









解压拿到
图片一张,
图片尾看到有压缩包,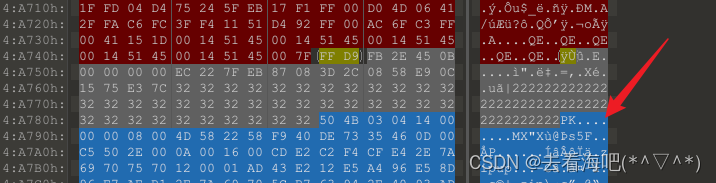
将数据拿出来,这个压缩包里面的所有东西都被加密了,并且看到提示说有个外卖被吃掉了一半,看到这里有很多用户的外卖,应该是用户1的被吃了,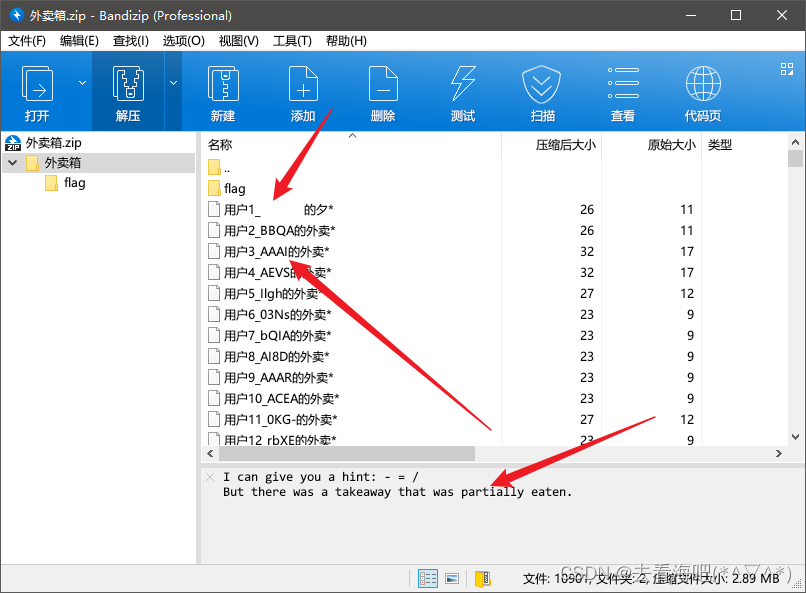
看到最后一个用户的文件名有两个“=”符号,再结合压缩包提示“- ”,“=”,“ /”这三个符号和文件名,猜测可能是要把全部文件名用户序号合在一起,应该是base64转文件,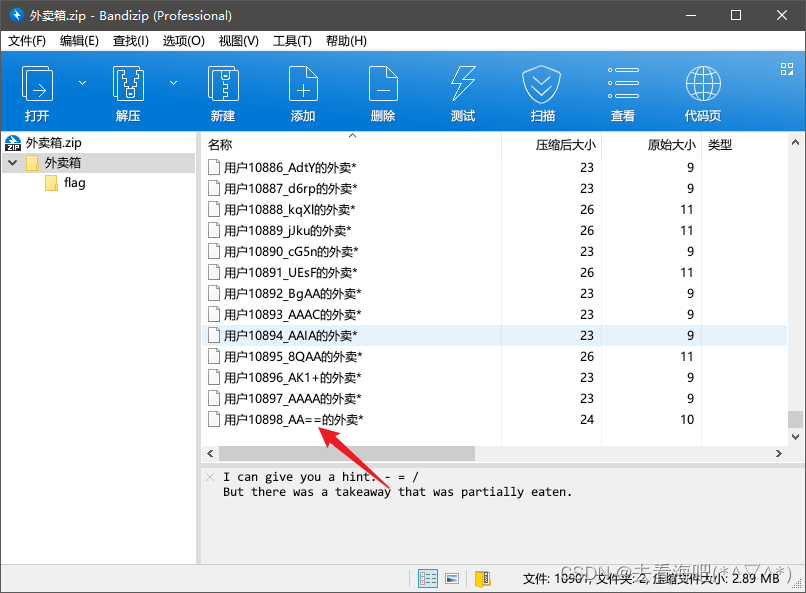
用下面的代码提取压缩包中所有的文件名,
import zipfile
def extract_filenames(zip_file_path):
filenames = []
