







注:该篇文章为本人原创,由于本人学习有限,若有错误或者笔误或者有问题,欢迎大家进行批评指正,谢谢。当然在使用爬虫前,请阅读下相关的法律法规,约束好自己的行为。第一次更新时间为2023.8.19,在2023.9.19当本人再次使用需要获取b站标题时,发现从仅更改“代码的演示”里面的url已经获取不到b站标题了,于是再次作了一定的修改,完成了标题的获取。
1.目的
在b站大学上,为了更好的写笔记,本人根据学到的Python(即Python入门(黑马)的学习笔记)与爬虫的知识(即Python爬虫的urlib的学习、Python爬虫的解析),使用xpath进行解析,获取到了b站视频的标题,具体步骤如下。若要直接阅读最终源代码,请直接看最后的一小部分。
2.代码的演示
本次将以获取尚硅谷Python爬虫教程小白零基础速通的视频标题为例进行演示。
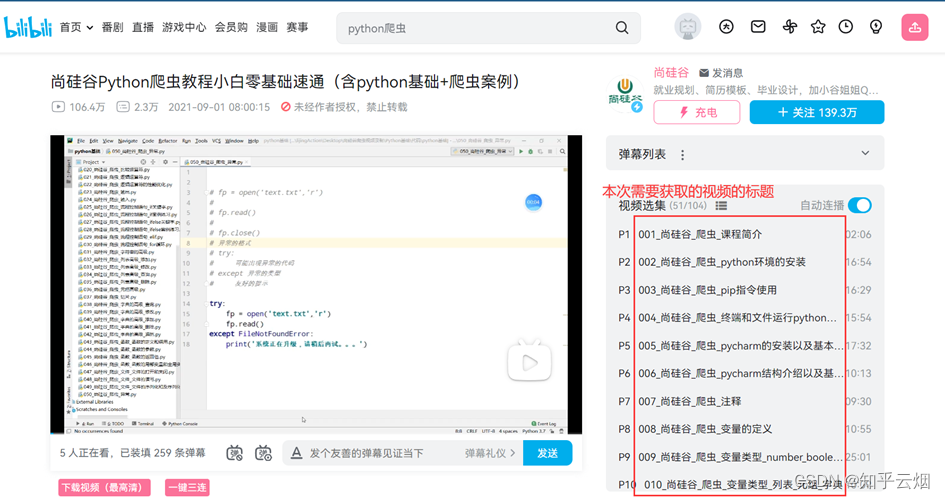
在PyCharm中创建文件“b站视频标题的获取(xpath).py”
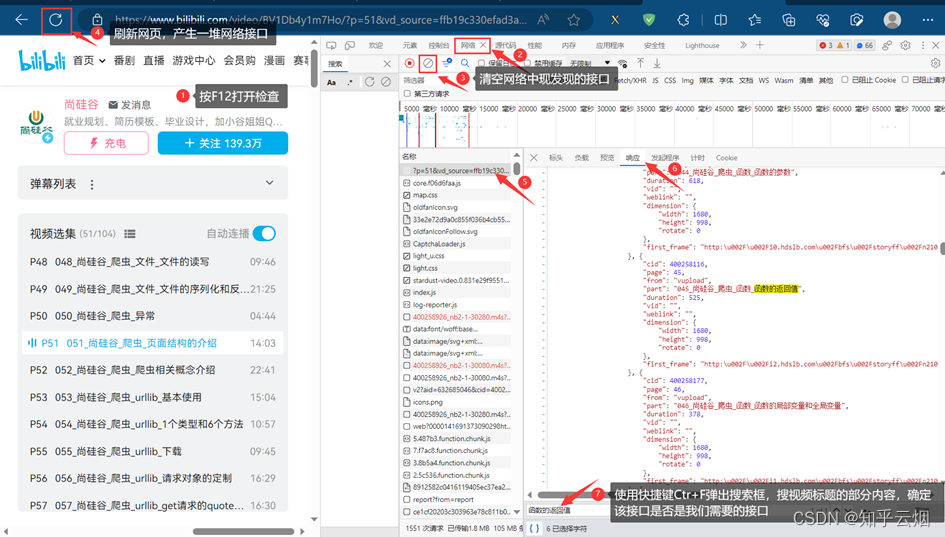
按F12打开检查,点击网络,清空网络中的接口,点击刷新,寻找含有视频标题的接口,将该接口的请求地址复制到PyCharm中。

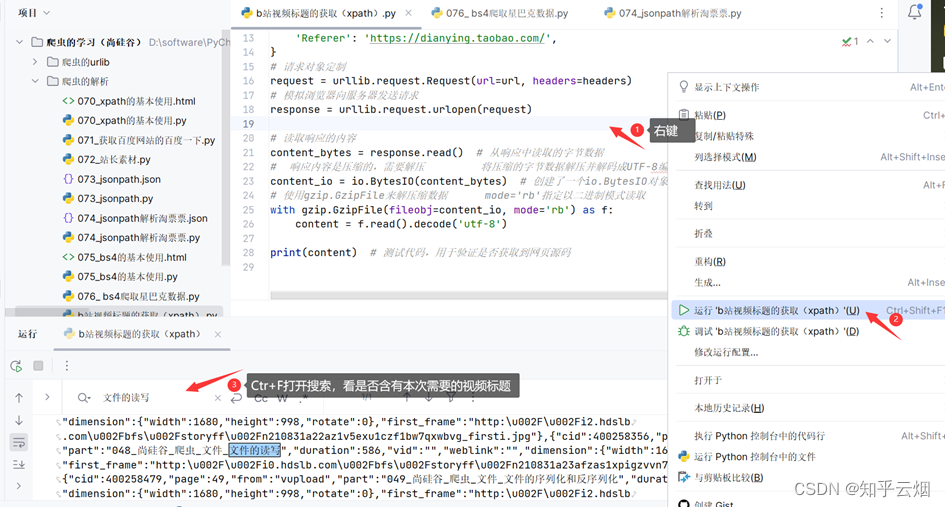
如下编程,先确定能获取到网页源码。
"""
b站视频标题的获取(xpath)
"""
import urllib.request
import gzip
import io
# 1.获取网页源码
# 请求地址
url = 'https://www.bilibili.com/video/BV1Db4y1m7Ho/?p=51&vd_source=ffb19c330efad3ae5d7d43710d936b1f'
# 请求头
headers = {
'Referer': 'https://dianying.taobao.com/',
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 读取响应的内容
content_bytes = response.read() # 从响应中读取的字节数据
# 响应内容是压缩的,需要解压 将压缩的字节数据解压并解码成UTF-8编码的字符串
content_io = io.BytesIO(content_bytes) # 创建了一个io.BytesIO对象,用于将字节数据包装成类似文件对象的形式
