






 本文涵盖了Python编程的一些基本概念,如安装扩展库(pip和conda)、函数定义、字典操作、匿名函数(lambda)、元组和列表的使用,以及字符串操作。此外,还讨论了异常处理、Pandas与NumPy的区别以及数据降维技术PCA的应用。
本文涵盖了Python编程的一些基本概念,如安装扩展库(pip和conda)、函数定义、字典操作、匿名函数(lambda)、元组和列表的使用,以及字符串操作。此外,还讨论了异常处理、Pandas与NumPy的区别以及数据降维技术PCA的应用。
pyrhon——一些题目
- 填空
- 选择
- 判断
- 23、在 Python 语言中,集合的元素能否重复?
- 24、在 Python 语言中,一行代码表示一条语句,语句结束可以加分号,也可省略分号是否正确?
- 25、python是否支持函数重载?
- 26、调用函数时传递的实参个数是否必须与函数形参个数相等?
- 27、哪些数据是有序的?哪些是无序的?
- 28、numpy库的append()和insert()有没有返回值?
- 29、python不允许使用关键字作为变量名,允许使用内置函数作为变量名,但这会改变函数名的含义。说法是否正确?
- 30、N算法是k-Nearest Neighbor的简称,叫作k近邻算法,属于有监督学习算法,既可以用于分类,也可以用于回归。说法是否正确?
- 31、Python语言中同一个集合中的元素不会重复,每个元素都是唯一的。说法是否正确?
- 32、DBSCAN算法不需要预先指定聚类数量,但对用户设定的参数非常敏感。当空间聚类的密度不均匀、聚类间距相差很大时,聚类质量较差。说法是否正确?
- 33、扩展库pandas的read_csv()函数的用法
- 34、Zigbee是一种近距离、低功耗、低速率的双向无线通信技术。说法是否正确?
- 35、在样本的众多特征中,并不是每个特征都对要分析的问题有贡献。即使是对问题有贡献的若干特征,每个特征的重要程度可能也不一样。说法是否正确?
- 简答
- 编程
填空
1、Python 安装扩展库常用的Python 安装扩展库常用的工具是什么?
python安装扩展库常用的工具是pip和conda。pip是Python包管理工具,该工具提供了对Python包的查找、下载、安装、卸载功能。conda需要安装Python集成开发环境Anaconda3之后才可以使用。
2、Python程序文件主要两种扩展名
py:python程序源文件的后缀名
pyw:此文件扩展名一般使用在python窗口程序上面,并且它在执行的时候是不会出现命令行控制台的。
3、在单片机上运行的Python版本
MicroPython
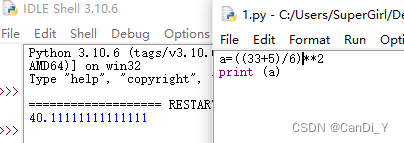
4、 ((33+5)/6)^2
40.11111111111111
5、字典对象的什么方法返回字典中的"键"的列表
使用字典对象的 items() 方法可以返回字典的“键 - 值对”列表,使用字典对象的 keys() 方法可以返回字典的“键”列表,使用字典对象的 values() 方法可以返回字典的“值”列表
6、Python可使用什么来创建匿名函数
在python3中,想处理一个简单的逻辑功能可以使用lambda来创建匿名函数
7、元组的len,set方法
len():计算元组元素个数
set():将元组转换为集合(set)类型,去掉其中的重复元素
8、Python可使用哪两种格式的文件
文本文件:这种格式的文件包含了纯文本,可以被人类读懂。Python可以很容易地读取和写入这种格式的文件。例如,Python的open()函数可以用于打开文本文件,并且可以使用read()和write()函数来读取和写入文件内容。
二进制文件: 这种格式的文件包含了二进制数据,无法被人类直接读取。二进制文件通常用于存储图像、音频、视频等媒体数据,也可以用于存储序列化的Python对象。Python的内置模块pickle可以用于将Python对象序列化为二进制数据,而struct模块可以用于打包和解包二进制数据。二进制文件可以使用Python的open()函数以二进制模式打开。
选择
9、Python的转义字符
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \’ | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
10、Python函数的定义
Python 提供了一个功能,允许我们将常用的代码以固定的格式封装(包装)成一个独立的模块,只要知道这个模块的名字就可以重复使用它,这个模块就叫做函数。
