







Wan 2.1 视频生成模型本地部署(文字转视频)
Wan 2.1(通义万相2.1)是阿里巴巴于2025年2月推出的开源视频生成大模型,专注于从文本或图像生成高质量视频内容。
主要特点:
-
模型规模: 提供1.3B和14B两个参数规模的模型,适用于不同需求。
-
高效性能: 1.3B模型仅需8.19 GB显存,可在消费级GPU上运行。例如,在RTX 4090上,约4分钟即可生成5秒的480P视频。
-
多任务支持: 支持文本生成视频、图像生成视频、视频编辑、文本生成图像和视频生成音频等多种任务。
-
开源协议: 采用Apache 2.0协议,全球开发者可在GitHub、HuggingFace等平台下载并体验。
注:在权威评测集VBench中,万相2.1以总分86.22%的成绩位居榜首,领先于其他视频生成模型。
1、下载 ComfyUI 一键安装包 :支持 Windows 和 mac 系统

点击 download,进入下载页面:
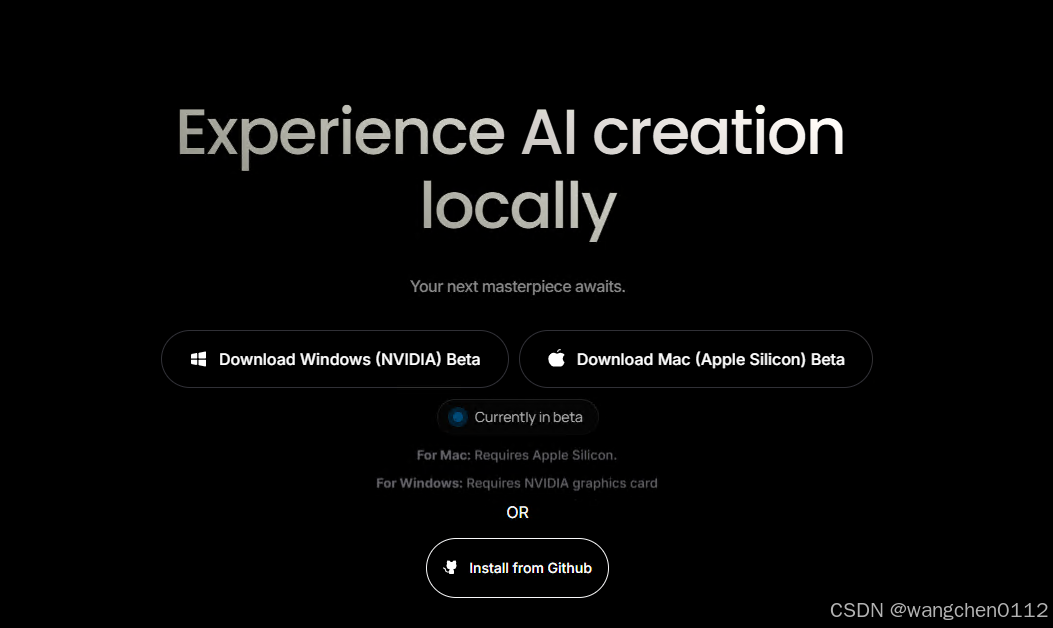
本人电脑 是windows 系统,选择Windows安装包:
点击后,windows开始下载:
点击下载后的文件进行安装:
进入该页面后,点击开始:
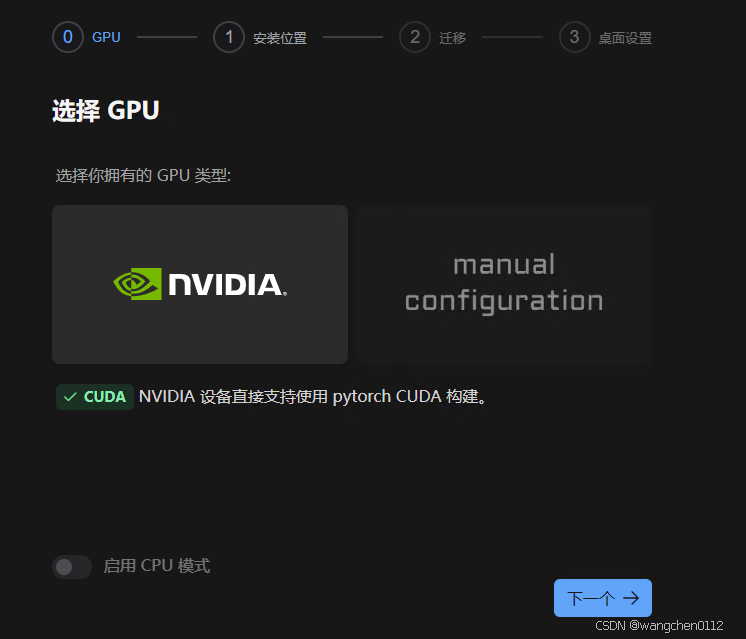
点击 下一步 按钮“显示的是 下一个”,进入安装位置选择页面:
初始页面如下:
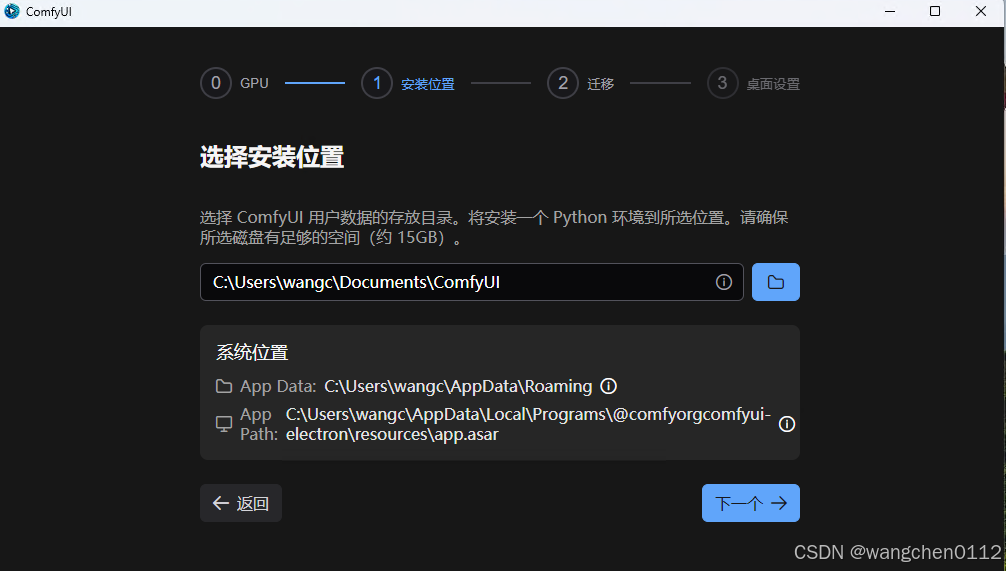
个人不喜欢程序安装在C盘,所以我选择在D盘:

编辑的存储路径如下:
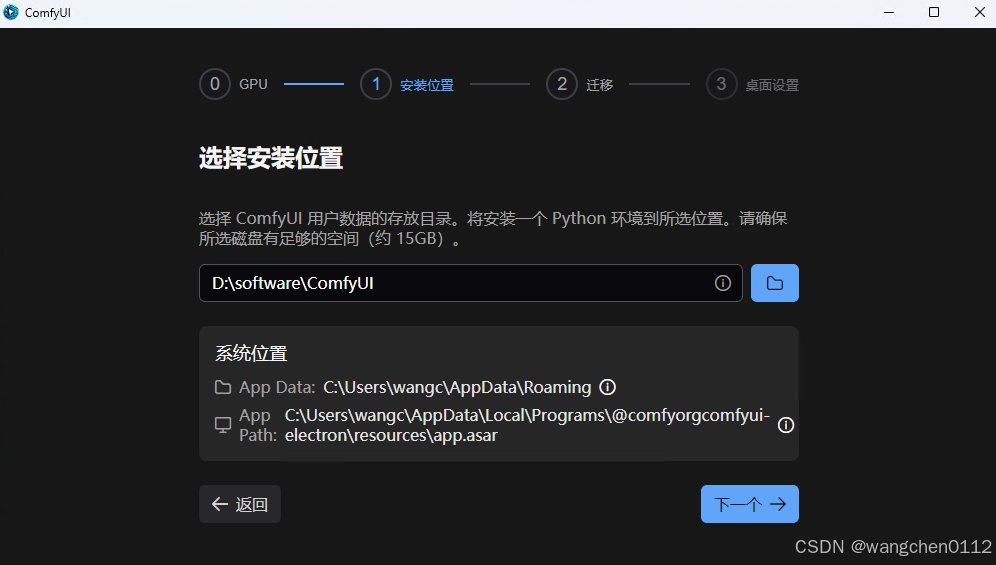