with zipfile.ZipFile(zip_file_path, 'r') as zip_ref:
for file_info in zip_ref.infolist():
filenames.append(file_info.filename)
return filenames
# 指定压缩包的路径
zip_file_path = 'your.zip'
# 提取文件名
filenames = extract_filenames(zip_file_path)
# 打印文件名
for filename in filenames:
print(filename)将这几个删掉, 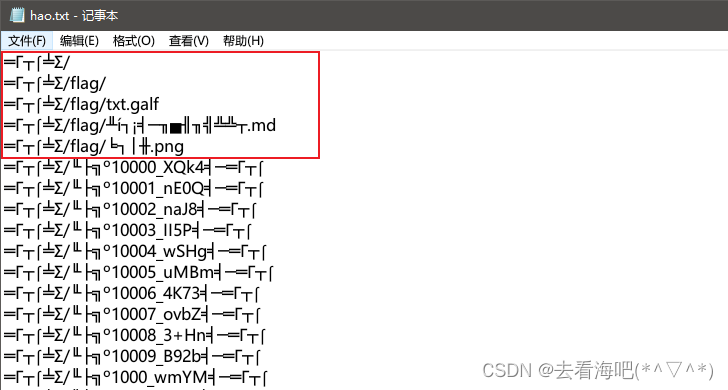
然后把剩下的没用的删掉,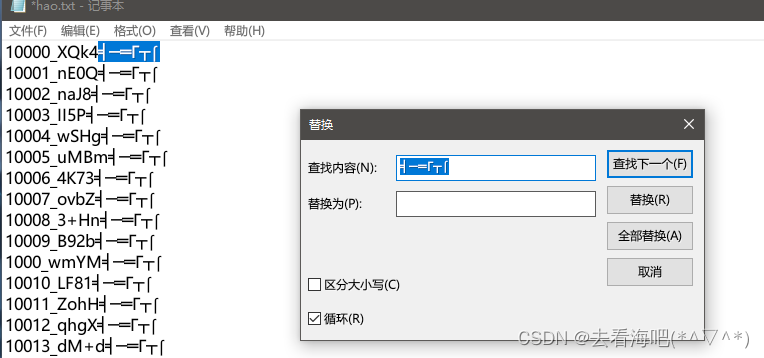
