






Llama 3.1模型推理实战
1、环境准备
首先,我们需要确保我们的服务器具备足够的硬件配置来支持Llama 3.1模型的运行。我们选择的是一台配备有4090型号GPU(24G显存)的服务器,基础镜像信息如下:ubuntu 22.04、python 3.12、cuda 12.1、pytorch 2.3.0。
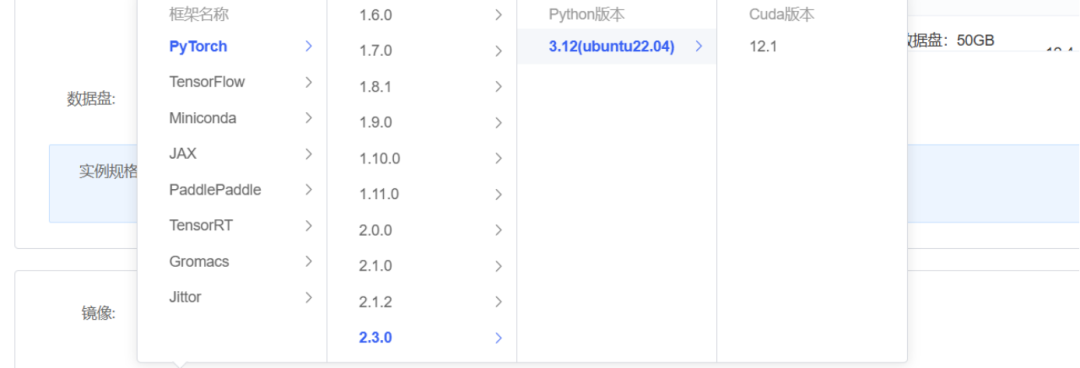
2、安装依赖
首先 pip 换源加速下载并安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install fastapi==0.111.1
pip install uvicorn==0.30.3
pip install modelscope==1.16.1
pip install transformers==4.42.4
pip install accelerate==0.32.1
安装完成如下:

3、模型下载
使用 modelscope 中的 snapshot_download 函数下载模型。第一个参数为模型名称,参数 cache_dir 用于指定模型的下载路径。
在 /root/autodl-tmp 路径下新建 d.py 文件,并在其中输入以下内容:
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3.1-8B-Instruct', cache_dir='/root/autodl-tmp', revision='master')
如下:

运行 python /root/autodl-tmp/d.py 执行下载。需注意,模型大小约为 15GB,下载模型大概需要 20 分钟,请耐心等待。

4、模型推理
1)推理测试
# 导入所需的库
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 加载预训练的分词器和模型
model_name_or_path = '/root/autodl-tmp/LLM-Research/Meta-Llama-3___1-8B-Instruct'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto", torch_dtype=torch.bfloat16)
# 定义对话消息列表,包含系统角色和用户角色的消息
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"}
]
# 使用分词器将对话消息转换为模型输入格式
input_ids = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 将输入转换为PyTorch张量并移动到GPU设备上
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
# 使用模型生成回复
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)
# 从生成的ID中提取回复部分
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 使用分词器将生成的ID解码为文本
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
执行成功如下:

查看响应结果
response
结果如下:
"I'm an artificial intelligence model designed to assist and communicate with users in a helpful and informative way. I'm a type of chatbot, and my primary function is to provide information, answer questions, and engage in conversation to the best of my abilities.\n\nI don't have a personal identity or emotions, but I'm here to help you with any questions or topics you'd like to discuss. I can provide information on a wide range of subjects, from science and history to entertainment and culture. I can also help with tasks such as language translation, text summarization, and even creative writing.\n\nHow can I assist you today?"
2)中文测试一
# 定义对话消息列表,包含系统角色和用户角色的消息
messages = [
{"role": "user", "content": "你会讲中文么?"}
]
# 使用分词器将对话消息转换为模型输入格式
input_ids = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 将输入转换为PyTorch张量并移动到GPU设备上
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
# 使用模型生成回复
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)
# 从生成的ID中提取回复部分
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 使用分词器将生成的ID解码为文本
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
response
输出如下:

