叫深度语义匹配模型,最早是微软发表的一篇应用于NLP领域中计算语义相似度任务的文章。
DSSM深度语义匹配模型原理很简单:获取搜索引擎中的用户搜索query和doc的海量曝光和点击日志数据,训练阶段分别用复杂的深度学习网络构建query侧特征的query embedding和doc侧特征的doc embedding,线上infer时通过计算两个语义向量的cos距离来表示语义相似度,最终获得语义相似模型。这个模型既可以获得语句的低维语义向量表达sentence embedding,还可以预测两句话的语义相似度。
2.2 DSSM模型结构
DSSM模型总的来说可以分成三层结构,分别是输入层、表示层和匹配层。
-
输入层 将用户、物品的信息转化为数值特征输入;
-
表示层 进一步用神经网络模型学习特征表示;
-
匹配层 计算用户特征向量与物品特征向量的相似度;
结构如下图所示: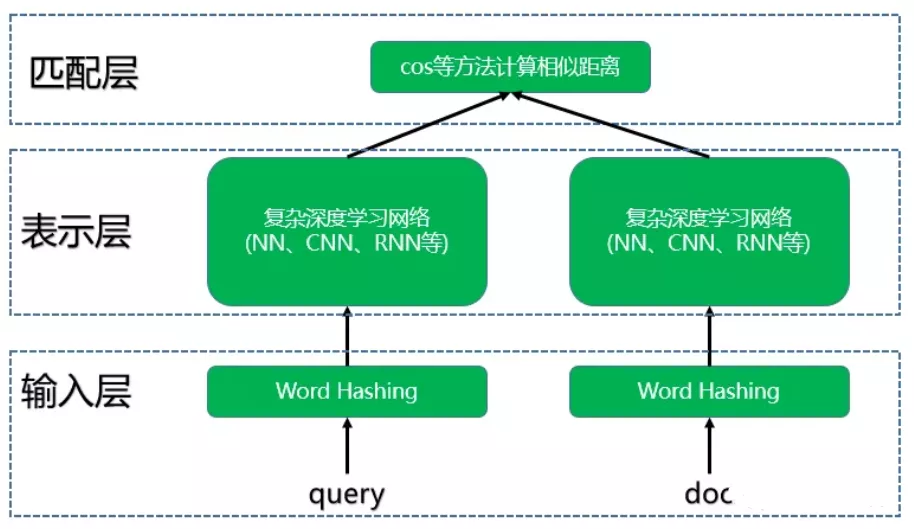
3.双塔模型代码实践
- 读取电影数据集(用户信息、电影信息、评分行为信息),数据格式处理、特征序列编码、数据拼接,并做评分的归一化处理作为模型学习的相似度目标(注:这里也可以另一个思路对评分做阈值划分,按照一个分类任务来解决)
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
### 1. 读取电影数据集(用户信息、电影信息、评分行为信息)
df_user = pd.read_csv("./ml-1m/users.dat",
sep="::", header=None, engine="python",encoding='iso-8859-1',
names = "UserID::Gender::Age::Occupation::Zip-code".split("::"))
df_movie = pd.read_csv("./ml-1m/movies.dat",
sep="::", header=None, engine="python",encoding='iso-8859-1',
names = "MovieID::Title::Genres".split("::"))
df_rating = pd.read_csv("./ml-1m/ratings.dat",
sep="::", header=None, engine="python",encoding='iso-8859-1',
names = "UserID::MovieID::Rating::Timestamp".split("::"))
import collections
# 计算电影中每个题材的次数
genre_count = collections.defaultdict(int)
for genres in df_movie["Genres"].str.split("|"):
for genre in genres:
genre_count[genre] += 1
genre_count
# # 每个电影只保留频率最高(代表性)的电影题材标签
def get_highrate_genre(x):
sub_values = {}
for genre in x.split("|"):
sub_values[genre] = genre_count[genre]
return sorted(sub_values.items(), key=lambda x:x[1], reverse=True)[0][0]
df_movie["Genres"] = df_movie["Genres"].map(get_highrate_genre)
df_movie.head()
# #### 给特征列做序列编码
def add_index_column(param_df, column_name):
values = list(param_df[column_name].unique())
value_index_dict = {value:idx for idx,value in enumerate(values)}
param_df[f"{column_name}_idx"] = param_df[column_name].map(value_index_dict)
add_index_column(df_user, "UserID")
add_index_column(df_user, "Gender")
add_index_column(df_user, "Age")
add_index_column(df_user, "Occupation")
add_index_column(df_movie, "MovieID")
add_index_column(df_movie, "Genres")
# 合并成一个df
df = pd.merge(pd.merge(df_rating, df_user), df_movie)
df.drop(columns=["Timestamp", "Zip-code", "Title"], inplace=True)
num_users = df["UserID_idx"].max() + 1
num_movies = df["MovieID_idx"].max() + 1
num_genders = df["Gender_idx"].max() + 1
num_ages = df["Age_idx"].max() + 1
num_occupations = df["Occupation_idx"].max() + 1
num_genres = df["Genres_idx"].max() + 1
num_users, num_movies, num_genders, num_ages, num_occupations, num_genres
# #### 评分的归一化
min_rating = df["Rating"].min()
max_rating = df["Rating"].max()
df["Rating"] = df["Rating"].map(lambda x : (x-min_rating)/(max_rating-min_rating)) # 评分作为两者的相似度
# df["is_rating_high"] = (df["Rating"]>=4).astype(int) # 可生成是否高评分作为分类模型的类别标签
df.sample(frac=1).head(3)
# 构建训练集特征及标签
df_sample = df.sample(frac=0.1) # 训练集抽样
X = df_sample[["UserID_idx","Gender_idx","Age_idx","Occupation_idx","MovieID_idx","Genres_idx"]]
y = df_sample["Rating"]

- 构建双塔模型,训练预测用户/产品间的相似度。进一步可以提取用户、产品的特征表示方便后续直接结算相似度。
def get_model():
"""搭建双塔DNN模型"""
# 输入
user_id = keras.layers.Input(shape=(1,), name="user_id")
