






一、SPSS结果
差异性分析方法(t检验、方差分析、卡方分析、非参数分析)
1.描述性分析(平均数/方差/标准差/频率分布直方图/P-P图/Q-Q图/偏度和峰度)
1.频率分布直方图
2.P-P图和Q-Q图
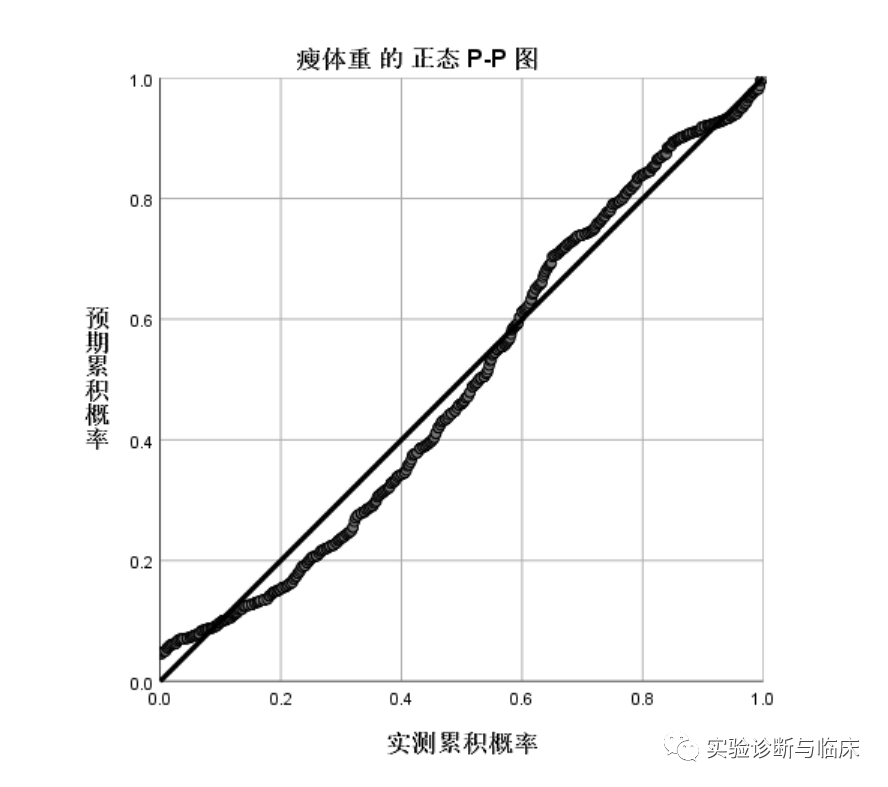
P-P图:反映的是数据的实际累积概率与假定所服从分布(这里即正态分布)的理论累积概率的符合程度。
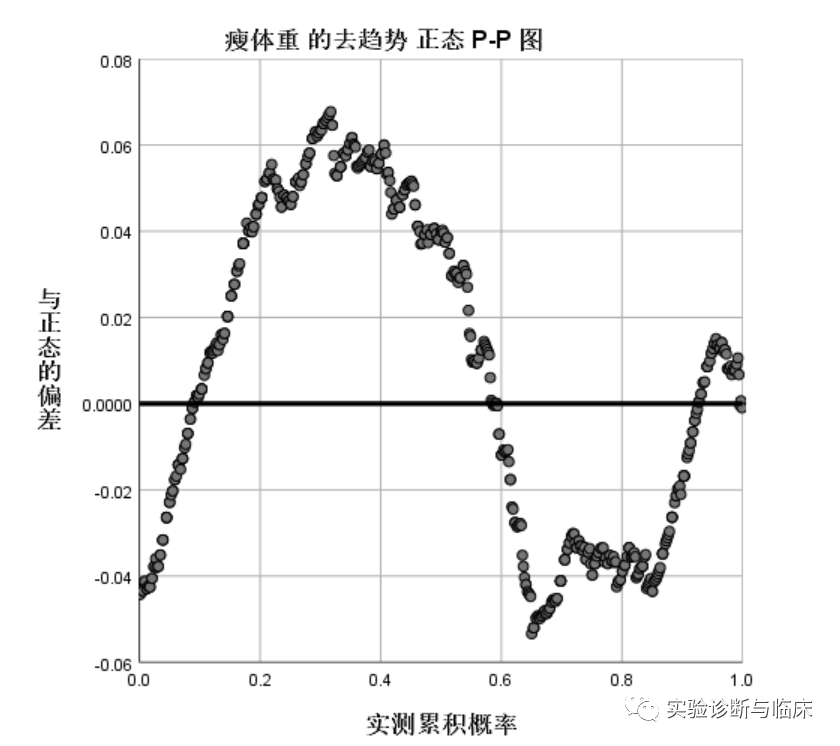
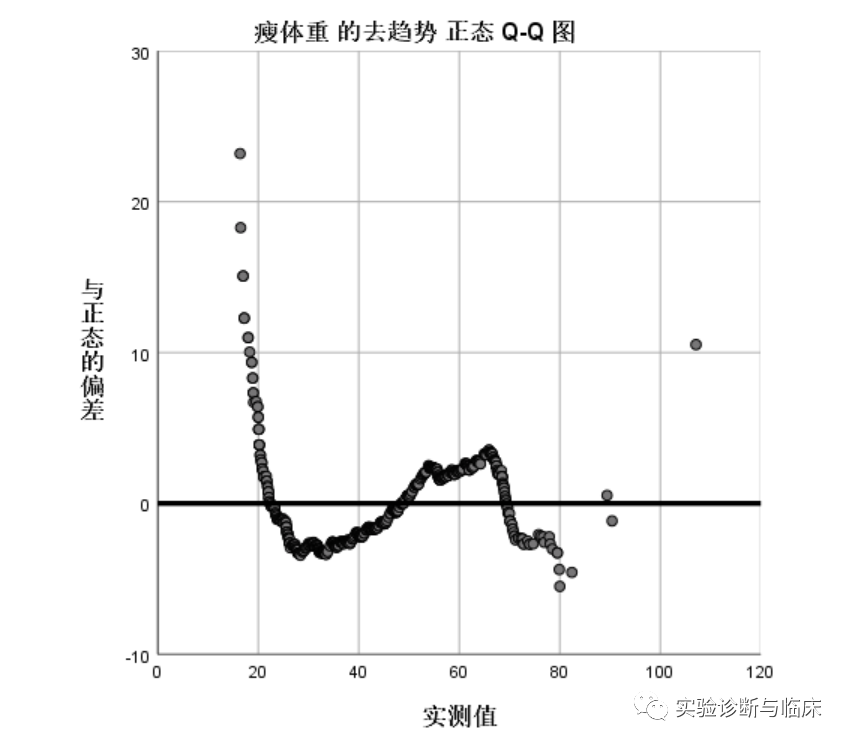
去趋势的正态P-P图:纵坐标轴是理论值与实际值的偏差,可以理解为分布的残差图。图中的点均值地散落在Y=0上,绝对偏差值较小,可说明数据是服从正态分布。
【SPSS操作】
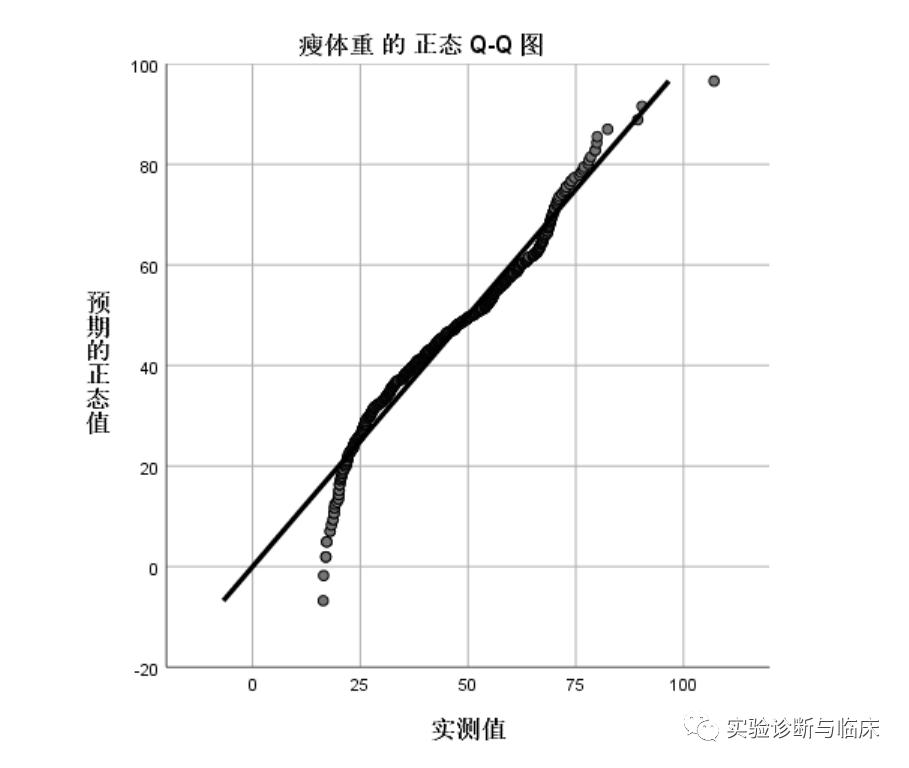
Q-Q图:考察的是实际百分位数与假定所服从分布的理论百分位数的差异。
3.偏度和峰度
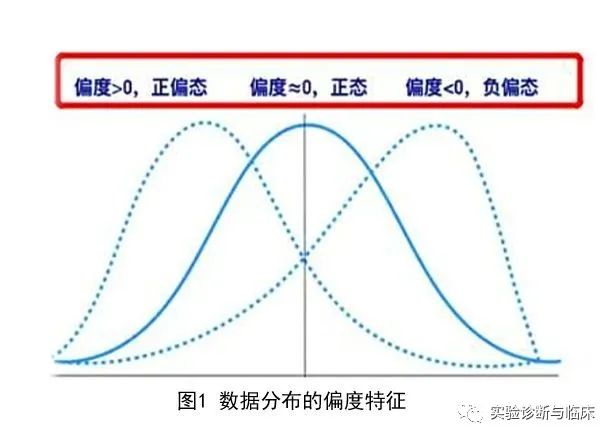
偏度主要用于判断数据的偏斜程度。偏度S>0,拖尾在右边,为正偏态,偏度S<0,拖尾在左边,为负偏态,偏度S≈0为正态,绝对值越大,偏态越严重。
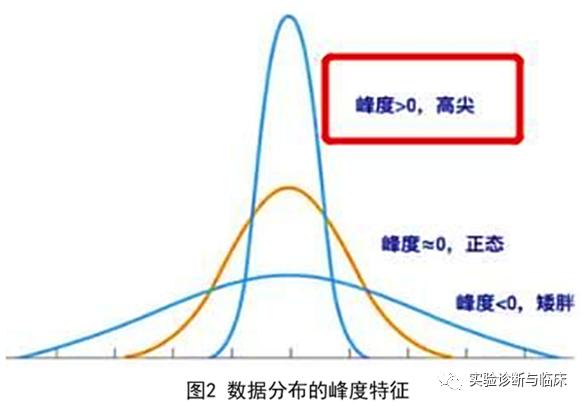
峰度是用于判定数据分布的陡缓程度。当峰度K>0时,分布的峰态陡峭(高尖),当峰度K<0时,分布的峰态平缓(矮胖),当K≈0时,可认为数据服从正态分布(不胖不瘦)。
【SPSS操作】
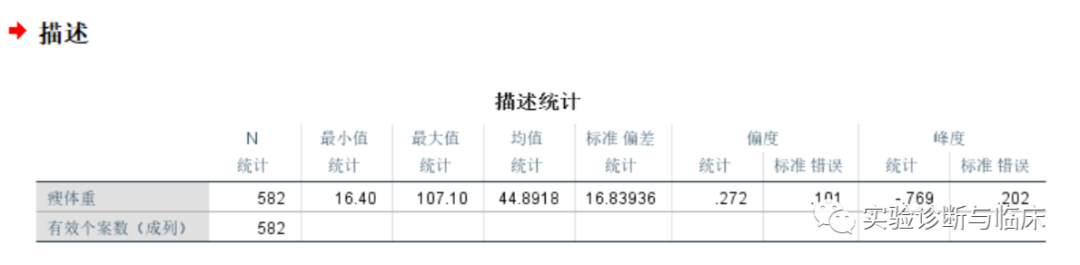
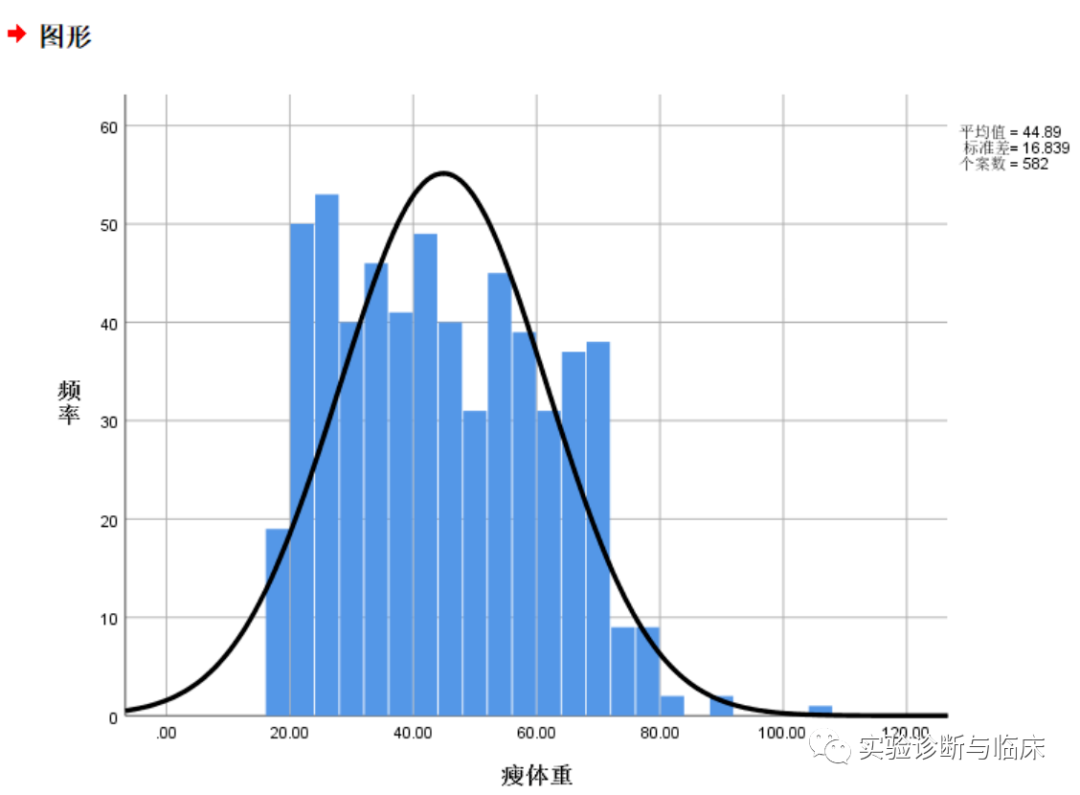
如图我们可以得到瘦体重数据的偏度S=0.272,峰度K=-0.769。其实我们还可以进一步检验S和K与0的差异有无统计学意义,计算出偏度系数和峰度系数,检验公式如下:

注:SS和SK分别是S和K的标准误,经计算,偏度系数Zs=2.69,峰度系数Zk=3.81,均大于1.96,在α=0.05的情况下,可认为S、K与0有显著性差异,即数据非正态。
2.信度分析
信度(reliability)即可靠性,它指的是采取同样的方法对同一对象重复进行测量时,其所得结果相一致的程度。从另一方面来说,信度就是指测量数据的可靠程度。
Spss操作步骤:选择“分析”—“标度”—“可靠性分析”,将量表题放入"项"中,点击确认。
若Cronbach α系数大于0.7时,证明一致性高,可信度高。其中,0.7-0.8说明信度一般,0.8-0.9认为信度比较好,0.9以上说明信度很好。
3.效度分析(因子分析/主成分因子分析 / 探索性因子分析 / 验证性因子分析)
(1)主成分分析
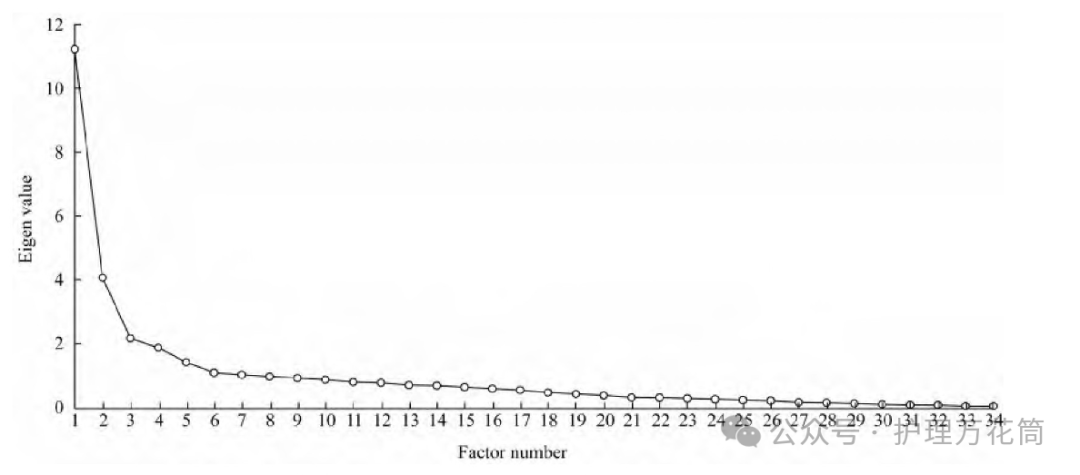
主成分分析(PCA)是一种数据降维技巧,它能将大量相关变量转化为一组很少的不相关变量,这些无关变量称为主成分。常用碎石图呈现。
(2)探索性因子分析
探索因子分析(exploratory factor analysis,EFA)是一系列用来发现一组变量的潜在结构的方法。通过寻找一组更小的、潜在的或隐藏的结构来解释已观测到的、显示的变量间的关系。这些虚拟的、无法观测的变量称作因子,每个因子被认为可解释多个观测变量间共有的方差,因子又可称为公共因子。
