







文章目录
1. 什么是双塔模型
双塔模型经典又简单,就是NLP领域的 query 和 document,推荐领域的 user 和 item,多模态检索领域的图像和文字等,都可以用双塔表示,分别把两个领域的特征编码成一个向量,然后向量相似度进行召回。
较早使用双塔模型的是DSSM模型。将文本编码成对应低维向量,然后通过优化向量点积估值,得到合适的query和文档向量。线上通过query和文档的相似度进行文档的召回。
推荐系统中使用的双塔模型结构如下:
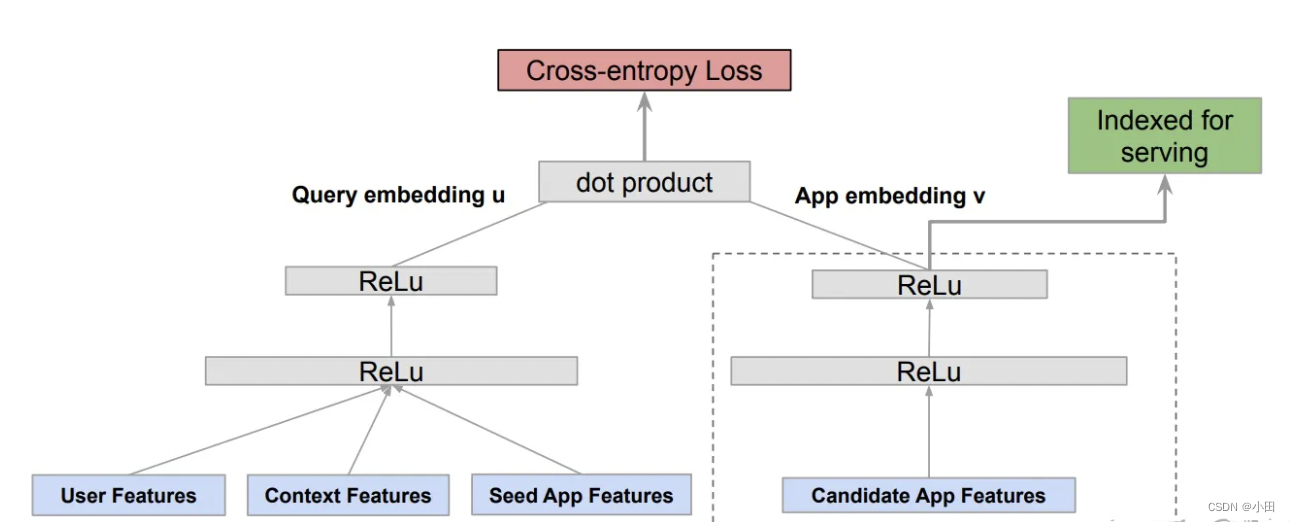
真实的推荐领域的大规模推荐系统,通常有百万到上亿的item和user。因此,这些系统通常有两部分组成:Retrieval阶段和Ranking阶段。双塔模型最常用的领域是Retrieval阶段中的召回和Ranking阶段中的粗排部分。
双塔模型包含user侧和item侧编码塔,两塔分别学习到user和item的表示(embeddings)。
双塔召回应用广泛原因有如下几点:
1. 模型原理简单,比较好实现
2. 模型能够使用几乎所有特征,比起简单id或单用某些属性特征的召回算法,效果较好
3. 模型能够使用除了交叉结构以外的所有结构
4. 能欧提前预先计算item侧向量,线上计算复杂度小,使用近邻查找技术很容易计算百万级规模以上的物料。
5. 可以服用排序算法的特征工程及上线流程,减少工程复杂度。
6. 通过多种采样技术能够实现对应召回模型和粗排排序模型,模型结构、流程代码可复用。
7. 由于使用了全部特征,能够实现五行为item的冷启动,且有这较高准确度。
8. 可以通过模型的实时预测,实现item的实时推荐,达到几乎秒级更新,比较适合新闻等对冷启动需求较强的场景。
双塔存在的问题:
1. 两塔分离,两塔特征不能交叉,只能等到最终向量才能交互。
这是困扰双塔模式的根本问题,很多特征交叉的模型都无法使用,也导致限制了双塔的精度提升的上限。
2 双塔模型特征与特征选择
2.1 模型数据