# 函数的简单定义
def 函数名(参数列表):
//实现特定功能的多行代码
[return [返回值]]
11、range()的使用
range() 函数可创建一个整数列表,一般用在 for 循环中。
语法:range([start,] stop[, step])
参数说明:
start: 计数从 start 开始。可选,默认为0。
stop: 计数到 stop 结束,但不包括 stop。
step:步长,可选,默认为1。
>>> a = range(5) # 即 range(0,5)
>>> a
range(0, 5)
>>> len(a)
5
>>> for x in a:
>>> print(x,end=" ")
0 1 2 3 4
# 对于 range() 函数,有几个注意点:
# (1)左闭右开
>>> for i in range(3, 6):
>>> print(i,end=" ")
3 4 5
# (2)参数类型:接收的参数必须是整数,可以是负数,但不能是浮点数等其它类型
>>> for i in range(-8, -2, 2):
>>> print(i,end=" ")
-8 -6 -4
>>> range(2.2)
----------------------------
TypeError Traceback (most recent call last)
...
TypeError: 'float' object cannot be interpreted as an integer
# (3)序列操作:不可变的序列类型,可以进行判断元素、查找元素、切片等操作,但不能修改元素
>>> b = range(1,10)
>>> b[0]
1
>>> b[:-3]
range(1, 7)
>>> b[0] = 2
TypeError Traceback (most recent call last)
...
TypeError: 'range' object does not support item assignment
# (4)不是迭代器
>>> hasattr(range(3),'__iter__')
True
>>> hasattr(range(3),'__next__')
False
>>> hasattr(iter(range(3)),'__next__')
True
12、元组、列表的定义及格式
首先了解序列:在python中常用到的数据结构一般为序列,我们在编程的时候几乎都会用到序列。序列中的每个元素都有编号,即索引,第一个元素的索引为0,以此类推,而用负索引来表示序列末尾元素的位置
序列主要包括:列表、元组和字符串等。(这三种最常见)
列表:列表是python中使用次数最频繁的一种序列,主要是可以实现添加、修改、删除、切片等操作
# 列表的操作
# 一、添加
# (1) append : 在列表的末尾添加一个元素
l1 = [1,2,3,4,5]
l2 = [3,2,1]
l1.append(2)
print(l1) # 输出:[1,2,3,4,5,2]
l1.append(l1) # 将l2作为一个元素添加到列表的末尾,包括l2的[]
print(l1) # 输出:[1,2,3,4,5,2,[3,2,1]]
# (2) extend : 在列表的末尾至少添加一个元素
l1 = [1,2,3,4,5]
l2 = [3,2,1]
l1.append(l2)
print(l1) # 输出:[1,2,3,4,5,3,2,1] 注意:与append的对比
# (3) insert : 将某一个对象插入列表指定的索引位置中
l = ['a','b','b','c','d']
l.insert(2,'e')
print(l) # 输出: ['a','b','e','b','c','d']
# (4) 切片操作也可实现向列表中添加数据 : 在列表的任意位置至少添加一个元素
# 格式:列表变量1[切入位置:切片距离]=列表变量2
# 理解: 从切片位置开始,去除(切片距离-切入位置)个数据,往切入位置插入列表变量2,若没有切片距离默认全切
lst1=['hello','world',10,20,30,40]
lst=[True,False,'python']
lst1[1:]=lst # 没有切入距离,默认lst1[1]开始后面全去除,往lst[1]处开始插入lst
print(lst1) # 输出 : ['hello',True,False,'python']
lst2=['hello','world',10,20,30,40]
lst2[1:1]=lst # 从lst2[1]开始去除1-1个数据,往lst2[1]开始插入lst
