






目录
节点选择器
节点选择器直接通过节点的名称选择节点,然后使用string属性得到节点内的文本
选择节点
定义html字符串
from bs4 import BeautifulSoup
html="""
<html>
<head>
<meta charset="UTF-8">
<title>演示</title>
</head>
<body>
<div>
<ul>
<li class="item1" value="1234" value2="hello world">
<a href ="https://geekori.com">geekori.com</a>
</li>
<li class="item2"><a href ="https://www.jd.com">京东商城</a></li>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item4" value="1234"><a href ="https://www.microsoft.com">微软</a></li>
<li class="item5"><a href ="https://www.google.com">谷歌</a></li>
</ul>
</div>
</body>
</html>
"""soup=BeautifulSoup(html,'lxml')
# 获取节点名称
print(soup.title.name)
# 获取节点属性
# 每个节点有0-n个属性,可以用attrs获取节点的所有名称和属性值
print(soup.li.attrs)
print(soup.li.attrs['value2'])
# 如果只是节点的某一个属性值,可以省略attrs
print(soup.li['value2'])
# 获取节点的内容
print(soup.a.string)
soup.li.attrs['value2']或者soup.li['value2']获取的属性值是一个字符串,而xpath是列表
运行结果: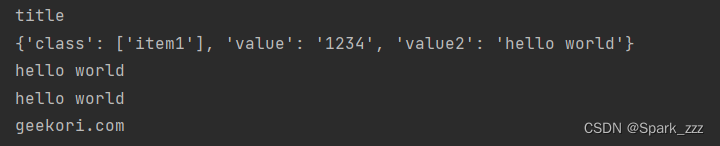
from bs4 import BeautifulSoup
html="""
<html>
<head>
<meta charset="UTF-8">
<title>演示</title>
</head>
<body>
<div>
<ul>
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item2"><a href ="https://www.jd.com">京东商城</a></li>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item4" value="1234"><a href ="https://www.microsoft.com">微软</a></li>
<li class="item5"><a href ="https://www.google.com">谷歌</a></li>
</ul>
</div>
</body>
</html>
"""
soup=BeautifulSoup(html,'lxml')
print(soup.head)
print()
print(type(soup.head))
print()
print(soup.head.title.string)
print()
print(soup.body.div.ul.a['href'])运行结果:
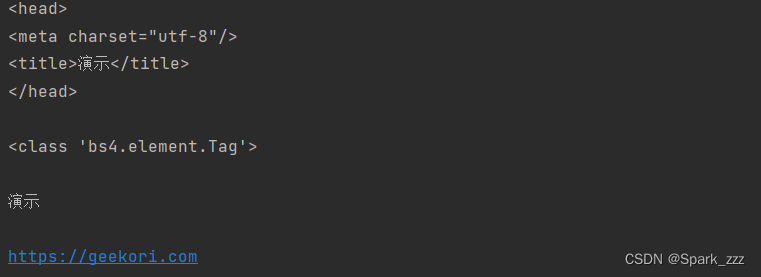
嵌套选择节点
from bs4 import BeautifulSoup
html="""
<html>
<head>
<meta charset="UTF-8">
<title>演示</title>
</head>
<body>
<div>
<ul>
<li class="item1"><a href ="https://www.jd.com">京东商城</a></li>
</ul>
</div>
</body>
</html>
"""
soup=BeautifulSoup(html,'lxml')
# 选取head节点
print(soup.head)
print()
print(type(soup.head))