再按照数字大小排列并且删除序号和“_”符号,
def extract_number(filename):
# 从文件名中提取数字部分
parts = filename.split('_')
if len(parts) > 1:
try:
return int(parts[-2]) # 假设数字位于倒数第二个部分
except ValueError:
pass
return 0 # 如果无法提取数字,默认为0
def sort_filenames_by_number(file_list):
# 使用自定义的排序键提取数字并进行比较
sorted_files = sorted(file_list, key=extract_number)
return sorted_files
def merge_filenames(file_list):
# 合并文件名并删除前缀序号和"_"
merged_names = [filename.split('_', 1)[-1].replace('_', '') for filename in file_list]
return merged_names
# 指定存储文件名的文本文件路径
file_path = 'your.txt'
# 从文本文件中读取名字列表
with open(file_path, 'r') as file:
file_list = [line.strip() for line in file.readlines()]
# 按照数字大小排序文件名列表
sorted_files = sort_filenames_by_number(file_list)
# 合并文件名并删除前缀序号和"_"
merged_names = merge_filenames(sorted_files)
# 删除所有换行符
merged_names = [name.replace('\n', '') for name in merged_names]
# 打印最终结果
for name in merged_names:
print(name)这都是我叫AI写的,但这个脚本实际并没有删除掉换行符将剩下的内容合在一起,只能自己找在线工具删掉换行符了,不过也可以用cyber去处理,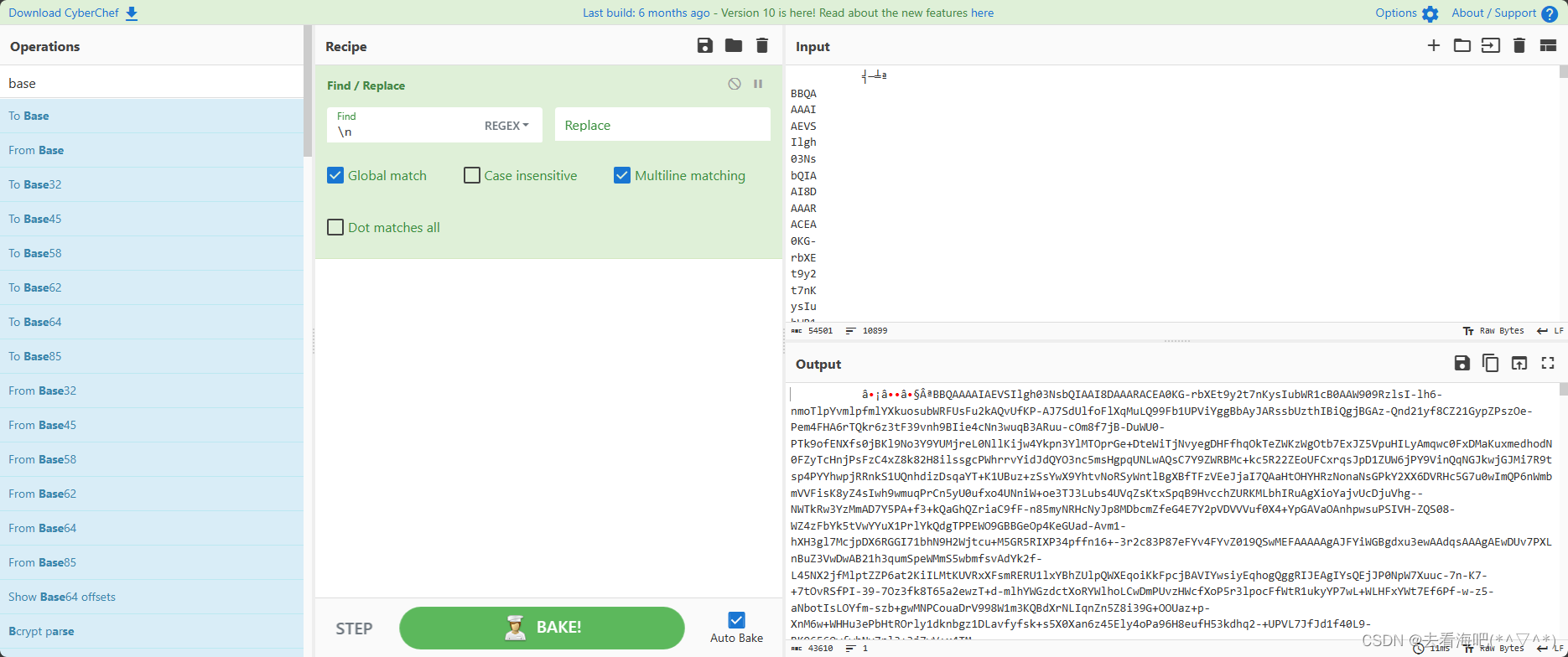
接着来,考虑到base64并没有“-”符号,结合提示,应该是将“-”换成“/”符号, 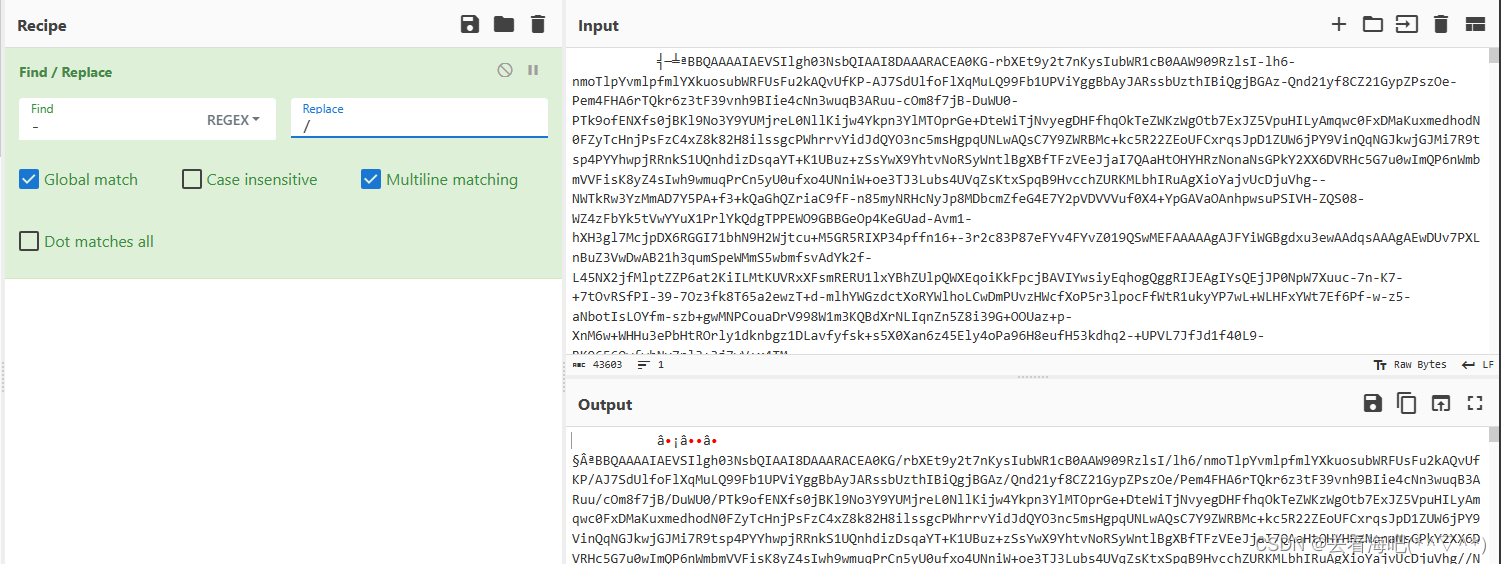
但是开头那个缺了,不知道是什么,后来我把这段base64先试着解码看看,看到跟之前压缩包有点相似的东西,都有“up”这两个字符,大胆猜测,将“外卖箱.zip”base64编码一下,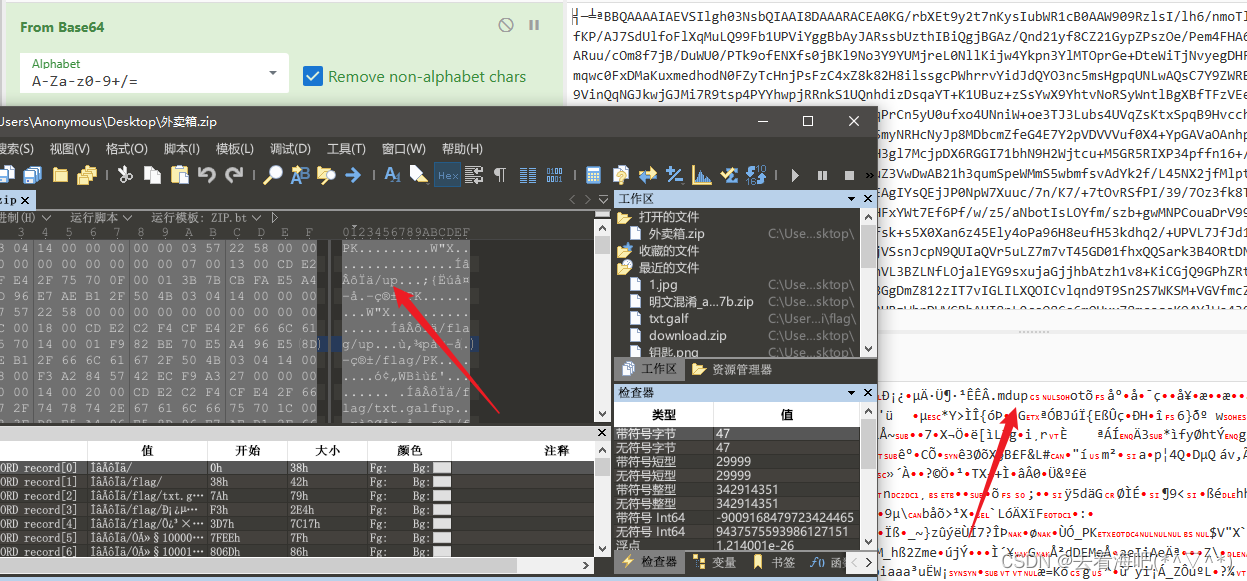