(3)验证性因子分析
效度(Validity)即有效性,它是指测量工具或手段得出结论与现实所需测量的事物事实的对应程度。
Spss操作步骤:
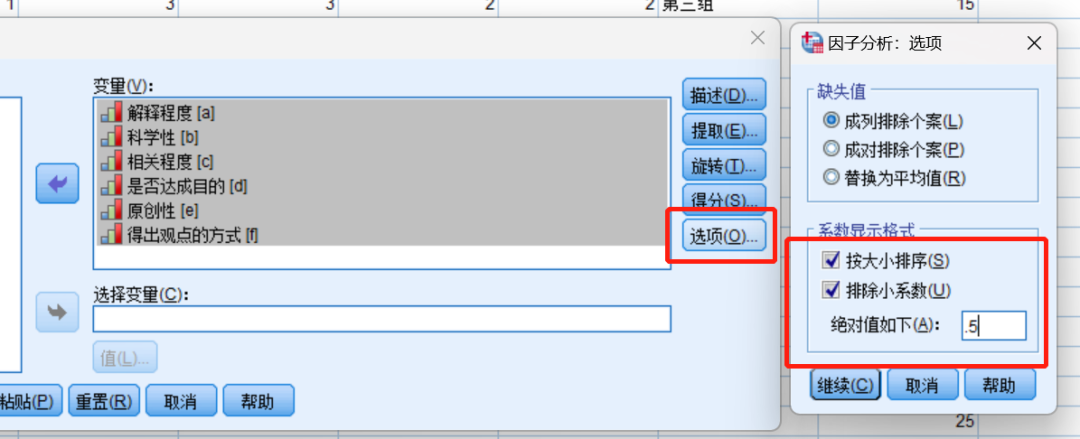
1选择“分析”—“降维”—“因子”,2将量表题放入"项"中,点击确认。3对描述、提取、旋转、选项分别进行参数设置。4 其中,设置“选项”中,绝对值一般设为0.5或0.6
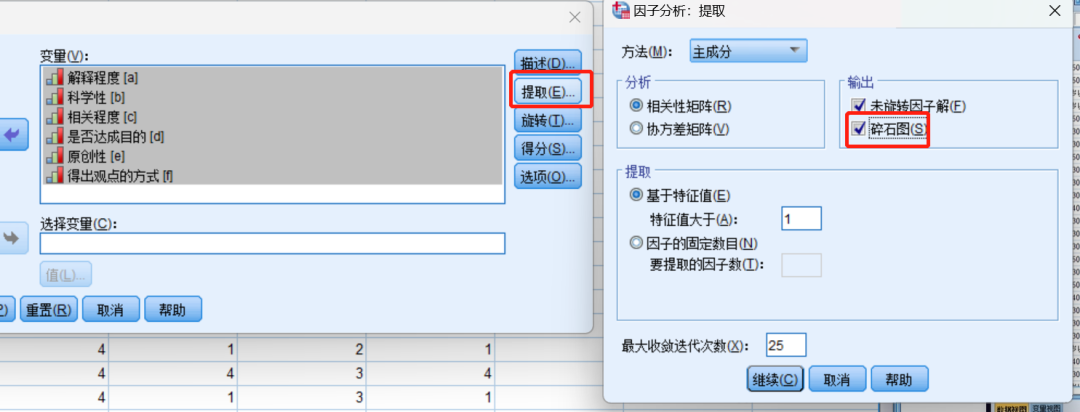
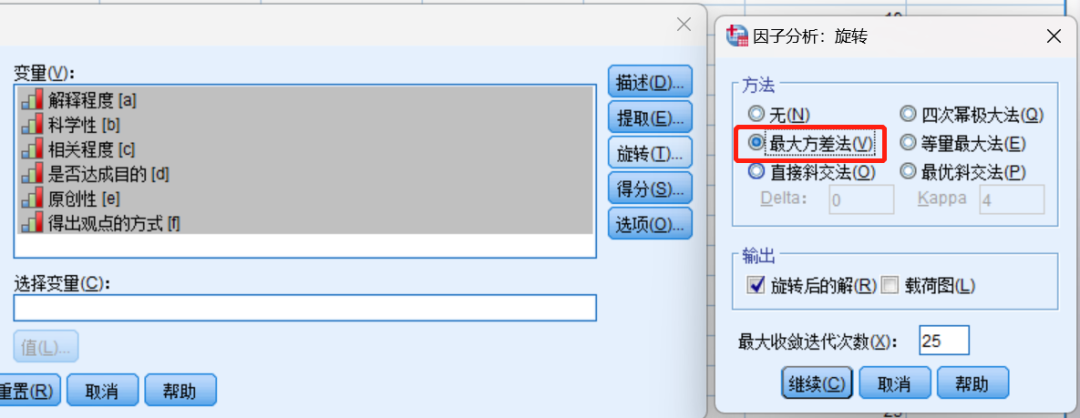
 1 看“KMO和P值”(考察数据是否可以进行因子分析)。
1 看“KMO和P值”(考察数据是否可以进行因子分析)。
如果KMO>0.6且和P<0.05,说明可以做因子分析,否则无法做效度分析。(对数据有要求,需要达到一定的关联性)
2 看“总方差分析”。
“总计”列大于1的,个数定为公因子数,下图为2个,即代表量表内可划分为2个维度,并查看最大累计值即最后一个,大于60%,则意味分为两个维度是可靠的。

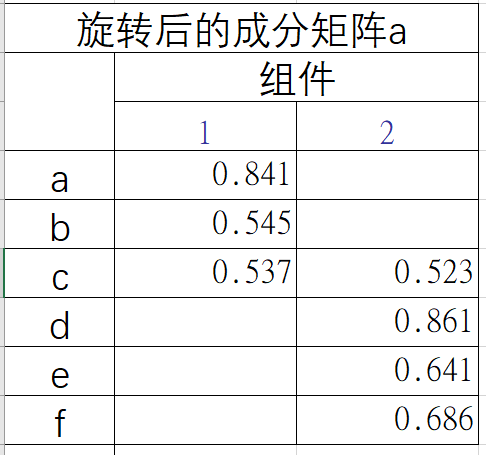
3看“旋转后的成分矩阵”。
具体题项的维度划分,大于0.05既满足,其中a、b属于维度1,d、e、f属于维度2,但c项维度1、2均满足,属于无效题项应舍去。
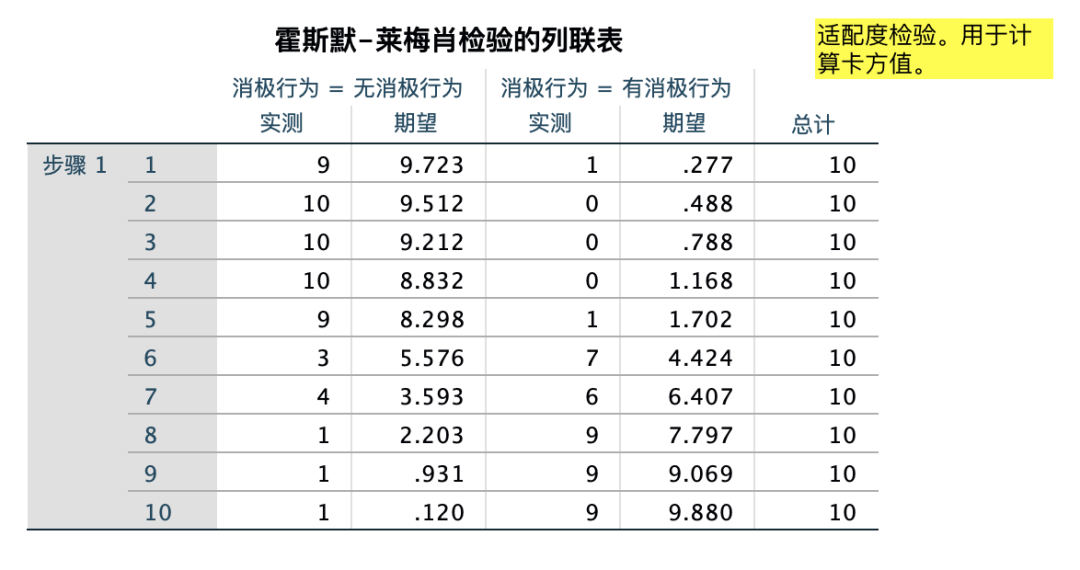
4.卡方检验(交叉分析)
在Spss里面交叉分析和卡方检测是放在一起的!!!无论用哪种方法都会生成两张表,交叉表是为了告诉你卡方检测看哪个方面的数据!!!
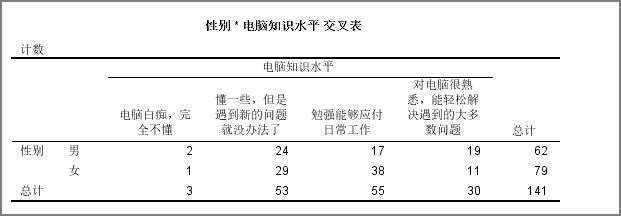
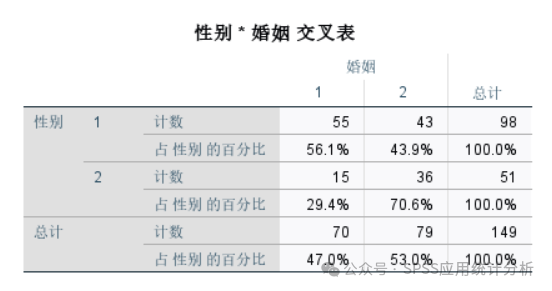
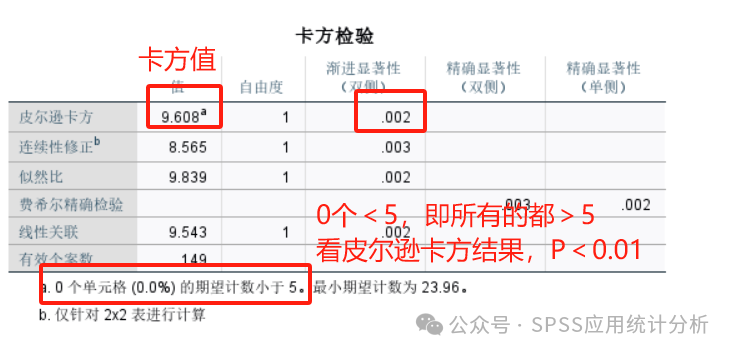
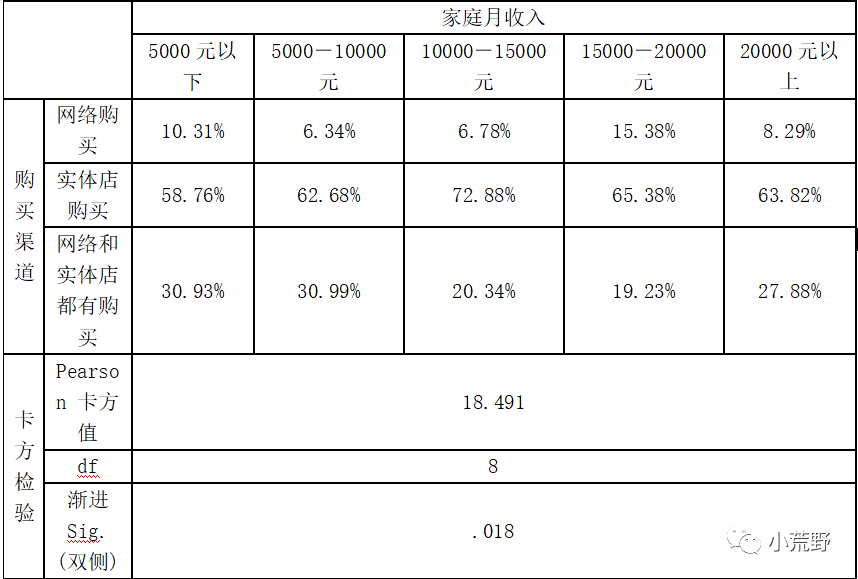
第一个表是交叉分析表:交叉表给出了两个分类变量的不同选项组合下的频数。要注意观察表格中是否存在单元格数量小于5的情况,如果存在,那么后续看卡方检验结果的时候就应该看Fisher精确检验的结果。本案例中,我们应该看Fisher精确检验的结果,因为存在单元格频数小于5的情况。
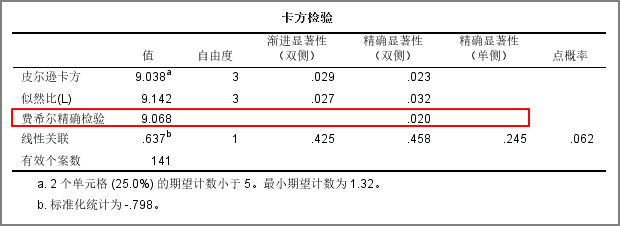
第二个表是卡方检验结果表:卡方检验结果表给出了不同检验的结果。如果上面的频数分析表中,不存在单元格频数小于5的情况,那么应该看下表中的第一行,即【皮尔逊卡方】这一行,注意其中的渐进显著性值,也就是卡方检验的p值,如果小于0.05,则认为两个变量之间存在显著相关关系。
本案例中因为存在单元格频数小于5的情况,则应该使用Fisher精确检验结果,即看【费舍尔精确检验】这一行,注意其中的精确显著性,也即Fisher精确检验的p值,此处p值小于0.05,即认为上面分析的两个分类变量之间是有显著相关关系的:性别会影响电脑知识水平,即不同性别的人电脑知识水平是不同的。
不同性别(男/女)人群在婚姻(已婚/未婚)上是否存在差异?
