






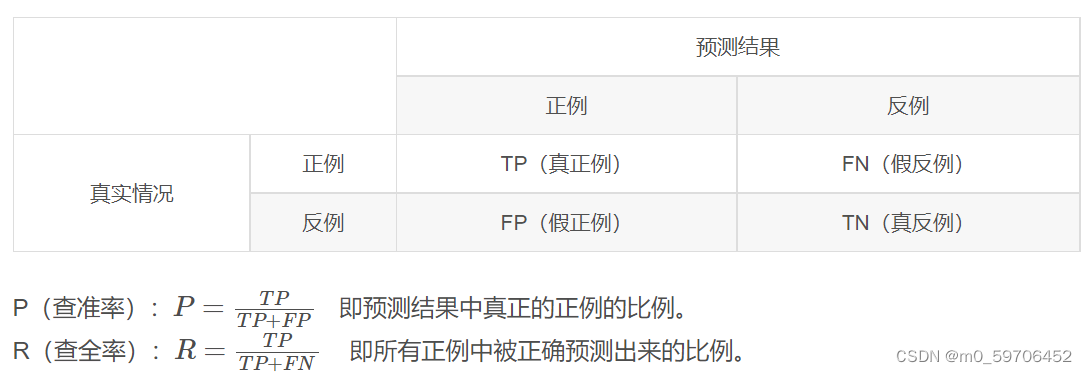
一、P、R、F1
P:precision R:recall
二、P-R曲线:
根据学习器的预测结果按正例预测可能性(概率值)大小进行排序。如目标检测问题,每确定一个概 率值即可得到一组P-R值,对概率值从大到小循环后可 以得到“P-R曲线”。
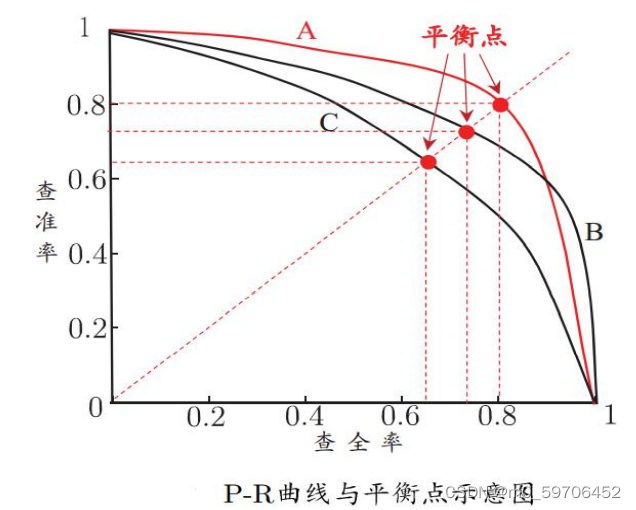
平衡点是曲线上“查准率=查全率”时的取值,可用来用于度量P-R曲线有交叉的分类器性能高低
三、绘制P-R图
代码来源:机器学习:python绘制P-R曲线与ROC曲线 - 代码天地 (codetd.com)
了解了查全率和查准率的相应的概念,我们就可以进行P-R曲线的绘制。我们知道,算法对样本进行分类的时候,都会有置信度,也就是表示该样本为正例的概率。然后通过选取合适的阈值,对样本概率进行划分,比如阈值为50%时,就是其置信度大于50%,那么它就是正例,否则它就是反例。
这里绘制图线同样的道理,我们要产生随机的概率,表示每个样本例子为正例的概率,然后通过这些概率进行从大到小的排序,再按此顺序逐个样本的选择阈值,大于阈值的概率的样例为正例,后面的全部为反例。我们将数据中每个样例的概率作为阈值,然后得到相应的查全率和查准率,这样我们可以许多数据,根据这些数据绘制图线,我们给出代码:
代码:
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.font_manager import FontProperties
def plot(dict,lists):#画出函数图像
fig = plt.figure()
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
plt.xlabel('查全率(R)',fontproperties=font)