果然能对应上, 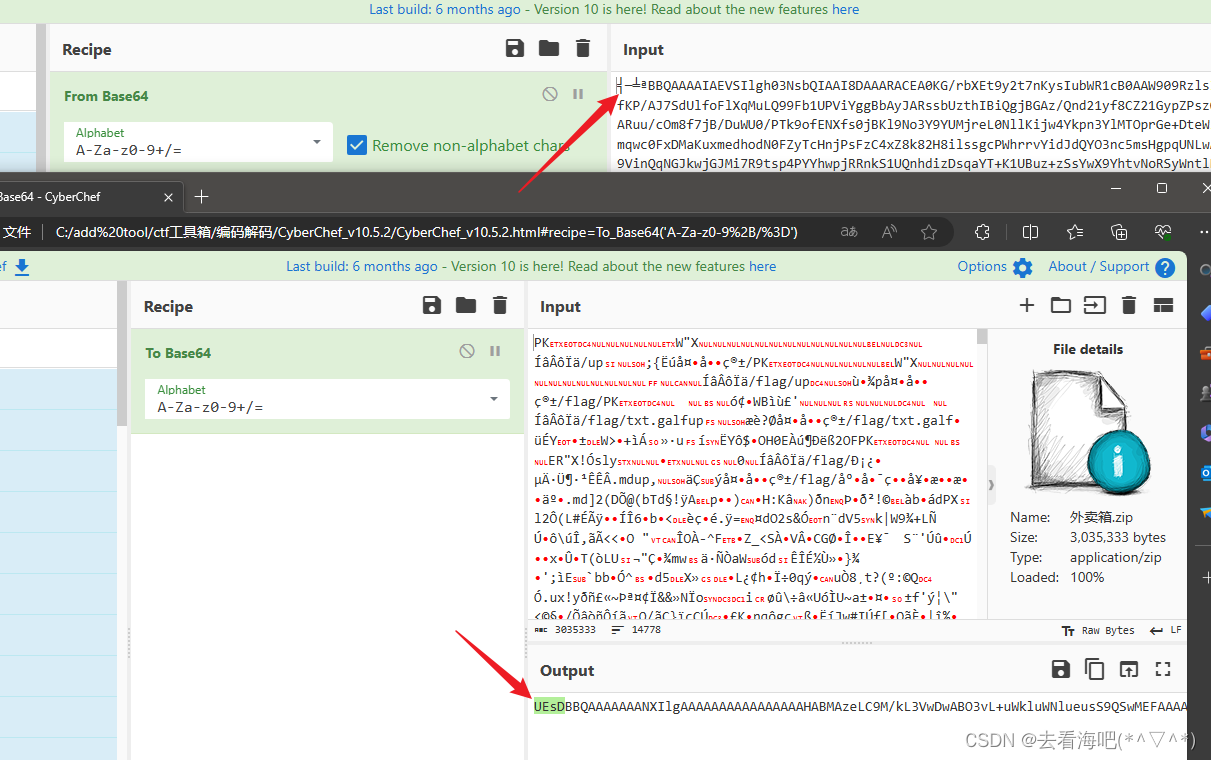
拿到这么个压缩包,跟加密压缩包里面的其中两个的循环冗余是一样的,
那就是明文攻击了,直接确定就可以保存了,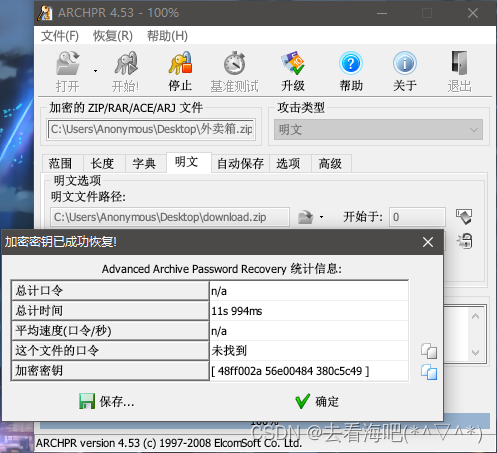
成功恢复压缩包,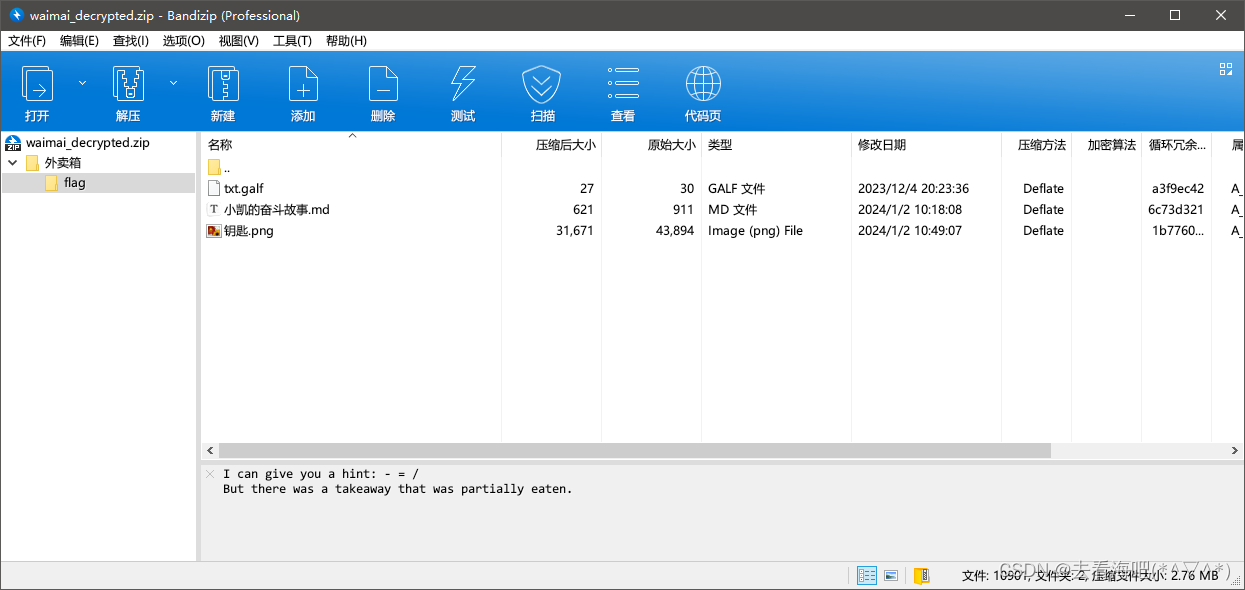
md文件,还给了个故事,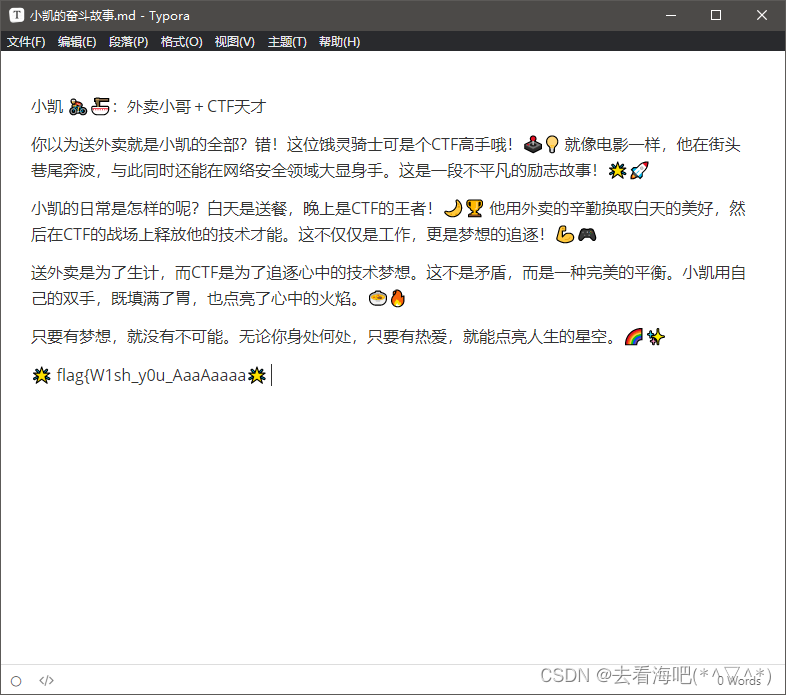
这个要逆序一下,合起来,flag{W1sh_y0u_AaaAaaaaaaaaaaa_w0nderfu1_CTF_journe9}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