性别中,1和2分别代表男和女;婚姻中,1和2分别代表已婚和未婚
当样本量“n≥40”且所有单元格的期望频数“Eij≥5”时,看皮尔逊卡方检验结果。当样本量“n≥40” 且“1≤Eij<5”时,看连续性校正的卡方检验结果。当期望频数“Eij<1”或总样本量“n<40”,使用Fisher’s(费希尔精确)检验结果。
当样本量“n≥40”且所有单元格的期望频数“Eij≥5”时,看皮尔逊卡方检验结果。当样本量“n≥40” 且“1≤Eij<5”时,看连续性校正的卡方检验结果。当期望频数“Eij<1”或总样本量“n<40”,使用Fisher’s(费希尔精确)检验结果。
下面这个步骤和上面相同可不看
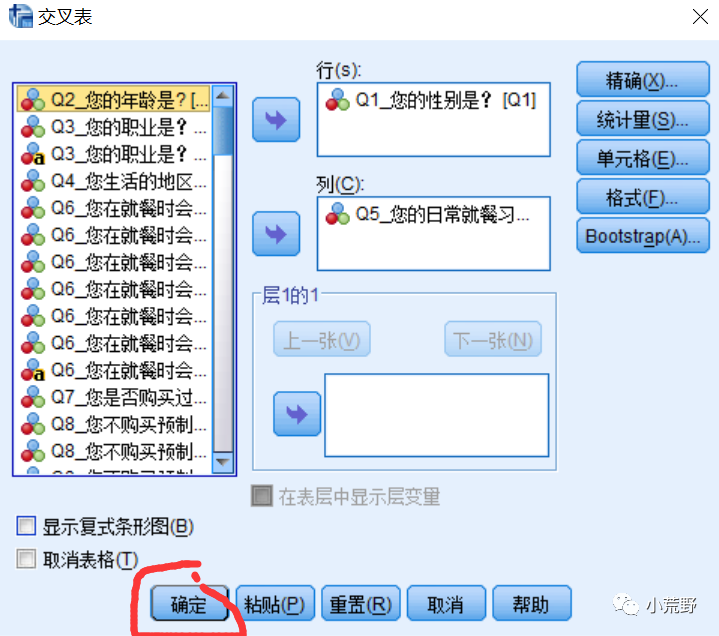
ps:交叉表提供两个变量之间的相互关系的基本画面。(选择你认为两个有关系的变量)
统计量--卡方--继续
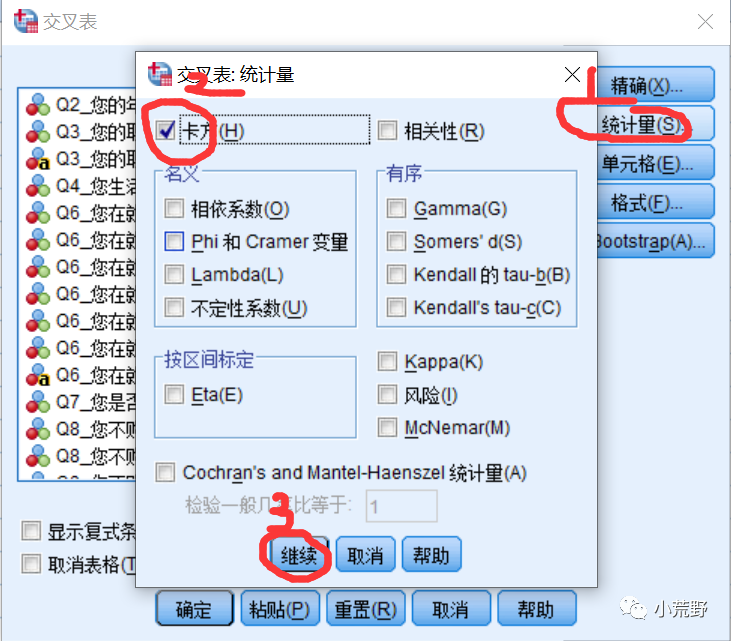
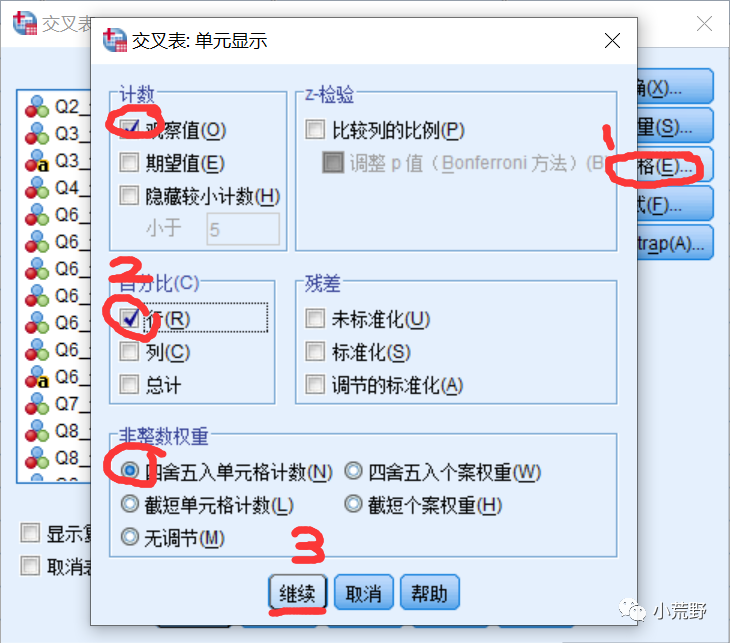
统计量--卡方--继续

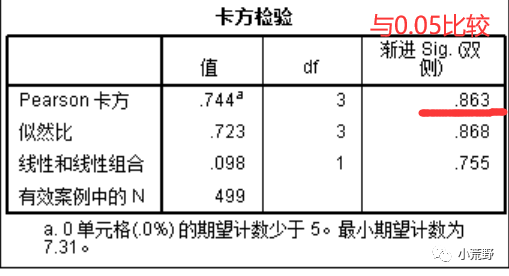
(卡方检验中的两个变量的渐进sig值大于0.05,两个变量没有关系,所以要重新找有关系的两个变量。)
(卡方检验中的两个变量的渐进sig值大于0.05,两个变量没有关系,所以要重新找有关系的两个变量。)
5.T检验(独立样本T检验)
独立样本t检验是在两个群体之间进行均值差异的检验
菜单【分析】中【比较平均值】,选择【独立样本T检验】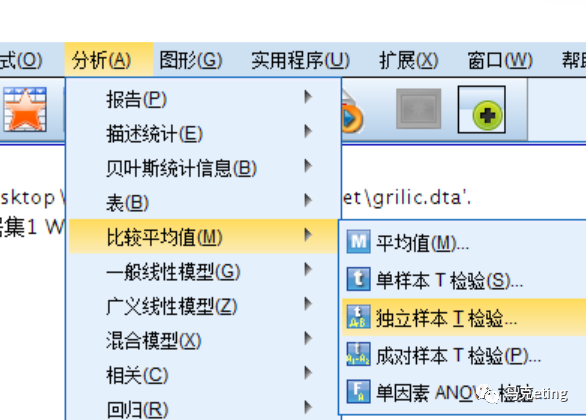
将连续变量拖入到【检验变量】,类别变量放入【分组变量】,选择【定义组】,组1和组2的值与你的类别变量的值一致,如果南方是1,北方是0,则组1的值为0,组2的值为1。弄好后就可以点击确定 ,进行分析。
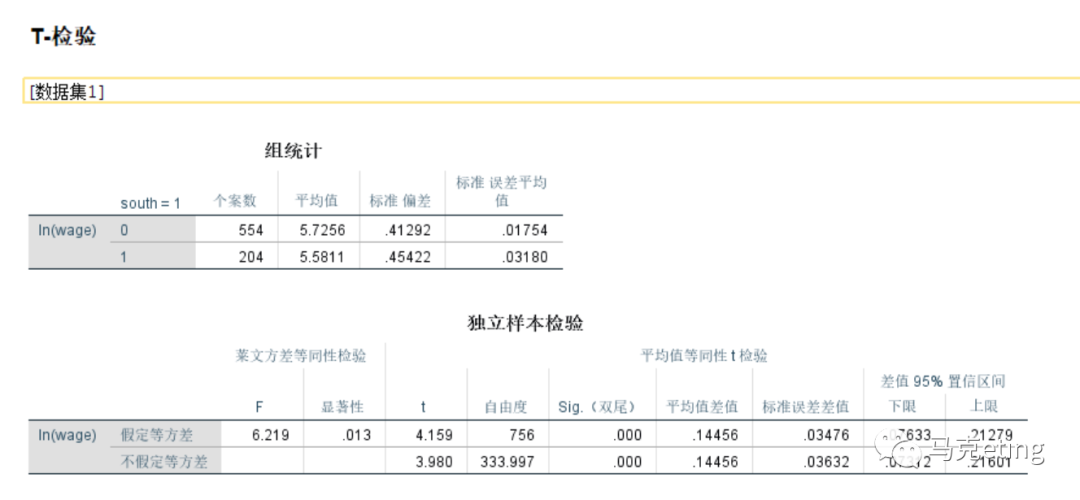
【组统计】的结果解读:各群体之间的描述统计,包括样本量、平均值、标准差
【独立样本检验】的结果解读:包括莱文方差等同性检验和平均值等同性t检验,莱文方差等同性检验看显著性,小于0.05表示两个群体之间的方差不相等。图中显著性为0.013,表明南北方的收入的方差不相等。方差不等即独立样本t检验的前提假设不成立,此时看第二行方差不等下的平均值等同性t检验,其显著性为0.000,表示拒绝了南北方的平均收入相等的假设,即南北方的平均收入不相等。
独立样本t检验先看【莱文方差等同性检验】的【显著性】结果,显著性小于0.05则看第二行的【不假定等方差】,再看【平均值等同性t检验】的【显著性】结果,小于0.05表示两个群体之间的变量平均值存在差异。