print()
head=soup.head
print(head.title.string)
print()
print(soup.body.div.ul.li.a['href'])运行结果: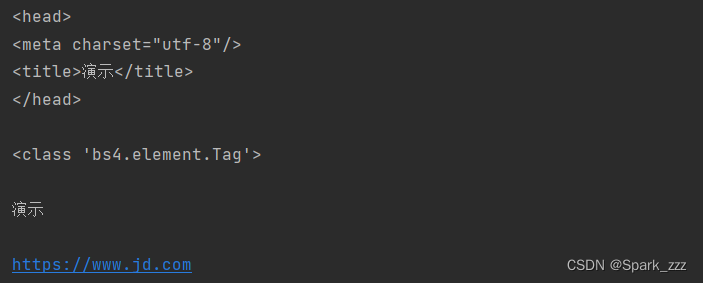
获取子节点及子孙节点
from bs4 import BeautifulSoup
html="""
<html>
<head>
<meta charset="UTF-8">
<title>演示</title>
<tag1><a><b></b></a></tag1>
</head>
<body>
<div>
<ul>
<li class="item1" value="hello world">
<a href="https://geekori.com">
geekori.com
</a>
</li>
<li class="item2"><a href="https://www.jd.com">京东商城</a></li>
</ul>
</div>
</body>
</html>
"""
soup=BeautifulSoup(html,'lxml')
# 输出head所有直接子节点
print(soup.head.contents) #返回列表,包括(\n)换行符
print(soup.head.children) #返回一个可迭代对象,需要for循环进行迭代
print(type(soup.head.contents))
print(type(soup.head.children))
#获取所有子孙节点,返回一个产生器,需要for循环进行迭代
print(soup.head.descendants)
print(type(soup.head.descendants))运行结果:
输出子节点两种方式
第一种,使用enumerate()函数,第一个参数迭代对象,第二个参索引起始值
enumerate(sequence, [start=0])
# 对ul中的所有节点进行迭代,并以文本形式输出子节点的内容
for i ,child in enumerate(soup.body.div.ul.contents):
print(i,child)
print('---------------') 运行结果;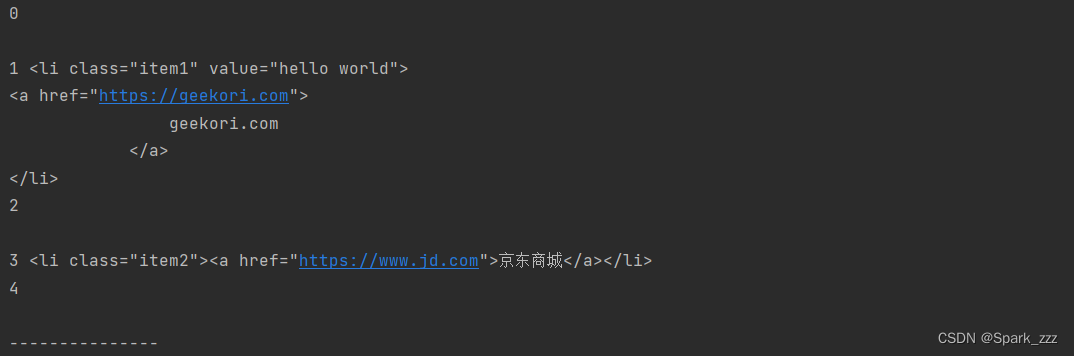
第二种,不使用enumerate()函数,所以要定义一个变量i保存元素索引
i=1
for child in soup.body.div.ul.children:
print('<',i,'>',child,end=' ')
i+=1
print('---------------') 运行结果: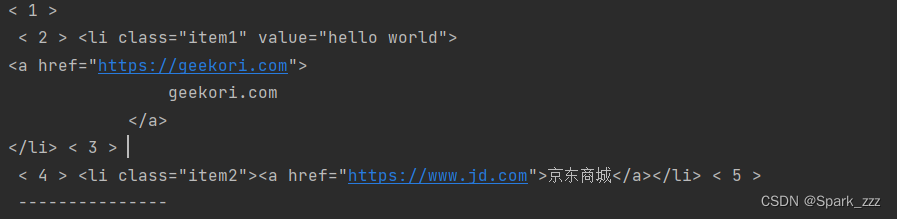
输出子孙节点
for i,child in enumerate(soup.body.div.ul.descendants):
print('[',i,']',child)
print('---------------')运行结果: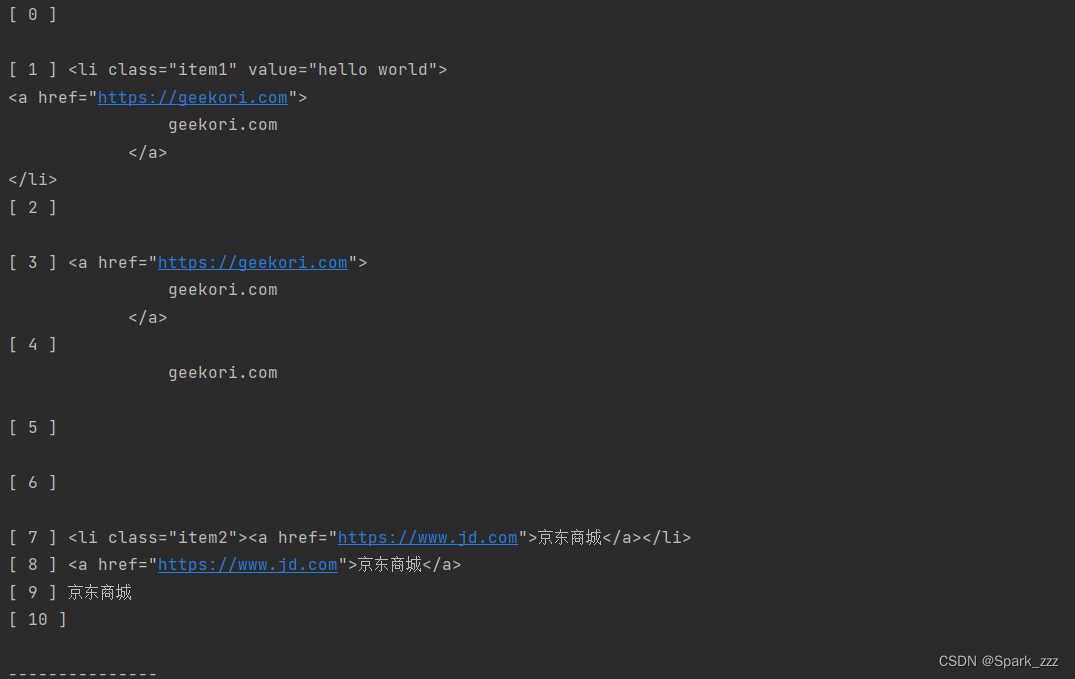
获取父节点
from bs4 import BeautifulSoup
html="""
<html>
<head>
<meta charset="UTF-8">
<title>演示</title>
<tag1><a1><b></b></a1></tag1>
</head>
<body>
<div>
<ul>
<li class="item1" value="hello world">
<a href="https://geekori.com">
geekori.com
</a>
</li>
<li class="item2"><a href="https://www.jd.com">京东商城</a></li>
</ul>
</div>
</body>
</html>
"""
soup=BeautifulSoup(html,'lxml')
# 获取<a>的直接父节点
print(soup.a.parent)
# 获取<a>的直接父节点的class属性值
print(soup.a.parent['class'])
# 获取<a>的所有父节点
print(soup.a.parents)