注释:
该路径存储 运行日志和服务器配置

该路径存储代码和资源:
![]()
由于本次是全新安装,所以 直接下一步:
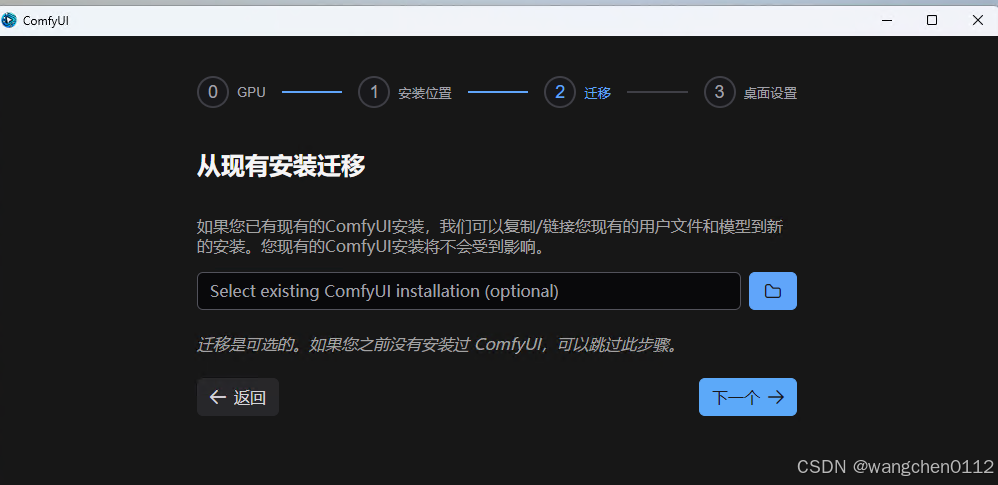
个人习惯关闭自动更新和信息反馈,这点基于个人习惯来定:
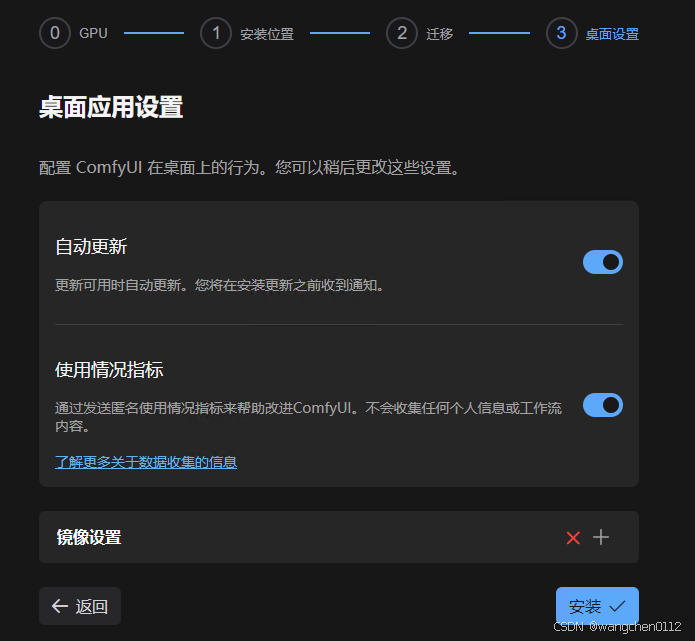
取消后,点击安装button
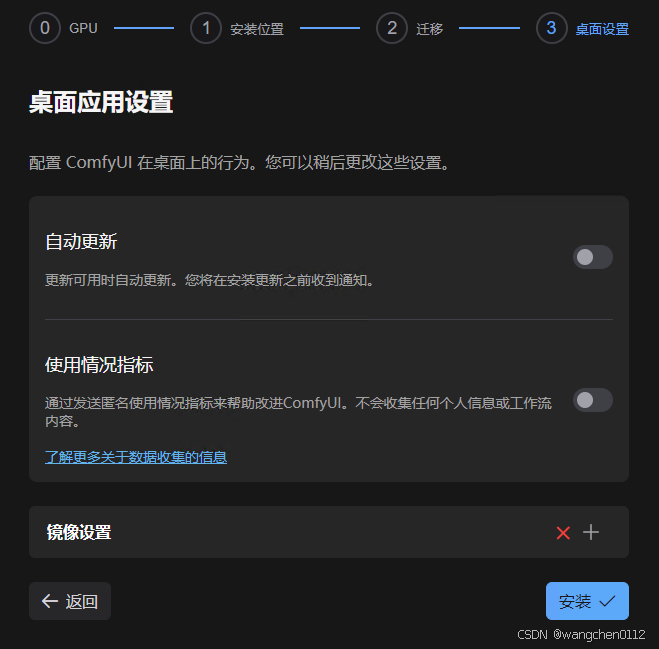
进入安装页面:
接下来会进入比较漫长的安装过程:
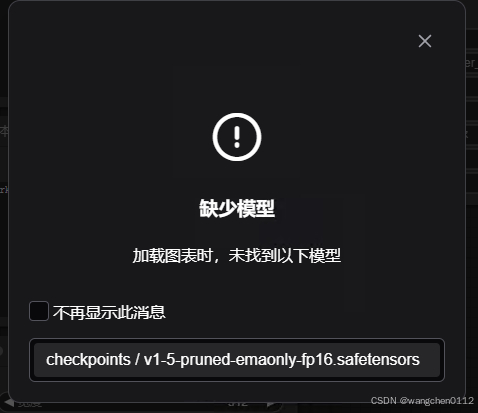
安装完成后系统会自动打开:(并显示缺少模型),点击下载模型
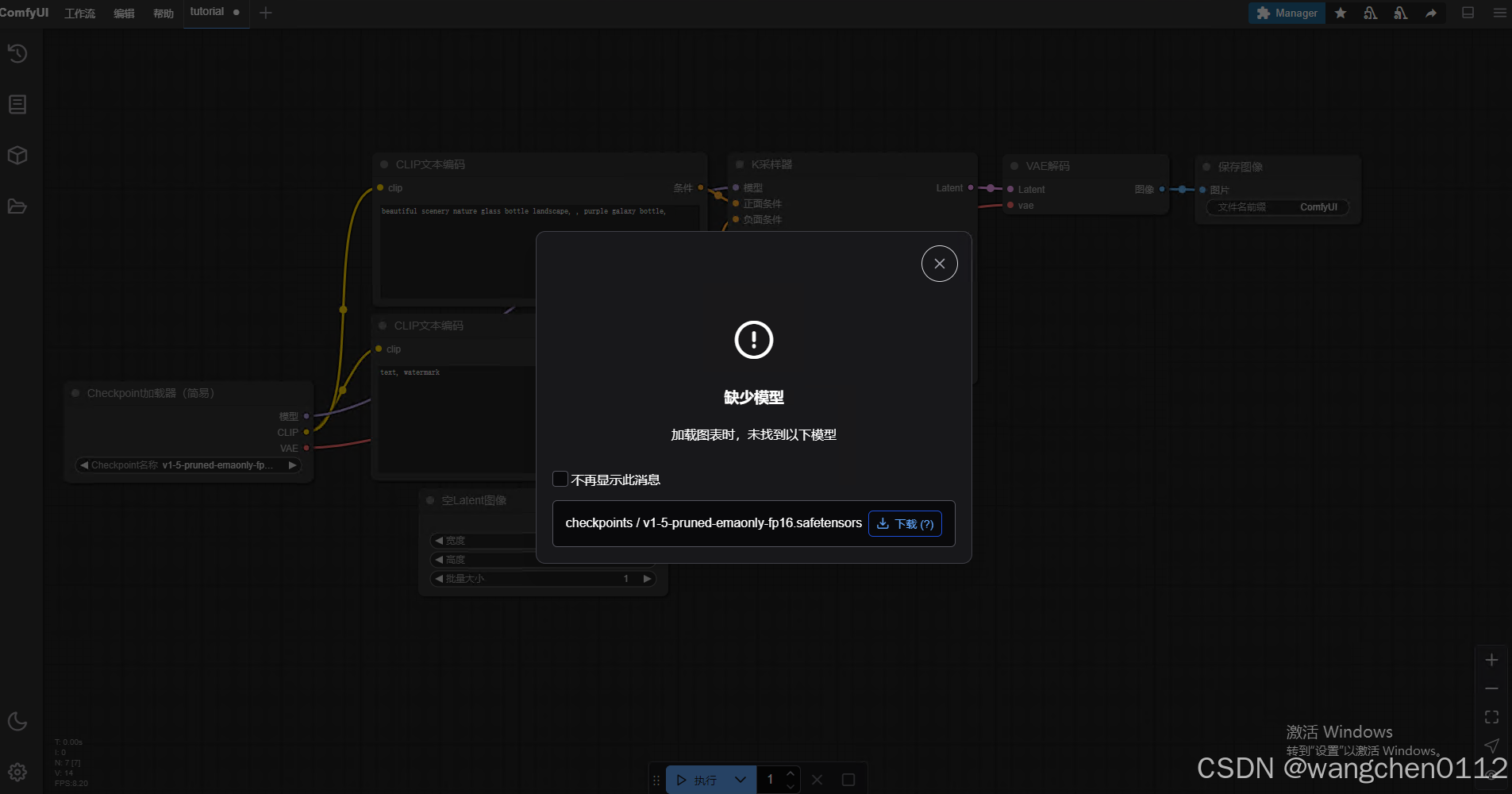