6.方差分析(ANOVA/单因素方差分析)
独立样本t检验是在两个群体之间进行均值差异的检验
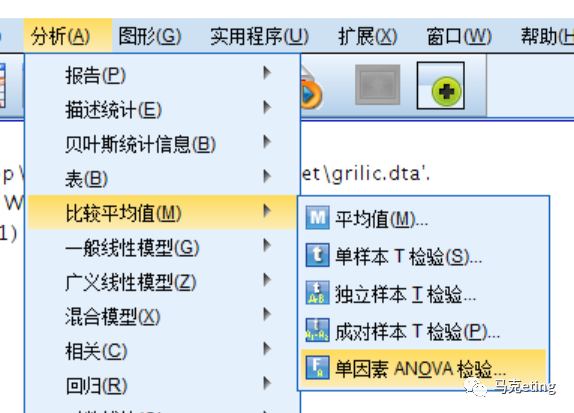
将连续变量(如收入)拖入到【因变量列表】,将各群体(如学龄)拖入到因子
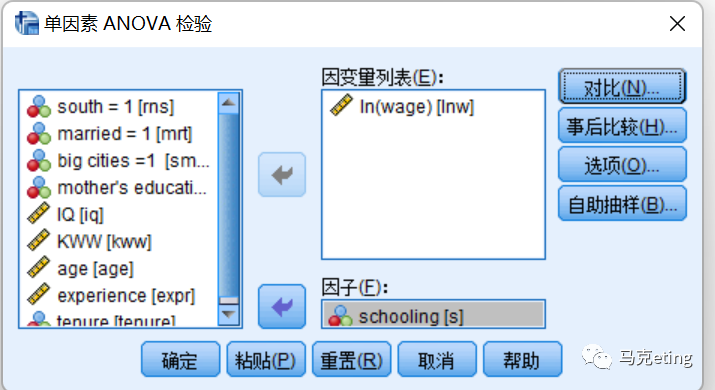
点击【事后比较】,勾选【雪费】;点击【选项】,勾选【方差齐性检验】。完事后点击确定,进行分析
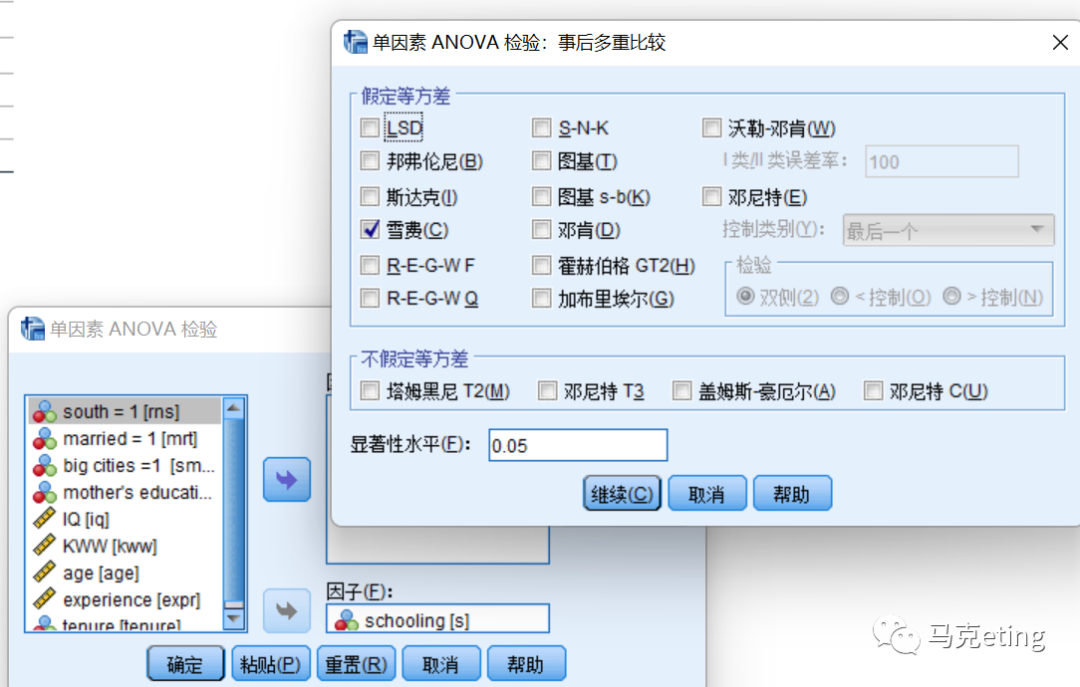
【方差齐性检验】结果解读:看【基于平均值】所在行即可,【显著性】小于0.05表示拒绝方差相等的假设,即不同群体之间的变量方差不相等。如图中显著性为0.221,说明不同学龄的人群的收入方差相等。方差不等时应选择方差不等的多重比较方法。
【ANOVA】结果解读:主要看【组间】的【显性著】,显著性小于0.05表示不同群体间的变量均值存在差异,但是我们不知道是哪两个群体之间存在均值差异,这要看【多重比较】的结果。如图中显著性为0.000,说明不同学龄的人群的平均收入存在差异。
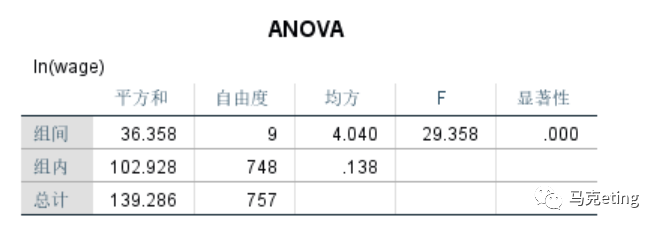
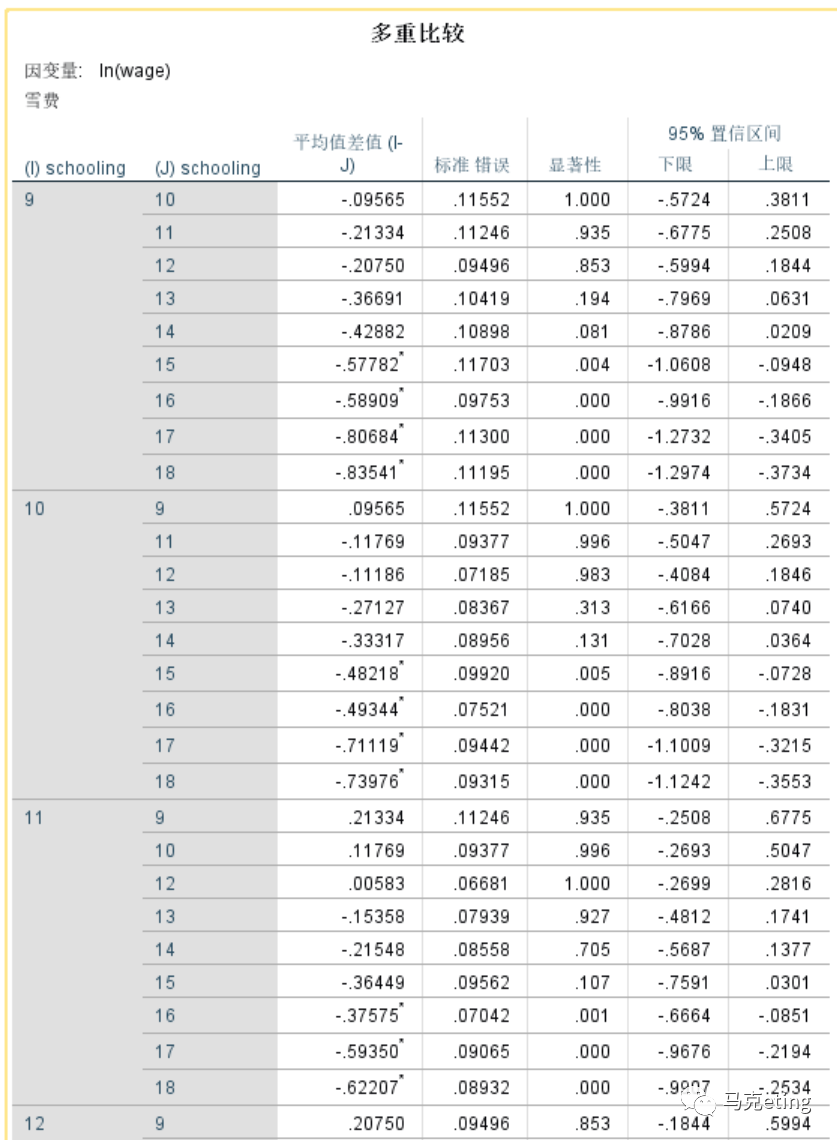
【多重比较】:第一列表示不同学龄的群体,第二列是要一一比较均值的群体,第三列是第一列的变量均值减去第二列的变量均值,第四列不用看,第五列为显著性。首先看【显著性】那一列,找出所有显著性小于0.05的行,表示那一行对应的两个群体之间的平均值存在差异。如图中学龄为9年的群体,与学龄为15年的群体存在均值差异(显著性为0.000)。
7.回归检验(线性回归/逻辑回归/Logistic回归/多元线性回归)
(1)线性回归

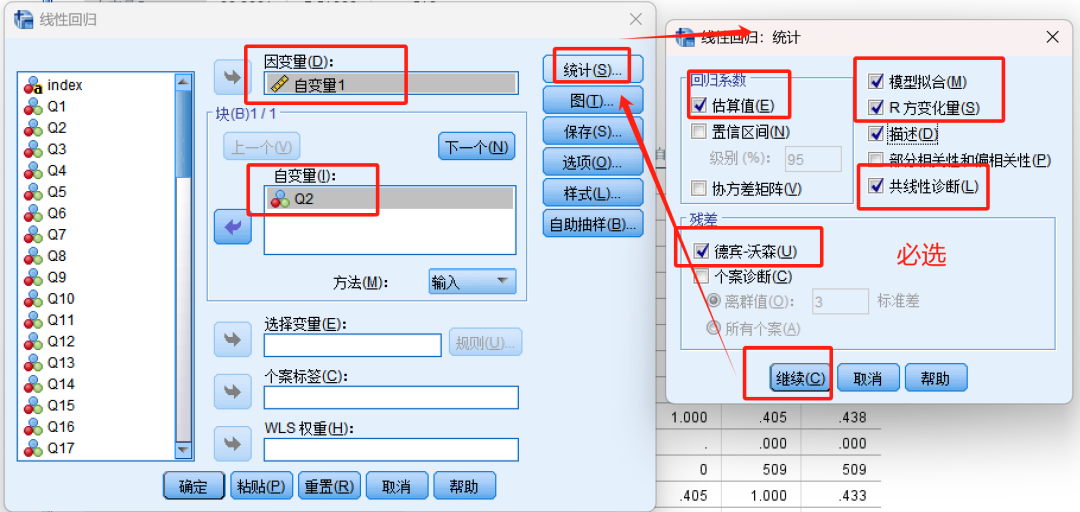
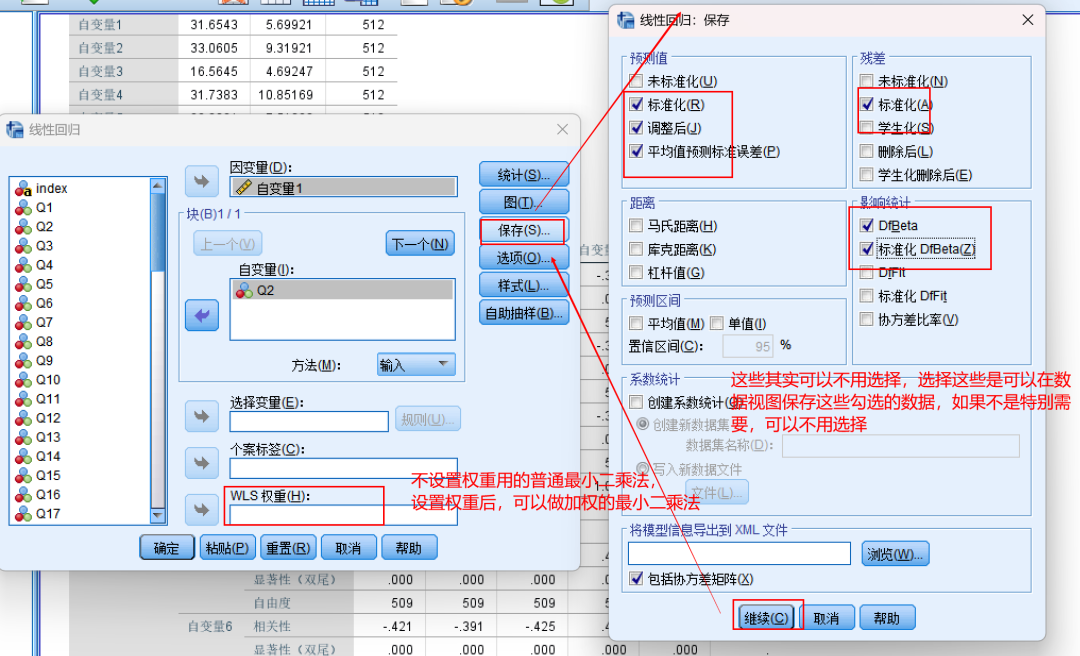
点击“确定”选项卡后,会出现最终结果,其中最重要的几个结果是“模型摘要”、“ANOVA分析”、“系数”和“共线性诊断”(多元线性回归需要)。
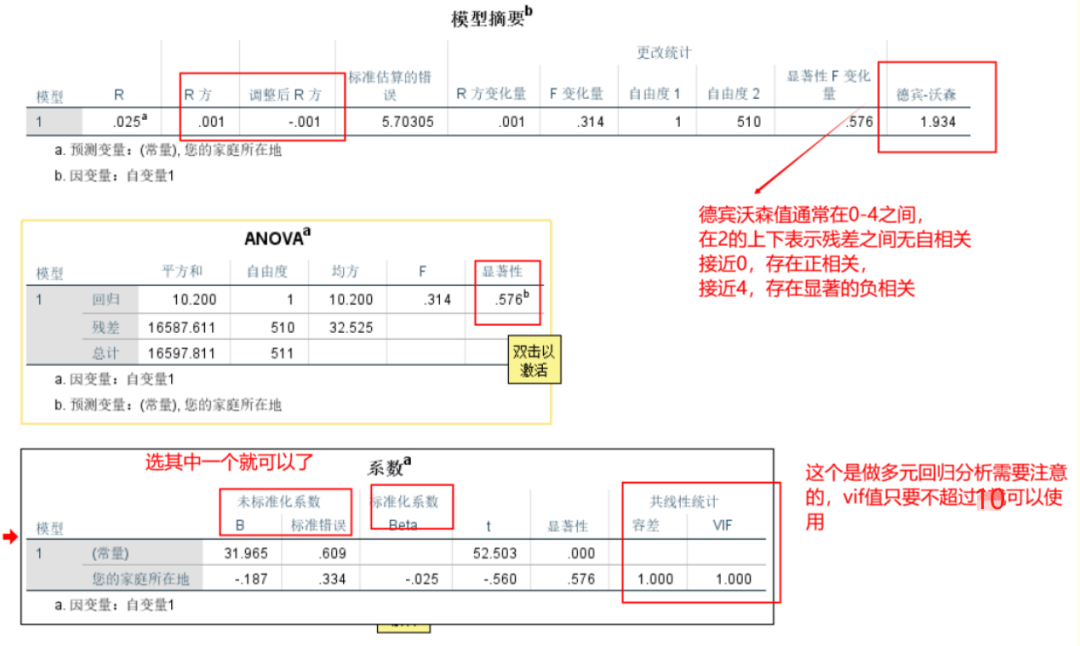
点击“确定”选项卡后,会出现最终结果,其中最重要的几个结果是“模型摘要”、“ANOVA分析”、“系数”和“共线性诊断”(多元线性回归需要)。
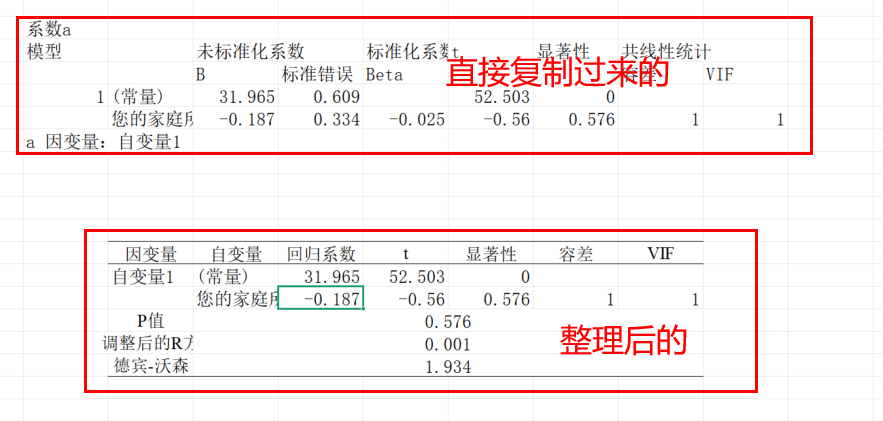
(2)多元线性回归(多元回归分析)