# 使用gzip.GzipFile来解压缩数据 mode='rb'指定以二进制模式读取
with gzip.GzipFile(fileobj=content_io, mode='rb') as f:
content = f.read().decode('utf-8')
print(content) # 测试代码,用于验证是否获取到网页源码
接着,使用快捷键Ctr+Alt+X打开xpath插件,然后如下图所示寻找到xpath路径,并复制到PyCharm中。
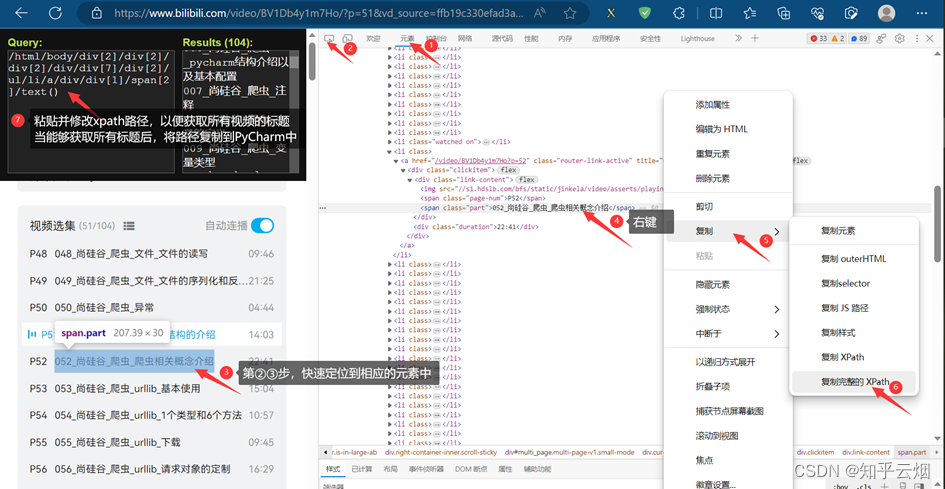
继续编程,发现按照该路径无法获取到内容。所以将获取到的网页源码保存为html文件,然后在html文件中不断使用搜索快捷键Ctr+F来协助我们找到xpath路径。
"""
b站视频标题的获取(xpath)
"""
import urllib.request
import gzip
import io
from lxml import etree
# 1.获取网页源码
# 请求地址
url = 'https://www.bilibili.com/video/BV1Db4y1m7Ho/?p=51&vd_source=ffb19c330efad3ae5d7d43710d936b1f'
# 请求头
headers = {
'Referer': 'https://dianying.taobao.com/',
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 读取响应的内容
content_bytes = response.read() # 从响应中读取的字节数据
# 响应内容是压缩的,需要解压 将压缩的字节数据解压并解码成UTF-8编码的字符串
content_io = io.BytesIO(content_bytes) # 创建了一个io.BytesIO对象,用于将字节数据包装成类似文件对象的形式
# 使用gzip.GzipFile来解压缩数据 mode='rb'指定以二进制模式读取
with gzip.GzipFile(fileobj=content_io, mode='rb') as f:
content = f.read().decode('utf-8')
# print(content) # 测试代码,用于验证是否获取到网页源码
# 将网页源码保存到文件“b站视频标题的获取(xpath).html”中
with open('b站视频标题的获取(xpath).html', 'w', encoding='UTF-8') as fp:
fp.write(content)
# 2.获取视频标题
# 解析服务器响应的文件 etree.HTML
tree = etree.HTML(content)