点击下载后,关闭页面
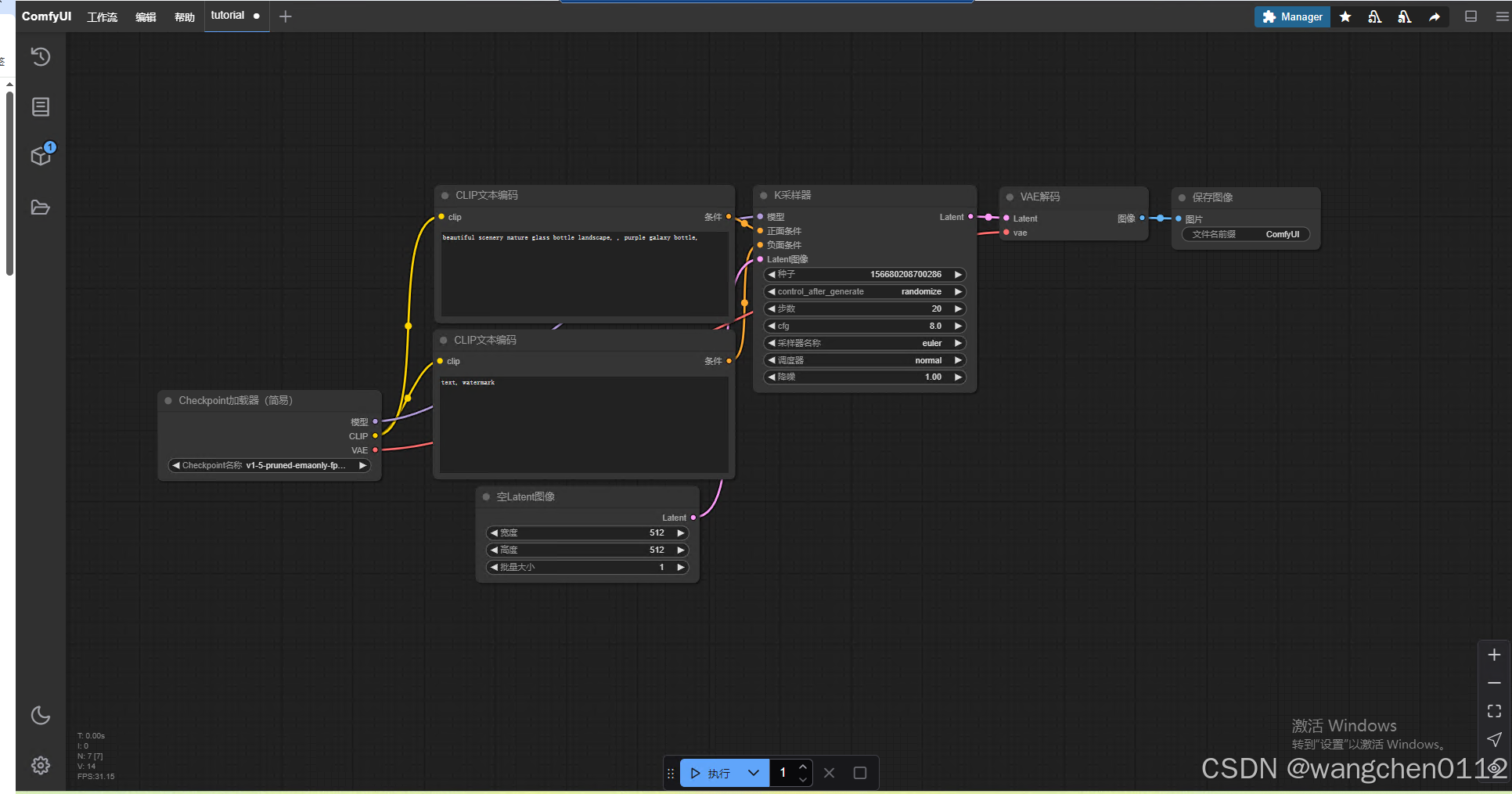
进入系统页面
2、下载文本编码器和 VAE(Variational Autoencoder,变分自编码器)是一种深度学习模型,主要用于生成建模
2.1 下载文本编码器模型文件
如果 URL无法访问,则访问 hf-mirror.com ,https://hf-mirror.com/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders![]() https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
打开页面如下:
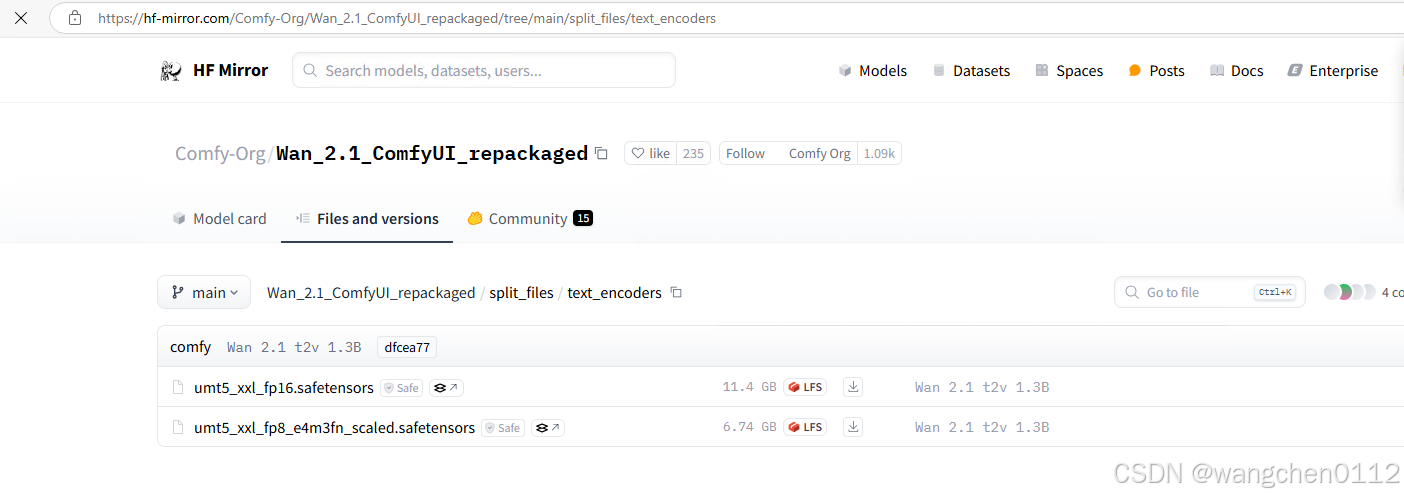