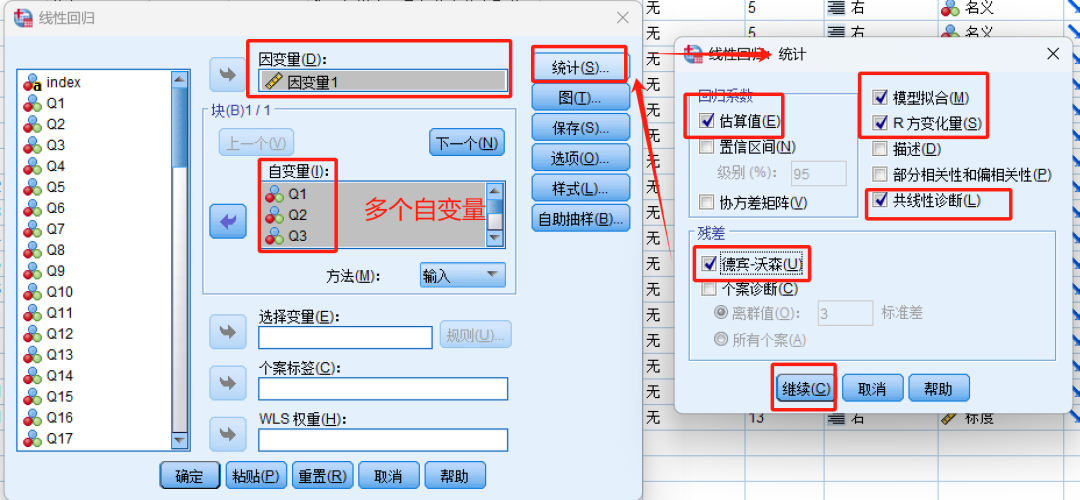
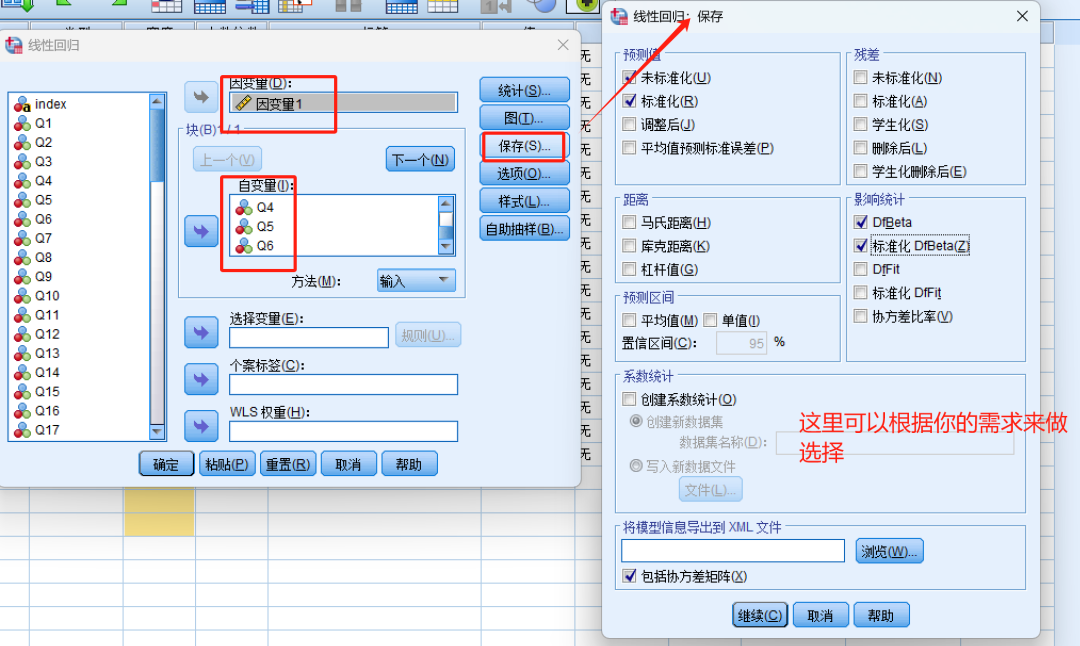
点击“确定”选项卡后,会出现最终结果,其中最重要的几个结果是“模型摘要”、“ANOVA分析”、“系数”和“共线性诊断”(多元线性回归需要)。
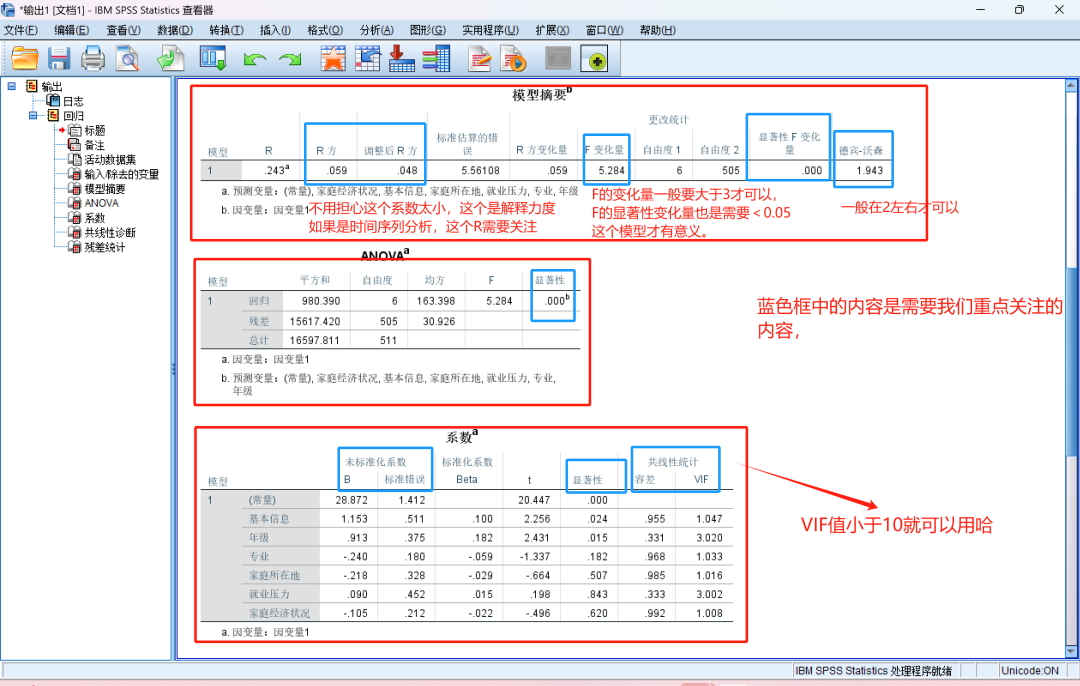
点击“确定”选项卡后,会出现最终结果,其中最重要的几个结果是“模型摘要”、“ANOVA分析”、“系数”和“共线性诊断”(多元线性回归需要)。
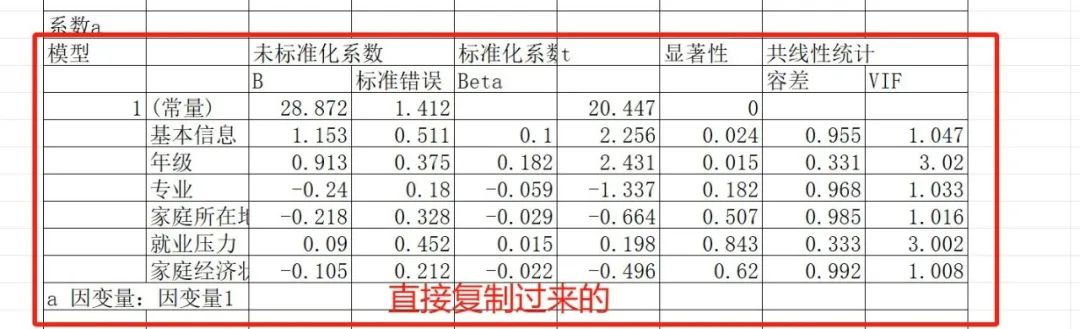
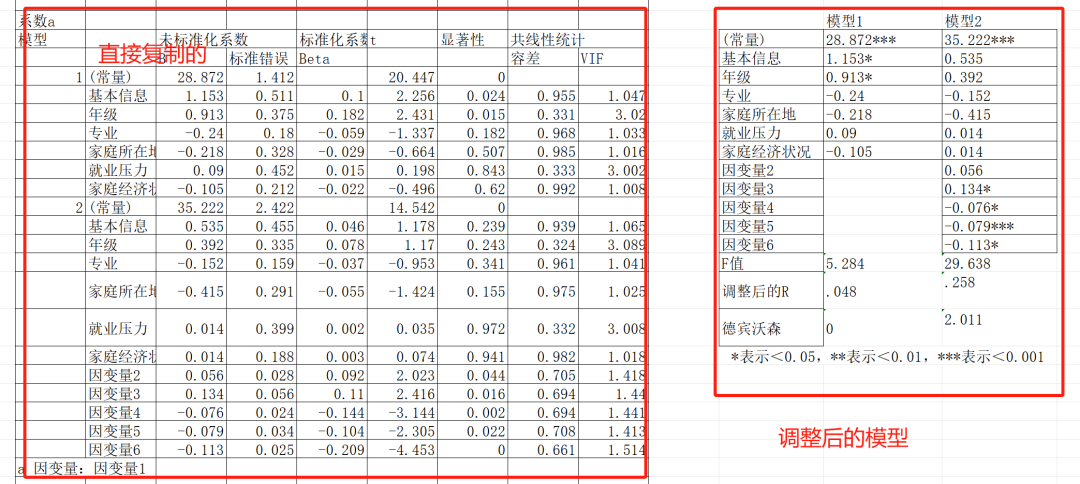
在仅包含性别和年级的基础模型(模型1)中,性别( p < .05)和年级(β p < .01)对因变量1具有显著正向预测作用
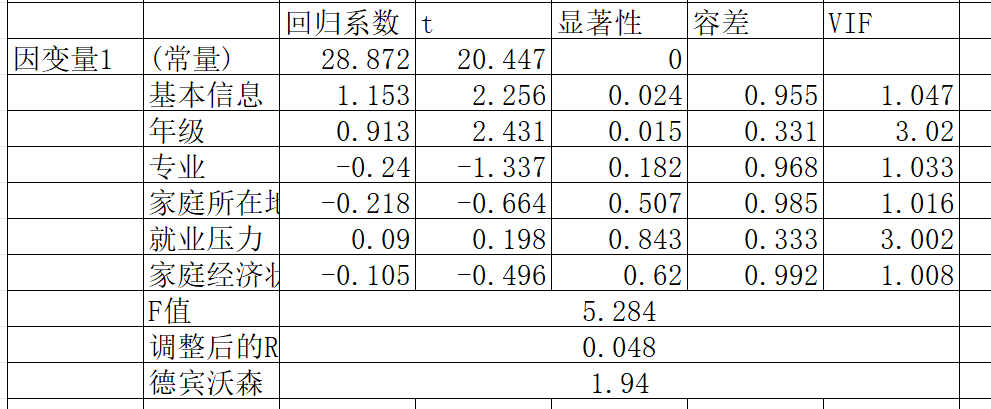
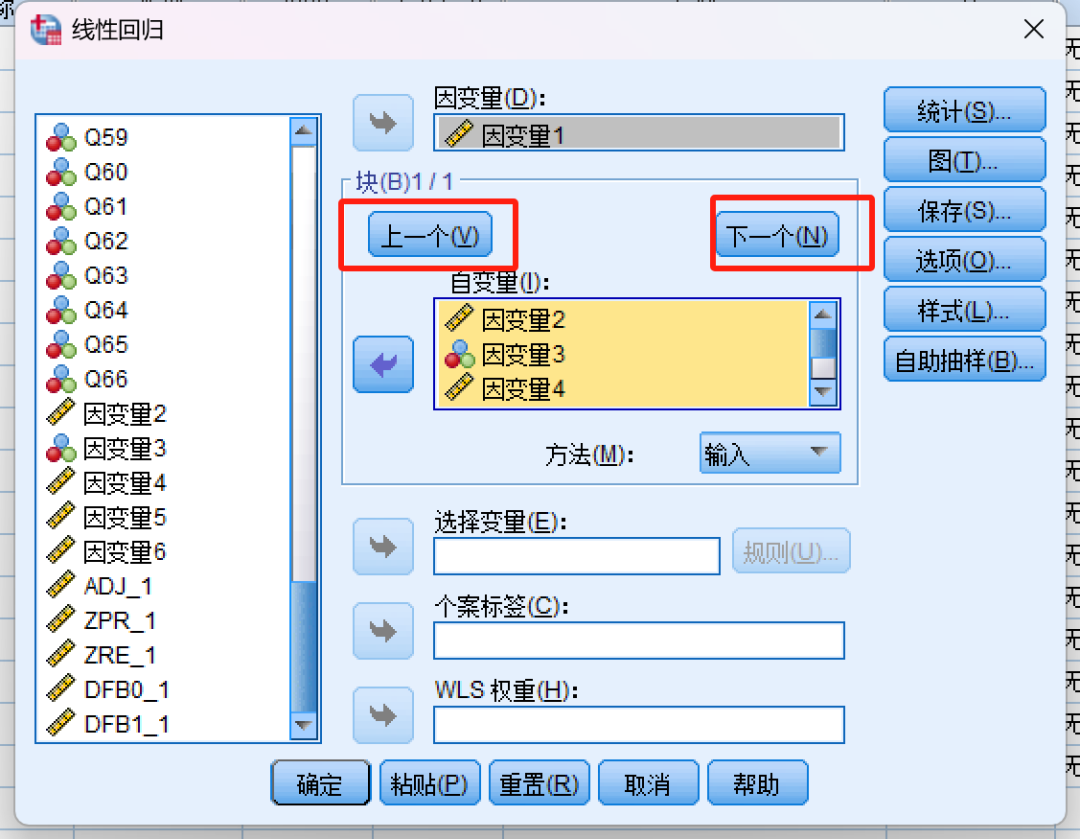
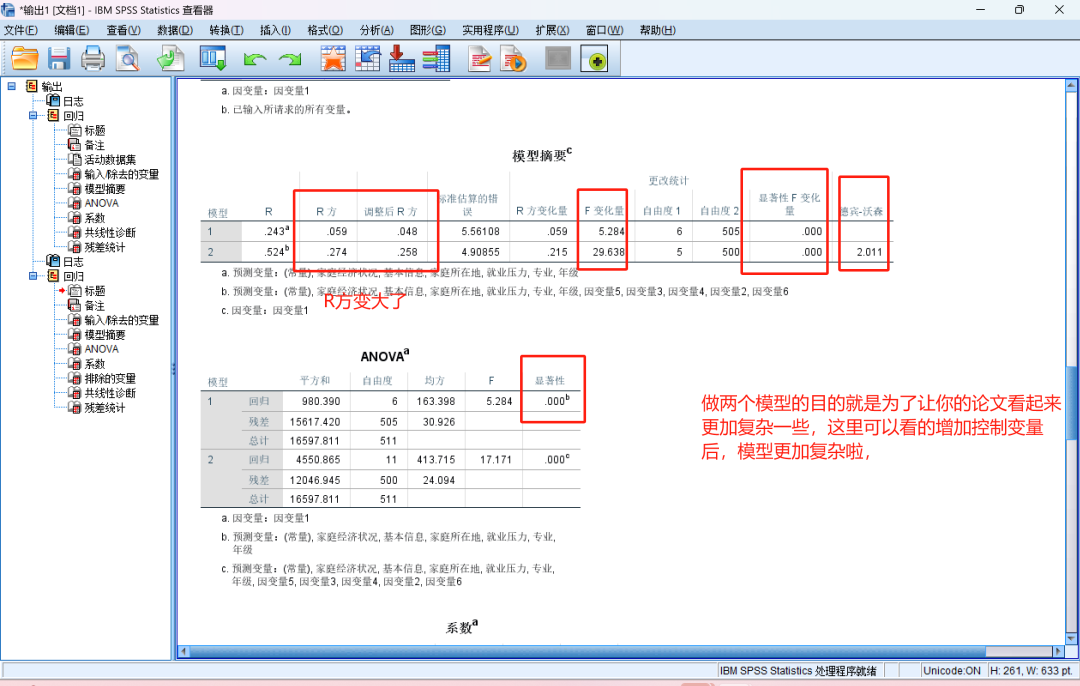
当引入因变量3、4、5、6构建扩展模型(模型2)后,性别和年级的效应不再显著(p > .050),而因变量5表现出最强的预测力( p < .001),其次是因变量4(p < .01)和因变量3、6( p < .05)。模型2的调整R²显著高于模型1( p < .001),表明新增变量对因变量1的解释具有增量效度。
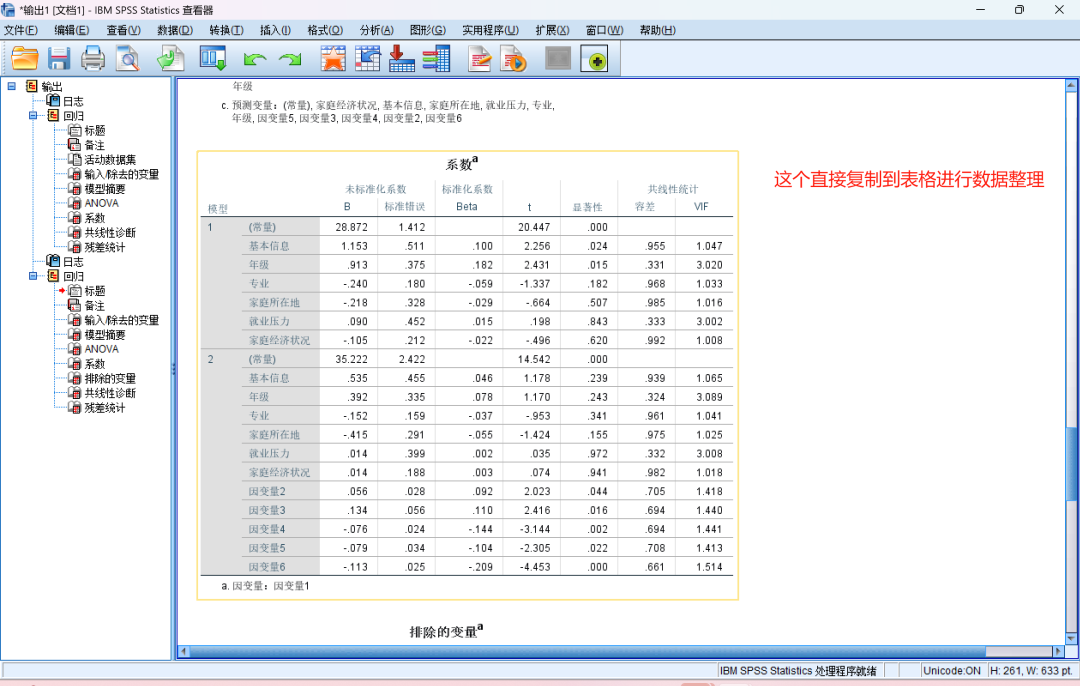
解读一下结果,分层回归分析显示,在仅包含性别和年级的基础模型(模型1)中,性别( p < .05)和年级(β p < .01)对因变量1具有显著正向预测作用。然而,当引入因变量3、4、5、6构建扩展模型(模型2)后,性别和年级的效应不再显著(p > .050),而因变量5表现出最强的预测力( p < .001),其次是因变量4(p < .01)和因变量3、6( p < .05)。模型2的调整R²显著高于模型1( p < .001),表明新增变量对因变量1的解释具有增量效度。这一结果提示,性别和年级的初始效应可能通过因变量3-6的中介路径实现,或因变量5等变量是更直接的预测因子。"
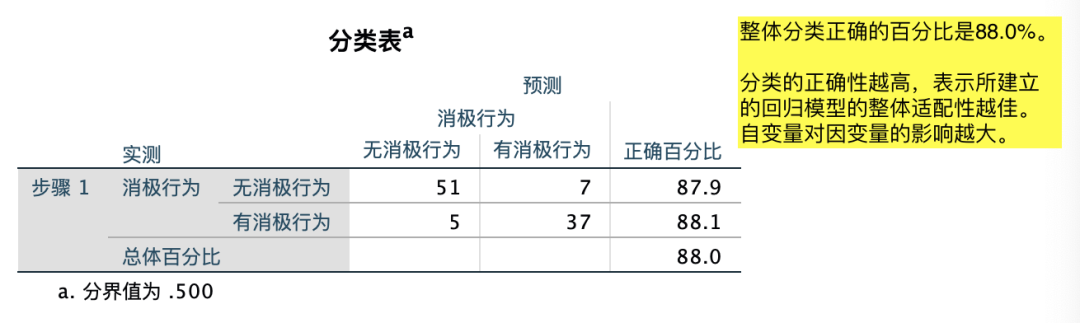
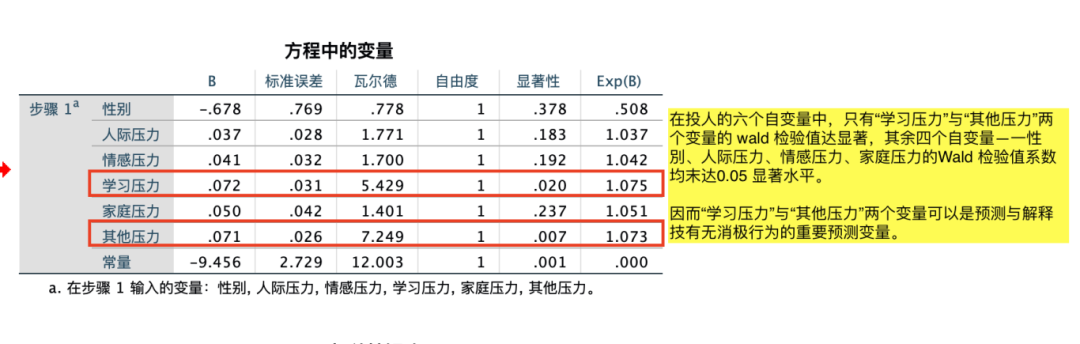
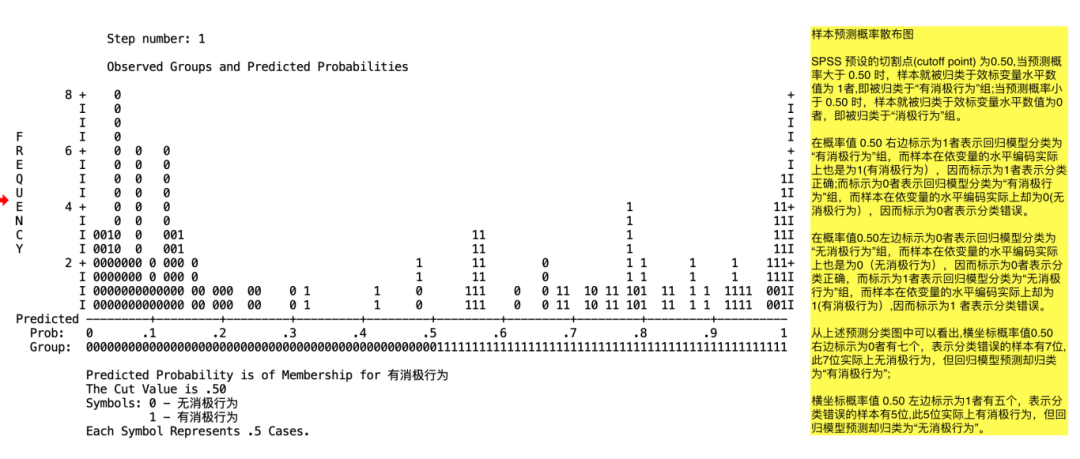
