






目录
添加和移除节点样式(add_class和remove_class)
7
CSS选择器
查找节点
import pyquery
import requests
from pyquery import PyQuery as pq
html="""
<div id="panel">
<ul class="list1">
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item"><a href ="https://www.jd.com">京东商城</a>
</ul>
<ul class="list2">
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item"><a href ="https://www.microsoft.com">微软</a></li>
<li class="item2"><a href ="https://www.google.com">谷歌</a></li>
</ul>
</div>
"""
# 创建PyQuery对象
doc=pq(html)
# 提取id属性值为panel,并且在该节点中所有class属性为list1的所有节点
result=doc('#panel .list1')
print(result)
# 在result的基础上,提取其中class属性值为item的所有节点(本例li节点)
print(result('.item'))
# 提取其中第二个<a>节点的href属性值和文本内容
print(result('a')[1].get('href'),result('a')[1].text)
print()
# 提取京东商城导航条链接文本
doc=pq(requests.get('https://www.jd.com').text)
group1=doc('#navitems-group1')
group2=doc('#navitems-group2')
group3=doc('#navitems-group3')
# 前4个
print(group1('a')[0].text,group1('a')[1].text,group1('a')[2].text,group1('a')[3].text)
# 中间4个
print(group2('a')[0].text,group2('a')[1].text,group2('a')[2].text,group2('a')[3].text)
# 后2个
print(group3('a')[0].text,group3('a')[1].text)结果: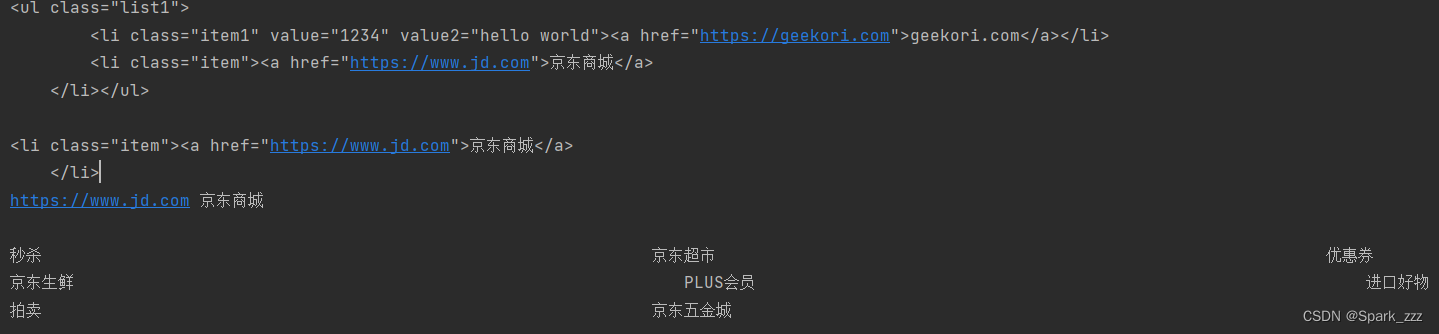
查找子节点
# 创建PyQuery对象
doc=pq(html)
# 提取id属性值为panel,并且在该节点中所有class属性为list1的所有节点
result=doc('#panel .list1')
aList=result.find('a')
print(aList)
for a in aList:
print(a.get('href'),a.text)
print('-------------------------')
result=doc('.item')
aList=result.children('a')
print(aList)
for a in aList:
print(a.get('href'),a.text)find方法与children区别
find查找子节点以及子孙节点,children只能查找子节点
查找父节点
# 查找直接父节点
print(result.parent())
# 查找所有父节点
print(result.parents())查找兄弟节点
# 创建PyQuery对象
doc=pq(html)
result=doc('#panel .list1')
# 查找class属性为list的节点的所有兄弟节点
print(result.siblings())
print(result.siblings('.list2'))获取节点信息
节点名称
html="""
<div id="panel">
<ul class="list1">
<li class="item" value1="1234" value2="hello world">
hello
123
<a href="https://geekori.com">geekori.com</a>