# 获取想要的数据
# 失败路径,需要将网页源码导入html文件中,手动找 /html/body/div[2]/div[2]/div[2]/div/div[7]/div[2]/ul/li/a/div/div[1]/span[2]/text()
result = tree.xpath('/html/head[@itemprop="video"]/script[4]/text()')[0] # 由于tree.xpath返回的是列表,需要使用切片[0]将它取出来
print(result)
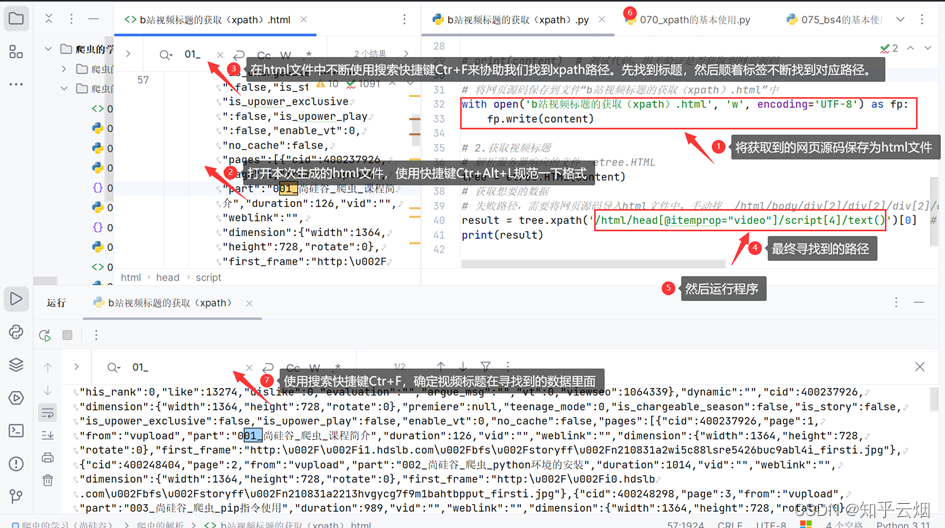
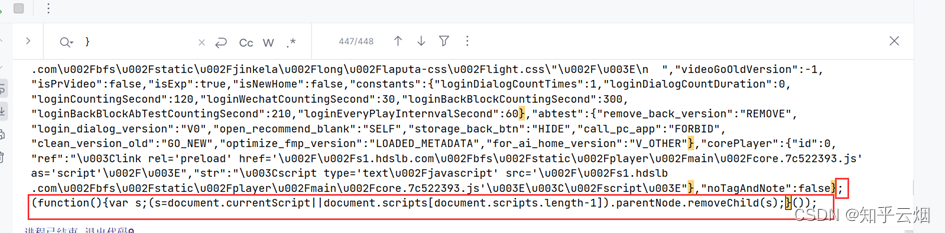
如图,发现将获取的内容就是json数据(本人使用的json解析网站为“https://c.runoob.com/front-end/53/”),只是多了一些东西,具体为“window.INITIAL_STATE=”、“;(function(){var s;(s=document.currentScript||document.scripts[document.scripts.length-1]).parentNode.removeChild(s);}());”。
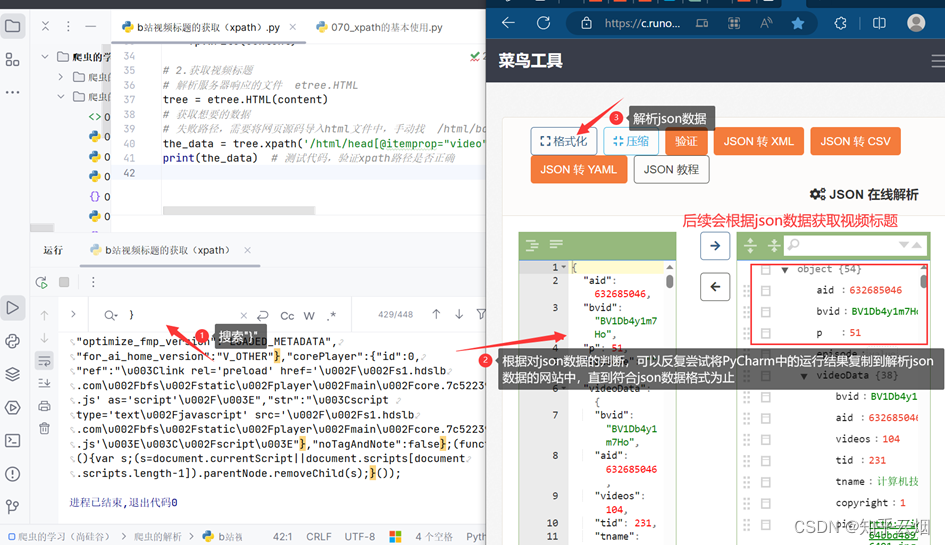
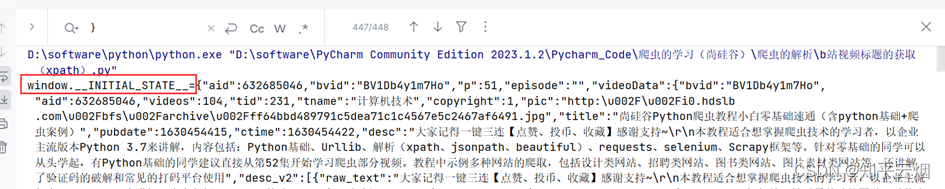
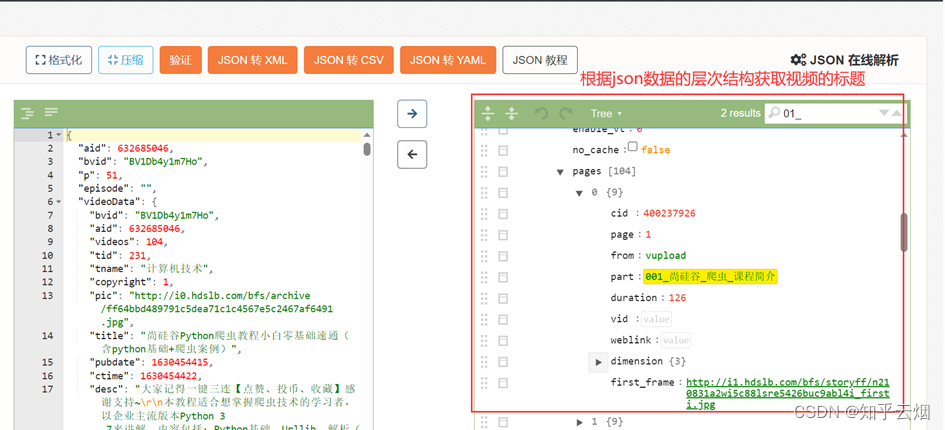
然后继续编程,将数据处理成json数据,然后根据json数据的层次获取到视频标题。
"""
b站视频标题的获取(xpath)
"""
import urllib.request
import gzip
import io
from lxml import etree
import json
# 1.获取网页源码
# 请求地址
url = 'https://www.bilibili.com/video/BV1Db4y1m7Ho/?p=51&vd_source=ffb19c330efad3ae5d7d43710d936b1f'
# 请求头
headers = {
'Referer': 'https://dianying.taobao.com/',
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 读取响应的内容
content_bytes = response.read() # 从响应中读取的字节数据