模型数据包含两部分:一部分是样本的特征,从线上引擎打印的快照日志中来。 另一部分是对应的用户反馈,如曝光,点击,转赞评等label信息。两者通过请求id和item id 的拼接获得完整的样本。
2.2 模型特征
模型特征包含用户特征、上下文特征和物料三种,其中用户特征和上下文特征用于用户塔,物料特征用于物料塔。
用户特征通常有用户id,用户历史点击、观看、点赞历史,用户性别、年龄、地域等profile信息,用户历史消费兴趣画像等
上下文特征通常有手机品牌、系统、版本等信息,访问频道,当前网络情况,定位信息等
物料特征通常有物料id,物料作者id,物料一级二级分类、关键词、主题等挖掘信息,预训练语义向量,物料的统计类特征。
其他信息还包括预训练的id向量等。
2.3 特征选择
SNET是图像领域的一个模型结构,用于CNN结构,通过对特征通道的相关性建模,对重要特征进行强化来提升模型效果。引入推荐系统双塔,在Embedding层之后,DNN之前,增加SENet,对特征重要性进行选择,也可以在特征预选阶段采用,正式线上模型结构中不采用。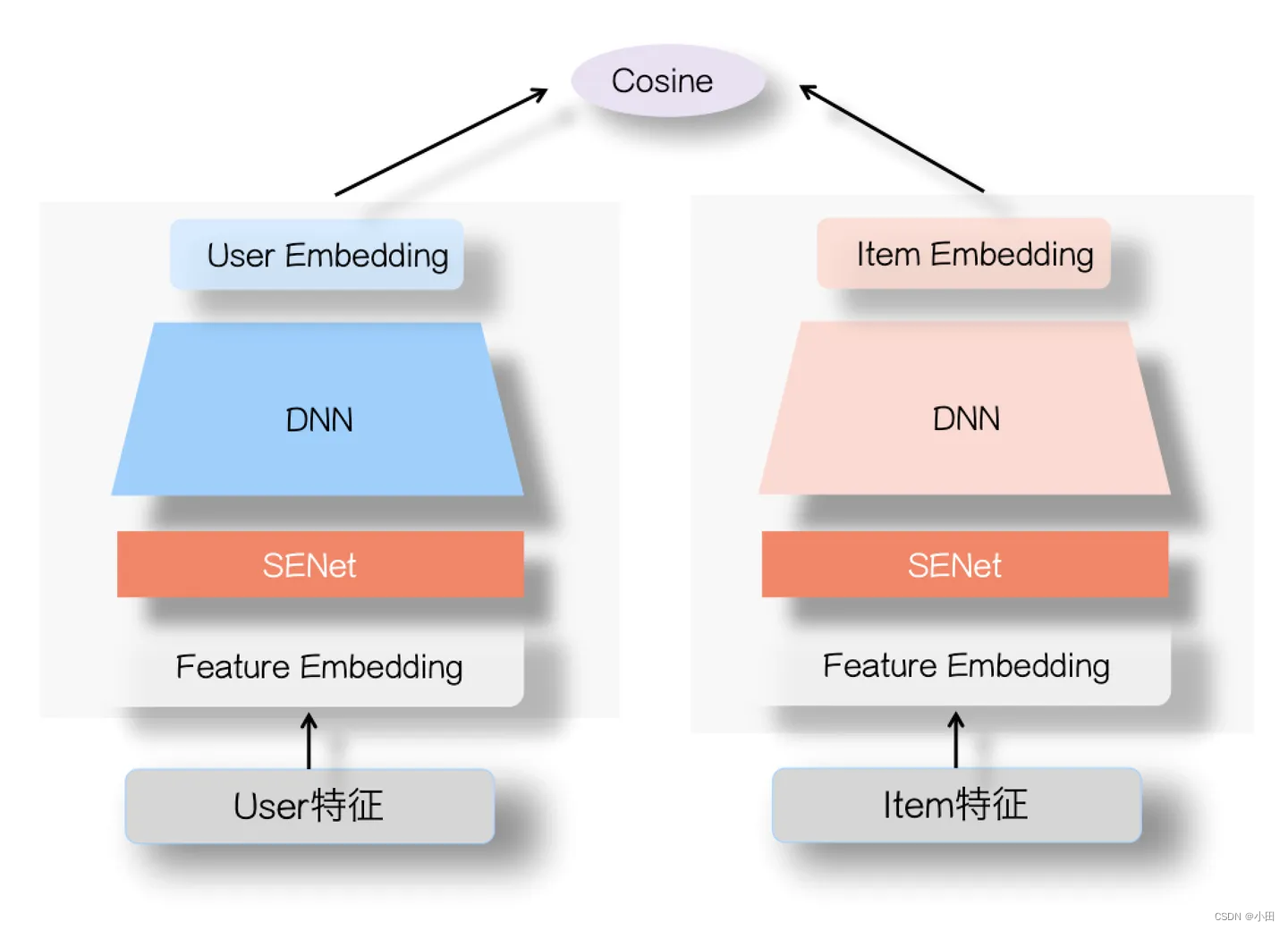
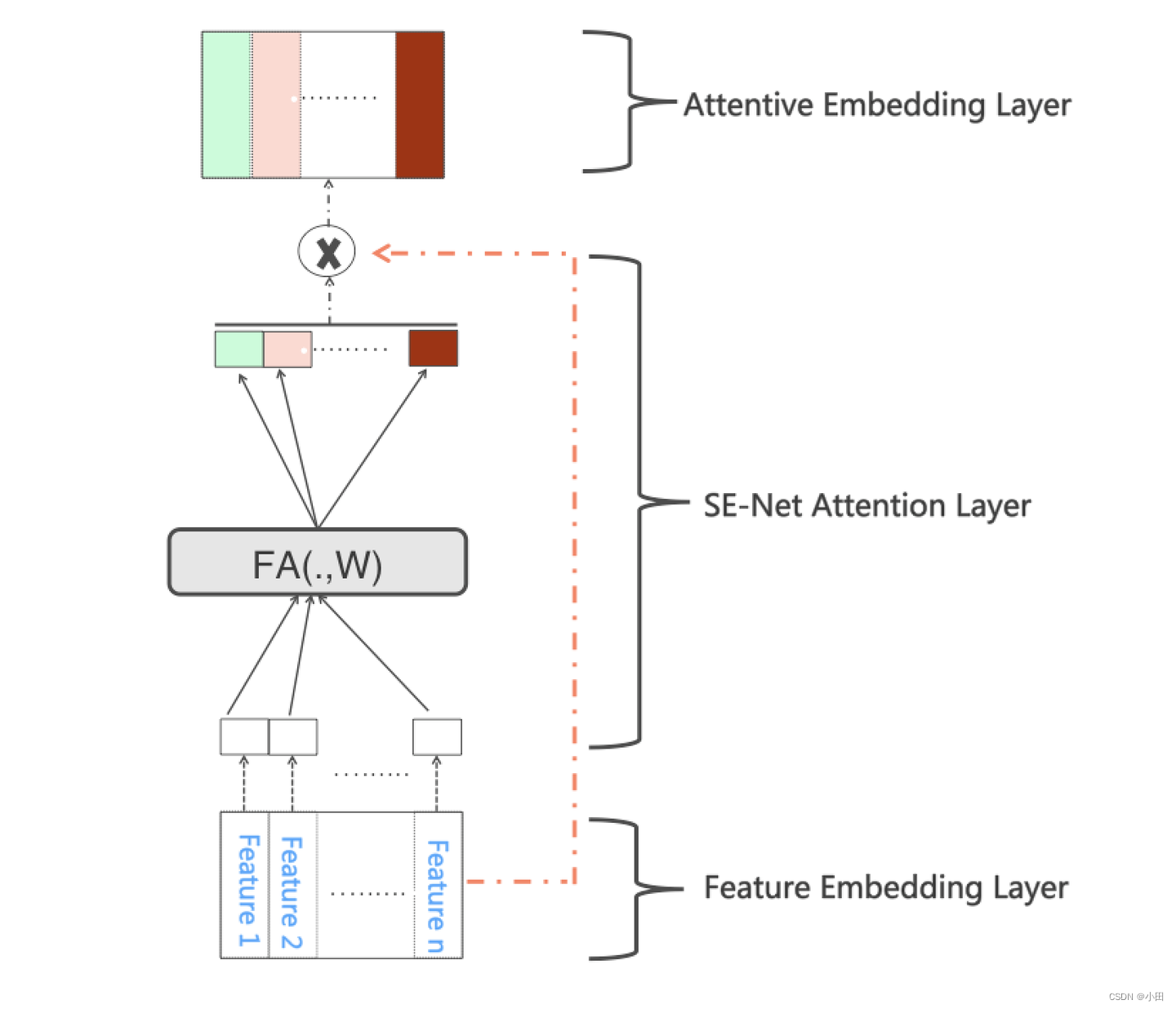
下面简单介绍一下SENet网络结构。在特征Embedding层上,增加SENet后,给每个特征学习一个特征权重,每个特征向量再乘上特征权重就得到新的特征向量了。这样动态学习得到的特征向量能够提升有效特征,抑制无效特征。
具体方法SENet分为两个阶段:Squeeze阶段和Excitation阶段;在Squeeze阶段,对每个特征的向量信息进行压缩汇总,在Excitation阶段,对特征权重进行还原,生成特征个数维度大小的向量。本质SENet结构跟autoEncoder比较像,都是特征信息压缩再扩展的思路。
3. 模型训练
特征经过Embedding层厚,再经过多层MLP,最终输出user和item的Embedding,两个Embedding做点积,作为最终预估分。