world
</li>
<li class="item1">
</li>
</ul>
<ul class="list2">
<li class="item3"><a href="https://www.taobao.com">淘宝</a></li>
<li class="item" value1="4321" value2="世界你好">
<a href="https://www.microsoft.com">微软</a></li>
</li>
<li class="item2"><a href="https://www.google.com">谷歌</a></li>
</ul>
</div>
"""
from pyquery import PyQuery as pq
doc=pq(html)
result=doc('.item')
# 获取某个节点名称
print(result[0].tag)节点属性
# 获取查询结果的第1个li节点的value1属性值
print('value1:',result[0].get('value1'))
# 获取查询结果的第1个li节点的value1属性值
print('value2:',result.attr('value2'))
print('value2:',result.attr.value2)节点文本
# text方法得到所有节点的文本
print(result.text())
# 对于lxml.etree_Element类来说,text属性获取该节点文本
# text属性只会获得节点中出现的第一个普通节点之前的文本,普通文本后不会获得
for node in result:
print(node.text)修改节点
添加和移除节点样式(add_class和remove_class)
add_class方法可以向节点的class属性添加样式,remove_class可以从节点的class属性移除样式
这两个方法都需要传入字符串形式的样式
如果多个样式,中间用空格隔开
from pyquery import PyQuery as pq
html="""
<div id="panel">
<ul class="list1">
<li class="item1 item2 item3">谷歌</li>
<li class="item1 item2">微软</li>
</ul>
</div>
"""
doc=pq(html)
# 查询class属性值为item1 item2的节点
li=doc('.item1.item2')
print(li)
# 为查询结果的所有节点添加一个名为myitem的样式
li.add_class('myitem')
print(li)
# 为查询结果的所有节点移除一个名为item1的样式
li.remove_class('item1')
print(li)
# 为查询结果的所有节点移除两个样式(item2和item3)
li.remove_class('item2 item3')
print(li)
# 为查询结果的所有节点添加两个样式(class1和class2)
li.add_class('class1 class2')
print(li)注意:
1)用pyquery查询节点时,如果需要指定多个样式,每个样式前面需要加点(.),而且多个样式要首尾相续,中间不能有空格
2)添加和删除样式时,样式名不能带点(.),否则会将(.)作为样式名的一部分添加到class属性中
3)添加和删除多个样式时,多个样式之间用空格分隔
4)如果需要操作多个节点,add_class和remove_class方法对所有节点有效
结果:
修改节点属性和文本内容(attr、remove_attr、text、html)
doc=pq(html)
# 查询所有class属性值为item1 item2的节点(本例都是li节点)
li=doc('.item1.item2')
print(li)
# 获取所有li节点的文本
print(li.text())
# 获取第一个li节点的文本
print(li.html())
print('------------')
# 为所有的li节点添加id属性
li.attr('id','list')
# 修改所有li节点的class属性
li.attr('class','myitem1,myitem2')
print(li)
# 删除所有li节点的id属性
li.remove_attr('id')