plt.ylabel('查准率(P)',fontproperties=font)
x = np.arange(0,1.0,0.2)
y = np.arange(0,1.0,0.2)
plt.xticks(x)
plt.yticks(y)
plt.plot(dict,lists)
plt.show()
def caculate():
num_real = 0
#初始化样本标签,假设1为正例,0为负例
trainlabel = np.random.randint(0,2,size=100)
#产生100个概率值(置信度),即单个样本值为正例的概率
traindata = np.random.rand(100)
#将样本数据为正例概率从大到小排序返回索引值
sortedTraindata = traindata.argsort()[::-1]
k = []
v = []
#统计样本中实际正例的数量
num = np.sum(trainlabel==1)
for i in range(100):
num_guess = i+1#假设为真的数量
for j in range(0,i+1):
a = sortedTraindata[j]
if trainlabel[a] == 1:
num_real += 1#假设为真中实际也为真的数量
p = float(num_real/(num_guess))
r = float(num_real/(num))
v.append(p)
k.append(r)
num_real = 0
plot(k,v)
if __name__=='__main__':
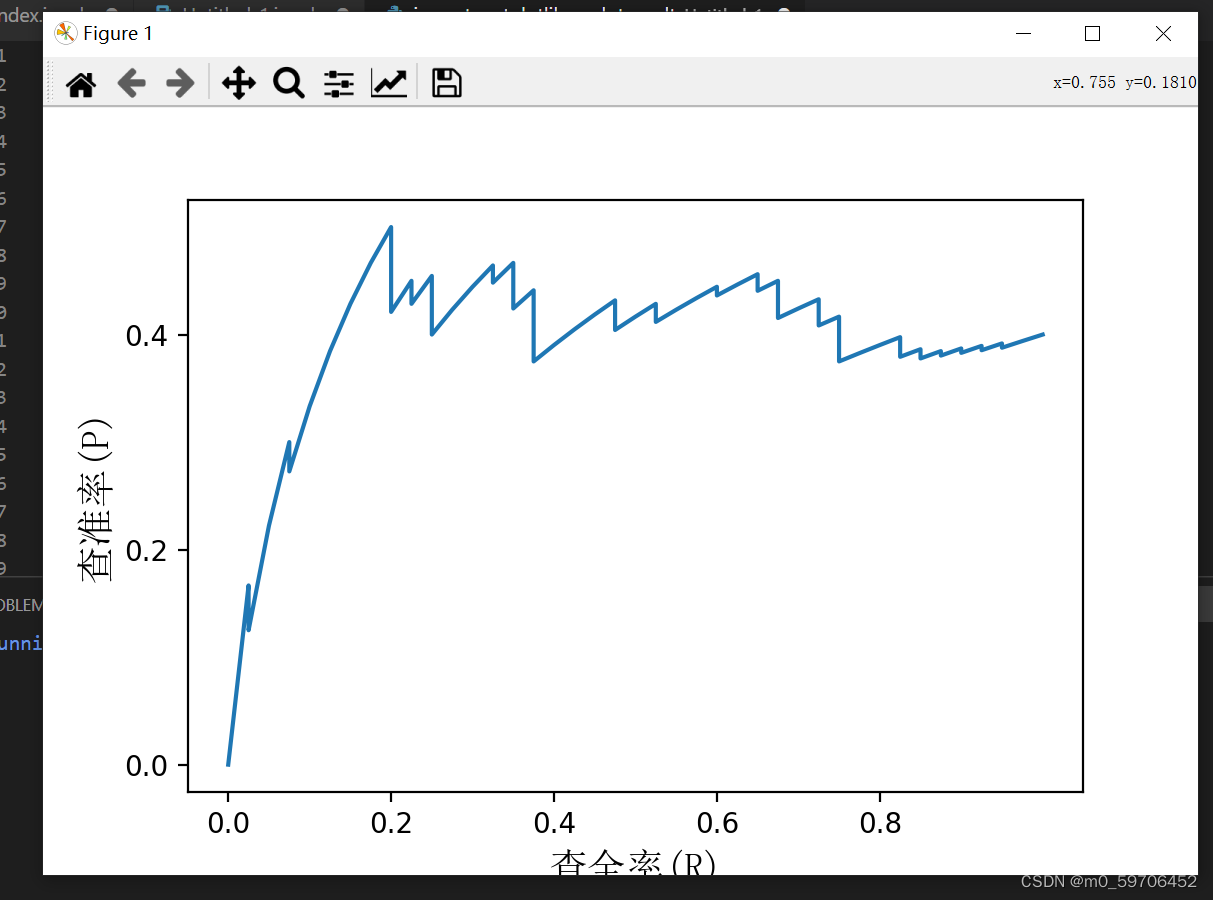
caculate()实验结果:















 2324
2324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