print(lst2) # 输出:['hello',True,False,'Python','world',10,20,30,40]
lst3=['hello','world',10,20,30,40]
lst3[1:2]=lst # 从lst3[1]开始去除2-1个数据,往lst3[1]开始插入lst
print(lst3) # 输出 : ['hello', True, False, 'python', 10, 20, 30, 40]
# 二、删除
# (1) clear : 清空列表的所有内容
l = [1,2,3,4,5]
l.clear()
print(l) #输出:[]
# (2) pop : 删除指定索引上的元素,指定索引不存在抛出IndexError,不指定索引,删除列表中的最后一个元素
l = [1,2,3,4,5]
l.pop(2)
print(l) #输出:[1,2,4,5]
# (3) remove : 删除一个元素,若有重复元素则删除第一个,若元素不存在则抛出ValueError
lst=['hello','world',10,20,30,10,40,]
lst.remove(10)
print(lst) # 输出:['hello', 'world', 20, 30, 10, 40]
# (4) 切片 : 一次至少删除一个元素(注意切片可以留下不想要的数据,也可以是去掉不想要的数据)
# 去除掉不想要的数据
lst1=['hello','world','hello',10,20,30,40]
lst1[1:3]=[] # 本质是用空列表代替原来的元素
print(lst1) # 输出: ['hello',10,20,30,40]
#保留想要的数据
lst2=['hello','world','hello',10,20,30,40]
lst2=lst2[1:3] #此时的操作时留下了[1,3)上面的元素
print(lst2) # 输出:['world', 'hello']
# (5) del : 删除列表
lst=['hello','world','hello',10,20,30,40]
del lst
print(lst) # NameError: name ‘lst’ is not defined
# 三、修改
# (1) 为指定索引的元素赋新值
# (2) 为指定切片赋新值
lst=[10,20,30,40,50]
lst[1:3]=[200,300] #将列表中的1位置和2位置替换为200,300
print(lst) # [10, 200, 300, 40, 50]
lst[1:3]=[50,60,70,80] #将列表中的1位置和2位置替换为50,60,70,80
print(lst) # [10, 50, 60, 70, 80, 40, 50]
# 四、排序
# (1) sort: 对列表中的元素就地排序
l = [3,2,1,4,5]
l.sort()
print(l) # 输出:[1,2,3,4,5]
# (2) sorted : 与sort的区别是sort是在原列表中排序,而sorted是产生新列表
# 五、其他方法
# (1) copy : 复制列表内容
l = [1,2,3,4,5]
a = l.copy()
print(a[1]) #输出:2
# (2) count : 指定元素列表中出现的次数
l = ['a','b','b','c','d']
print(l.count('b')) #输出:2
# (3) index : 表示某个元素在列表中第一次出现的索引位置
l = ['a','b','b','c','d']
print(l.index('c')) #输出:3
# (4) reverse : 将列表中的顺序进行翻转
l = [1,2,3,4,5]
l.reverse()
print(l) # 输出:[5,4,3,2,1]
元组:元组与列表类似,只是表示的方法和可操作性不同,即列表用[]而元组用()表示方法,列表可以可变的而元组是不可变的。
13、字符串的加法和乘法
序列的相加和乘法并不是数学意义上的数学运算,二十将他们进行拼接,并且相加只能对同一类型的序列进行相加。
# (1) 相加
s="Hello"
print(s+s[2]) # Hellol
print(s+s) # HelloHello
# (2) 乘法
print(s*3) # HelloHelloHello
14、列表的添加
见12
15、Python用什么方法来创建文件
open()函数: 使用写入的文件模式去打开一个当前路径下并不存在的文件,它就会自动的去创建出这个文件,w、w+、a+、a这个写文件模式都能创建新文件。