有的用cosine值作为预估分,即对最后一层Embedding层进行I2归一化,这样预估分含义为向量角度,不受向量的模的影响。然而cosine值的范围[-1,1] 范围,在预估分达到-2.2左右时,才能较好的拟合CTR为0.1左右的样本集合。因此,范围限制过于严格,大多会给预估值除以一个小数,比如0.2,称为温度系数,或锐度化系数。
目标loss:根据不同目标,拟定不同loss,来进行模型的优化。比如,一般点击率预估,采用交叉熵loss,时长预估采用MSE loss,当然时长一般需进行log变换或者分位数变换。
优化器与学习率:定义好了目标函数和对应目标函数需要优化的变量之后,可以选定优化器,进行梯度下降优化了。不同优化器一般会有不同的学习率,不同的参数也会使用不同的优化器和学习率去优化。不同特征的出现拼读不一样,因此,不同法特征都需要根据频度设定自己的学习率,这点非常重要,对效果影响也比较大。
3.1 样本选择
正样本一般设定为用户的正向行为,比如点击、点赞、观看等。
负样本的讨论比较多,可以氛围以下几种情况:
- 曝光未点击
排序算法一般采用曝光未点击作为负样本,如果训练一个双塔模型,采用曝光未点击,最后是能够达到跟排序模型相似的效果的。召回的效果指标也不差,更可以当做粗排和召回中的排序来用。 - 随机负采样
使用比较多的召回算法中用到的随机负采样,比较经典的论文就是2016年的YouTubeDNN。在全量item中随机选取一定数据的item,有的是完全随机,也可以看招出现频率做选择,出现越多选中概率越大。 - 粗排样本
有从链路一致性角度考虑,粗排的学习目标应该是精排,为了跟精排统一,粗排的负样本应该是精排排名靠后的样本,而不是曝光未点击。因此,精排中排名靠后的样本,也可以作为粗排的负样本。 - batch内负采样
YouTube2019年初的一篇论文,采用的是batch内负采样。文章使用所有正向行为比如点击当做正样本,然后再batch内负采样作为负样本,其关注点是如果batch内都是正样本,但是却过多的当成了负样本,而且正样本出现的越多,当成负样本的概率越大,很不合理。文中对负样本重要度做了一个平衡,根据样本出现的频率,出现的越多,重要度越低,这样能够把流行的item的重要度降低下来。