# 删除所有li节点的class属性
li.remove_attr('class')
print(li)
# 设置所有li节点的文本内容
li.text('列表')
print(li)
# 用text方法设置html代码,特殊字符会转码
li.text('\n<a href="https://www.google.com">\n')
print(li)
# 设置html形式的文本内容
li.html('\n<a href="https://www.google.com">\n')
print(li)
# 获取所有li节点的文本内容(没纯文本内容,啥都获取不了)
print(li.text())
# 获取所有li节点的html代码
print(li.html())结果: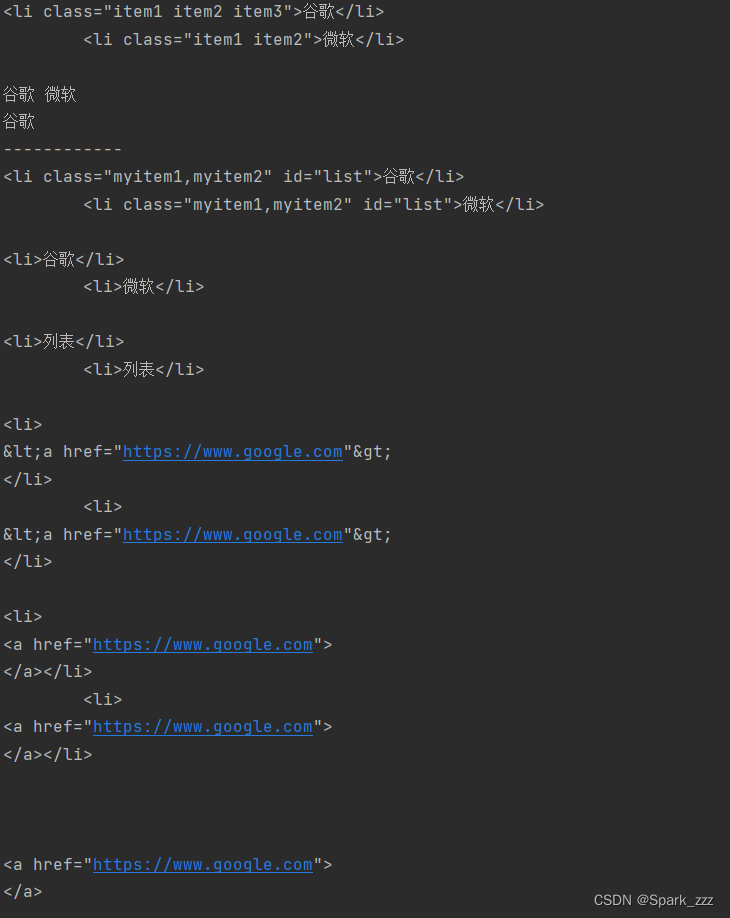
删除节点
from pyquery import PyQuery as pq
html="""
<div id=panel>
<ul class="list1">
<li class="item1 item2">谷歌<p>微软</p>Facebook</li>
</ul>
</dic>
"""
doc=pq(html)
li=doc('.item1.item2')
# 获取li节点所有文本
print(li.text())
print('------<p>微软</p>---------删除')
li.remove('p')
print(li)
# 重新获取li节点中所有的文本
print(li.text())结果: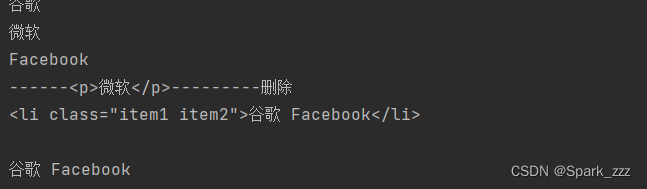
li=doc('.item1.item2')
# 先找到p节点,然后删除
print(li.find('p').remove())
print(li.text()) 结果:
伪类选择器
支持选择第一个节点,最后一个节点,索引为奇书、偶数的节点,包含某个文本的节点等
from pyquery import PyQuery as pq
html="""
<html>
<head>
<meta charset="UTF-8">
<title>演示</title>
</head>
<body>
<div>
<ul>
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item"><a href ="https://www.jd.com">京东商城(https://www.jd.com)</a></li>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item" value="1234"><a href ="https://www.microsoft.com">微软</a></li>
<li class="item2"><a href ="https://www.google.com">谷歌</a></li>
</ul>
</div>
"""
doc=pq(html)
# 选取第1个li节点
li=doc('li:first-child')
print(li)
# 选取最后1个li节点
li=doc('li:last-child')
print(li)
# 选取第3个li节点
li=doc('li:nth-child(3)')
print(li)
# 选取索引小于2的li节点(从0开始)
li=doc('li:lt(3)')
print(li)
# 选取索引大于3的li节点(从0开始)
li=doc('li:gt(3)')
print(li)
# 选择序号为奇数的li节点,第一个li节点的序号为1
li=doc('li:nth-child(2n+1)')
print(li)
# 选择序号为偶数的li节点
li=doc('li:nth-child(2n)')
print(li)
# 选择文本内容包含com的所有li节点
li=doc('li:contains(com)')
print(li)
# 选取文本内容包含com的所有节点
all=doc(':contains(com)')
print(len(all))
for t in all:
print(t.tag,end=' ')















 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