使用os模块: 在os模块之中有着mknod()方法可以去创建任意类型的空文件,但是需要当前的文件路径下没有同名文件,所以一般要先获取到路径,然后再通过检测是否有这个文件的方法才能创建文件
16、upper()的用法
upper() 方法将字符串中的小写字母转为大写字母。
s='abcdeF'
print(s) #abcdeF
s1=s.upper()
print(s1) #ABCDEF
17、条件表达式
expressionq1 if condition else expression2
x=10
y=11
max=x if x>y else y
print(max) # 11
18、a[-3:-2]截取了哪些字符
在Python中,a[-3:-2]表示从a的倒数第三个元素(包括该元素)开始,到倒数第二个元素(不包括该元素)结束的一个切片。因此,a[-3:-2]截取了a中的倒数第3个元素。
a=[1,2,3,4,5,6]
print(a) # [1,2,3,4,5,6]
a=a[-3:-2]
print(a) #[4]
19、beak、continue、exit的用法
break:用于跳出当前循环,不再执行循环中的剩余语句,而是继续执行循环之后的语句。
continue:用于跳过当前循环中的剩余语句,直接进入下一次循环。
exit:用于退出程序。
20、在Python中,有列表users,语句while users:的终止条件为什么?
当在Python中使用while循环时,循环的终止条件是判断条件语句的值是否为False。在这种情况下,当列表users为空时,条件语句的值为False,循环将终止。因此,语句while users: 的终止条件为列表users为空。循环体内,如果从列表中删除了所有元素,循环将终止。
users=[0,1,2,3,4]
i=0
while users:
i=i+1
users.pop()
print(i) # 5
21、在Python中,对文件的读操作有哪些方法?
read()方法: 一次性读取整个文件内容,返回字符串类型。
with open('{文件路径}', 'r') as f:
data = f.read()
readline()方法: 每次读取文件的一行内容,返回字符串类型。如果读取到文件末尾,返回空字符串。
with open('{文件路径}', 'r') as f:
line = f.readline()
while line:
print(line)
line = f.readline()
# 逐行读取文件内容并在每行内容后面执行一些操作
readlines()方法: 一次性读取整个文件内容,返回列表类型,其中每个元素为文件的一行内容。
with open('{文件路径}', 'r') as f:
data = f.readlines()
直接打开就读:
with open('filepath','r') as f:
for line in f:
print(line)
print('一行数据')
虽然f是一个文件实例,但可以通过以上方式对每一行进行循环处理了,处理时每一行是一个字符串str,而且这个是速度最快最简洁的方法。
22、显式抛出异常的语句是什么?
在Python中,显式抛出异常的语句是 raise。使用 raise 语句可以手动抛出异常。
raise 唯一的参数就是要抛出的异常。这个参数必须是一个异常实例或者是一个异常类(派生自 Exception 的类)。如果传递的是一个异常类,它将通过调用没有参数的构造函数来隐式实例化。

在上面的示例中,raise 语句抛出了一个 Exception 异常,并指定了异常消息为 “Something went wrong.”。我们也可以使用其他类型的异常对象,如 ValueError、TypeError、ZeroDivisionError 等等。
通常情况下,我们会在代码中添加适当的异常处理来捕获可能出现的异常。但是在某些情况下,我们需要手动抛出异常来表示程序遇到了无法继续执行的错误,这时 raise 语句就派上用场了。
判断
23、在 Python 语言中,集合的元素能否重复?
(否)
在 Python 语言中,集合的元素是不能重复的。集合是一种无序、可变、且元素唯一的容器类型,可以用大括号 {} 或 set() 函数来创建。当你向集合中添加一个已经存在的元素时,集合并不会发生变化,因为集合中已经有了该元素。这是因为集合使用哈希表来存储元素,每个元素都有唯一的哈希值,相同的元素会有相同的哈希值,因此集合只保留一个元素。
24、在 Python 语言中,一行代码表示一条语句,语句结束可以加分号,也可省略分号是否正确?