对于模型版本的选择:(本人选择fp8)

等待下载完成:
进入到自己的安装 ComfyUI时,设定的目录:

把下载的模型放入 models/text_encodes/ 这个文件目录下:
2.2 下载VAE模型文件
打开页面如下:
点击download 按钮:
浏览器开始下载:
下载完成后,将下载好的模型,放入文件路径:D:\software\ComfyUI\models\vae 下面:
3、 下载视频生成模型:
如果 URL无法访问,则访问 hf-mirror.com ,
https://hf-mirror.com /Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_models![]() https://hf-mirror.com /Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_models
https://hf-mirror.com /Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_models
打开页面如下:
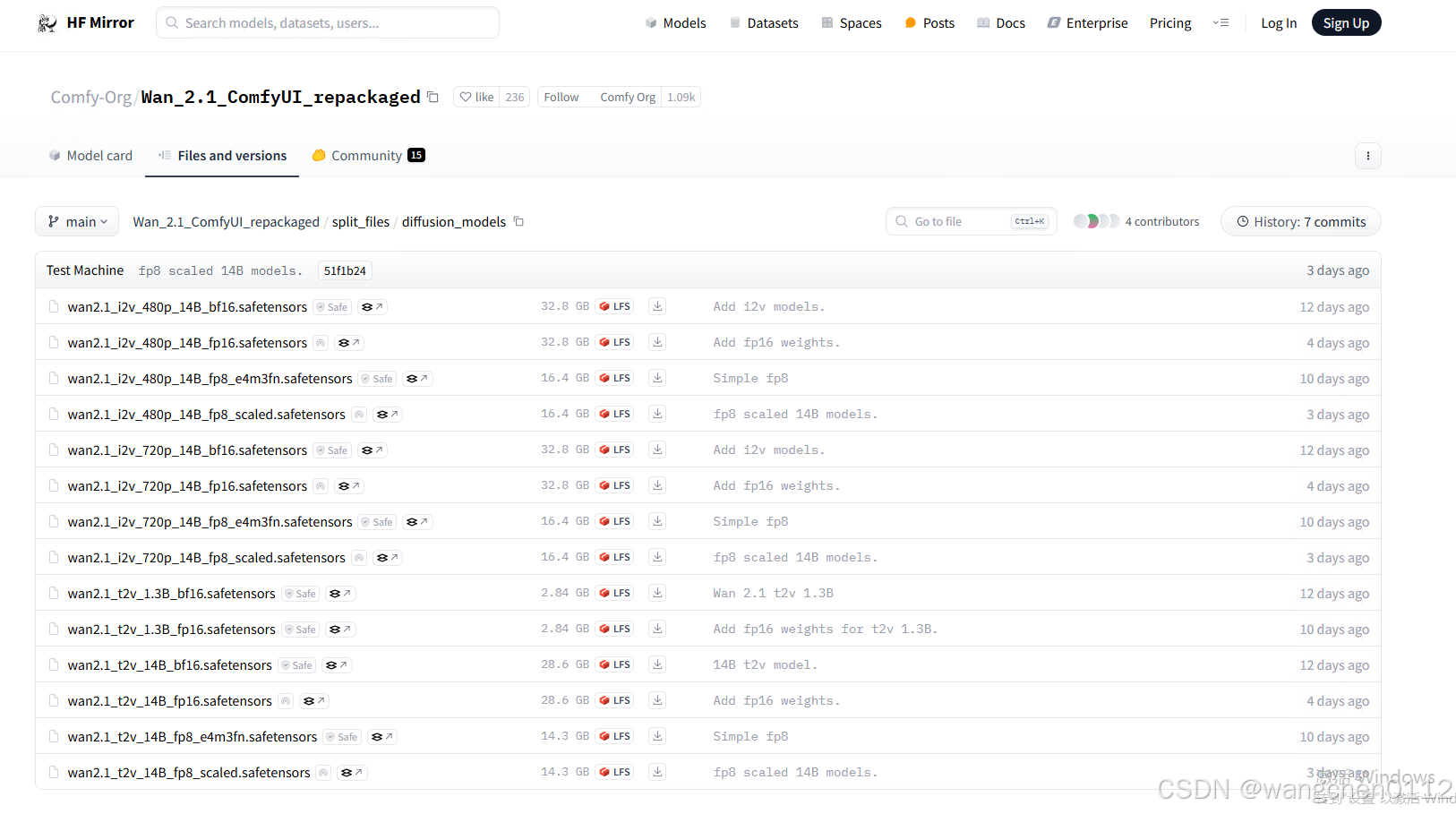
说明:生成视频的质量等级 :fp16 > bf16 > fp8_scaled > fp8_e4m3fn
个人倾向与使用 fp16 版本而不是 bf16 版本,fp16版本会产生更好的结果。当然也要参考硬件环境,如果硬件资源不足则可以选择fp8版本
如果显卡是8G以内的,建议选择:1.3B_fp16 版本:(其他的占用比较大,个人也是选择此模型)
