






目录
1. 安装环境
1.1 python环境
如果有 python3.10+ 环境可以跳过这一步 直接进入第2步 安装步骤点击查看
低于 3.10(cp310) 会导致 flash_attn 依赖无法正常安装, 这里用的 python3.12.9
1.2 cuda环境
需要安装和自己的显卡版本相匹配的包 显卡低于4060就别去搞了 训练5小时得到5秒钟的视频, 还不如直接用阿里提供在线网页版视频生成功能
打开cmd输入nvidia-smi
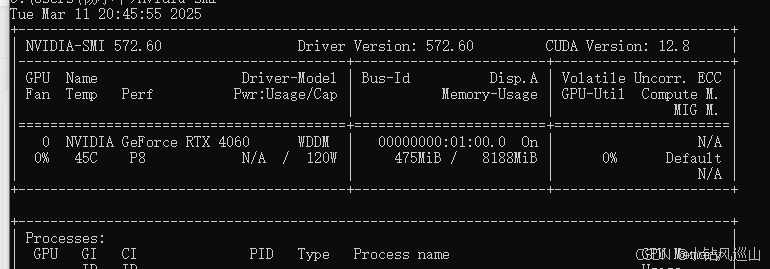
发现cuda版本支持到12.8 去cuda官网下载
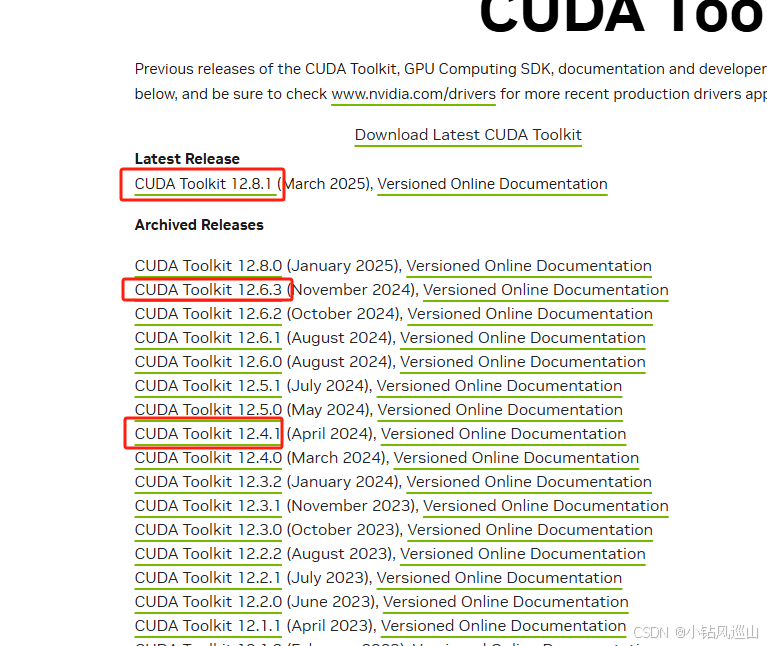
后来发现项目启动需要的flash_attn这个依赖与cuda编译好的现成的依赖只支持12.4,所以下载12.8就行不通了
所以下载12.4的cuda依赖点击下载 或者使用csdn下载速度快些
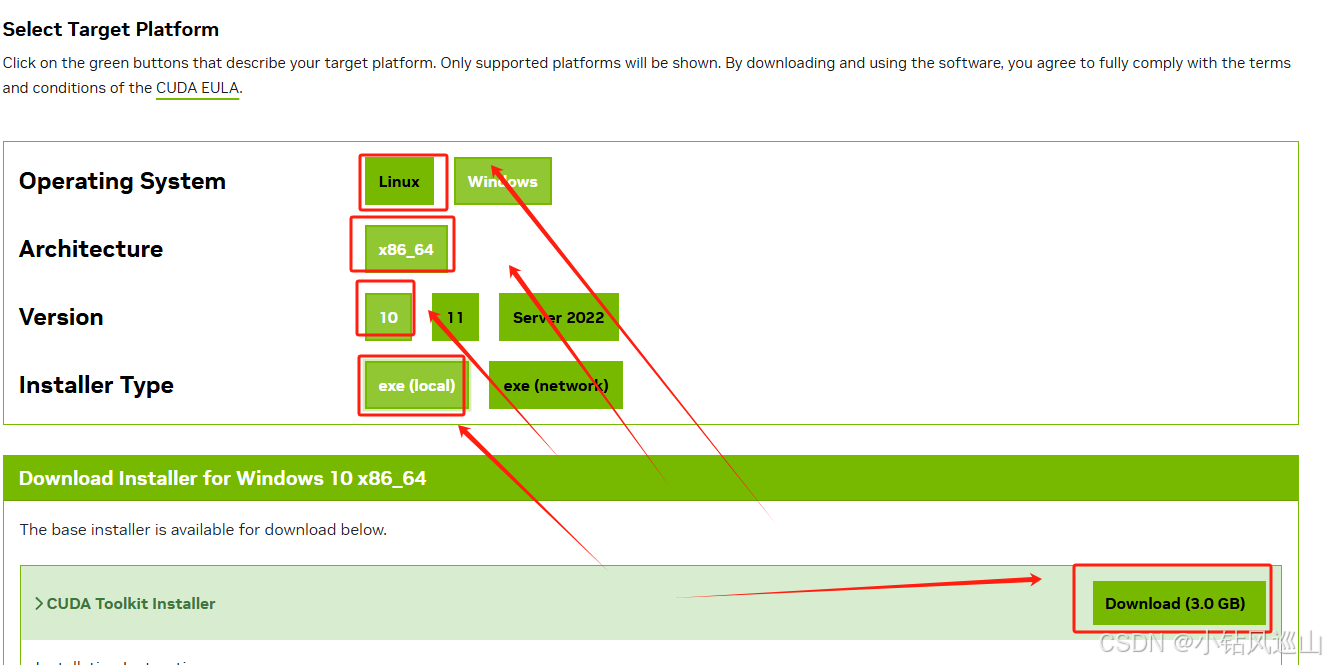
下载之后设置安装 第一次选择的是临时目录 安装之后会自动删除 第二次选择的是安装,选择自定义安装,选择所有,设置安装目录,然后下一步一直点最后安装完成,验证安装是否正常
选择安装的时候提示 visual studio 不支持(如果没有出现就跳过下面的c++工具安装),需要单独安装visual studio找到支持当前cuda的版本 这里安装的cuda12.4支持visual studio 2022
点击进入官网选择下载visual studio工具
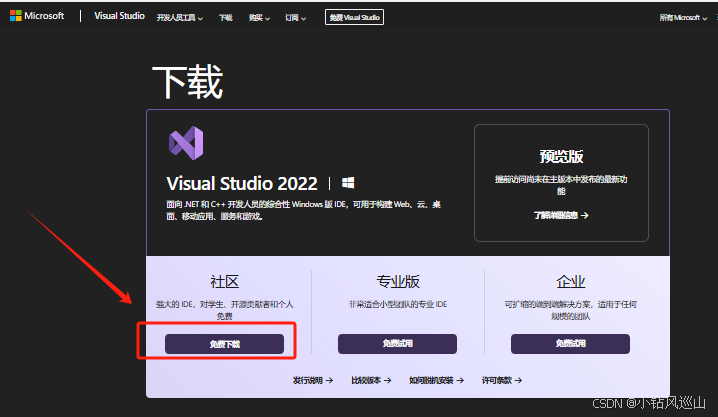
下载完成后打开
下载完成后打开安装c++的桌面开发工具

然后安装完成后关闭,继续回到cuda的安装,这个时候就发现 visual studio 已经支持,点击下一步继续安装cuda最后安装完成,关闭
打开cmd控制台 输入
nvcc --version
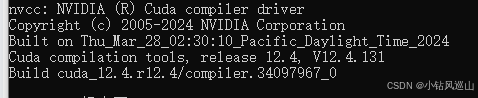
如果没有提示 需要主动设置环境变量
2. 下载万相2.1源码
解压后得到文件
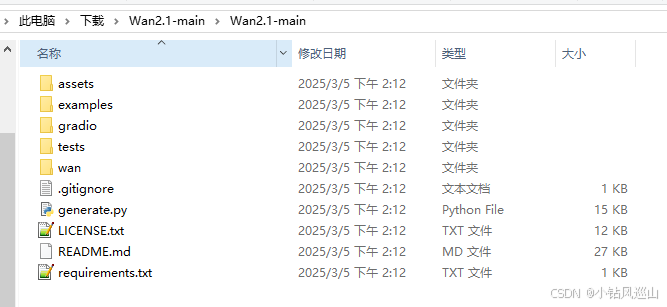
其中 requirements.txt 表示依赖文件 generate.py是环境搭建好了之后的启动脚本
3. 创建虚拟环境下载依赖
3.1 启动虚拟环境
# 在当前目录中创建python虚拟环境
python -m venv venv
# 启动虚拟环境
venv\Scripts\activate3.2 下载万相2.1的依赖
万相2.1的所有依赖在 requirements.txt 中,直接使用pip下载 速度较慢 可以使用国内的源下载