(3)二元Logistic回归分析
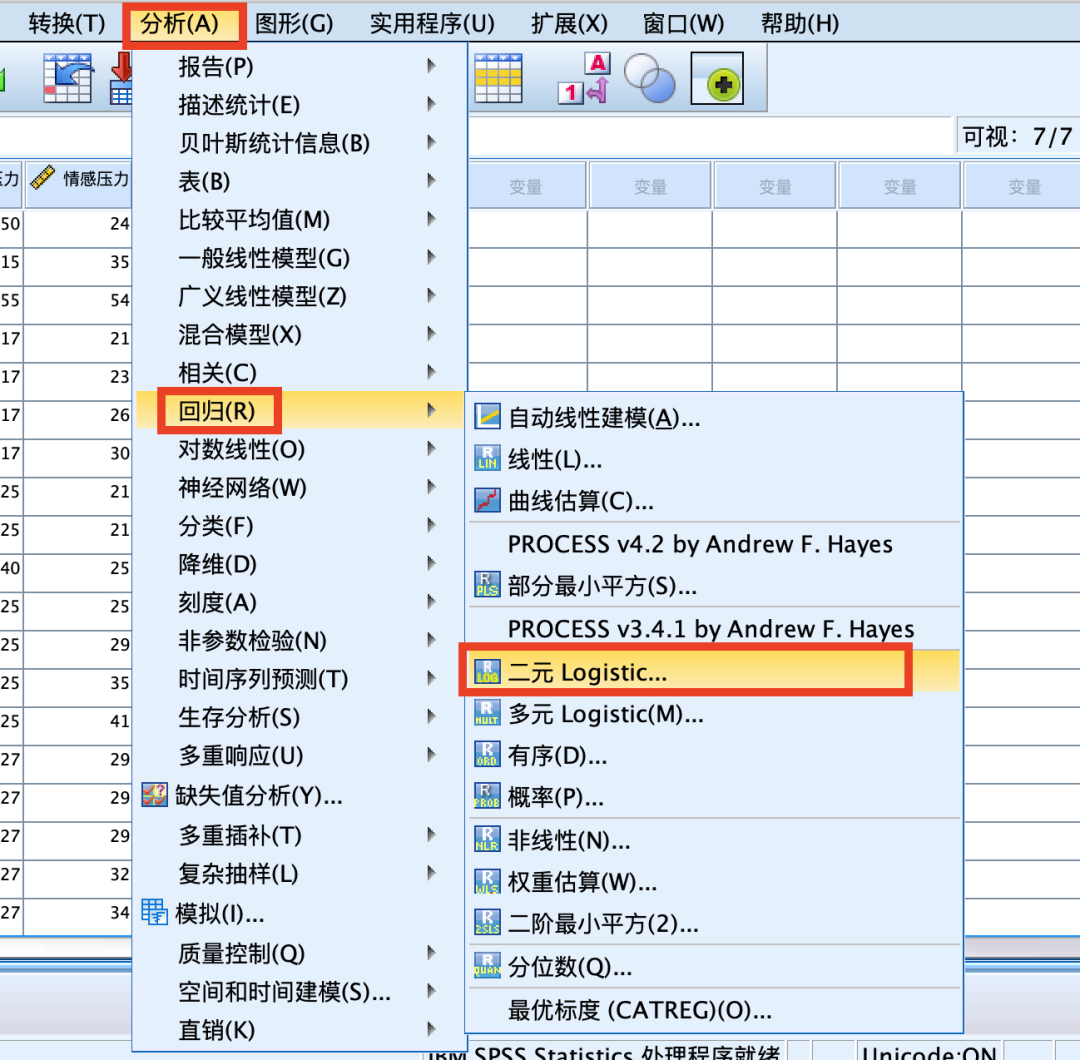
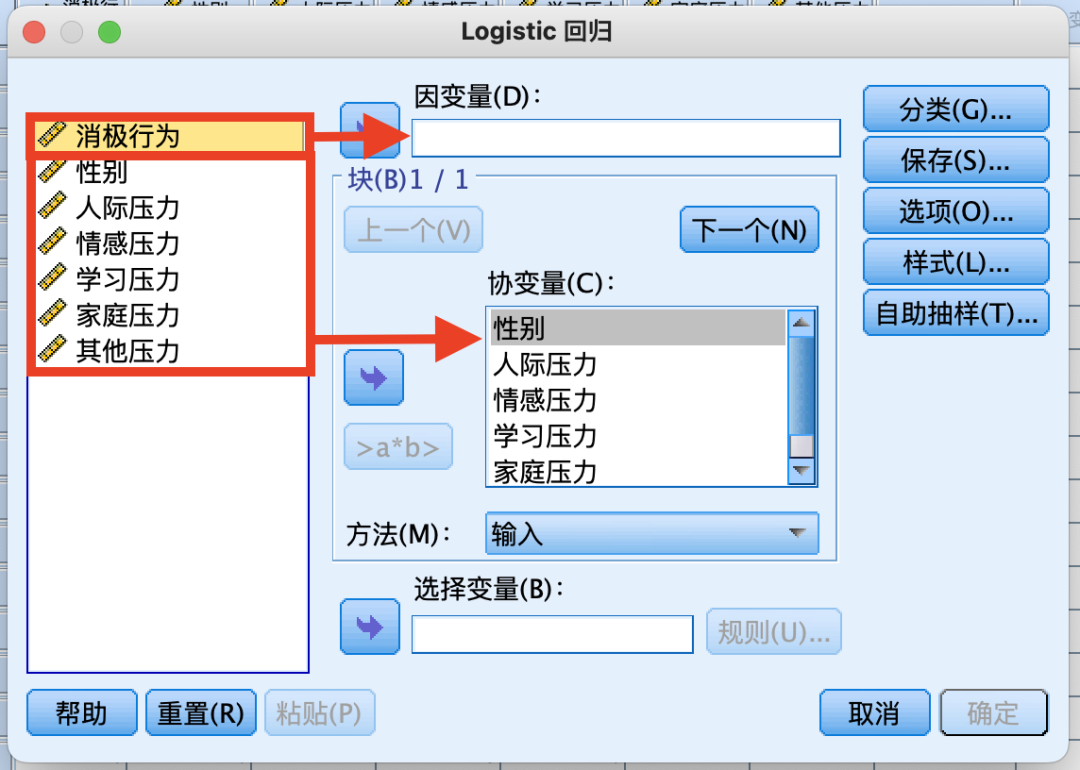
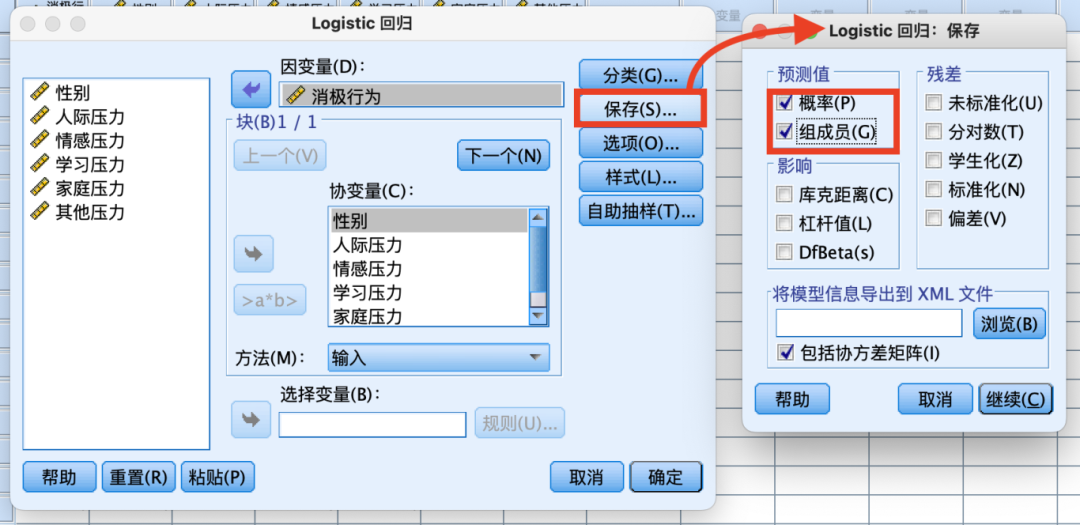
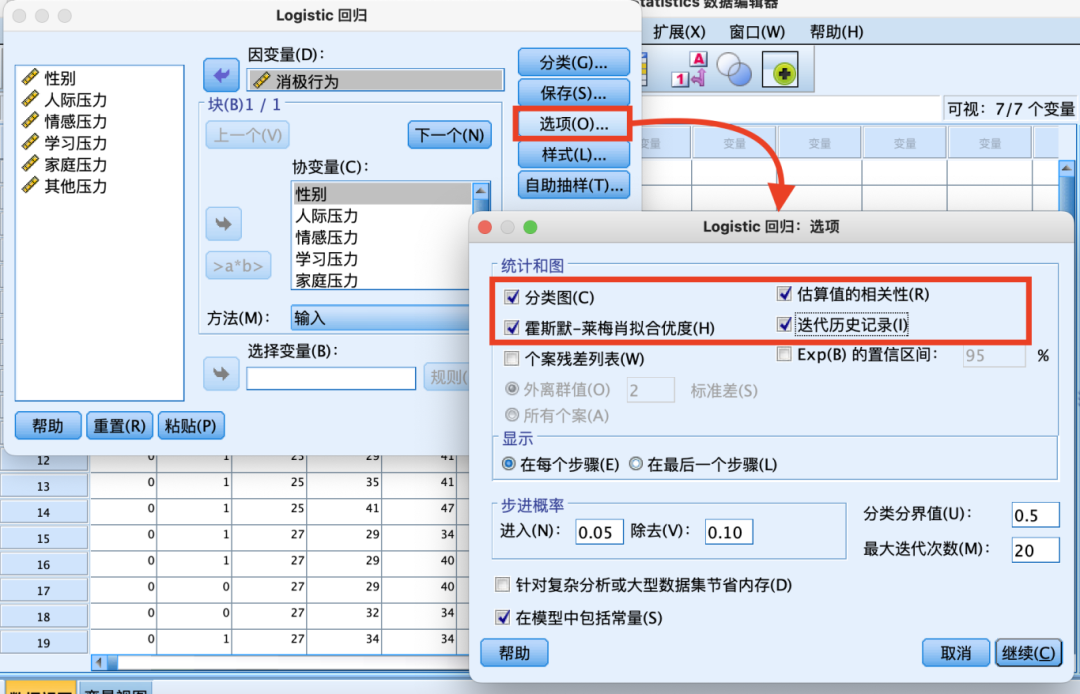
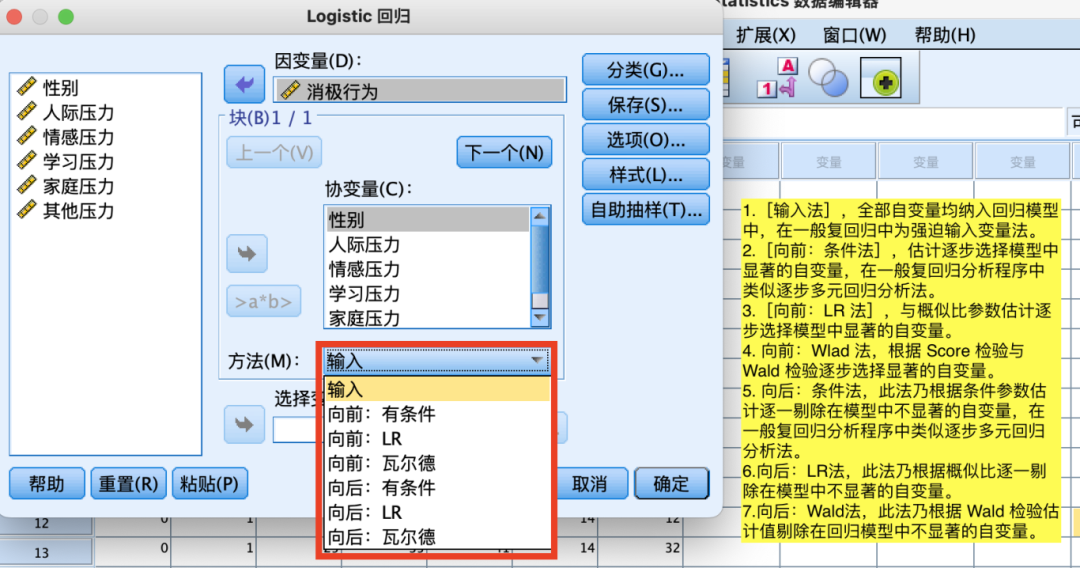
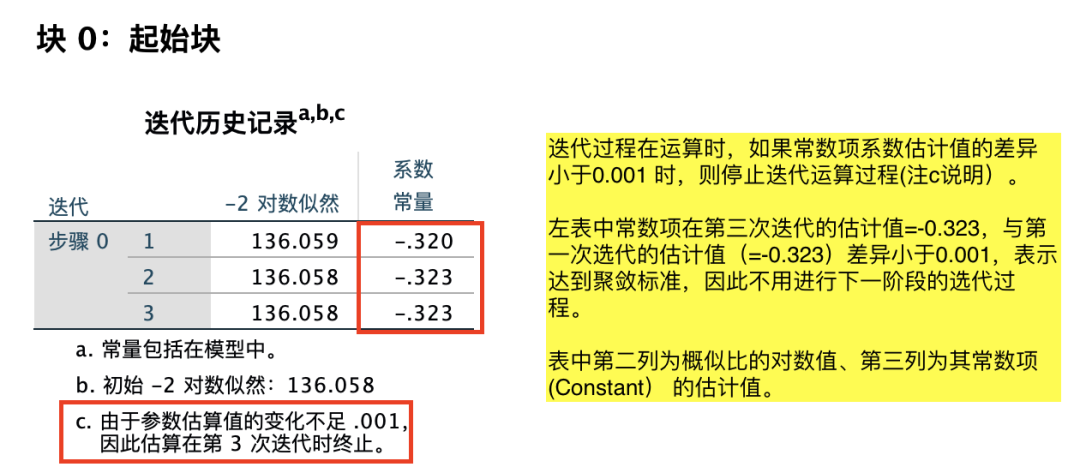
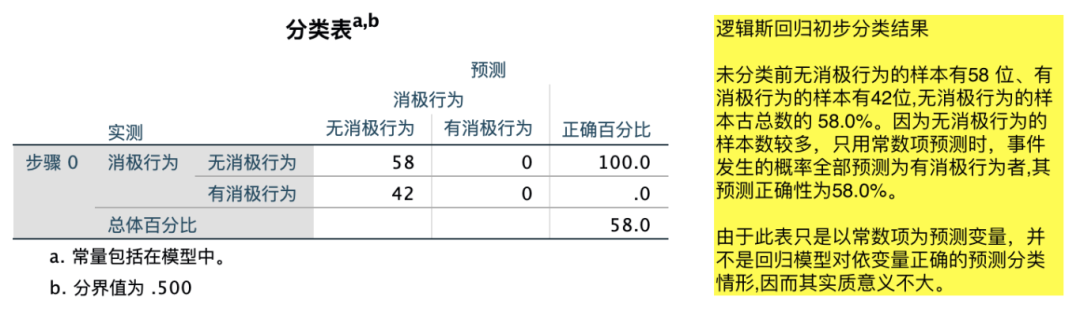


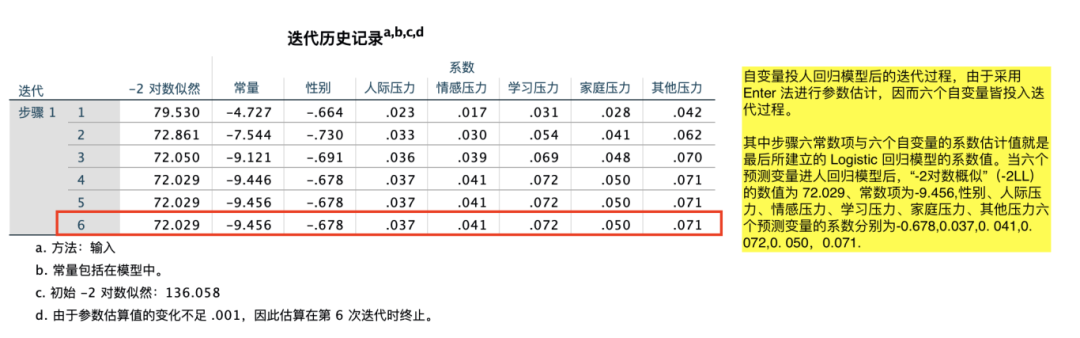



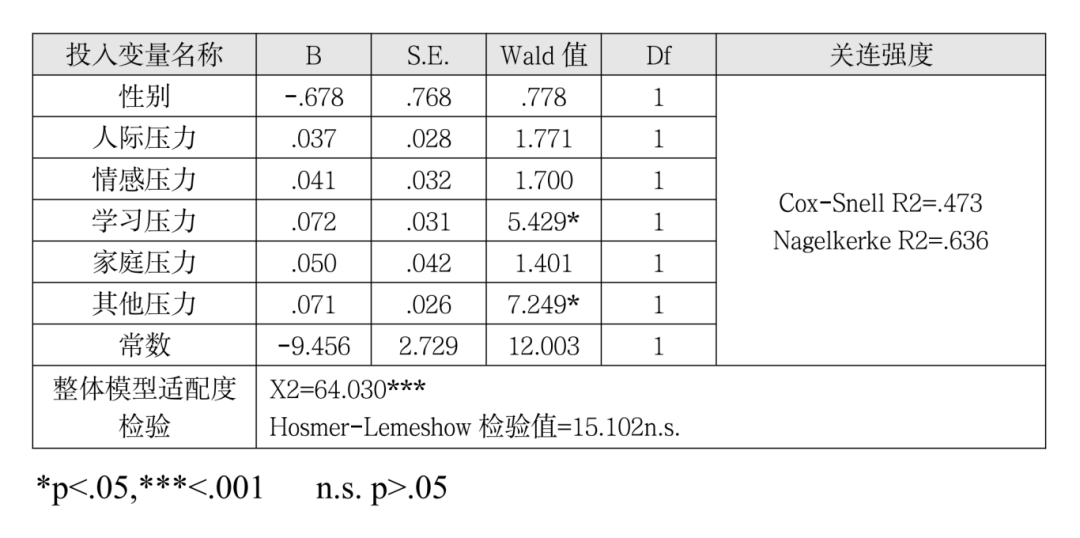 8.相关性分析(皮尔逊相关性分析/Person相关分析)
8.相关性分析(皮尔逊相关性分析/Person相关分析)
第一步,选择“分析”——“相关”——“双变量”。
第二步,在相关系数里,选择“皮尔逊”。显著性可以选“双侧”。
第三步,点击“选项”,可以勾选统计,计算平均数与标准差等,如下图所示。
其他设置都可以默认。直接点“确定”,就能生成结果了。
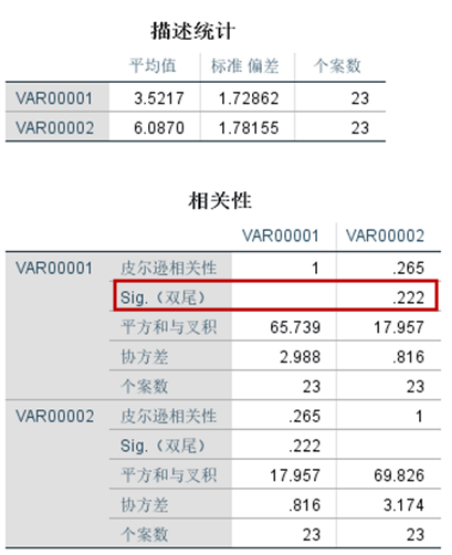
皮尔逊相关性分析结果显示,P值显著性为0.222,如红框中所示。P值大于0.05,说明示例的两个变量无显著相关性。相关性系数为0.265,离1比较远,也说明相关性不高。
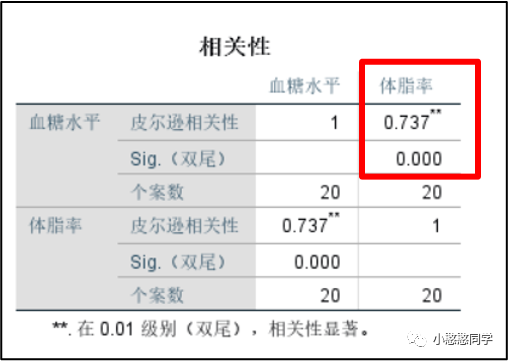
输出分析结果,这里给出的是皮尔逊相关系数的结果,这里相关系数为0.737,该数值给出了两个信息,一是相关性的大小,相关系数的绝对值为0-1,数值越大表示相关性越强,二是相关性的方向,相关系数大于0,表示两个变量是正相关的。而且p值小于0.05,提示相关性是有统计学意义的。
9.聚类分析(系统聚类/Kmeans聚类/两类聚类)
(1)系统聚类
第一步:点击“分析”——分类——选择“系统聚类”。注意,虽然是聚类分析,但在SPSS里叫“分类”。
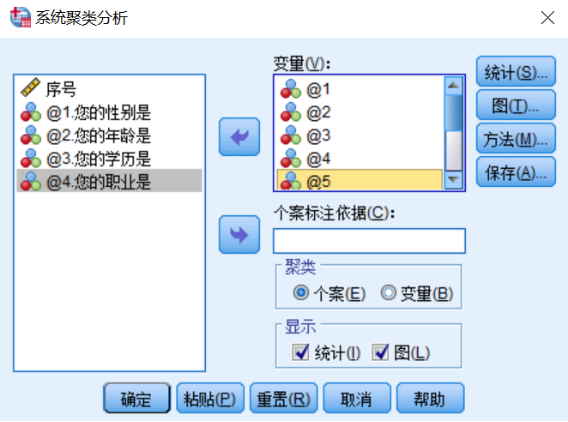
第二步,变量选择。如下图所示。只选择连续变量。因为我们要计算距离,需要连续型数值。
第三步,统计设置。可以设置聚类成员的数量。默认为“无”。系统会自动计算聚类数量。
第四步,图结果设置。勾选“谱系图”。
第五步,方法设置。默认为“组间联接”,“平方欧式距离”。可以选择“欧式距离”等常用的距离计算方法。