gender = keras.layers.Input(shape=(1,), name="gender")
age = keras.layers.Input(shape=(1,), name="age")
occupation = keras.layers.Input(shape=(1,), name="occupation")
movie_id = keras.layers.Input(shape=(1,), name="movie_id")
genre = keras.layers.Input(shape=(1,), name="genre")
# user 塔
user_vector = tf.keras.layers.concatenate([
layers.Embedding(num_users, 100)(user_id),
layers.Embedding(num_genders, 2)(gender),
layers.Embedding(num_ages, 2)(age),
layers.Embedding(num_occupations, 2)(occupation)
])
user_vector = layers.Dense(32, activation='relu')(user_vector)
user_vector = layers.Dense(8, activation='relu',
name="user_embedding", kernel_regularizer='l2')(user_vector)
# item 塔
movie_vector = tf.keras.layers.concatenate([
layers.Embedding(num_movies, 100)(movie_id),
layers.Embedding(num_genres, 2)(genre)
])
movie_vector = layers.Dense(32, activation='relu')(movie_vector)
movie_vector = layers.Dense(8, activation='relu',
name="movie_embedding", kernel_regularizer='l2')(movie_vector)
# 每个用户的embedding和item的embedding作点积
dot_user_movie = tf.reduce_sum(user_vector*movie_vector, axis = 1)
dot_user_movie = tf.expand_dims(dot_user_movie, 1)
output = layers.Dense(1, activation='sigmoid')(dot_user_movie)
return keras.models.Model(inputs=[user_id, gender, age, occupation, movie_id, genre], outputs=[output])
model = get_model()
model.compile(loss=tf.keras.losses.MeanSquaredError(),
optimizer=keras.optimizers.RMSprop())
fit_x_train = [
X["UserID_idx"],
X["Gender_idx"],
X["Age_idx"],
X["Occupation_idx"],
X["MovieID_idx"],
X["Genres_idx"]
]
history = model.fit(
x=fit_x_train,
y=y,
batch_size=32,
epochs=5,
verbose=1
)
# ### 3. 模型的预估-predict
# 输入前5个样本并做预测
inputs = df[["UserID_idx","Gender_idx","Age_idx","Occupation_idx","MovieID_idx", "Genres_idx"]].head(5)
display(df.head(5))
# 对于(用户ID,召回的电影ID列表),计算相似度分数
model.predict([
inputs["UserID_idx"],
inputs["Gender_idx"],
inputs["Age_idx"],
inputs["Occupation_idx"],
inputs["MovieID_idx"],
inputs["Genres_idx"]
])
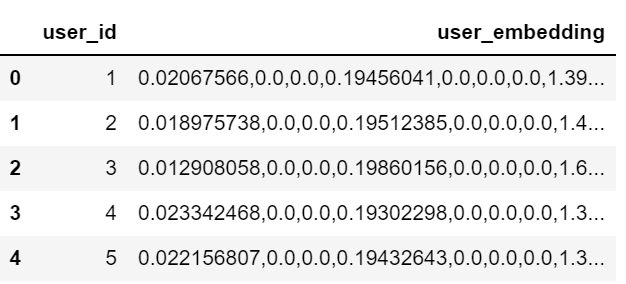
# 可以提取模型中的user或movie item 的embedding
user_layer_model = keras.models.Model(
inputs=[model.input[0], model.input[1], model.input[2], model.input[3]],
outputs=model.get_layer("user_embedding").output
)
user_embeddings = []
for index, row in df_user.iterrows():
user_id = row["UserID"]
user_input = [
np.reshape(row["UserID_idx"], [1,1]),
np.reshape(row["Gender_idx"], [1,1]),
np.reshape(row["Age_idx"], [1,1]),
np.reshape(row["Occupation_idx"], [1,1])
]
user_embedding = user_layer_model(user_input)
embedding_str = ",".join([str(x) for x in user_embedding.numpy().flatten()])
user_embeddings.append([user_id, embedding_str])
df_user_embedding = pd.DataFrame(user_embeddings, columns = ["user_id", "user_embedding"])
df_user_embedding.head()
- 输入前5个样本并做预测,计算用户与电影之间的相似度匹配的分数, 进一步就可以推荐给用户匹配度高的电影。
 43218394218499#wechat_redirect)
43218394218499#wechat_redirect)
技术交流
目前已开通了技术交流群,群友已超过1000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、微信搜索公众号:机器学习社区,后台回复:加群;
- 方式③、可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
















 5614
5614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