for parent in soup.a.parents:
print('<',parent.name,'>')运行结果: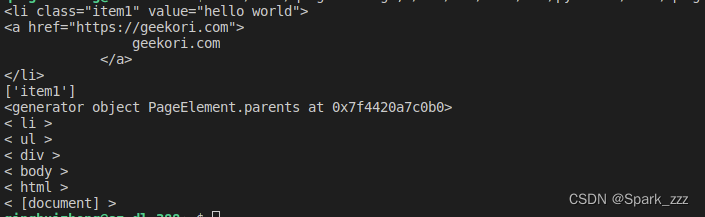
获取兄弟节点
next_sibling属性获得当前节点的下一个兄弟节点
previous_sibling属性获得当前节点的上一个兄弟节点
next_siblings属性获得当前节点后面的所有兄弟节点(可迭代对象)
previous_siblings属性获得当前节点前面的所有兄弟节点(可迭代对象)
PS: \n 换行符也属于一个文本节点
from bs4 import BeautifulSoup
html="""
<html>
<head>
<meta charset="UTF-8">
<title>演示</title>
</head>
<body>
<div>
<ul>
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item2"><a href ="https://www.jd.com">京东商城</a></li>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item4" value="1234"><a href ="https://www.microsoft.com">微软</a></li>
<li class="item5"><a href ="https://www.google.com">谷歌</a></li>
</ul>
</div>
</body>
</html>
"""
soup=BeautifulSoup(html,'lxml')
# 得到第2个li节点,soup.li.next_sibling值的是文本节点(包括\n节点)
secondli=soup.li.next_sibling.next_sibling
# 输出第2个li节点的代码
print('第1个li节点的下一个li节点:',secondli)
# 获得第2个li节点的上一个同级的li节点,并输出该li节点的class属性的值
print('第2个li节点的上一个li节点的class属性值:',
secondli.previous_sibling.previous_sibling['class'])
# 输出第2个li节点后的所有节点,包括带换行符的文本节点
print()
for sibling in secondli.next_siblings:
print(type(sibling))
if str.strip(sibling.string)=='':
print('换行')
else:
print(sibling)运行结果: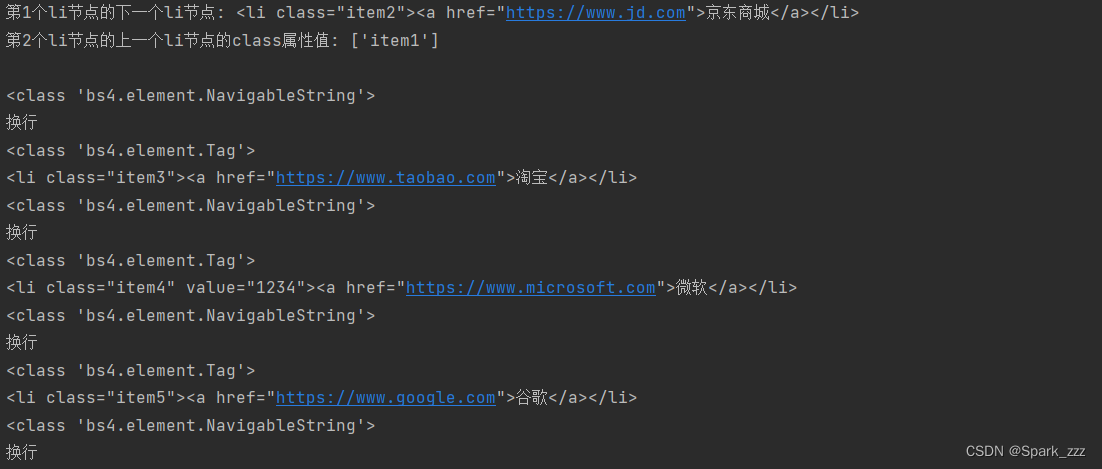
方法选择器
find_all方法

1.name参数
from bs4 import BeautifulSoup
html="""
<html>
<head>
<meta charset="UTF-8">
<title>演示</title>
</head>
<body>
<div>
<ul>
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item2"><a href ="https://www.jd.com">京东商城</a></li>
</ul>
<ul>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item4" value="1234"><a href ="https://www.microsoft.com">微软</a></li>
<li class="item5"><a href ="https://www.google.com">谷歌</a></li>
</ul>
</div>
</body>
</html>
"""
soup=BeautifulSoup(html,'lxml')
# 搜索所有的ul节点
ulTags=soup.find_all(name='ul')
# 输出ulTags类型
print(type(ulTags))
# 迭代获取的所有ul节点对应的Tag对象运行结果:![]()
# 迭代获取的所有ul节点对应的Tag对象
for ulTag in ulTags:
print(ulTag) 运行结果: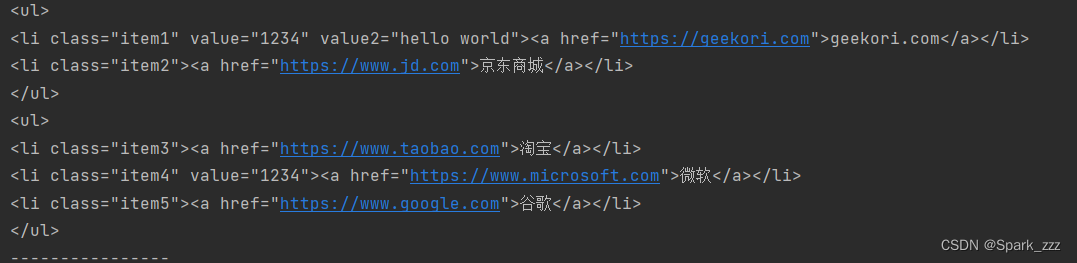
for ulTag in ulTags:
# 选取当前ul节点下的所有li节点
liTags=ulTag.find_all(name='li')
for liTag in liTags:
print(liTag) 运行结果:
2.attrs参数
from bs4 import BeautifulSoup
html="""
<div>
<ul>
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item"><a href ="https://www.jd.com">京东商城</a></li>
</ul>
<button id="button1">确定</button>
<ul>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item" value="1234"><a href ="https://www.microsoft.com">微软</a></li>
<li class="item2"><a href ="https://www.google.com">谷歌</a></li>
</ul>
</div>
"""
soup=BeautifulSoup(html,'lxml')
# 查询class属性值为item的所有节点
tags=soup.find_all(attrs={'class':'item'})
print(tags)
for tag in tags:
print(tag)
# 查询class属性值为item2的所有节点
tags=soup.find_all(class_='item2')
print(tags)
# 查询id属性值为button1的所有节点
tags=soup.find_all(id='button1')
print(tags)运行结果:
3.text参数
参数可以是字符串,也可以是正则表达式对象
import re
from bs4 import BeautifulSoup
html="""
<div>
<xyz>hello world</xyz>
<button>this is a button</button>
<a href='https://geekori.com'>geekori.com</a>
</div>
"""
soup=BeautifulSoup(html,'lxml')
# 搜索文本为geekori.com的文本节点
tags=soup.find_all(text='geekori.com')
print(tags)
# 搜索文本包含this的文本节点
tags=soup.find_all(text=re.compile('this'))
print(tags)运行结果:
find方法

CSS选择器
基本用法:
需要使用Tag对象的select方法,接受一个字符串类型的CSS选择器
例:
.item (选取class属性值是item的节点)
a (选取节点名为a的节点)
#button (选取id属性值是button的节点)
from bs4 import BeautifulSoup
html="""
<div>
<ul>
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item"><a href ="https://www.jd.com">京东商城</a></li>
</ul>
<button id="button1">确定</button>
<ul>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item" value="1234"><a href ="https://www.microsoft.com">微软</a></li>
<li class="item2"><a href ="https://www.google.com">谷歌</a></li>
</ul>
</div>
"""
soup=BeautifulSoup(html,'lxml')
# 选取class属性值是item的所有节点
tags=soup.select('.item')
print(type(tags))