第六步,保存设置。这个根据自身的分析需求,看看需不需要保留聚类中心点。
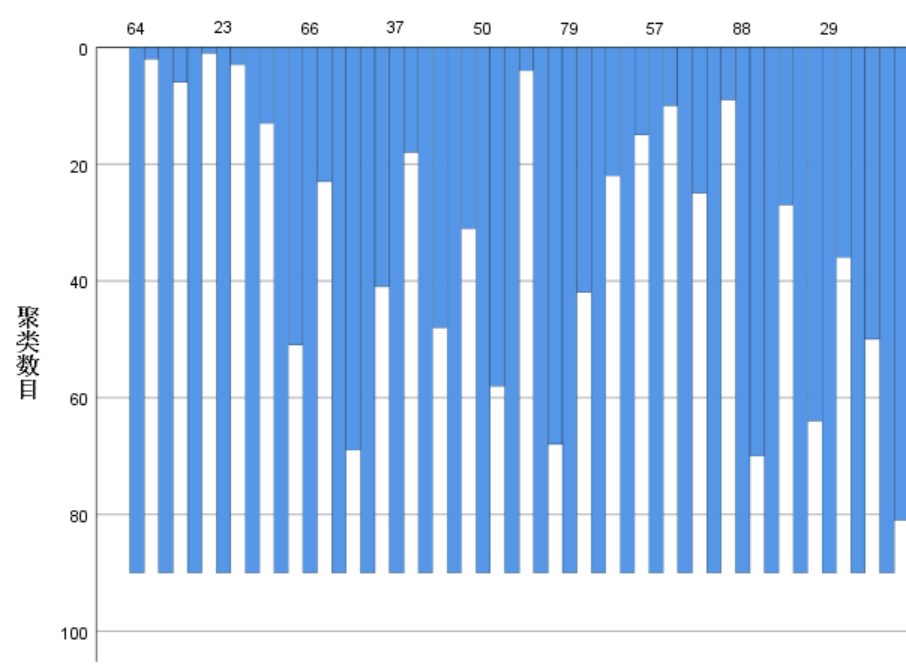
分析结果是
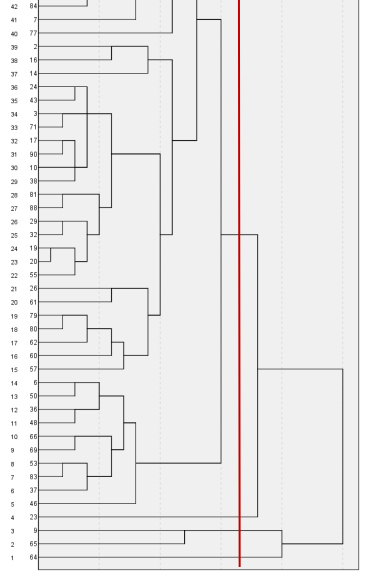
(2)Kmeans聚类
分析~描述性统计~描述,将定量变量纳入到变量后在左下角勾选将标化值另存为变量,点击确定
在变量右侧就生成了标准化后的数值,每个变量名称前加了一个Z
标准化完成以后进行聚类分析
分析~聚类~k均值聚类,在保存中选择保存聚类成员,在选项中选择AVONA表和初始聚类中心,SPSS默认迭代次数为10,在迭代中修改为100。默认收敛准则为0,意味前后两个如果各点到聚类中心的之差为0,则达到收敛标准,收敛停止
将HADS选入个案标注依据,将标准化后的数值选入到变量框内,意思为根据变量(母亲年龄、CBTS、妊娠时间、EPDS)将HADS进行分类
初始聚类个数为2,在方法的左侧可以修改需要聚类的个数
第一个 为初始聚类中心,初始聚类中心是SPSS自动选择的一个实际样本,选择原则是所有变量构成的空间中的距离尽可能远,而且尽可能地分布在空间中,需要注意的是选择会和个案排列的顺序有关,可以在计算之前打乱排列顺序
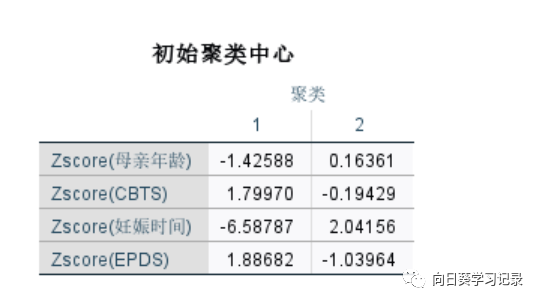
下一幅图是迭代记录,可以开出聚类中心变化越来越小,直至趋近于0,在第11次迭代的时候终止,聚类中心收敛
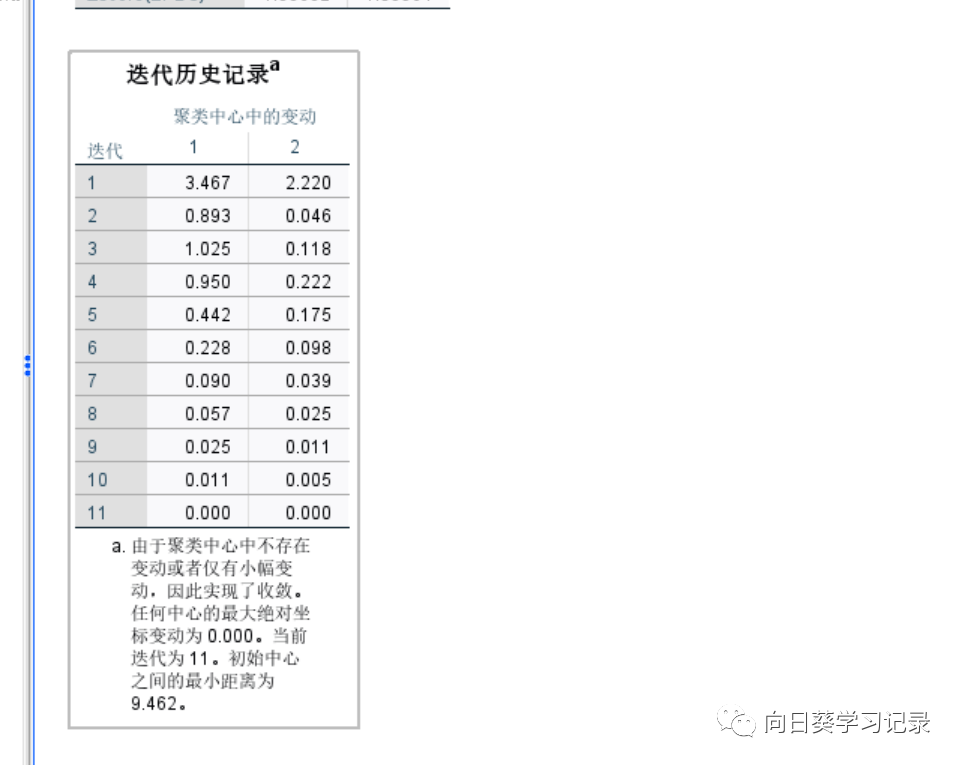
下一幅图是最终聚类中心以及他们之间的距离.最终聚类中心也说明了他们的特征,比如1类的CBTS和EPDS就比较高,而2就低,说明1组的焦虑程度比2组要高
最后是给出了每个聚类的个案数和ANOVA检验,ANOVA表示每个变量在不同类别之间是否存在显著差异,若存在的越多则表明聚类效果越好,根据图中可知,CBTS和EPDS对聚类有贡献,且EPDS的F值最大,说明EPDS对聚类的影响最大,CBTS次之,妊娠时间最小。1类为119 2类为271
最后结果会输出为QCL_1,最后是对聚类后的结果进行描述(使用之前的变量),来说明每个类别的含义
(3)两步聚类
分析~分类~二阶聚类
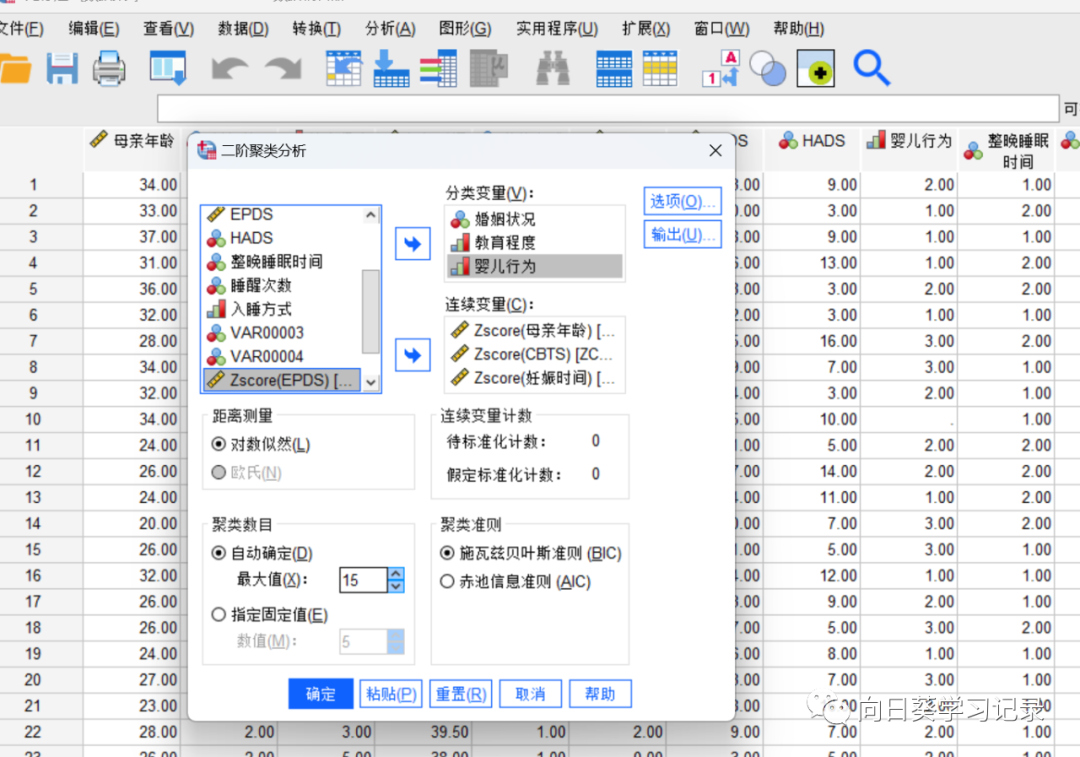
将一些分类变量和定量变量选入到相应的方框中,测量距离选择对数似然,若只有连续变量,则可以选择欧式
聚类数目默认最大15,聚类准则为BIC
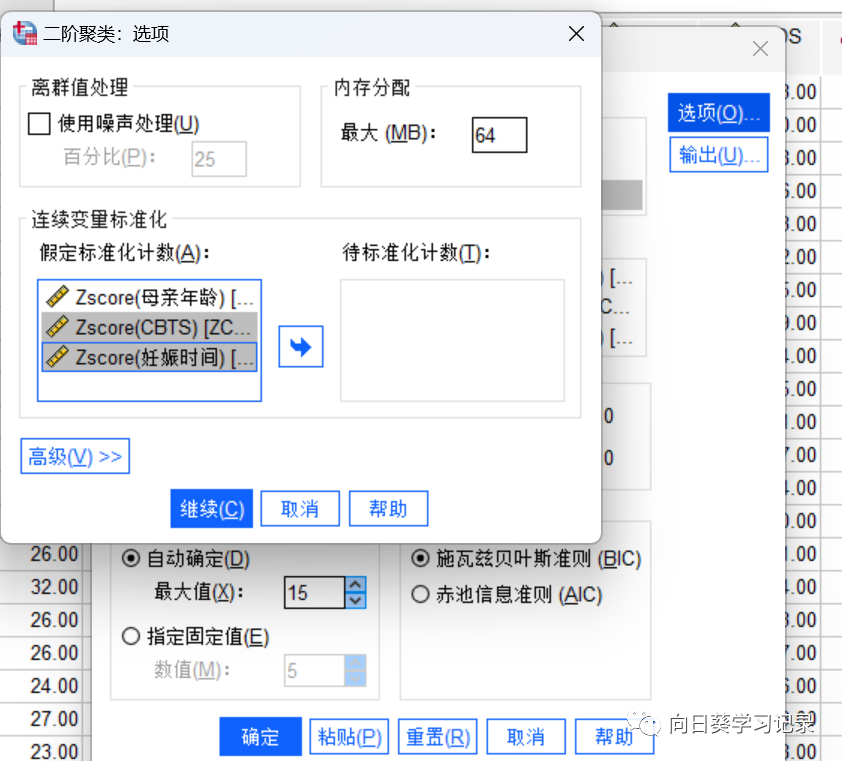
点击选项,由于SPSS默认对所有的数值变量进行标准化,因此若已进行标准化则需将待标准化计数放回到假定标准化计数内,若未进行标准化则无需进行改动