注意 numpy>=1.23.5,<2 这里用1.26.4
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple numpy==1.26.4
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple torch>=2.4.0
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision>=0.19.0
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python>=4.9.0.80
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple diffusers>=0.31.0
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple transformers>=4.49.0
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple tokenizers>=0.20.3
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple accelerate>=1.1.1
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple tqdm
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple imageio
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple easydict
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple ftfy
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple dashscope
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple imageio-ffmpeg
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple gradio>=5.0.0
pip3 install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple flash_attn其中的依赖 flash_attn 安装失败
官方发布的最新版是2.7.4且只有Linux版本,不支持windiws,在github中有大佬编译好的windows版本的flash_attn
需要手动到第三方找到符合自己系统的版本(速度较慢,科学上网)
直接下载离线安装到python虚拟环境 或者在CSDN中点击下载
这里下载的是 (cp312表示python3.12版本 主要和自己的版本对应上否则安装flash_attn会失败)
flash_attn-2.7.4.post1+cu124torch2.6.0cxx11abiFALSE-cp312-cp312-win_amd64.whl
对应的cuda124和torch2.6.0 上面提到需要cuda版本和flash_attn进行兼容,flash_attn 对应的 cuda支持到12.4
下载完成之后离线安装
pip install D:/data/flash_attn-2.7.4.post1+cu124torch2.6.0cxx11abiFALSE-cp312-cp312-win_amd64.whl
更换cuda版本
# 卸载
pip uninstall torch torchvision
# 根据上述的cu124和torch2.6.0更换版本 要下载很久 预计5个小时 睡一晚就好了
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu1244. 下载模型
4.1 离线下载
点击魔塔社区选择下载 需要下载整个目录
4.2 在线下载
在线下载自动下载整个目录
# 方式1 使用huggingface_hub下载 需要设置国内源否则下载不了
# pip install "huggingface_hub[cli]"
# huggingface-cli download Wan-AI/Wan2.1-T2V-1.3B --local-dir ./Wan2.1-T2V-1.3B
# 方式2 推荐 使用modelscope 下载
pip install --timeout 30 -i https://pypi.tuna.tsinghua.edu.cn/simple modelscope
modelscope download Wan-AI/Wan2.1-T2V-1.3B --local_dir ./Wan2.1-T2V-1.3B5. 官方示例
python D:\wan2.1\Wan2.1-main\generate.py --task t2v-1.3B --size 480*832 --ckpt_dir D:\wan2.1\python_tmp\Wan2.1-T2V-1.3B --prompt "两只拟人化的猫穿着舒适的拳击服,戴着明亮的手套,在聚光灯下激烈地打斗." --save_file D:\wan2.1\out.mp46. 运行效果截图
还在下载模型... 等下完了再截图演示..
