






目录
操作文件基本方法
open函数:open(文件路径,文件模式)
write(string):写入内容,该方法返回字节数
read([n]):读取文件的内容,n是整数,表示从文件指针指定的位置开始读取n个字节,如果不知道n,该方法就会读取从当前位置往后的所有字节,该方法返回读取的数据
seek[n]:重新设置文件指针,一般使用write方法写入内容后,使用seek[0],再使用read方法可以读取文件全部内容
close():关闭文件
'r' 读模式(默认)
'w'写模式
'x'排他的写模式(只能用户写)
'a'追加模式
'b'二进制模式(可以添加到其他模式)
't'文本模式(默认,可以添加到其他模式)
'+'读写模式(必须与其他模式一起使用)

读行、写行
readline方法:用于从文件指针当前位置读取一整行文本,遇到结束符停止读取文本
readlines方法:用于从文件指针当前位置读取后面所有的数据,并将这些数据按行结束符分隔后,放到列表里返回
writelines:方法需要通过参数指定一个字符串类型的列表,该方法会将列表中的每一个元素作为单独的一行写入文件
先建立一个urls.txt文件
https://geekori.com
https://geekori.com/que.php
https://edu.geekori.comimport os
f=open('urls.txt','r+')
while True:
# 读取urls.txt每一行
url=f.readline()
# 将最后的行结束符去掉
url=url.strip()
# 读取到空行时,结束循环
if url =='':
break
else:
# 输出读取的文本
print(url)
print('----------------')
# 文件指针初始化
f.seek(0)
# 读取文件指针后所有行
print(f.readlines())
# 添加一个新行
f.write('https://jiketiku.com'+os.linesep)
f.close()
f=open('urls.txt','a+')
# 定义一个列表
urlList=['https://geekori.com'+os.linesep,'https://www.google.com'+os.linesep]
# 将urlList写入urls.txt文件的列表
f.writelines(urlList)
f.seek(0)
print(f.readlines())
f.close()第一个print:
第二个print:![]()
第三个print:
['https://geekori.com\n', 'https://geekori.com/que.php\n', 'https://edu.geekori.com\n', '\n', 'https://jiketiku.com\n', '\n', 'https://geekori.com\n', '\n', 'https://www.google.com\n', '\n']
使用FileInput对象读取文件
import fileinput
# 使用input方法打开urls.txt
fileobj=fileinput.input('urls.txt')
print(type(fileinput))
# for循坏遍历其他行
for line in fileobj:
line=line.rstrip()
# 如果不是空行,输出当前行号和内容
if line !='':
print(fileobj.lineno(),':',line)
else:
# 输出当前操作的文件名,必须读取第一行后再调用,否则返回None
print(fileobj.filename())处理xml格式的数据
读取与搜索xml文件
先建立一个xml文件
<!--products.xml-->
<root>
<products>
<product uuid ="1234">
<id>10000</id>>
<name>iphone9</name>
<price>9999</price>
</product>
<product uuid ="4321">
<id>20000</id>>
<name>特斯拉</name>
<price>800000</price>
</product>
<product uuid ="5678">
<id>30000</id>>
<name>Mac Pro</name>
<price>40000</price>
</product>
</products>
</root>from xml.etree.ElementTree import parse
# 分析producs.xml文件
doc=parse('products.xml')
# 通过Xpath搜索子节点集合,然后对子节点集合迭代
for item in doc.iterfind('products/product'):
# 读取product节点的id子节点的值
id=item.findtext('id')
name=item.findtext('name')
price=item.findtext('price')
print('uuid','=',item.get('uuid'))
print('id','=',id)
print('name','=',name)
print('price','=',price)
print('--------------')
字典转化为xml字符串
import dicttoxml
from xml.dom.minidom import parseString
import os