点击下载(下载小图标),浏览器开始下载文件:
下载完成后,将文件拷贝至 /models/diffusion_models/ 目录下:
4、下载文件转视频的工作流定义文件:
点击鼠标“右键”,选择另存为:
暂时存放在桌面:
桌面文件:
个人在整理习惯上,喜欢创建一个常用文件的文件夹,将常用的文件放入:

5、关闭ComfyUI客户端,重新打开,执行测试:
启动中,模型加载:
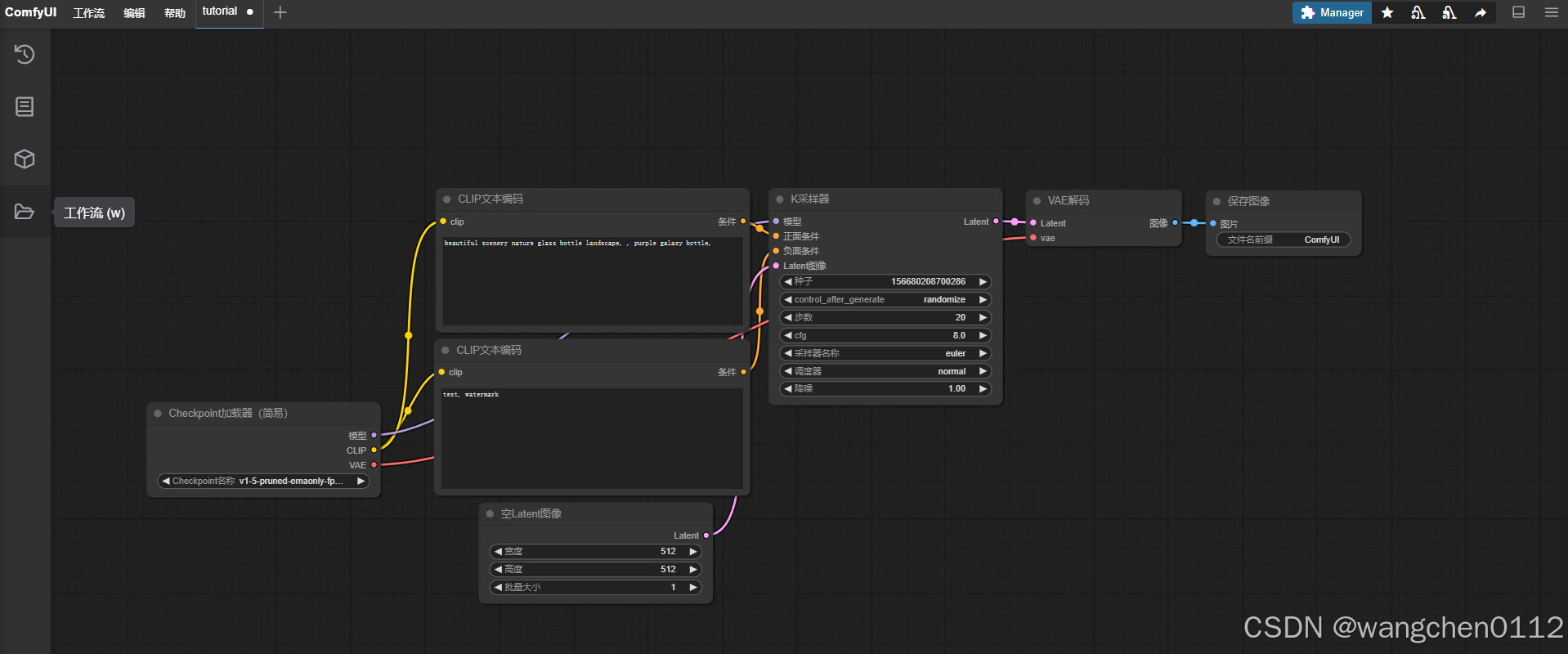
进入初始页面:
 将工作流文件拖拽到页面中:
将工作流文件拖拽到页面中:
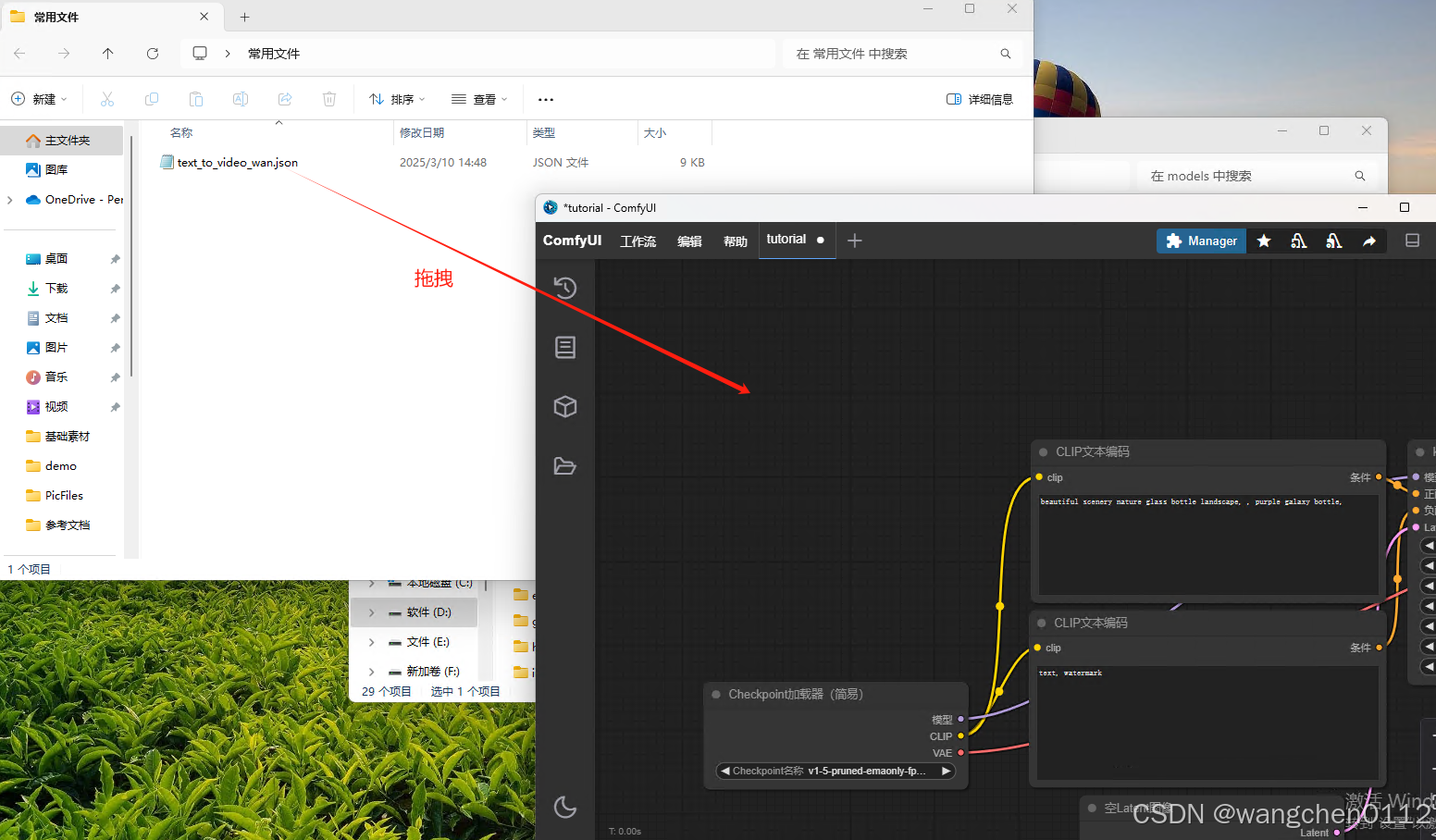
拖拽后效果:
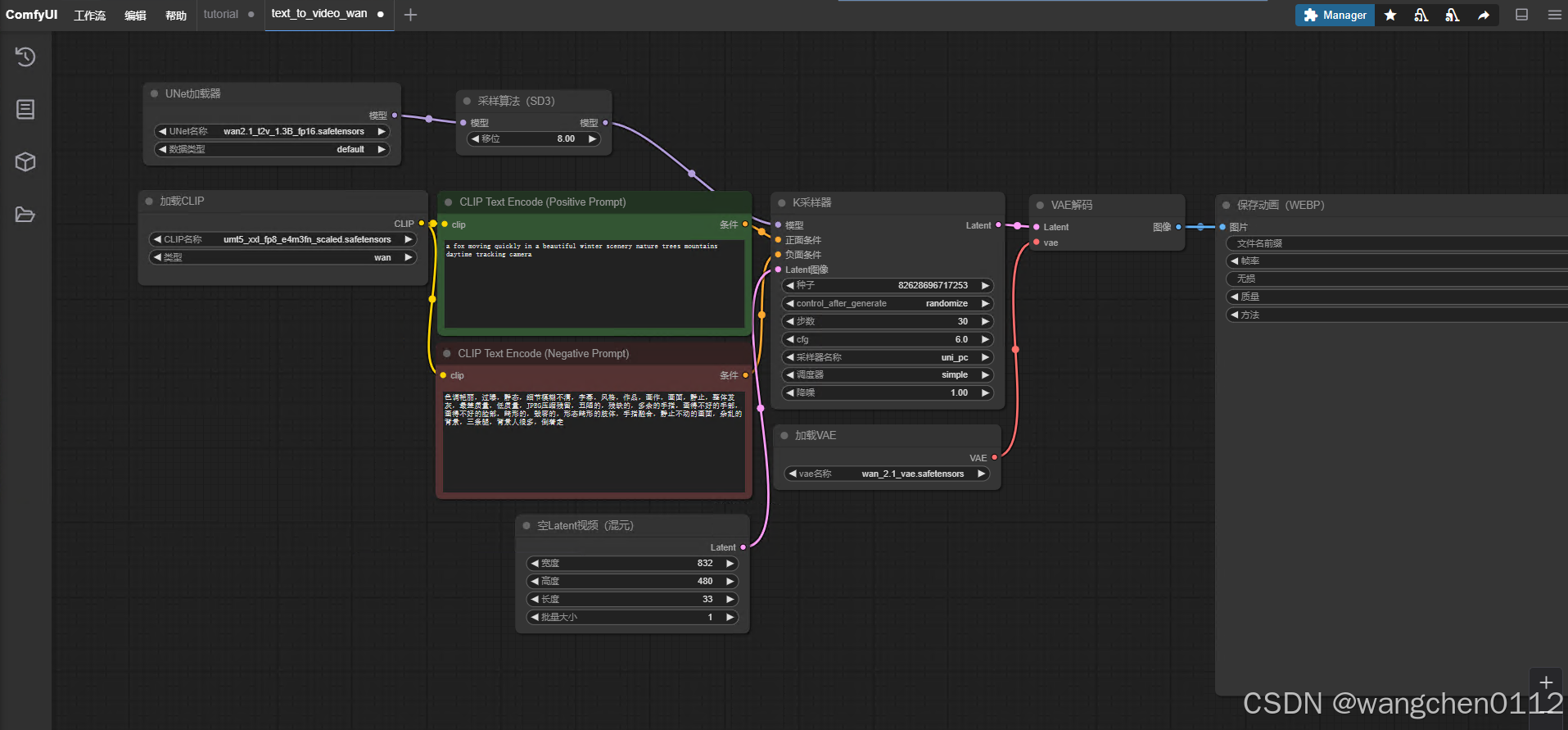