(是)
25、python是否支持函数重载?
(否)
在 Python 中,函数的名称是唯一的,因此无法通过参数的类型和数量来区分同名函数,也就无法实现函数重载。
26、调用函数时传递的实参个数是否必须与函数形参个数相等?
(否)
Python 允许为参数设置默认值,即在定义函数时,直接给形式参数指定一个默认值。这样的话,即便调用函数时没有给拥有默认值的形参传递参数,该参数可以直接使用定义函数时设置的默认值。
27、哪些数据是有序的?哪些是无序的?
在 Python 中,列表(list)、元组(tuple)、字符串(string)和字节数组(bytearray)是有序的数据类型。集合(set)和字典(dict)是无序的数据类型。有序的数据类型可以按照特定的顺序访问其中的元素,而无序的数据类型则不能。
28、numpy库的append()和insert()有没有返回值?
numpy库的 append() 和 insert() 函数都会修改原数组,并且它们的返回值是修改后的数组。如果要将修改后的数组保存到一个新的变量中,需要将返回值赋值给一个新变量。
29、python不允许使用关键字作为变量名,允许使用内置函数作为变量名,但这会改变函数名的含义。说法是否正确?
(是)
Python 不允许使用关键字作为变量名,因为关键字是 Python 语言中的保留字,具有特定的含义。Python 允许使用内置函数名作为变量名,但是这会覆盖原有函数的含义,不建议这么做。
30、N算法是k-Nearest Neighbor的简称,叫作k近邻算法,属于有监督学习算法,既可以用于分类,也可以用于回归。说法是否正确?
(否)
KNN算法
31、Python语言中同一个集合中的元素不会重复,每个元素都是唯一的。说法是否正确?
(是)
Python 语言中的集合(set)确实不允许元素重复,每个元素都是唯一的。如果将重复的元素添加到集合中,只会保留一个元素。
32、DBSCAN算法不需要预先指定聚类数量,但对用户设定的参数非常敏感。当空间聚类的密度不均匀、聚类间距相差很大时,聚类质量较差。说法是否正确?
(是)
33、扩展库pandas的read_csv()函数的用法
read_csv()函数是Pandas中常用的函数之一,用于从CSV文件中读取数据并返回一个DataFrame对象。
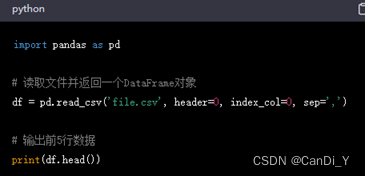
在这个示例中,read_csv()函数从名为file.csv的文件中读取数据,并将第一行作为列名,第一列作为行索引,并使用逗号作为分隔符。最后,我们通过调用head()函数输出DataFrame的前5行数据。
34、Zigbee是一种近距离、低功耗、低速率的双向无线通信技术。说法是否正确?
(是)
35、在样本的众多特征中,并不是每个特征都对要分析的问题有贡献。即使是对问题有贡献的若干特征,每个特征的重要程度可能也不一样。说法是否正确?
(是)
简答
1、 在Python 中导入模块中的对象有哪几种方式?