# 定义一个字典
d=[20,'name',
{'name':'bill','age':30,'salary':2000},
{'name': '王军', 'age': 34, 'salary': 3000},
{'name': 'john', 'age': 25, 'salary': 2500},
]
# 将字典转换为xml格式(bytes形式)
bxml=dicttoxml.dicttoxml(d,custom_root='persons')
# 将bytes形式的xml数据按照utf-8编码格式解码为xml字符串
xml=bxml.decode('utf-8')
# 输出xml字符串
print(xml)
# 解析xml字符串
dom=parseString(xml)
# 生成带缩进格式的xml字符串
prettyxml=dom.toprettyxml(indent=' ')
# 创建files目录
os.makedirs('files',exist_ok=True)
# 以只写和utf-8编码格式的方式打开persons.xml文件
f=open('persons.xml','w',encoding='utf-8')
# 将格式化的xml字符串写入persons.xml文件
f.write(prettyxml)
f.close()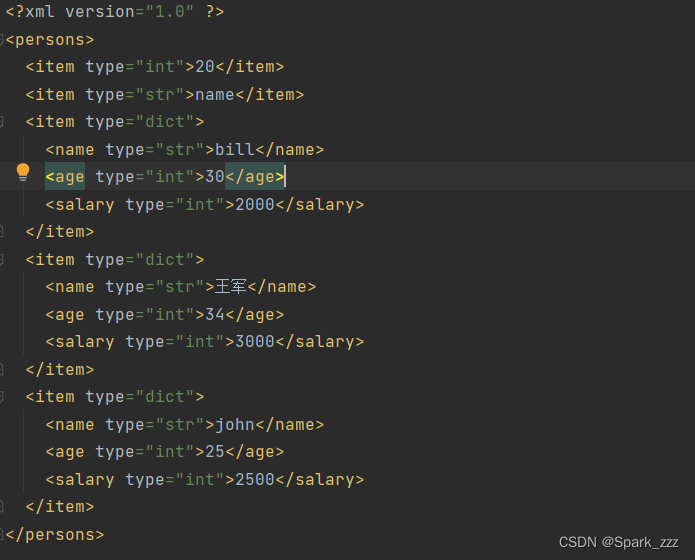
xml字符串转化为字典
import xmltodict
f=open('products.xml',encoding='utf-8')
xml=f.read()
# 分析xml字符串,并转化为字典
d=xmltodict.parse(xml)
# 输出字典内容
print(d)
f.close()
import pprint
print(d)
pp=pprint.PrettyPrinter(indent=4)
pp.pprint(d)处理json格式的数据
json字符串与字典互换
import json
# 定义一个字典
data={
'name':'bill',
'company':'microsoft',
'age':34
}
# 将字典转换为json字符串
jsonStr=json.dumps(data)
# 输出jsonStr变量的类型
print(type(jsonStr))
# 输出json字符串
print(jsonStr)
# 将json字符串转换为字典
data=json.loads(jsonStr)
print(type(data))
print(data)
print('--------------')
# 定义一个json字符串
s="""
{
'name':'bill',
'company':'microsoft',
'age':34
}
"""
# 使用eval函数将json字符串转换为字典
data=eval(s)
print(type(data))
print(data)
# 输出字典中的key为company的值
print(data['company'])eval函数和loads函数都可以将json字符串转换为字典,建议用loads函数进行转换,因为eval函数可以执行任何python代码,如果json字符串包含有害python代码,执行json字符串可以带来风险
将json字符串转换为类实例
1.指定类:loads函数会自动创建指定类的实例,并将json字符串转换成字典通过类得构造方法传入类实例,也就是说,指定类必须有一个可以接受字典的构建方法;
2.指定回调函数:loads函数会调用回调函数返回类实例,并将有json字符串转换成字典传入回调函数,也就是说,回调函数也必须有一个参数可以接收字典
都是由loads函数将json字符串转换成字典,然后从字典转换为对象
import json
class Product:
# d参数是要传入的字典
def __init__(self,d):
self.__dict__=d
# 打开product.json文件
f=open('products.json')
jsonStr=f.read()
# 通过制定类的方式将json字符串转换为Product对象
my1=json.loads(jsonStr,object_hook=Product)
# 下面3行代码输出Product对象中对应属性的值
print('name','=',my1.name)
print('price','=',my1.price)
print('count','=',my1.count)
print('---------------')
# 定义用于将字典转换为Product对象的函数
def json2Product(d):
return Product(d)
# 通过指定类回调函数的方式将json字符串转换为Product对象
my2=json.loads(jsonStr,object_hook=json2Product)
# 下面3行代码输出Product对象中相关属性的值
print('name','=',my2.name)
print('price','=',my2.price)
print('count','=',my2.count)
f.close()将类实例转换为json字符串
dumps函数不仅可以将字典转换为json字符串,还可以将类实例转换为json字符串
dumps函数需要通过default关键字参数指定一个回调函数,在转换的过程中,dumps函数会向这个回调函数传入类的实例(通过dumps函数第1个参数传入),而回调函数的任务是将传入的对象转换为字典,然后dumps函数再将由回调函数返回的字典转换为json字符串.