点击 CLIP,选择刚刚下载的fp8
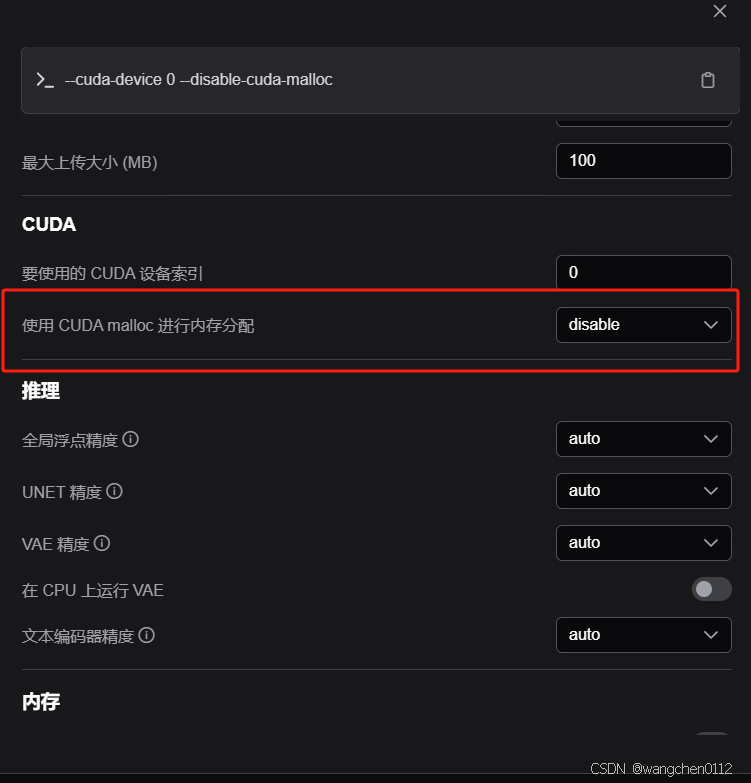
点击 设置 按钮:打开系统设置,将 CUDA--》CUDA malloc 设置为 disable【本人的TeslaP100 需要这样设置才可以运行】
显存:12G
性能:GPU 运算 100%
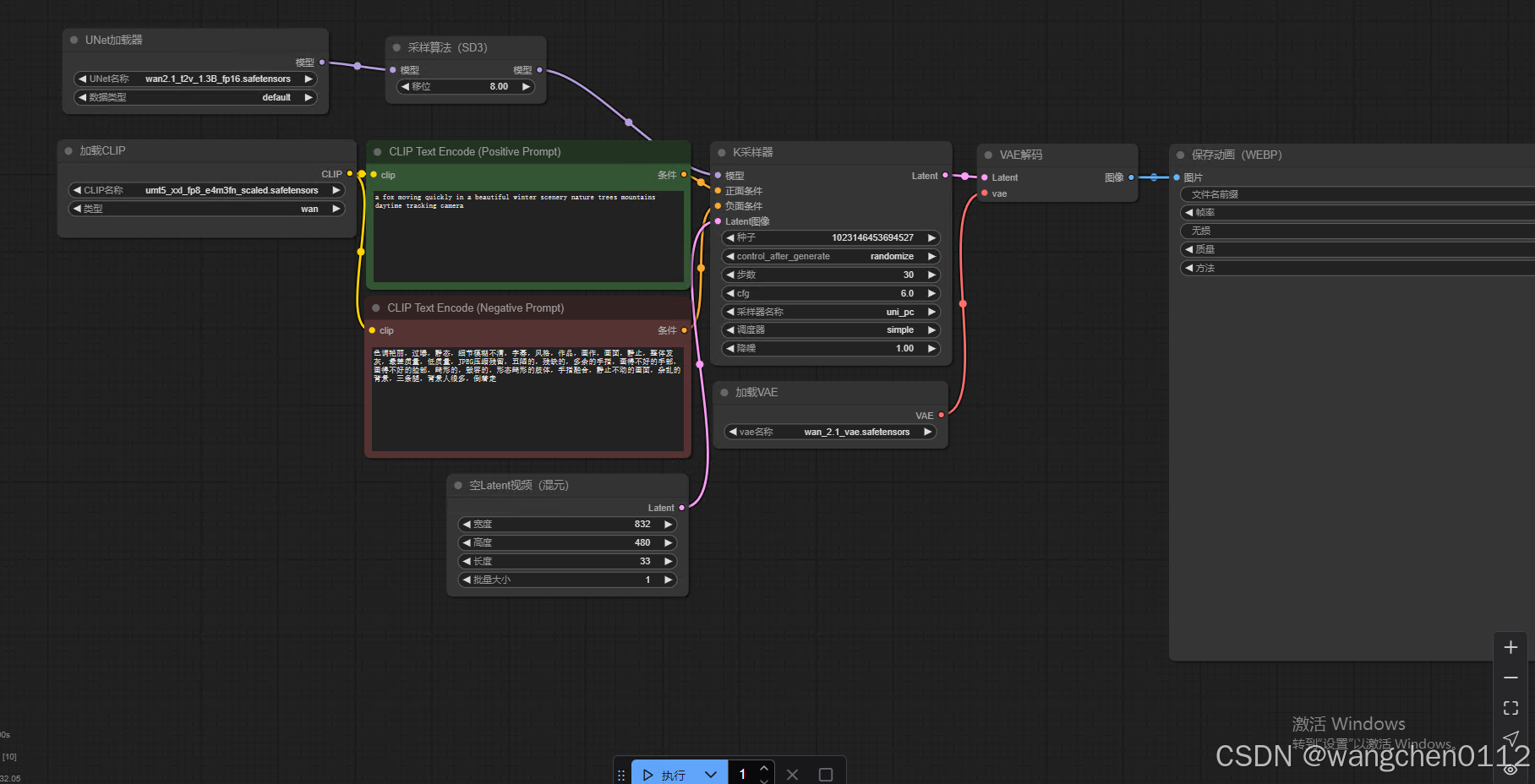
执行步骤展示:
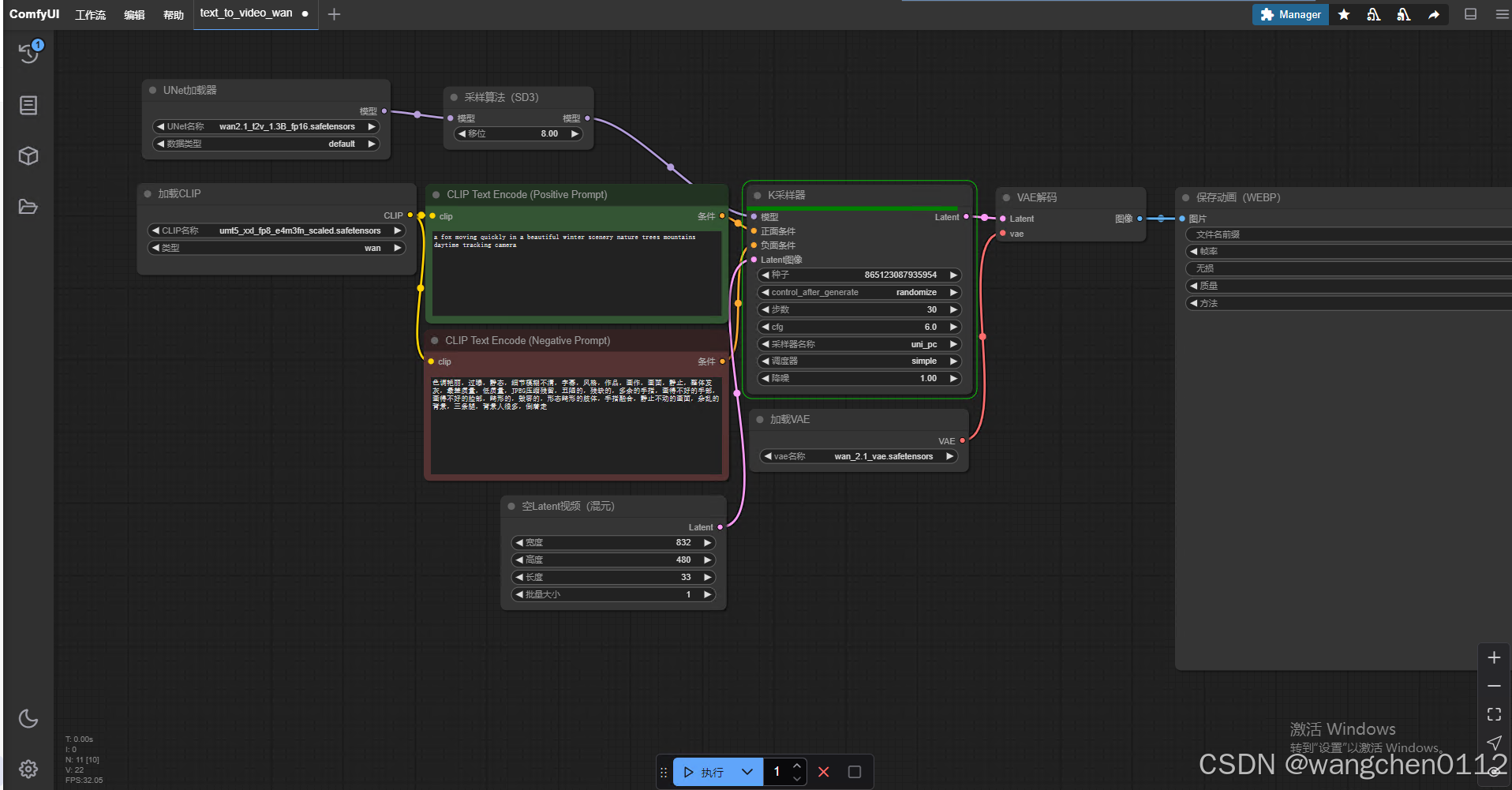
点击 执行 进行测试:(用默认提示词),生成视频 预览:



















 1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