for tag in tags:
print(tag)
# 选取id属性值是button1的所有节点
tags=soup.select('#button1')
print(tags)
# 选取节点名为a的节点中除了前2个节点外的所有节点
tags=soup.select('a')[2:]
print(type(tags))
for tag in tags:
print(tag)运行结果: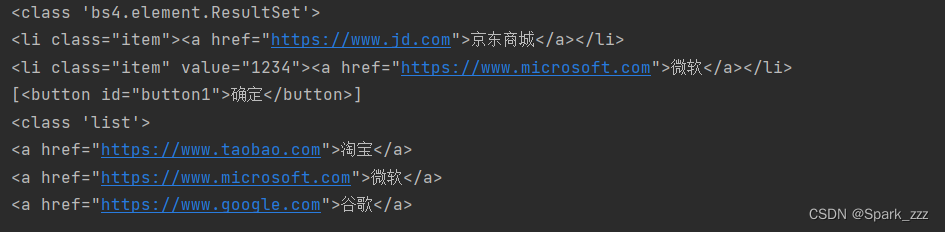
嵌套选择节点
跟节点选择器的嵌套相似
from bs4 import BeautifulSoup
html="""
<div>
<ul>
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item">
<a href ="https://www.jd.com">京东商城</a>
<a href ="https://www.google.com">谷歌</a>
</li>
</ul>
<ul>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item" value="1234"><a href ="https://www.microsoft.com">微软</a></li>
</ul>
</div>
"""
soup=BeautifulSoup(html,'lxml')
# 选取class属性值为item的所有节点
tags=soup.select('.item')
print(type(tags))
for tag in tags:
# 在当前节点中选取节点名为a的所有节点
aTags=tag.select('a')
for aTag in aTags:
print(aTag)
print('----------------')
for tag in tags:
# 通过方法选择器选取节点名为a的所有节点
aTags=tag.find_all(name='a')
for aTag in aTags:
print(aTag)运行结果:
获取属性值与文本

from bs4 import BeautifulSoup
html="""
<div>
<ul>
<li class="item1" value="1234" value2="hello world"><a href ="https://geekori.com">geekori.com</a></li>
<li class="item">
<a href ="https://www.jd.com">京东商城</a>
<a href ="https://www.google.com">谷歌</a>
</li>
</ul>
<ul>
<li class="item3"><a href ="https://www.taobao.com">淘宝</a></li>
<li class="item" value="1234"><a href ="https://www.microsoft.com">微软</a></li>
</ul>
</div>
"""
soup=BeautifulSoup(html,'lxml')
# 选取class属性值为item的所有节点
tags=soup.select('.item')
print(type(tags))
for tag in tags:
# 在当前节点中选取节点名为a的所有节点
aTags=tag.select('a')
for aTag in aTags:
# 获取a节点的href属性值和文本内容
print(aTag['href'],aTag.get_text())
print('----------------')
for tag in tags:
# 通过方法选择器选取节点名为a的所有节点
aTags=tag.find_all(name='a')
for aTag in aTags:
# 获取a节点的href属性值和文本内容
print(aTag['href'], aTag.string)运行结果: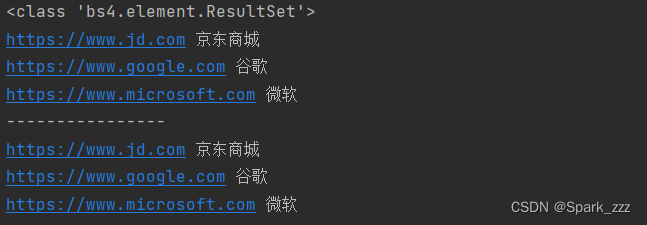















 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