# 响应内容是压缩的,需要解压 将压缩的字节数据解压并解码成UTF-8编码的字符串
content_io = io.BytesIO(content_bytes) # 创建了一个io.BytesIO对象,用于将字节数据包装成类似文件对象的形式
# 使用gzip.GzipFile来解压缩数据 mode='rb'指定以二进制模式读取
with gzip.GzipFile(fileobj=content_io, mode='rb') as f:
content = f.read().decode('utf-8')
# print(content) # 测试代码,用于验证是否获取到网页源码
# # 将网页源码保存到文件“b站视频标题的获取(xpath).html”中
# with open('b站视频标题的获取(xpath).html', 'w', encoding='UTF-8') as fp:
# fp.write(content)
# 2.获取视频标题
# 解析服务器响应的文件 etree.HTML
tree = etree.HTML(content)
# 获取想要的数据
# 失败路径,需要将网页源码导入html文件中,手动找 /html/body/div[2]/div[2]/div[2]/div/div[7]/div[2]/ul/li/a/div/div[1]/span[2]/text()
the_data = tree.xpath('/html/head[@itemprop="video"]/script[4]/text()')[0] # 由于tree.xpath返回的是列表,需要使用切片[0]将它取出来
# print(the_data) # 测试代码,验证xpath路径是否正确
the_json_data = the_data.split('__=')[1].split(';(function')[0]
# print(the_json_data) # 测试代码,验证得到的json数据是否正确
# 将字符串json转换为python的字典
data_dict = json.loads(the_json_data)
# 根据json数据的层次结构获取视频的标题
the_temp_data = data_dict['videoData']['pages']
the_name_of_videos = [] # 用于存储视频的标题
for name in the_temp_data:
the_name_of_videos.append(name['part'])
# 打印b站视频的标题
for name in the_name_of_videos:
print(name)
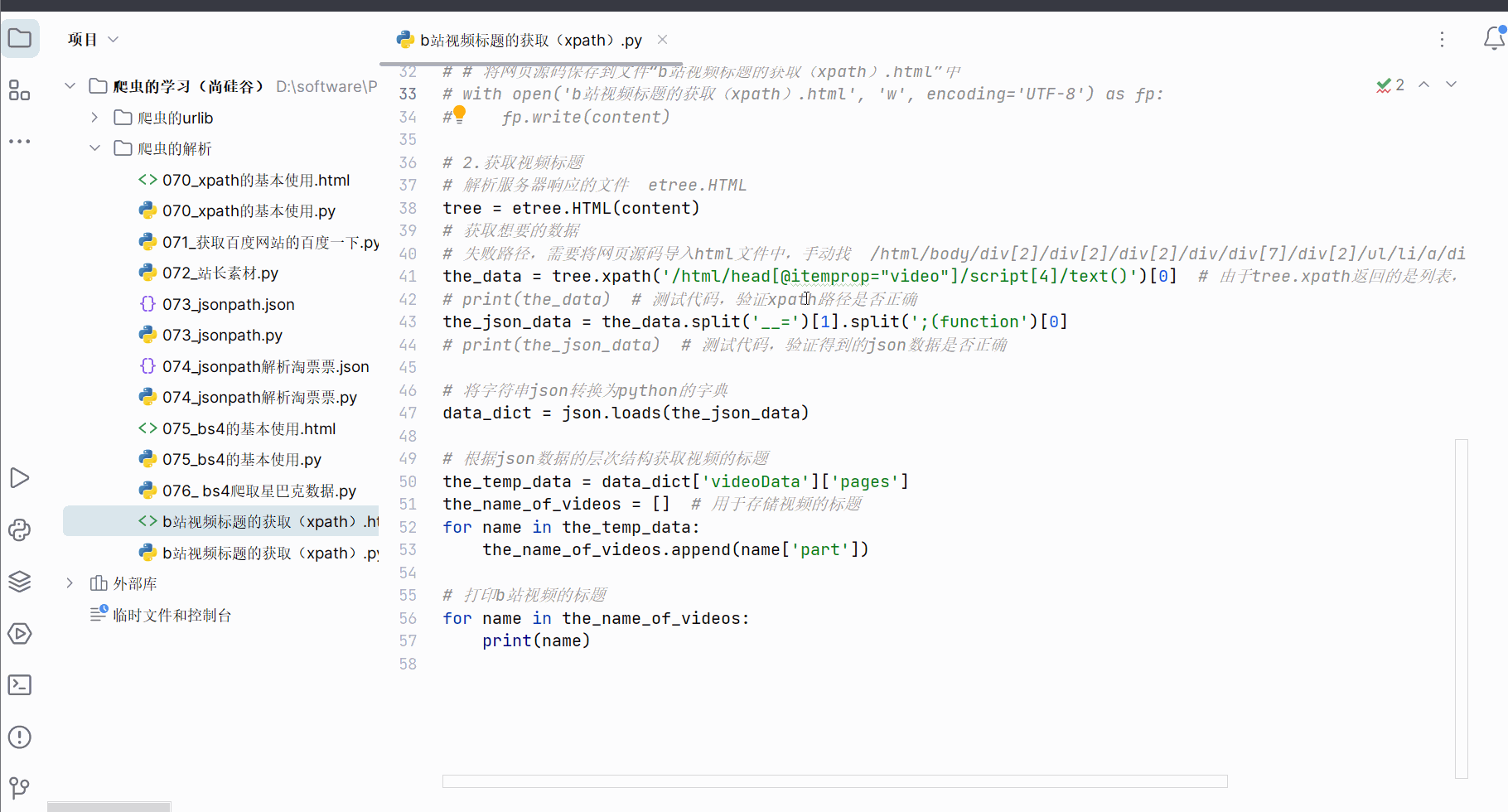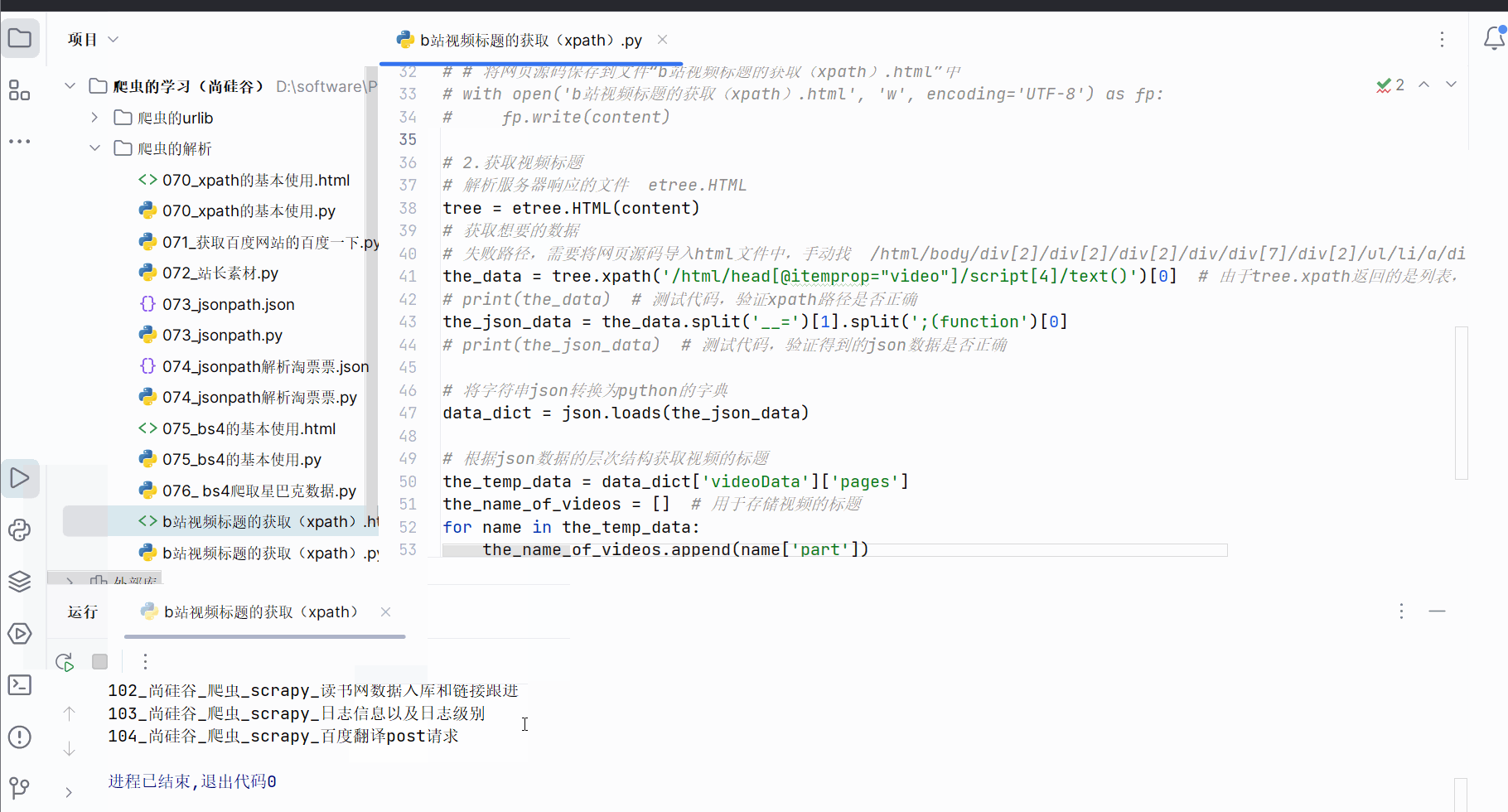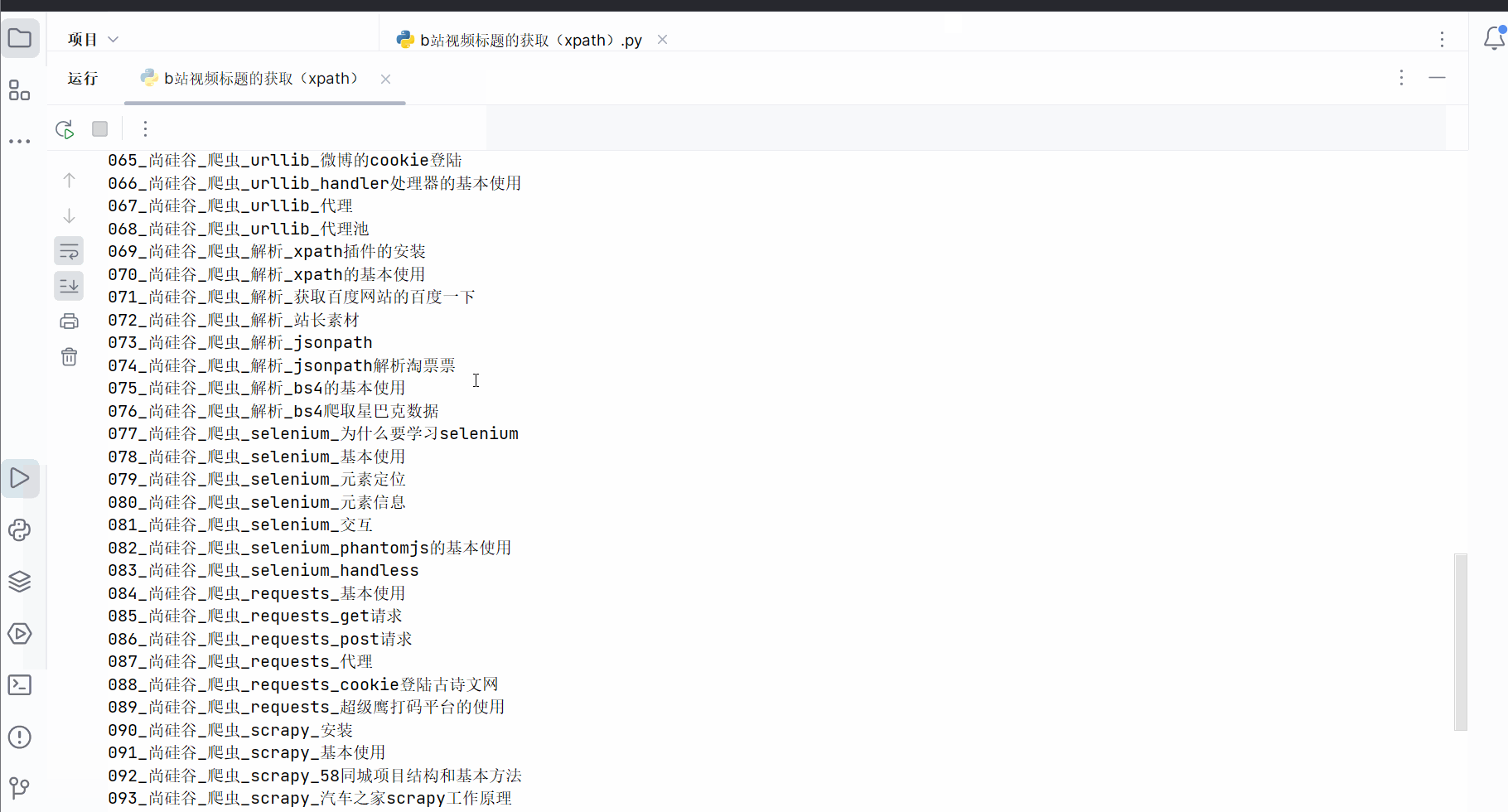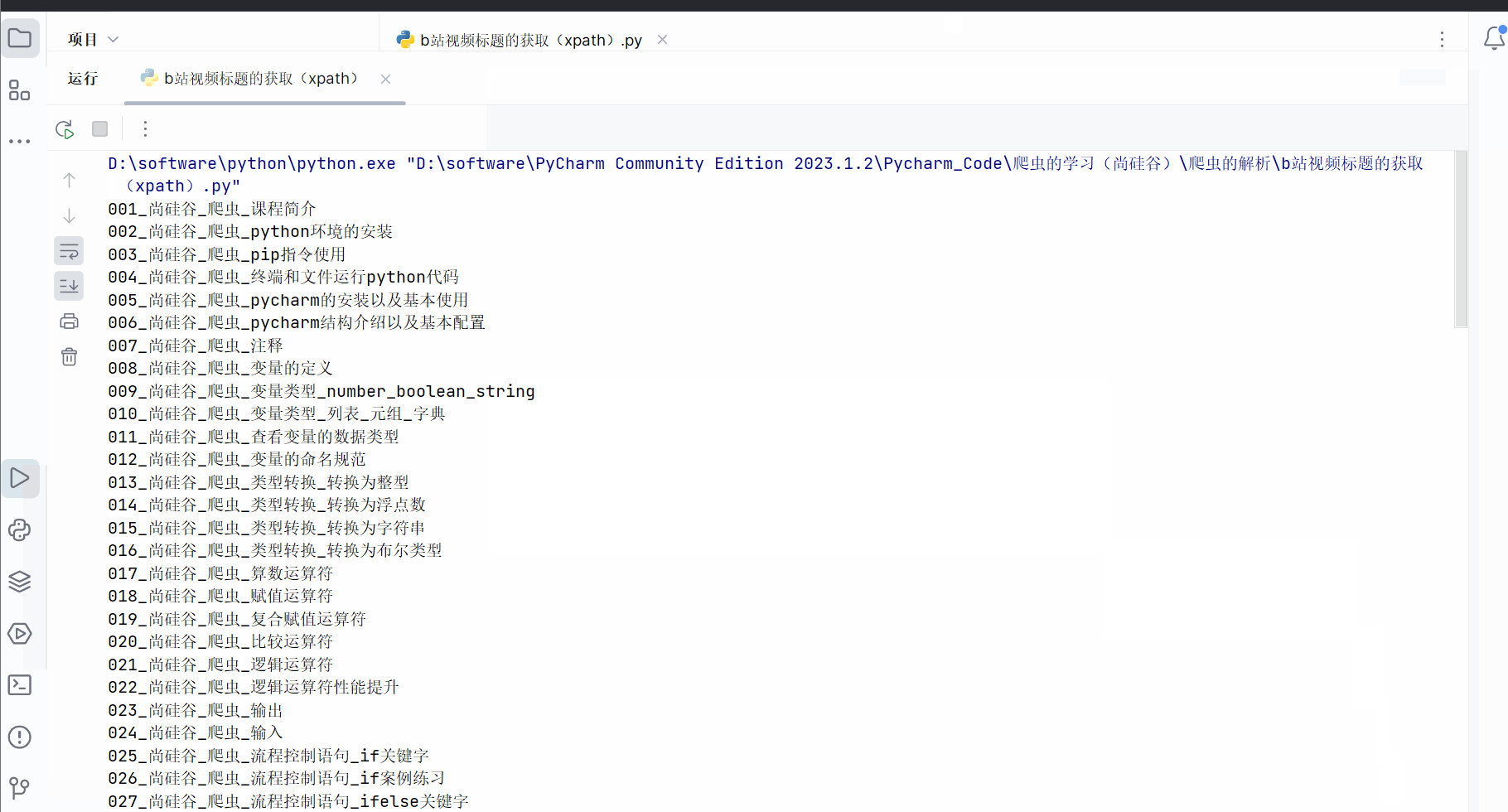
当然,json数据部分可使用jsonpath来解析,代码与运行结果如下。
"""
b站视频标题的获取(xpath)
"""
import urllib.request
import gzip
import io
from lxml import etree
import json
import jsonpath
# 1.获取网页源码
# 请求地址
url = 'https://www.bilibili.com/video/BV1Db4y1m7Ho/?p=51&vd_source=ffb19c330efad3ae5d7d43710d936b1f'
# 请求头
headers = {
'Referer': 'https://dianying.taobao.com/',
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 读取响应的内容
content_bytes = response.read() # 从响应中读取的字节数据
# 响应内容是压缩的,需要解压 将压缩的字节数据解压并解码成UTF-8编码的字符串
content_io = io.BytesIO(content_bytes) # 创建了一个io.BytesIO对象,用于将字节数据包装成类似文件对象的形式
# 使用gzip.GzipFile来解压缩数据 mode='rb'指定以二进制模式读取
with gzip.GzipFile(fileobj=content_io, mode='rb') as f:
content = f.read().decode('utf-8')
# print(content) # 测试代码,用于验证是否获取到网页源码
# # 将网页源码保存到文件“b站视频标题的获取(xpath).html”中
# with open('b站视频标题的获取(xpath).html', 'w', encoding='UTF-8') as fp:
# fp.write(content)
# 2.获取视频标题
#(1)处理变成json数据
# 解析服务器响应的文件 etree.HTML
tree = etree.HTML(content)