python D:\wan2.1\Wan2.1-main\generate.py ^
--task t2v-1.3B ^
--size 480*832 ^
--frame_num 1 ^
--ckpt_dir D:\wan2.1\Wan2.1-T2V-1.3B ^
--prompt "在月光下,出现一只在夜间漫步行走的黑色猫咪" ^
--save_file D:\wan2.1\out.mp4参数解释
task 模型类型
size 输出文件的尺寸
ckpt_dir 模型的根目录
prompt 转化为视频的内容说明
save_file 输出文件名称
frame_num 帧,为了方便 这里只用了1帧 相当于是图片
如果当前电脑的请求压力比较大,可以使用一些请求参数降低当前服务的请求压力,比如降低当前服务使用的内存参数大小
请求的示例参数如下 (注意 ^ 表示换行拼接,用在windows的环境中,linux中不适用当前请求参数)
请求的示例如下(这里只写了14B的模型代码示例,没有演示):
:: 如果下载的是14B的模型,使用14B的模型完成文字转图片示例
python D:\wan2.1\Wan2.1-main\generate.py ^
--task t2i-14B ^
--size 1024*1024 ^
--ckpt_dir E:\models\Wan2.1-T2V-14B ^
--offload_model True
--t5_cpu ^
--sample_shift 8 ^
--sample_guide_scale 6 ^
--prompt "一只猫咪" ^
--save_file D:\wan2.1\out.jpg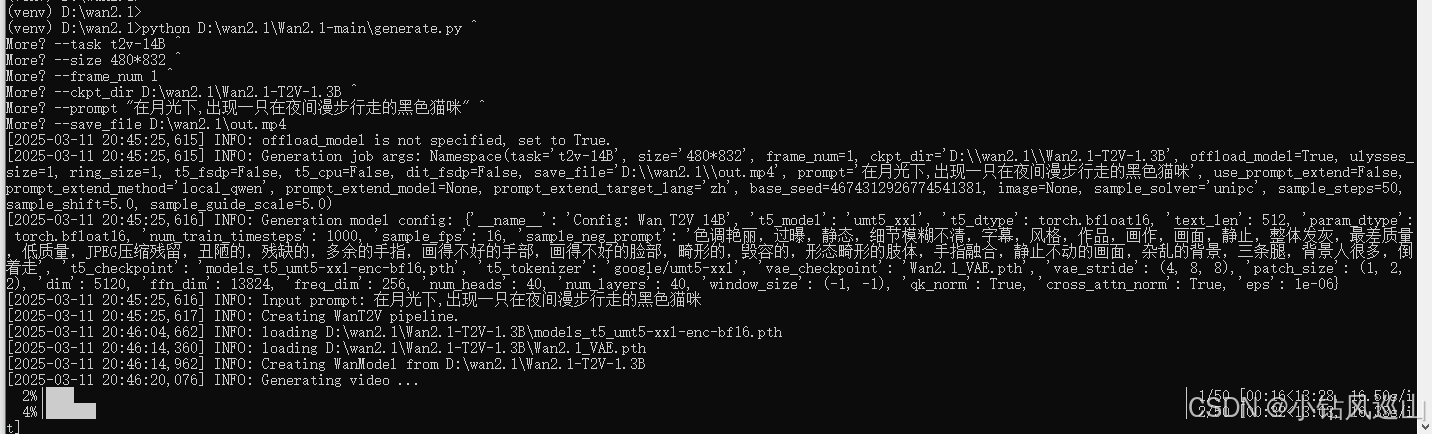
这里设置的frame_num是1,所以出图较快,等十来分钟过后就出来了
接下来见证使用1.3B模型在4060跑图的奇迹时刻(<1帧视频>在月光下,出现一只在夜间漫步行走的黑色猫咪)
!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!

感觉有点奇怪

总结是使用的文字描述不够完美 这里在换一次文字
一位身着白色水手服的青春女学生,黑色直发齐刘海,面容清秀,红润的嘴唇。站在校园楼梯间,阳光透过窗户斜射进来,在她脸上和白色衣服上形成温暖的光斑,背景是模糊的楼梯和栏杆。她轻轻眨动眼睛,嘴角缓缓上扬形成浅浅的微笑,随后低头看向地面,手指不经意地轻抚过垂落的发丝,将它们别到耳后,又将双手轻轻放入校服口袋,微微侧头望向远方,眼神中流露出些许思考和憧憬的神情。镜头采用近景拍摄,柔和地捕捉她细微的表情变化和动作,随后缓缓平移至侧面,展现她站立的优雅轮廓。整个场景充满宁静与温暖的氛围,洋溢着青春的气息,日系青春电影风格,柔和复古的色调,如同胶片相机般带有淡淡的怀旧感


经过实测,正常跑5秒视频 4060显卡消耗时间 6个小时20分钟




















 1938
1938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