import json
class Product:
def __init__(self,name,price,count):
self.name=name
self.price=price
self.count=count
# 用于将Product类的实例转换为字典的函数
def product2Dict(obj):
return {
'name':obj.name,
'price':obj.price,
'count':obj.count
}
# 创建Product类的实例
product=Product('特斯拉',10000000,20)
# 将Product类的实例转换为json字符串,ensure_ascii关键字参数的值设为True,
# 可以让返回的json字符串正常显示中文
jsonStr=json.dumps(product,default=product2Dict,ensure_ascii=False)
print(jsonStr)类实例列表与json字符串互相转换
import json
class Product:
def __init__(self,d):
self.__dict__=d
f=open('products.json',encoding='utf-8')
jsonStr=f.read()
# 将json字符串转换为Product对象
product=json.loads(jsonStr,object_hook=Product)
# 输出Product对象相关属性
for p in product:
print('name','=',p.name)
print('price','=',p.price)
print('count','=',p.count)
f.close()
# 定义将Product对象转换为字典的函数
def product2Dict(p):
return {
'name':p.name,
'price':p.price,
'count':p.coujnt
}
jsonStr=json.dumps(product,default=product2Dict,ensure_ascii=False)
print(jsonStr)将json格式字符串转换成xml字符串
import json
import dicttoxml
f=open('products.json',encoding='utf-8')
jsonStr=f.read()
d=json.loads(jsonStr)
print(d)
xmlStr=dicttoxml.dicttoxml(d).decode('utf-8')
print(xmlStr)
f.close()CSV文件储存
写入csv文件
writerow方法将数据写入CSV文件,使用得是列表类型的数据
默认字段的分隔符是逗号(,),如果要修改分隔符,需要使用writer类构建方法的delimiter参数
如果数据源是多条记录,数据集如果是一个列表,列表的每一个元素是一条记录(一个列表,)可以使用writerows方法写入一个数据集
import csv
with open('data.csv','w',encoding='utf-8') as f:
writer=csv.writer(f)
write = csv.writer(f, delimiter=';')
write.writerow(['filed1','filed2','filed3'])
write.writerows([['data1','data2','data3'],
['data21', 'data22', 'data23']])数据源可以自描述,字段与数据可以混在一起
通过字典描述,需要用到DictWriter对象的writerow方法将这样的数据写入CSV文件
通过下面代码可以看到
写入的数据是一个字典类型的值,key字段名,value字段值
注意:字典的key与DictWriter类构造方法的fieldnames参数指定的字段名一致,否则抛出异常
import csv
with open('data.csv','w',encoding='utf-8') as f:
fieldnames=['filed1','filed2','filed3']
writer=csv.DictWriter(f,fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'filed1':'data11','filed2':'data12','filed3':'data13'})
writer.writerow({'filed1': 'data21', 'filed2': 'data22', 'filed3': 'data23'})读取csv文件
import csv
with open('data.csv','r',encoding='utf-8') as f:
# 创建reader对象
reader=csv.reader(f)
# 读取每一行数据
for row in reader:
print(row)
print('-----------')
# 导入pandas模块
import pandas as pd
# 读取data.csv文件数据
df=pd.read_csv('data.csv')
print(df)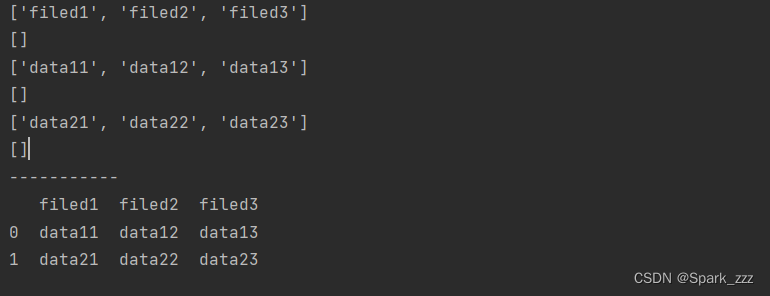
结言
xml文件、json文件、csv文件本质上都是纯文本文件
只是数据组织形式不同
最常用的是json文件和csv文件,因为他们数据冗余较小,适用于网络传输















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