# 获取想要的数据
# 失败路径,需要将网页源码导入html文件中,手动找 /html/body/div[2]/div[2]/div[2]/div/div[7]/div[2]/ul/li/a/div/div[1]/span[2]/text()
the_data = tree.xpath('/html/head[@itemprop="video"]/script[4]/text()')[0] # 由于tree.xpath返回的是列表,需要使用切片[0]将它取出来
# print(the_data) # 测试代码,验证xpath路径是否正确
the_json_data = the_data.split('__=')[1].split(';(function')[0]
# print(the_json_data) # 测试代码,验证得到的json数据是否正确
# (2)处理json数据,得到视频的标题
# # 法1.使用切片
# # 将字符串json转换为python的字典
# data_dict = json.loads(the_json_data)
#
# # 根据json数据的层次结构获取视频的标题
# the_temp_data = data_dict['videoData']['pages']
# the_name_of_videos = [] # 用于存储视频的标题
# for name in the_temp_data:
# the_name_of_videos.append(name['part'])
# 法2.使用jsonpath解析
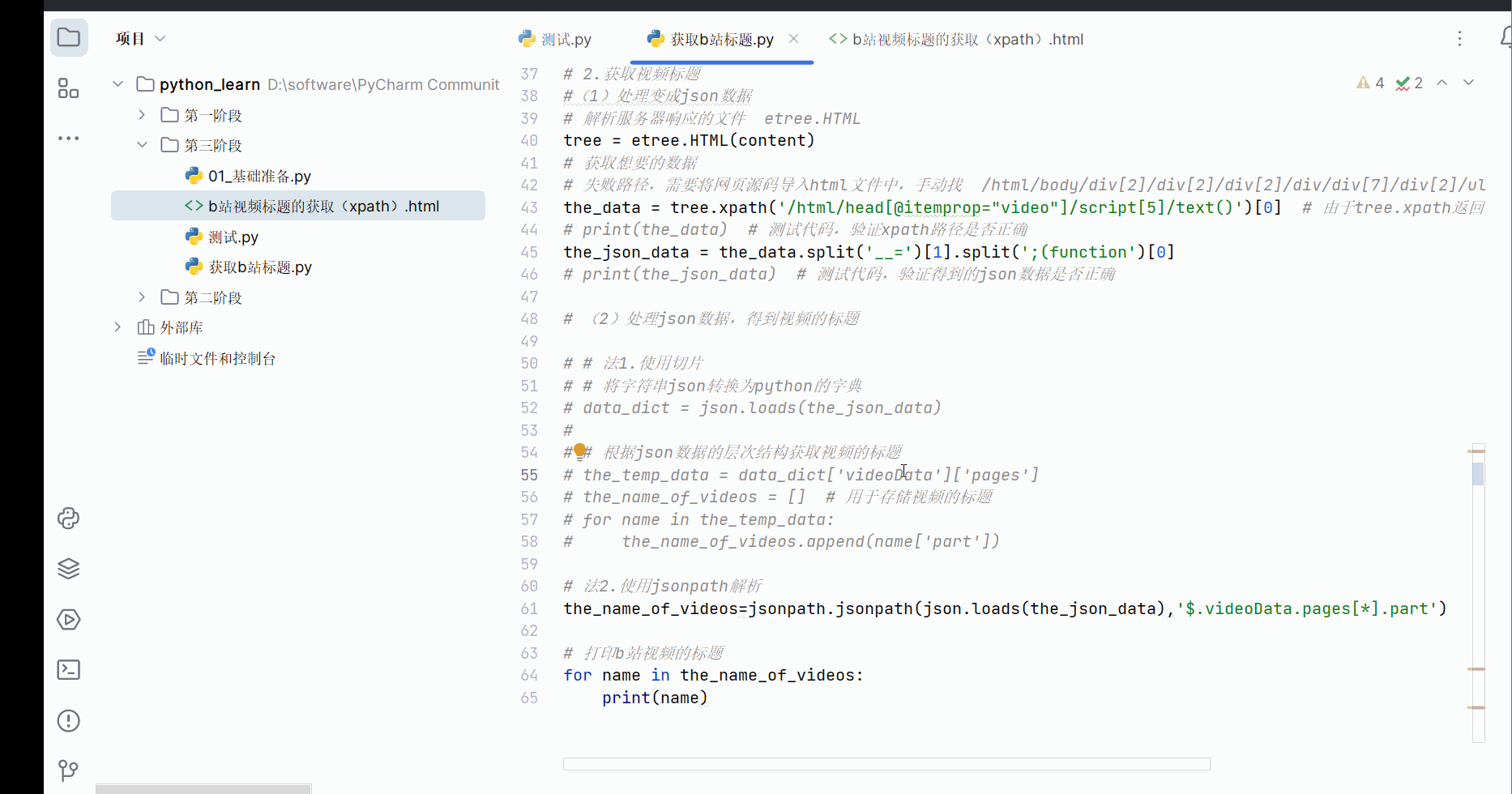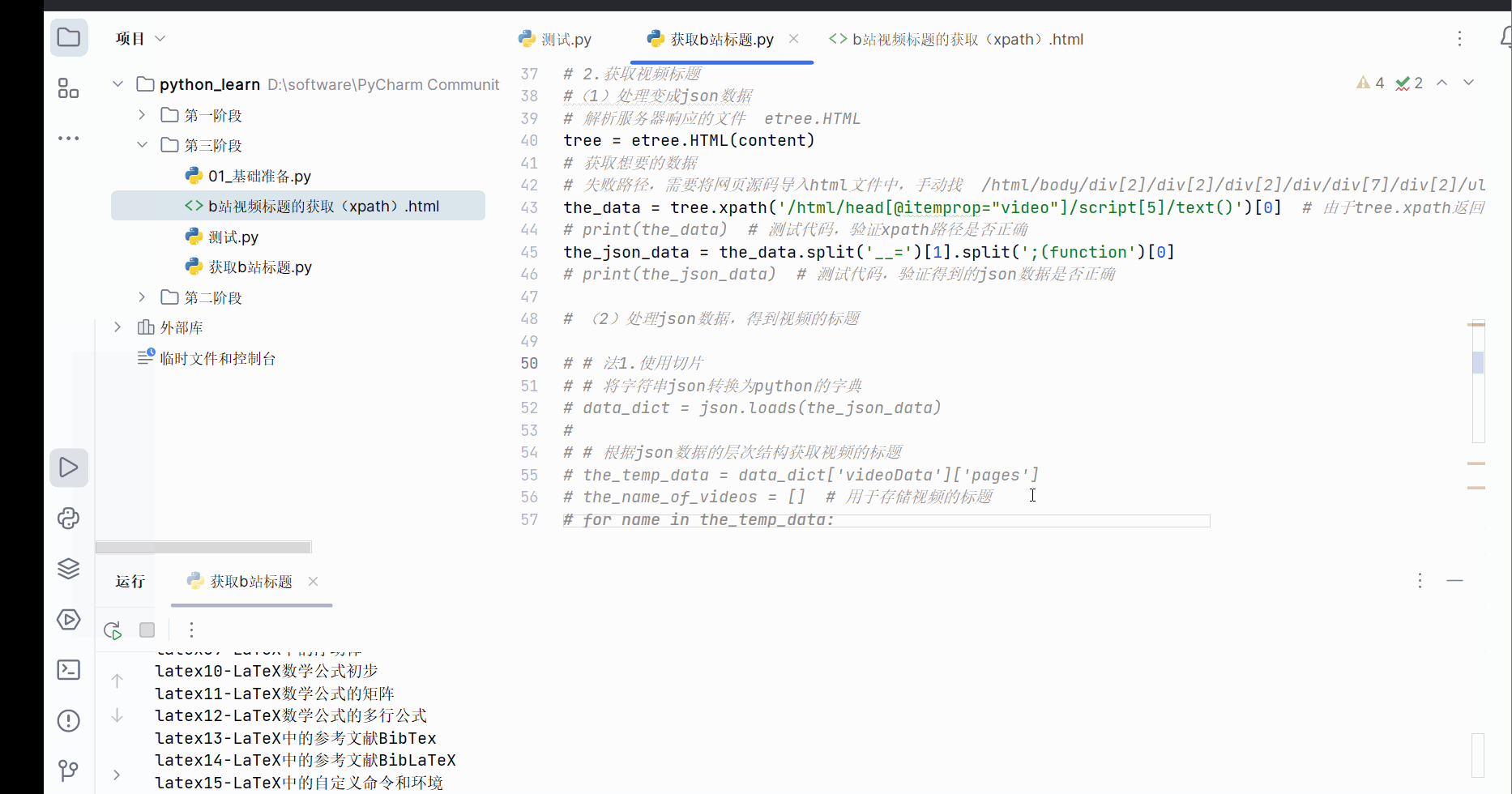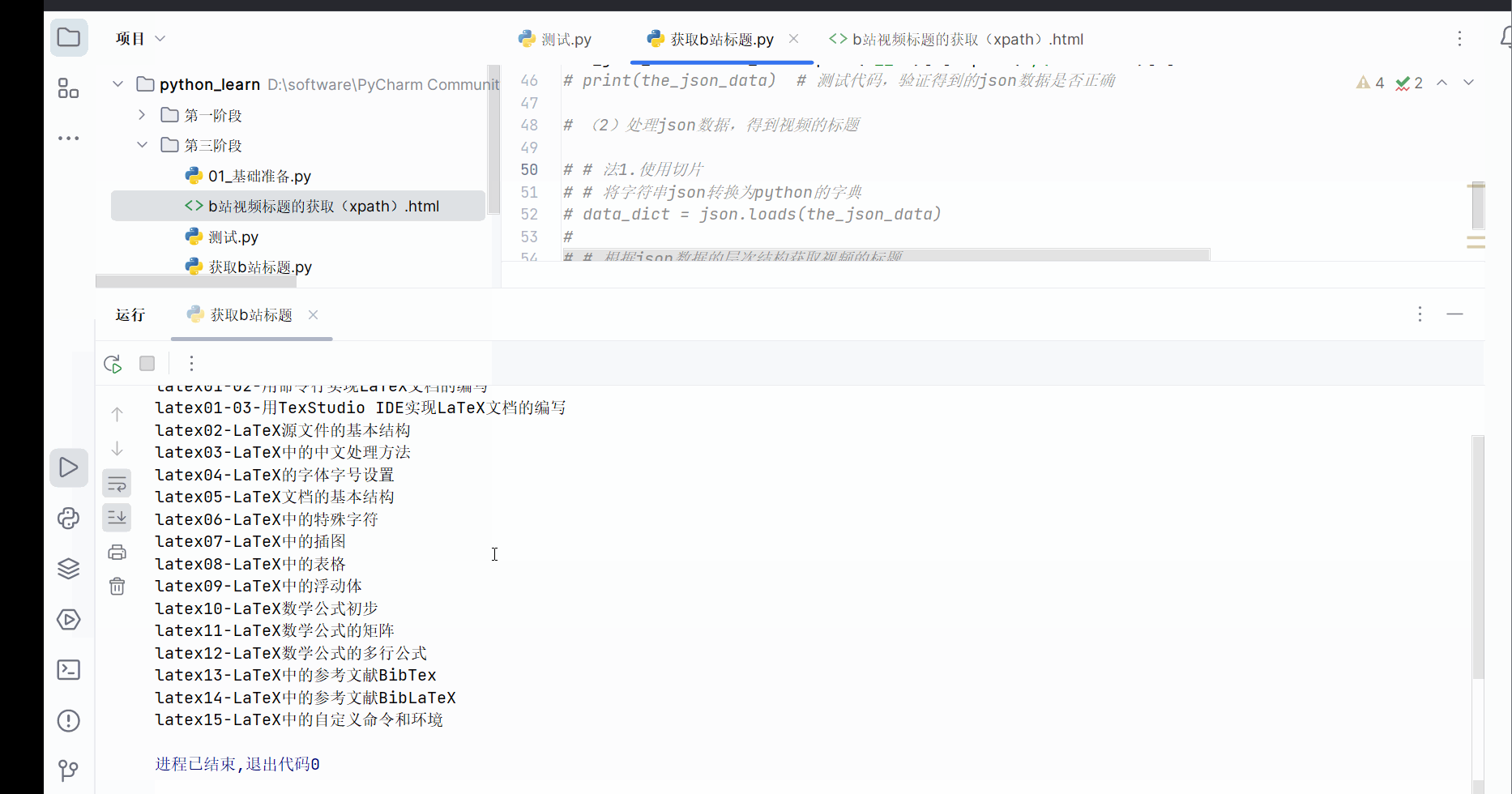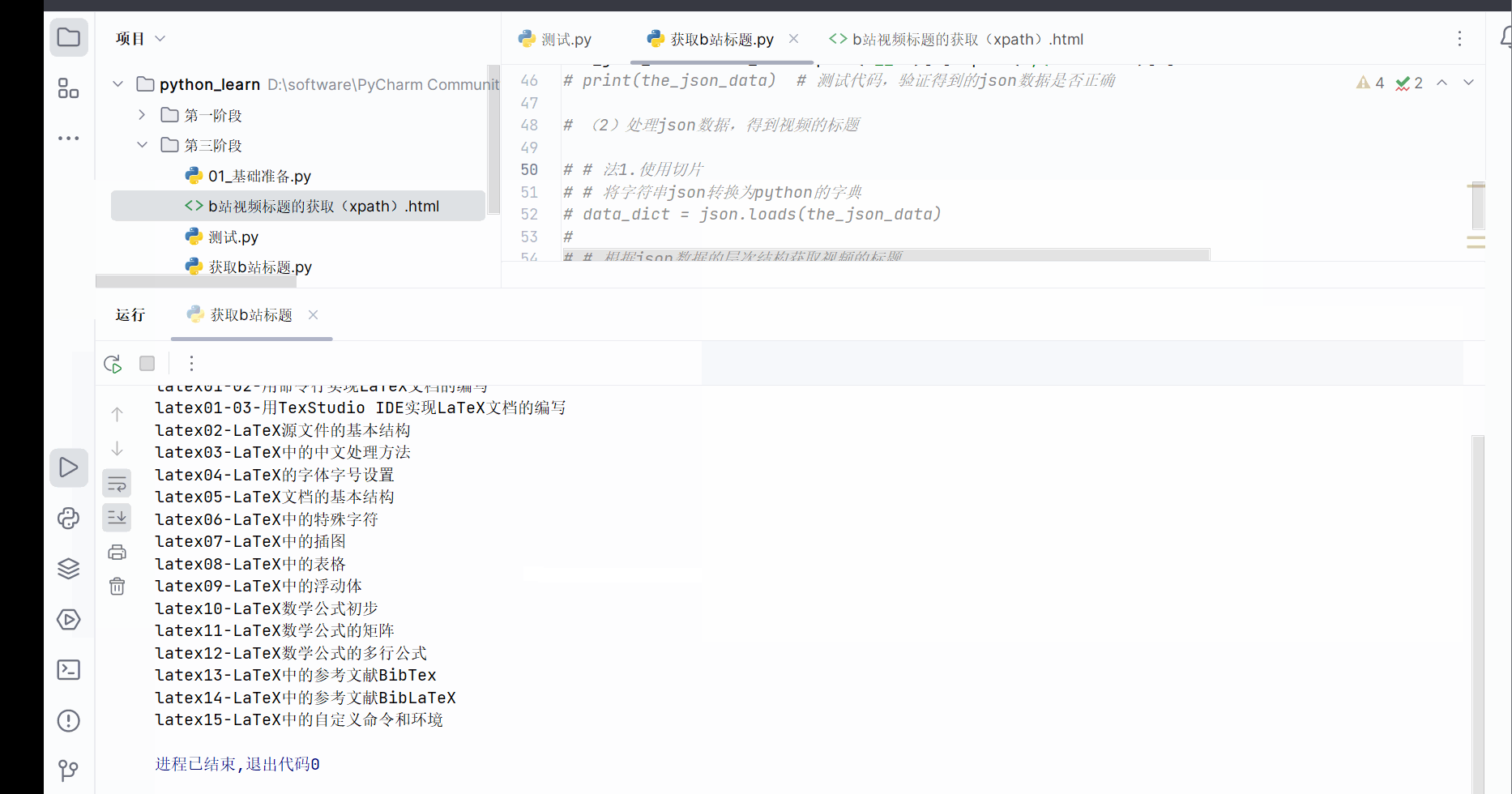
the_name_of_videos=jsonpath.jsonpath(json.loads(the_json_data),'$.videoData.pages[*].part')
# 打印b站视频的标题
for name in the_name_of_videos:
print(name)
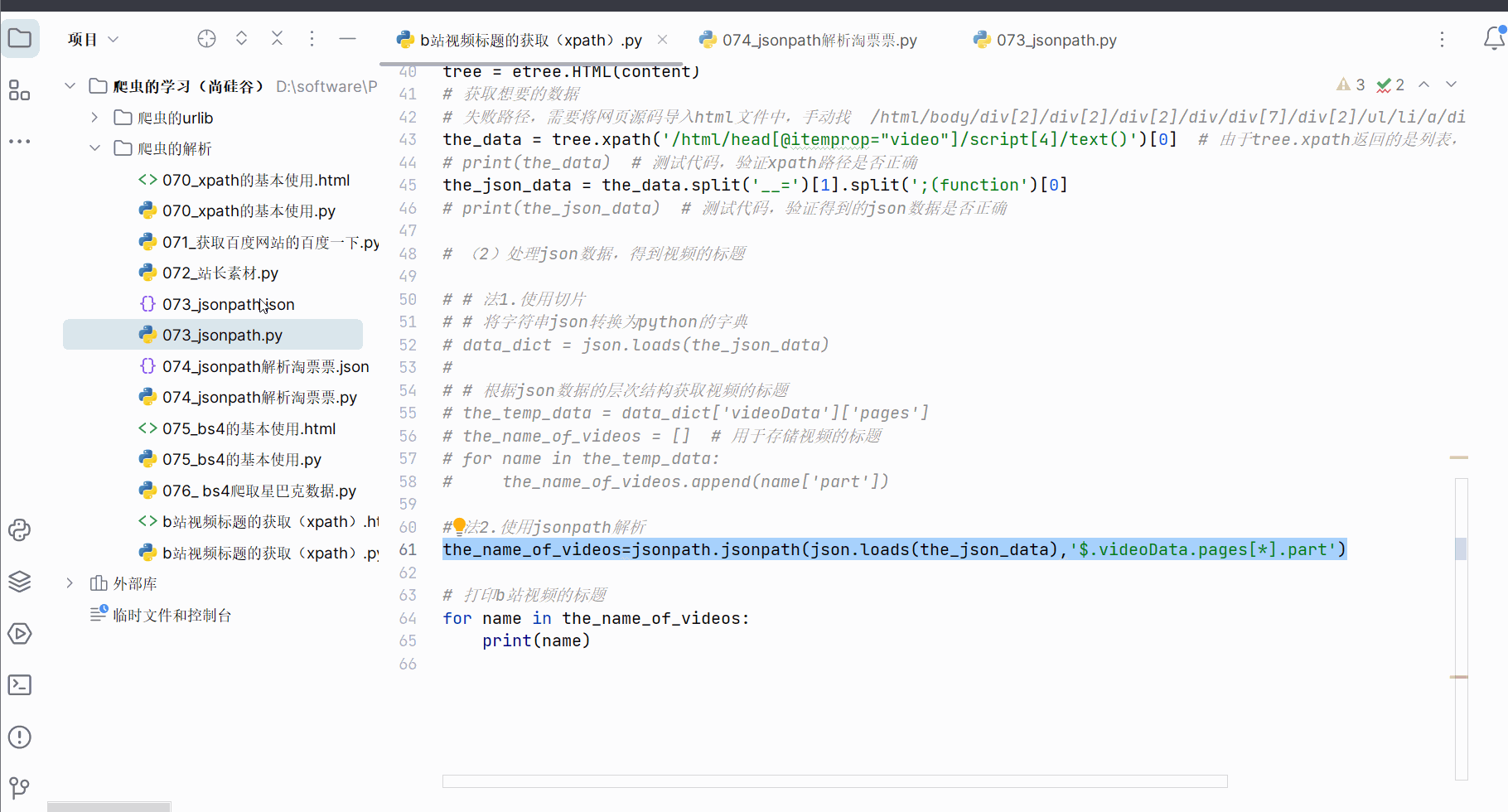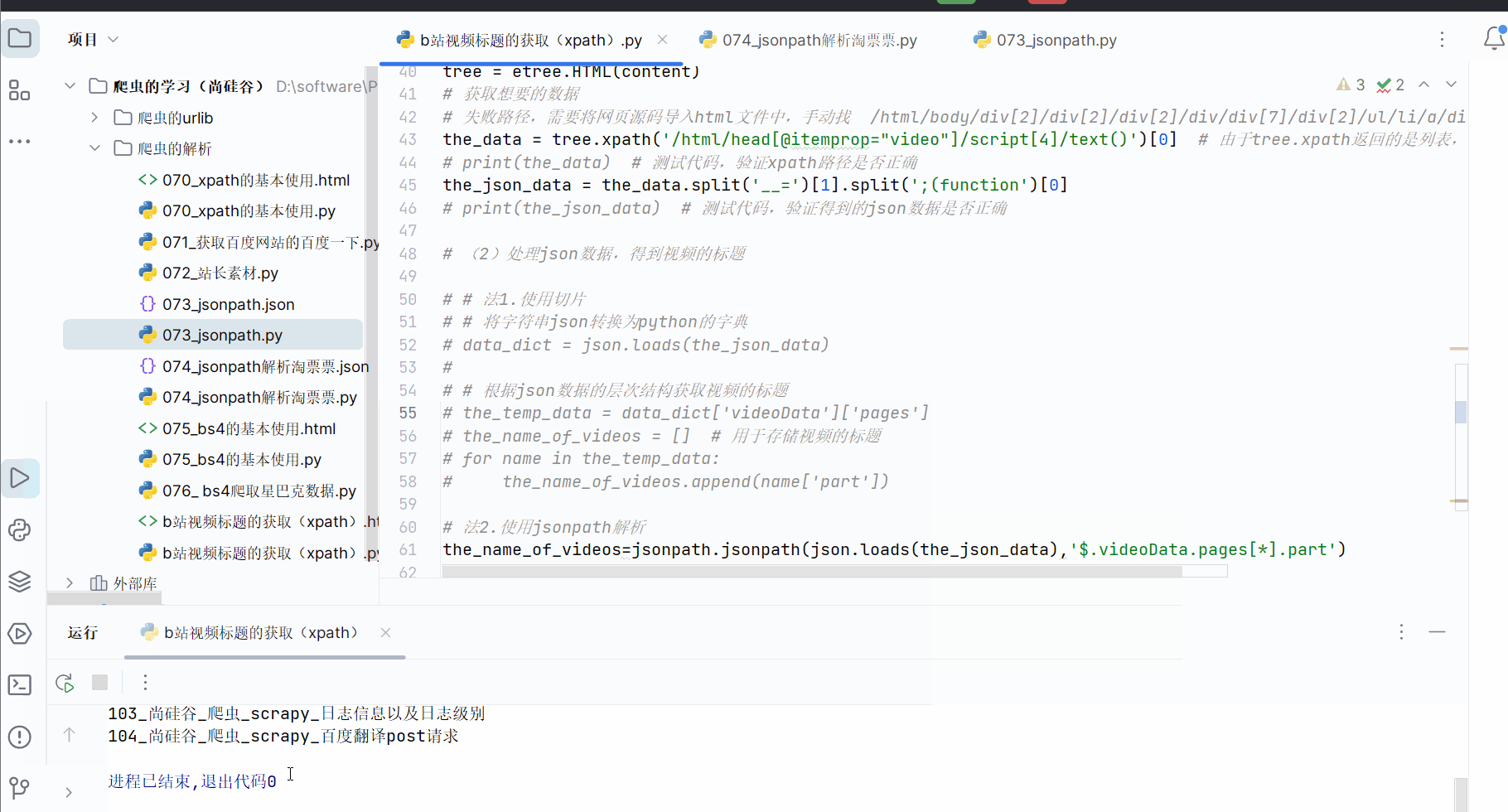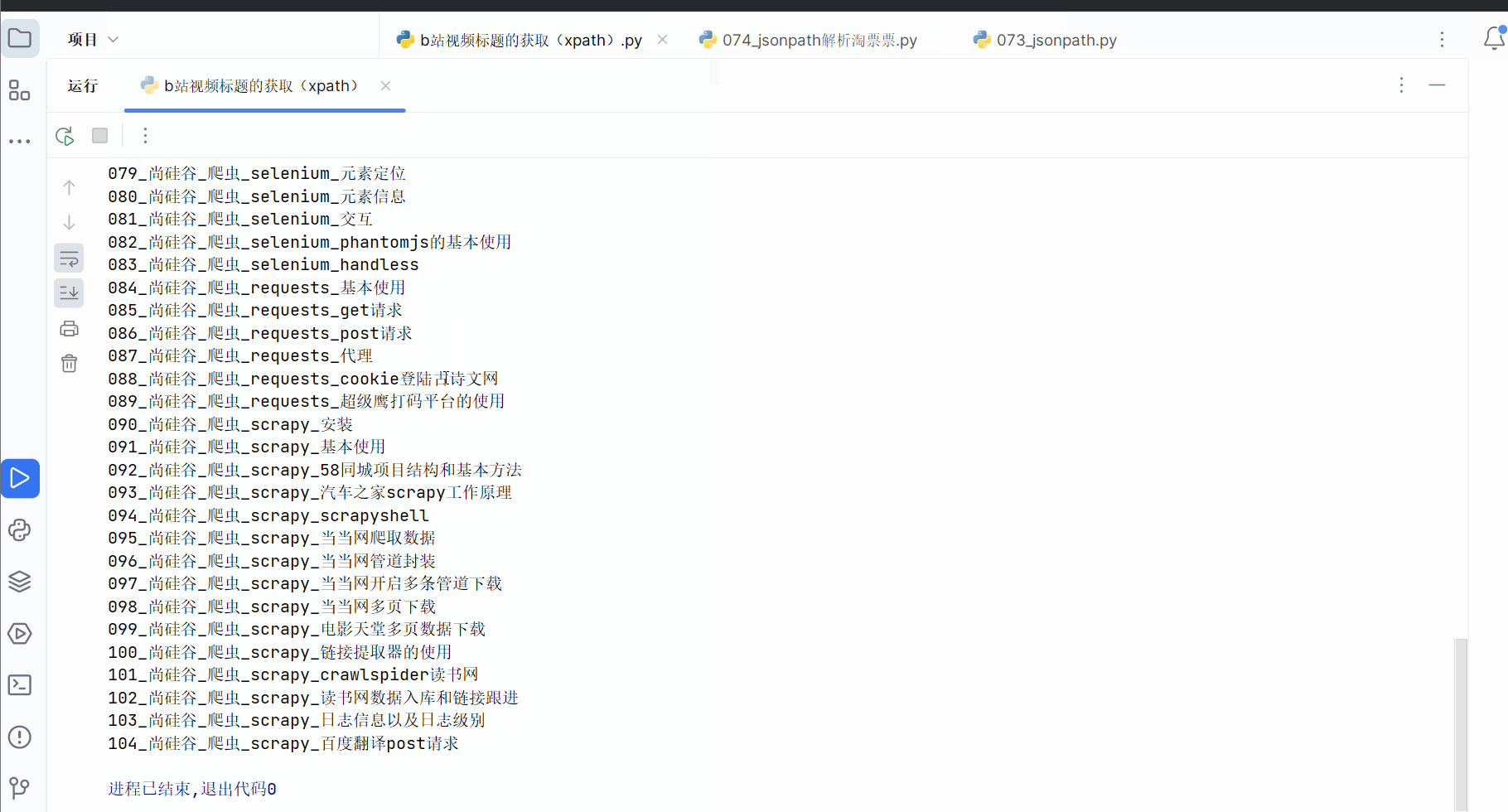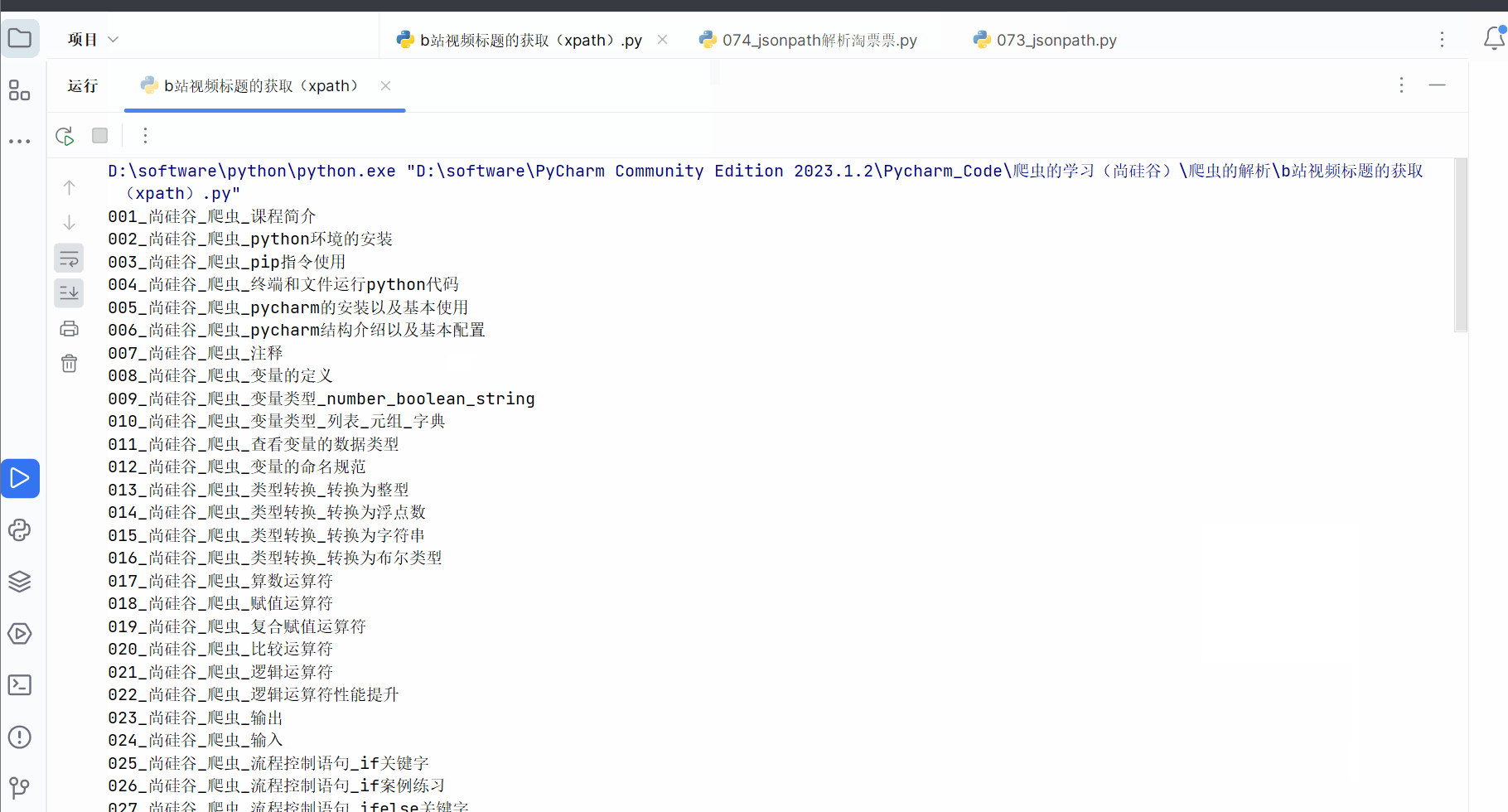