from: Sampling-bias-corrected neural modeling for large corpus item recommendations
Google Play的一篇双塔采用的全局随机负采样和batch内负采样混合采样,既能保证batch内采样的高效训练,又能把全局长尾item作为负样本,能够训练到,而且能够设定样本分布。
from: https://zhuanlan.zhihu.com/p/533449018
阿里开源的easyrec也是在batch内负采样,不过batch内既包含正样本又包含负样本,这样没有了流行正样本过多当成负样本的顾虑。可以直接进行随机batch内负采样。另外示例代码中给出的loss还能够实现了对hard样本加权的逻辑,对预测的正样本与负样本对的差值大于0的,减弱loss,反之增大loss。
from: https://zhuanlan.zhihu.com/p/475117993
在实际工作中,既要考虑效果又要考虑实际基础设施情况,我们在阿里的easyrec中batch负采样基础上,加上曝光未点击,能够同时获得recall@k,和AUC的同步提升。
4 双塔模型的评估
4.1 线下评估指标
一般采用未来一段时间(1Day)数据作为测试机进行评估。
- AUC: 不论在找回和排序模型中,AUC都是一个重要指标,在排序中更重要,针对特征维度统计的GAUC,更能在特征场景有重要意义。
- Recall@K: 在预测的前K个样本中,是正样本的个数。
- AverageRank:对于一个正样本的情况,随机取100个负样本,求得正样本的平均排名
- NDCG: 考虑到排序不同为止的重要程度,对不同为止赋予不同权重值,得出评价分数。为了不同排名top k之间可比,使用最优DCG进行归一化,得到归一化后的评价指标。
4.2 线上评估指标