import 模块名 [as 别名 ] 直接导入整个模块
from 模块名 import 对象名 [ as 别名 ] 将模块中的指定函数导入命令空间
from 模块名 import *
2、 简述如何使用xpath进行爬虫。
在Python中使用XPath进行爬虫可以使用第三方库lxml或者内置的标准库xml.etree.ElementTree来解析HTML或XML文档。下面是使用lxml库进行爬虫的基本步骤:
①安装lxml库:可以使用pip进行安装,命令为 pip install lxml
②导入库:
③获取网页源代码:可以使用Python的requests库发送HTTP请求获取网页源代码。
④解析HTML文档:使用etree模块中的fromstring方法将HTML文本转换为Element对象,以便进行XPath查询。
⑤使用XPath进行查询:使用xpath方法,传入XPath查询表达式来获取需要的信息。
⑥处理获取的数据:获取到的数据可以保存到本地文件、数据库等等。
3、 简单解释Python基于值的自动内存管理方式
Python采用的是基于值得内存管理方式,在Python中可以为不同变量赋值为相同值,这个值在内存中只有一份,多个变量指向同一个内存地址;Python具有自动内存管理功能,会自动跟踪内存中所有的值,对于没有任何变量指向的值,Python自动将其删除。
4、 简述Pandas和NumPy的区别与联系。
NumPy和Pandas都是Python中常用的数据处理库,它们在一定程度上有一些相似的地方,也有许多不同之处。下面是它们的主要区别和联系:
区别:
①数据类型:NumPy主要用于处理数值类型的数组,而Pandas主要用于处理表格型的数据(例如CSV文件、SQL数据库、Excel表格等)。
②数据结构:NumPy主要提供ndarray多维数组对象,而Pandas则提供了Series和DataFrame对象。
③数据分析功能:Pandas提供了许多用于数据分析和数据操作的函数和方法,例如数据清洗、重塑、聚合、分组、统计等,而NumPy则更注重数值计算和科学计算方面的功能。
联系:
①依赖关系:Pandas是基于NumPy构建的,因此Pandas中许多函数和方法的实现都依赖于NumPy数组的基础。
②共同点:NumPy和Pandas都是Python数据处理生态系统中非常重要的两个组成部分,许多数据分析和科学计算库都与它们配合使用,例如SciPy、Matplotlib、scikit-learn等。
总之,NumPy和Pandas在数据处理和分析方面都有其各自的优势和特点,程序员可以根据实际需求选择合适的库来进行数据处理和分析。
5、 Python中异常值处理可分为哪几种?
删除含有异常值的记录:直接将含有异常值的记录删除;
视为缺失值:将异常值视为缺失值,利用缺失值处理的方法进行处理;
平均值修正:可用前后两个观测值的平均值修正该异常值;
不处理:直接在具有异常值的数据集上进行数据挖掘;
6、 简述运用PCA对高维数据进行降维的优点。
PCA(Principal Component Analysis)是一种常见的数据降维方法,它可以将高维数据转换为低维数据,同时最大程度地保留数据的特征信息。其优点主要有以下几点:
① 降低计算复杂度:随着数据维度的增加,计算机处理数据所需的计算资源会指数级增加。使用PCA可以减少数据维度,从而降低计算复杂度。
② 减少存储空间:高维数据通常需要占用大量的存储空间。使用PCA可以将数据降维,从而减少存储空间的需求。
③ 去除冗余信息:高维数据通常存在大量冗余信息,这些信息不利于数据处理和分析。使用PCA可以去除冗余信息,提高数据的处理效率和分析准确性。
④ 提高模型性能:在机器学习和数据挖掘任务中,高维数据通常会导致维数灾难和过拟合问题。使用PCA可以减少数据维度,从而提高模型的性能和泛化能力。
⑤ 可视化展示:在高维数据可视化方面,使用PCA可以将数据转换为二维或三维空间,从而方便数据可视化展示和分析
7、 简述list和tuple的区别。
① 可变性:list是可变的,可以增加、删除或修改其中的元素;而tuple是不可变的,一旦创建就无法修改。
② 语法:list用方括号[]括起来,元素之间用逗号,隔开;tuple用圆括号()括起来,元素之间也用逗号,隔开。如果元素只有一个,则需要在后面加一个逗号,,否则会被当作其他类型的值,而不是元组。
③ 性能:由于tuple是不可变的,所以它的操作速度比list更快。
④ 用途:list通常用于需要频繁地修改元素的情况,例如存储日志、维护用户列表等;而tuple通常用于需要保证数据不可变性的情况,例如函数的参数列表、字典的键值对等。


















 2748
2748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