3.原代码上的更新(2023.9.19)
如下图所示,在2023.9.19本人希望获取如下b站视频的标题。发现由于网页源码的html结构有所改动,代码也需要跟着变动。
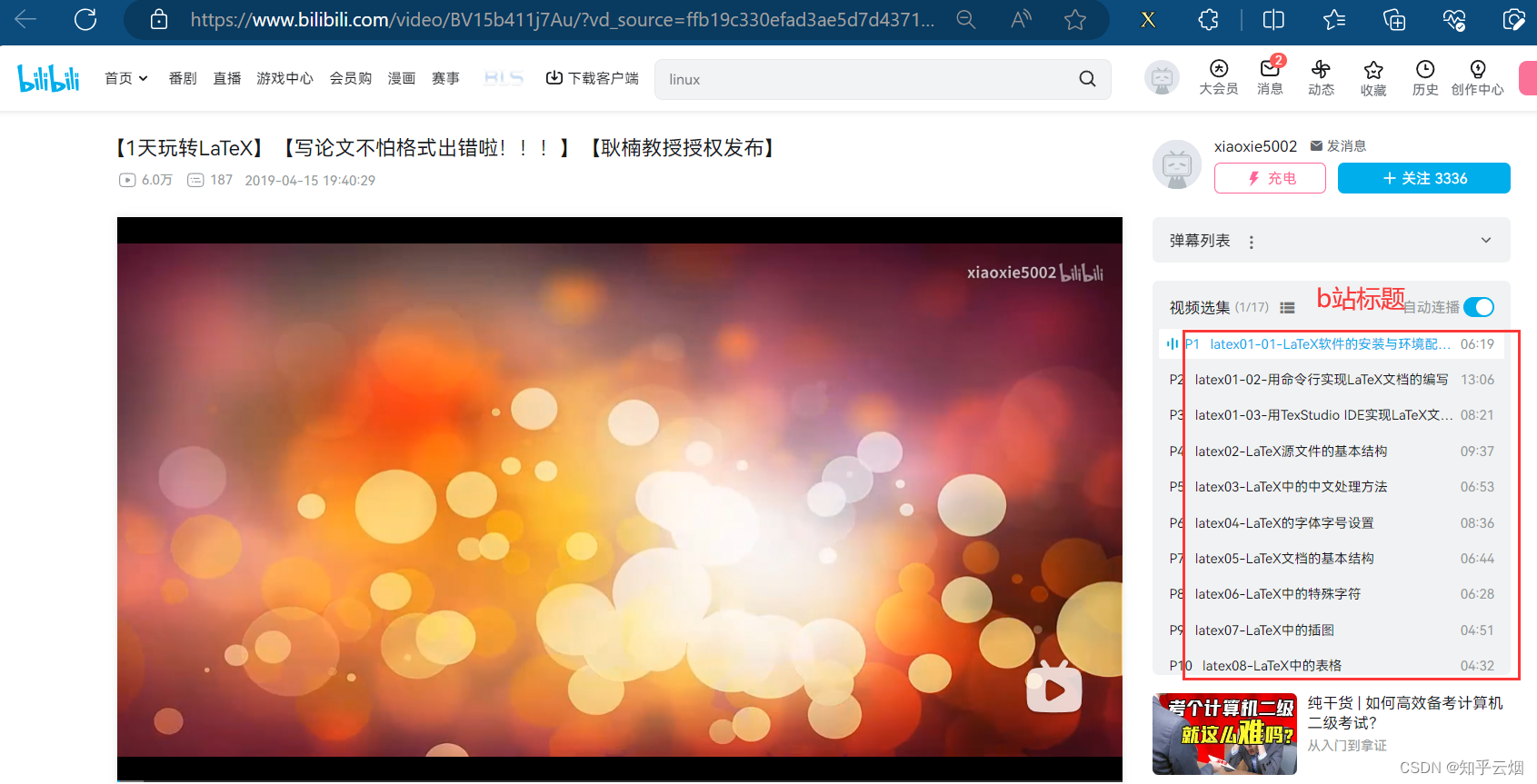
(1)首先需要修改请求地址和请求头里的”Referer“。修改代码的具体位置以及如何去浏览器中寻找请求地址和请求头里的”Referer“如下几张图所示。
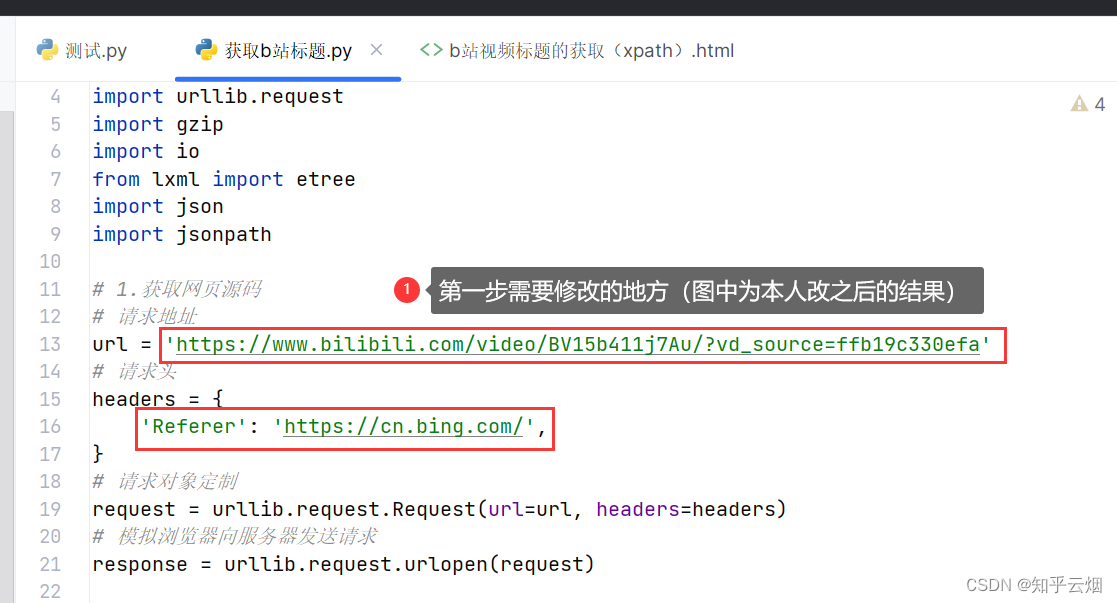
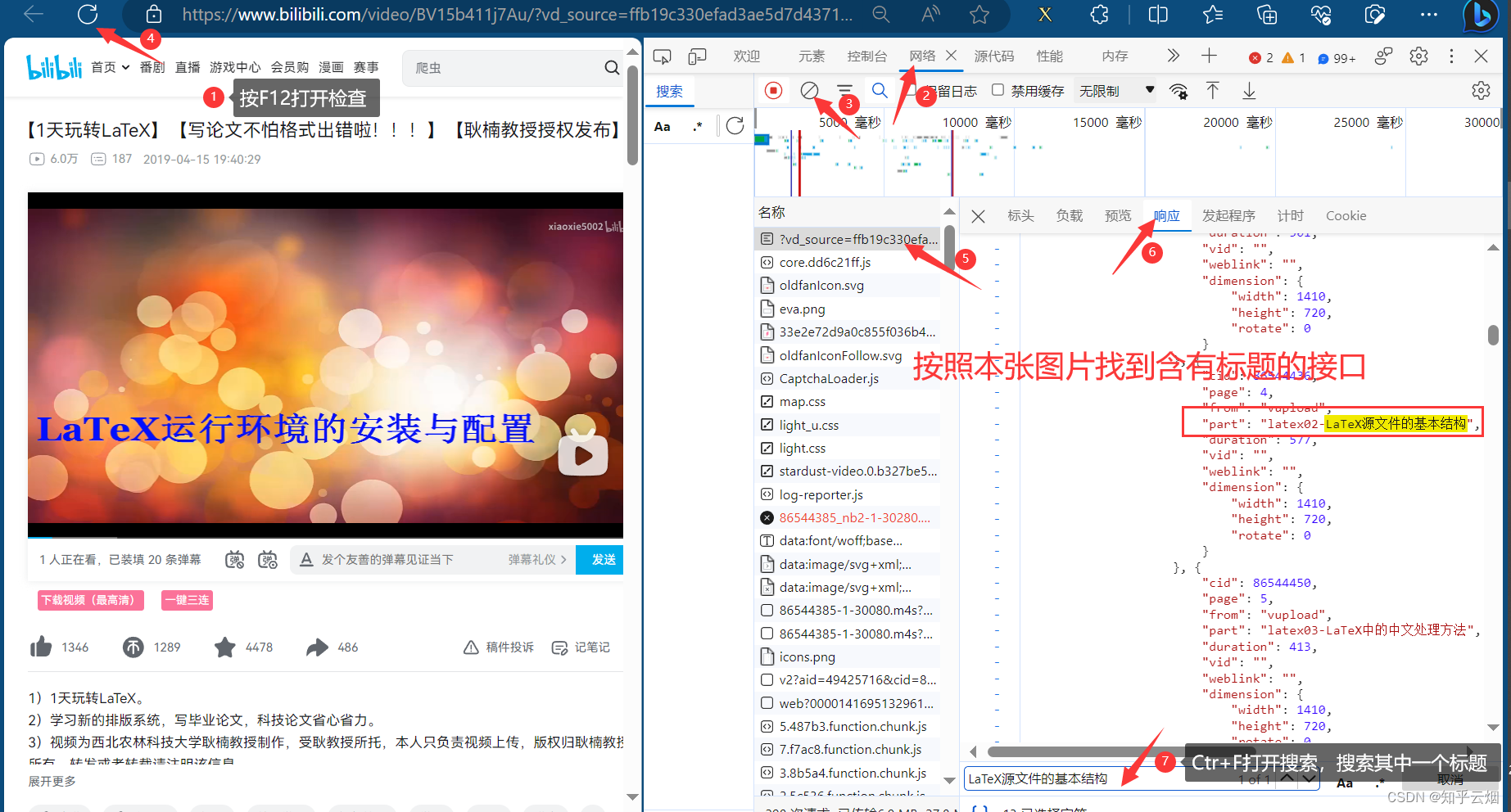
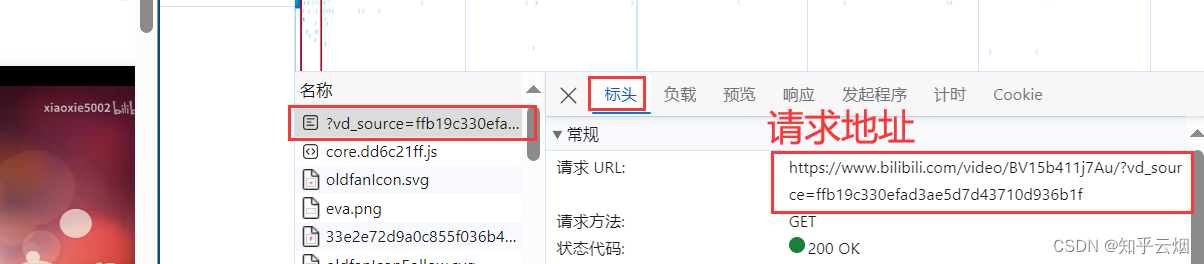
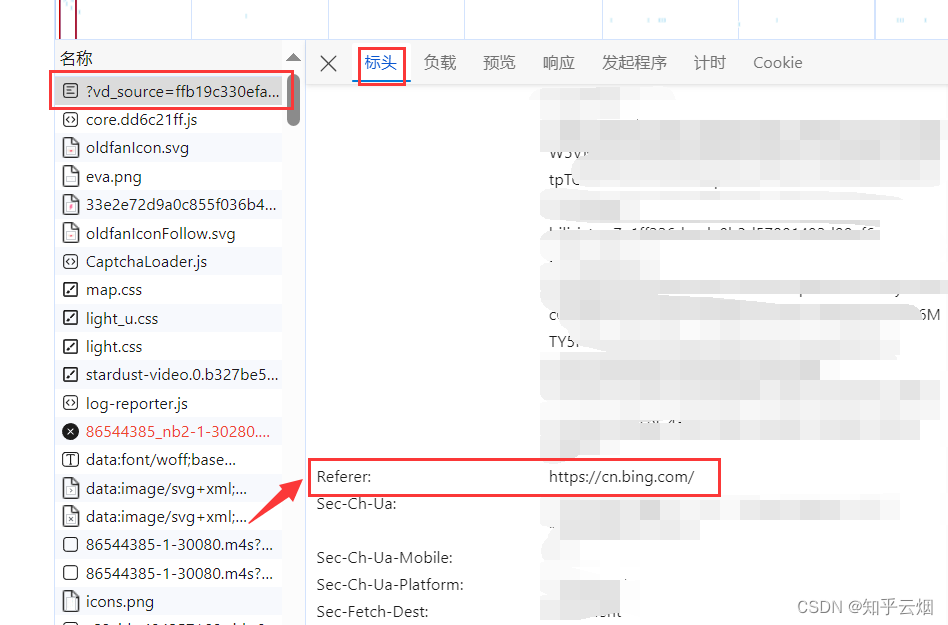
(2)然后如下图所示去修改数据的xpath路径。
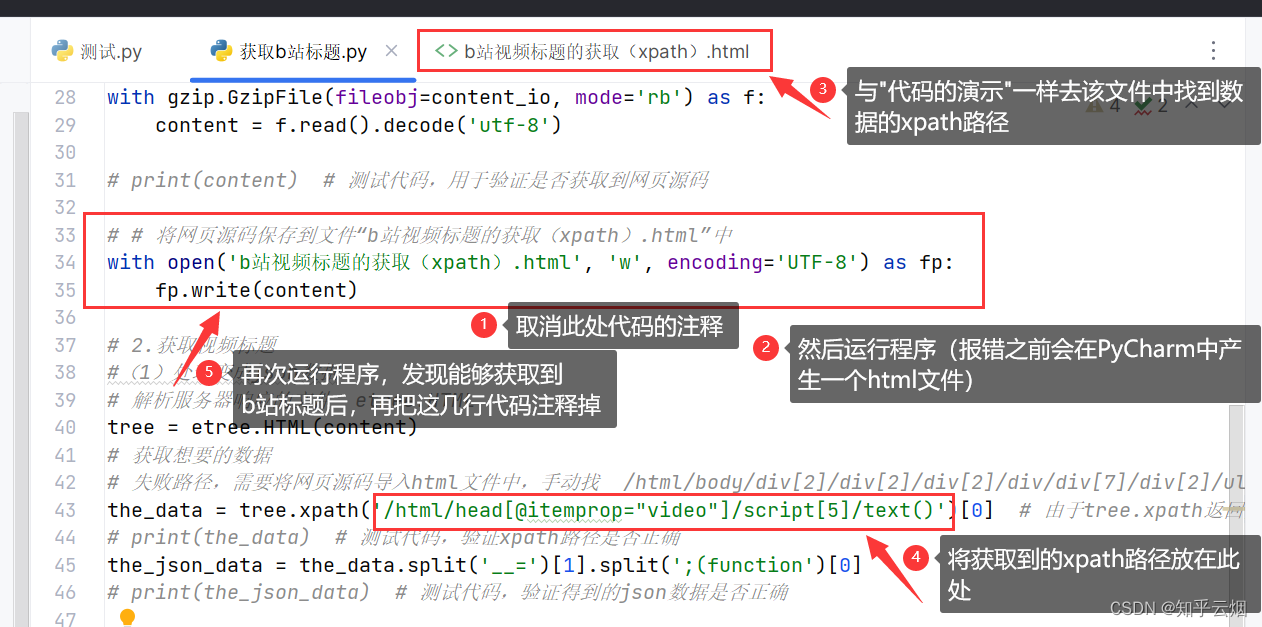
之后,如下图所示,发现能够再次获取到b站标题。
"""
b站视频标题的获取(xpath)
"""
import urllib.request
import gzip
import io
from lxml import etree
import json
import jsonpath
# 1.获取网页源码
# 请求地址
url = 'https://www.bilibili.com/video/BV15b411j7Au/?vd_source=ffb19c330efa'
# 请求头
headers = {
'Referer': 'https://cn.bing.com/',
}
# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 读取响应的内容
content_bytes = response.read() # 从响应中读取的字节数据
# 响应内容是压缩的,需要解压 将压缩的字节数据解压并解码成UTF-8编码的字符串
content_io = io.BytesIO(content_bytes) # 创建了一个io.BytesIO对象,用于将字节数据包装成类似文件对象的形式
# 使用gzip.GzipFile来解压缩数据 mode='rb'指定以二进制模式读取
with gzip.GzipFile(fileobj=content_io, mode='rb') as f:
content = f.read().decode('utf-8')