线上指标一般采用人均曝光、人均刷新、人均点击、点击率、人均时长、人均互动,留存等指标判定。
5 双塔模型预测与线上使用
5.1 日志模块
使用tfrecord等格式数据作为数据输入,每条数据包含特征和样本label。其中tfrecord文件上游为搜索引擎打印的snapshot日志和用户的行为日志&时长日志等。经过拼接&处理完成后,形成特定格式的文件,小时级或者分钟级更新。
5.2 模型训练模块
使用约1-3个月数据进行模型训练。训练流程分为全量更新和增量更新,全量更新完成后,需要追加训练完成小时级增量追加训练。
模型训练完成后产出的模型文件,双塔产出两份模型,user模型和item模型,分别放置到指定路径上。
5.3 模型上线&压测
导出模型后,需要在特征模型管理中心,进行模型上线&压测
5.4 模型更新模块
模型小时级训练完成后可以选择推送到线上更新,在更新模型之前,需要保证item全量日志预测完成,且推送到引擎指定路径。
模型更新指定路径之后,serving会自动加载user模型和item模型,形成user server和item server。更新信息写入到redis,供算法和引擎调用。
5.5 item日志预测模块
5.5.1 全量预测
全量预测数据源:引擎到处的小时级全量文件,预测结果为对应版本的item全量向量
5.5.2 小时级增量
数据源:预测结果为item新增向量,推送到增量路径,供引擎加载
5.5.3 实时预测
数据源:拼接实时数据包含新增item的特征
产出:item的向量及对应版本 发送到引擎接口
5.5.4 线上应用
双塔调用方式:
user侧:引擎获取用户user侧特征,访问user server,获得user向量
item侧:通过全量、小时增量、vali实时,获取模型item向量。
点积:线上通过点积操作获取user-item分数














 5293
5293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