3)中文测试二
# 定义对话消息列表,包含系统角色和用户角色的消息
messages = [
{"role": "user", "content": "请以“夜晚”为题写一首诗"}
]
# 使用分词器将对话消息转换为模型输入格式
input_ids = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 将输入转换为PyTorch张量并移动到GPU设备上
model_inputs = tokenizer([input_ids], return_tensors="pt").to('cuda')
# 使用模型生成回复
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)
# 从生成的ID中提取回复部分
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
# 使用分词器将生成的ID解码为文本
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
response
输出如下:

注意:如果推理报错如下
File ~/miniconda3/lib/python3.10/site-packages/transformers/models/llama/configuration_llama.py:182, in LlamaConfig._rope_scaling_validation(self) 179 return 181 if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:--> 182 raise ValueError( 183 "`rope_scaling` must be a dictionary with two fields, `type` and `factor`, " f"got {self.rope_scaling}" 184 ) 185 rope_scaling_type = self.rope_scaling.get("type", None) 186 rope_scaling_factor = self.rope_scaling.get("factor", None)
ValueError: `rope_scaling` must be a dictionary with two fields, `type` and `factor`, got {'factor': 8.0, 'low_freq_factor': 1.0, 'high_freq_factor': 4.0, 'original_max_position_embeddings': 8192, 'rope_type': 'llama3'}
则需要升级transformers:
pip install --upgrade transformers
资源消耗如下:
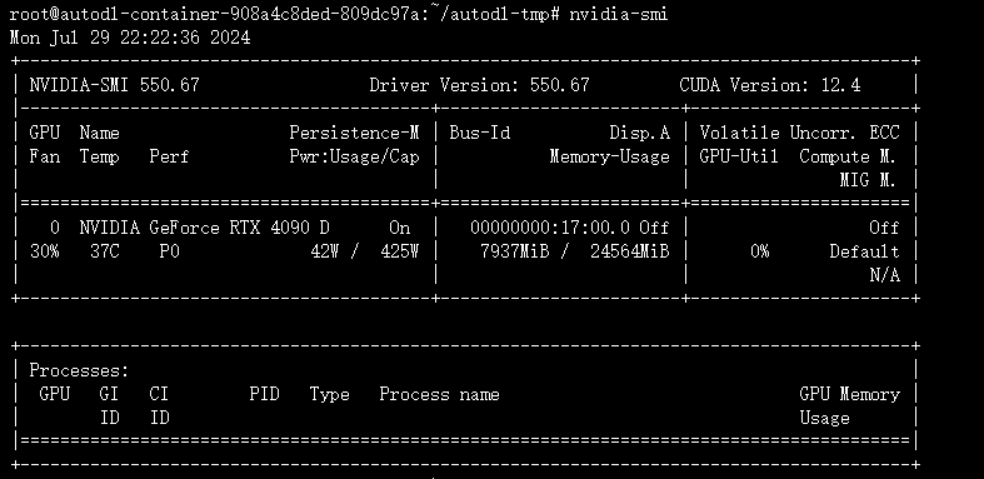
文章最后
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频,免费分享!

一、大模型全套的学习路线
L1级别:AI大模型时代的华丽登场
L2级别:AI大模型API应用开发工程
L3级别:大模型应用架构进阶实践
L4级别:大模型微调与私有化部署

达到L4级别也就意味着你具备了在大多数技术岗位上胜任的能力,想要达到顶尖水平,可能还需要更多的专业技能和实战经验。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人在大模型时代,需要不断提升自己的技术和认知水平,同时还需要具备责任感和伦理意识,为人工智能的健康发展贡献力量。
有需要全套的AI大模型学习资源的小伙伴,可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

如有侵权,请联系删除。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