# print(content) # 测试代码,用于验证是否获取到网页源码
# # 将网页源码保存到文件“b站视频标题的获取(xpath).html”中
with open('b站视频标题的获取(xpath).html', 'w', encoding='UTF-8') as fp:
fp.write(content)
# 2.获取视频标题
#(1)处理变成json数据
# 解析服务器响应的文件 etree.HTML
tree = etree.HTML(content)
# 获取想要的数据
# 失败路径,需要将网页源码导入html文件中,手动找 /html/body/div[2]/div[2]/div[2]/div/div[7]/div[2]/ul/li/a/div/div[1]/span[2]/text()
the_data = tree.xpath('/html/head[@itemprop="video"]/script[5]/text()')[0] # 由于tree.xpath返回的是列表,需要使用切片[0]将它取出来
# print(the_data) # 测试代码,验证xpath路径是否正确
the_json_data = the_data.split('__=')[1].split(';(function')[0]
# print(the_json_data) # 测试代码,验证得到的json数据是否正确
# (2)处理json数据,得到视频的标题
# # 法1.使用切片
# # 将字符串json转换为python的字典
# data_dict = json.loads(the_json_data)
#
# # 根据json数据的层次结构获取视频的标题
# the_temp_data = data_dict['videoData']['pages']
# the_name_of_videos = [] # 用于存储视频的标题
# for name in the_temp_data:
# the_name_of_videos.append(name['part'])
# 法2.使用jsonpath解析
the_name_of_videos=jsonpath.jsonpath(json.loads(the_json_data),'$.videoData.pages[*].part')
# 打印b站视频的标题
for name in the_name_of_videos:
print(name)
好了,本次的笔记到此结束,谢谢大家阅读。


















 2300
2300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