在这里由于我已经将离群值进行了处理,因此未勾选使用噪声处理,若勾选会按照25%的比例计算哪些数据是噪声值,内存分配默认
确认
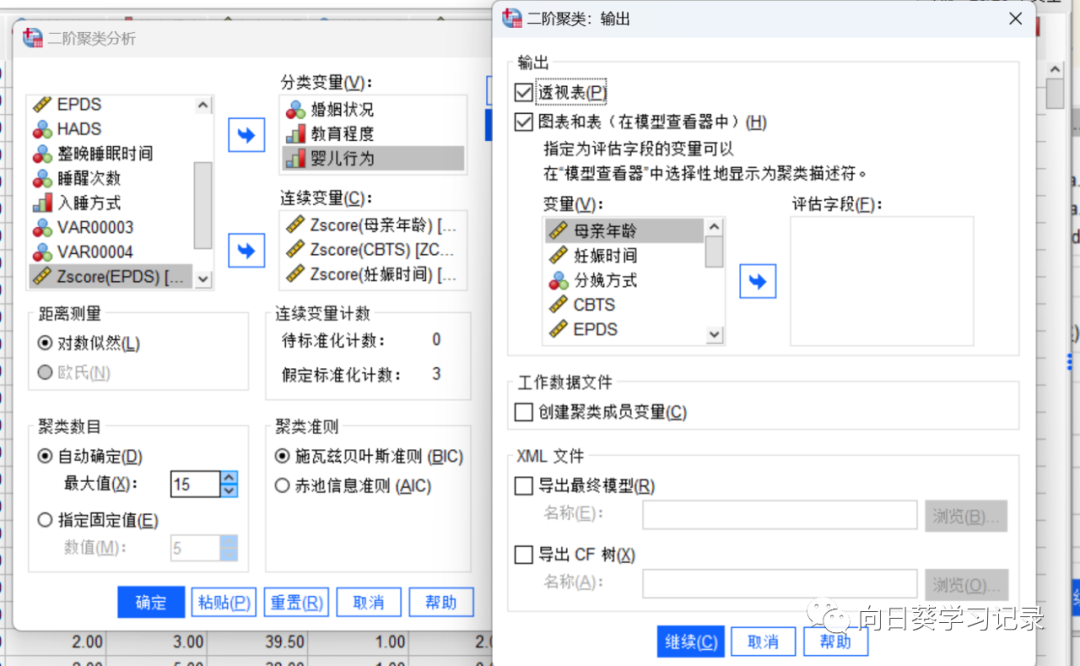
点击输出,勾选透视表
全部万层以后点击确定,输出结果,结果最终被聚为2类,双击进入更详细的界面
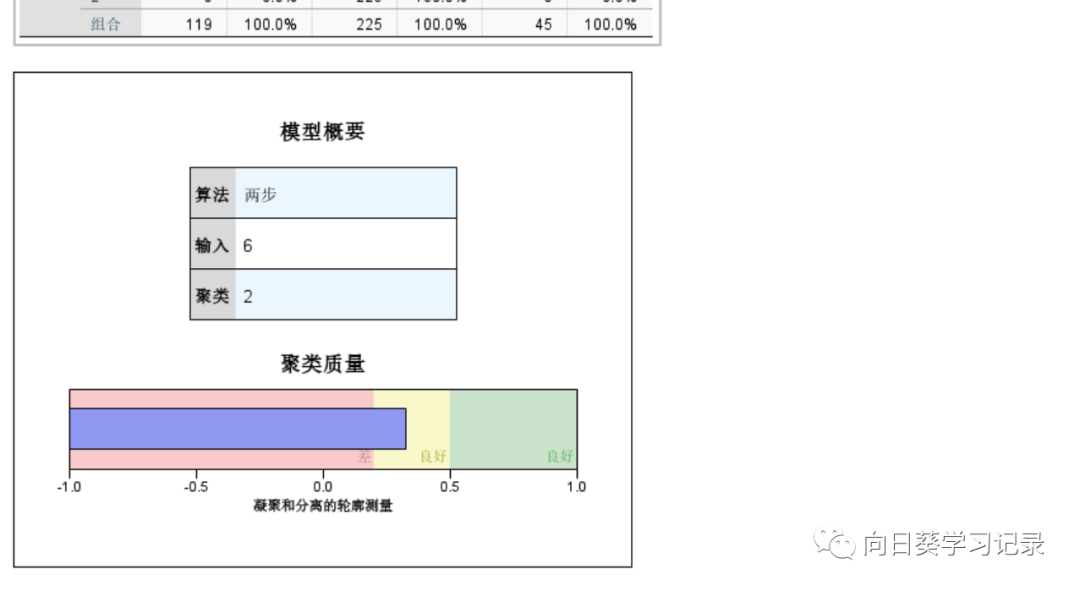
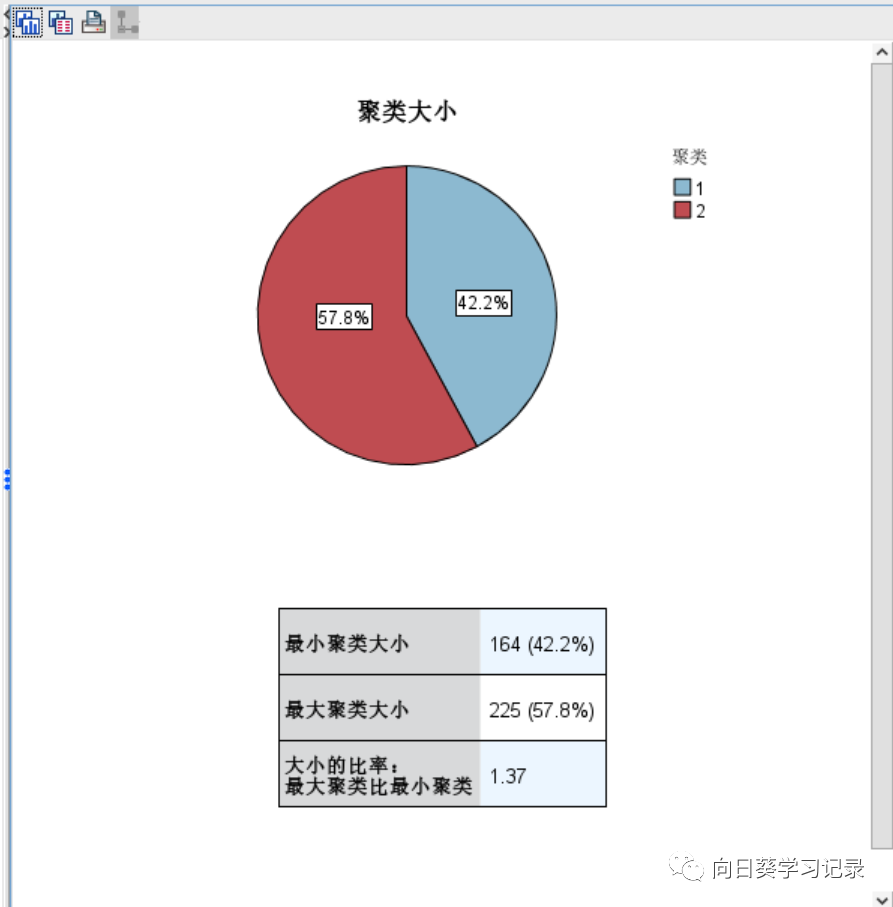
根据两类的结果分布得知,两类的分布比较均匀,聚类大小是样本数
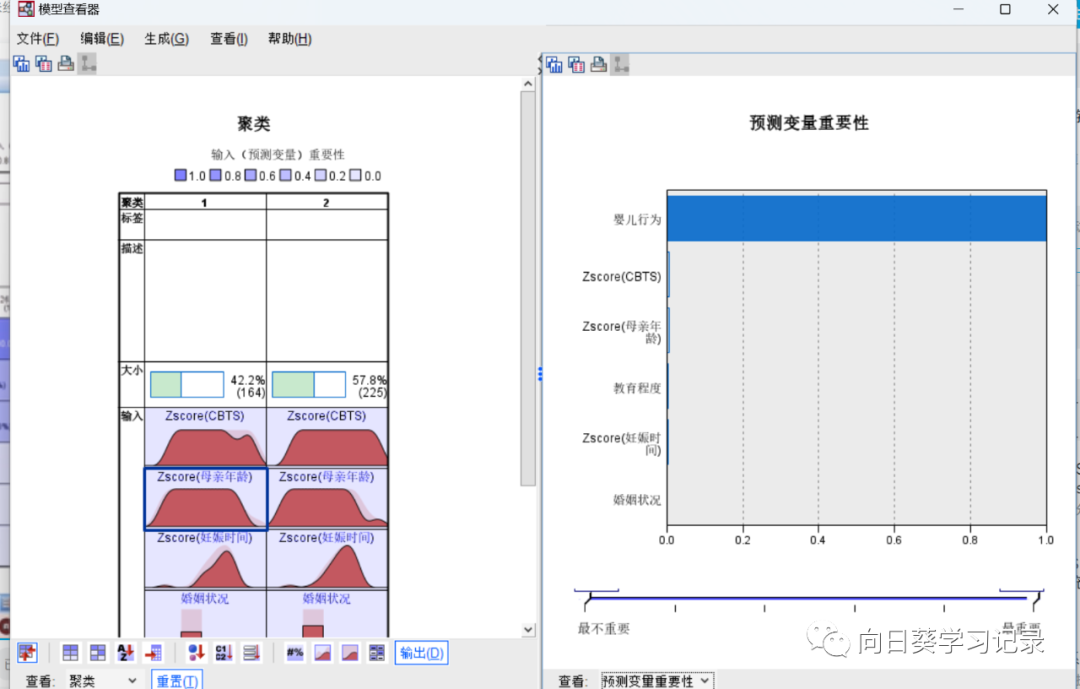
在模型查看器左下,将查看改为聚类,可查看各个输入的重要程度,在后续中可将不重要的输入踢去在进行聚类,在下图中,婴儿行为最为重要,而CBTS和母亲年龄重要性很低(颜色),除了颜色还可以将鼠标放在相应的模块内,会显示模型重要性
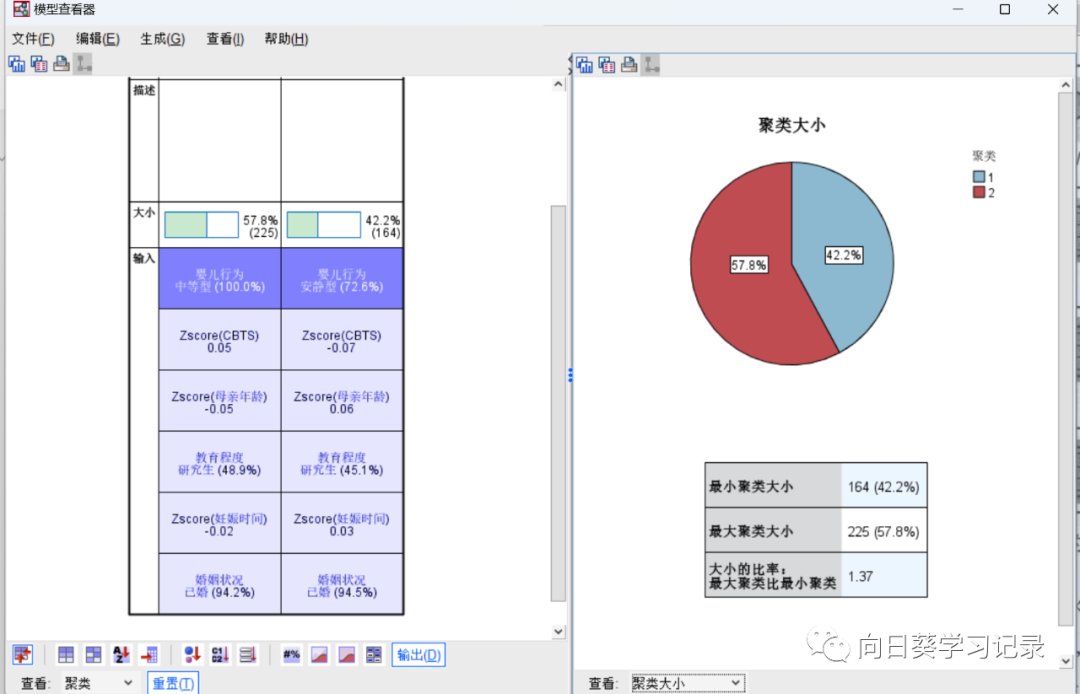
将右侧的聚类大小改为预测模型变量重要性,可以图的方式呈现出来,选择不同的类可展现不同类别的重要性
在模型中,查看聚类比较,可直观的看出不同聚类的分布,点击2即可选种这一整列,然后点击聚类比较即可呈现出来
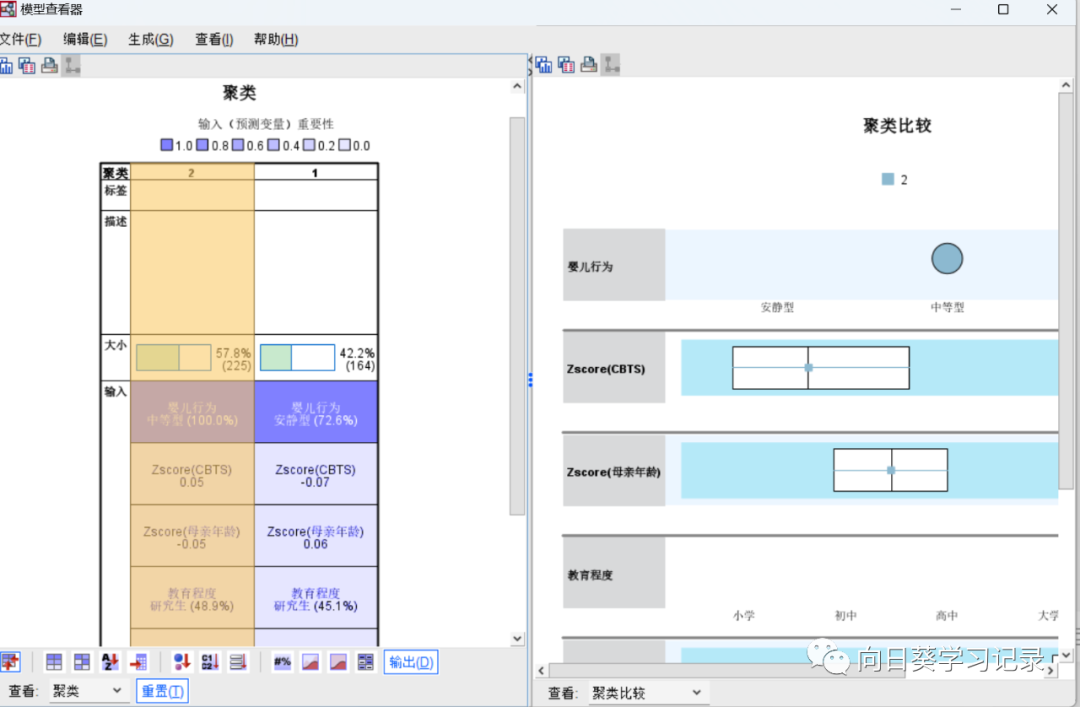
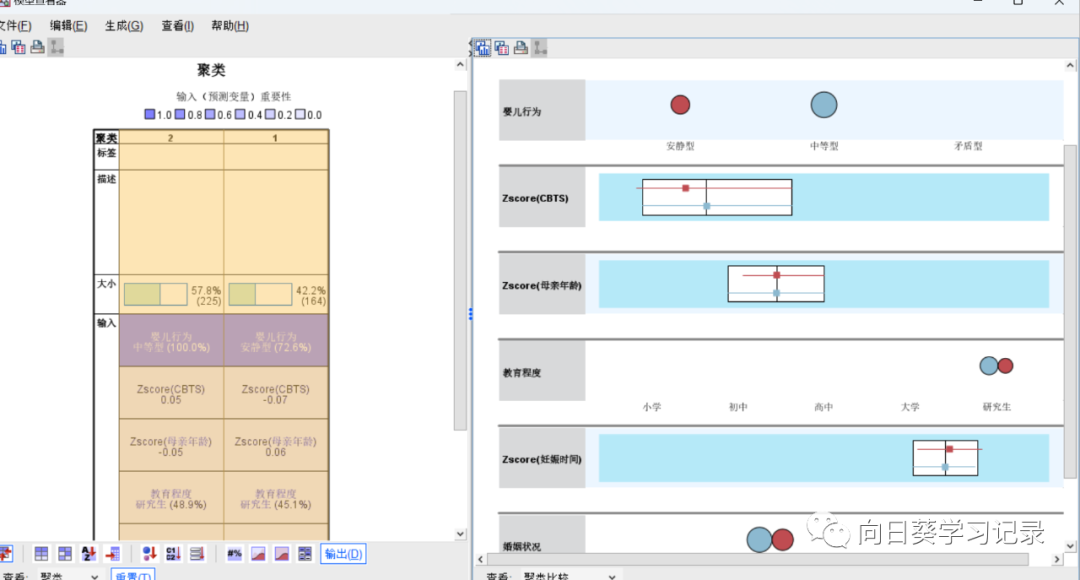
按shift选全部的类别,进行聚类比较,可以看出1类主要是安静型,2类主要是中等型,其余的都差不多
在变量栏中,TSC_4877下的数值是聚类结果
10.正态检验
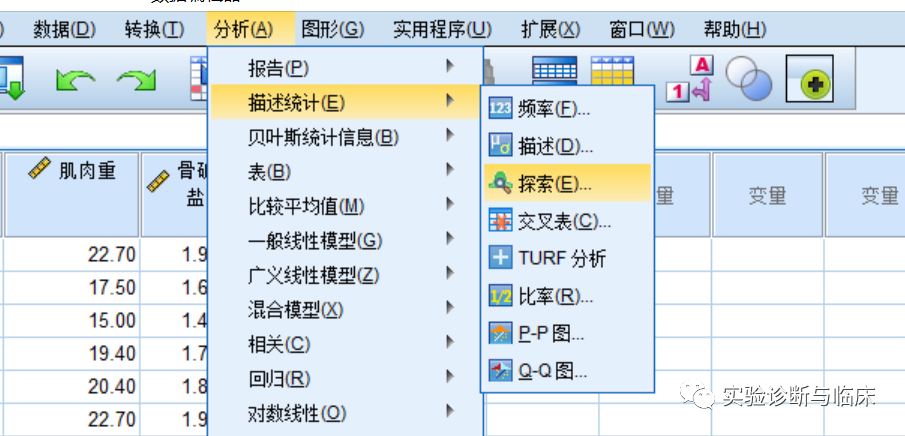
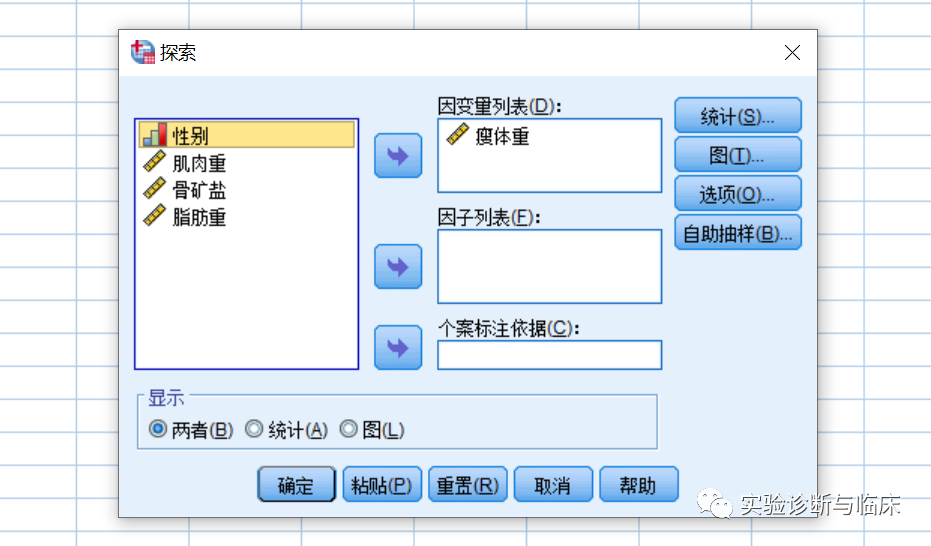
分析——描述统计——探索——结果(正态性检验)

以上结果显示两种方法均P<0.05,所以拒绝原假设,因此样本所来自的总体与正态分布有显著性差异,即数据不符合正态分布。
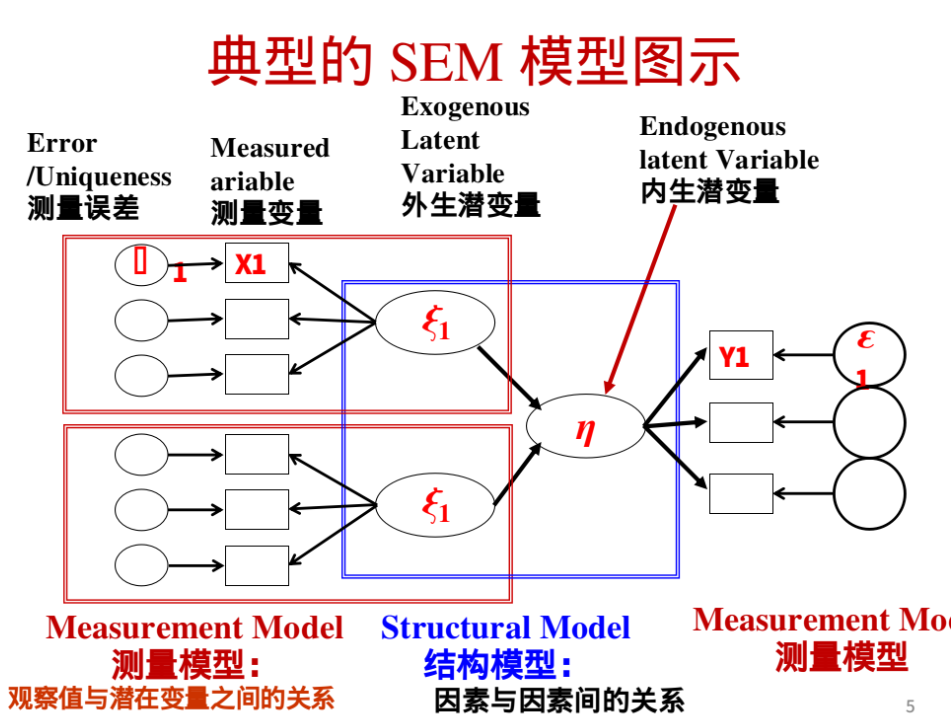
二、Amos结果
1.被指向的变量都需要添加残差!!!
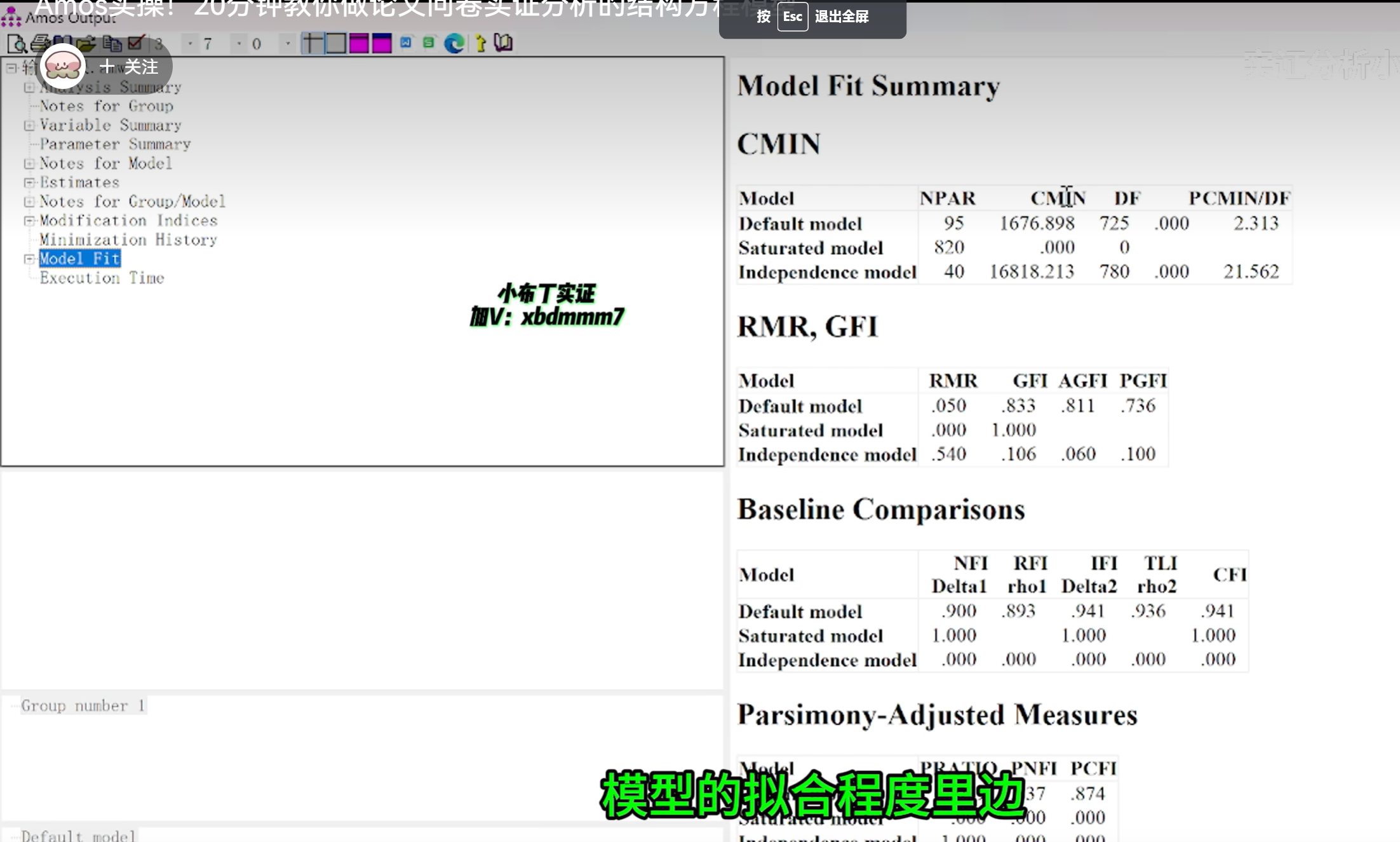
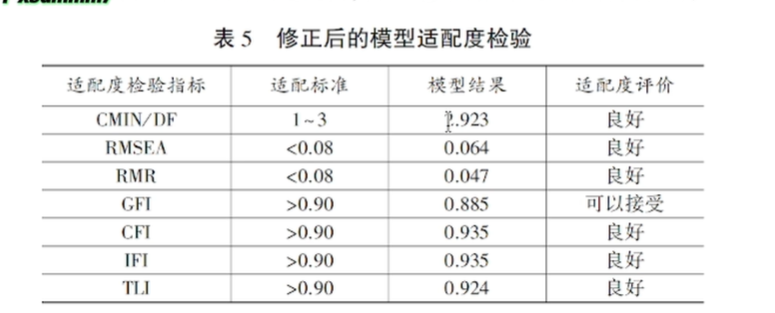
1.适配度检验和模型拟合
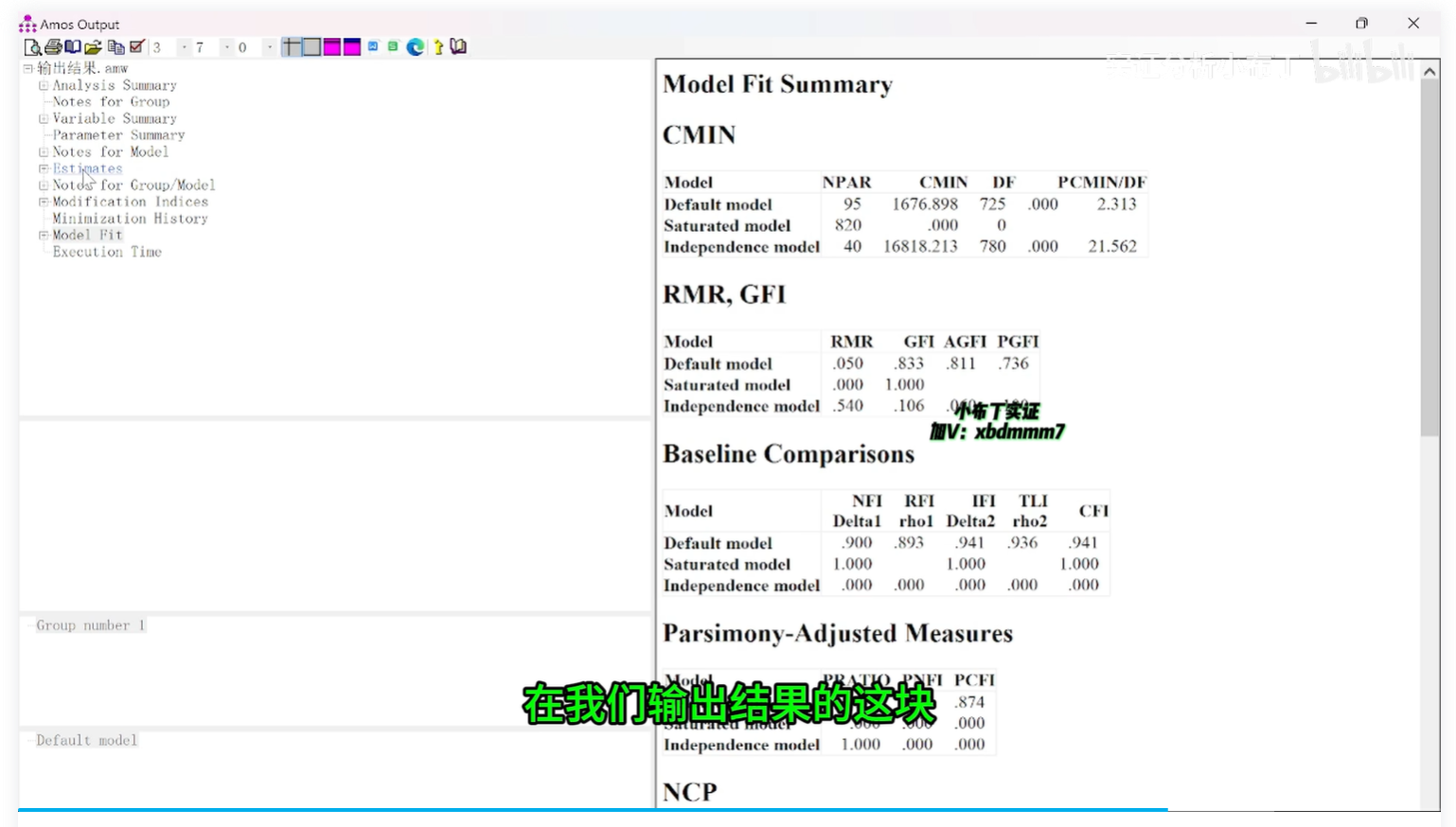
2.回归系数(一般是使用标准化系数)
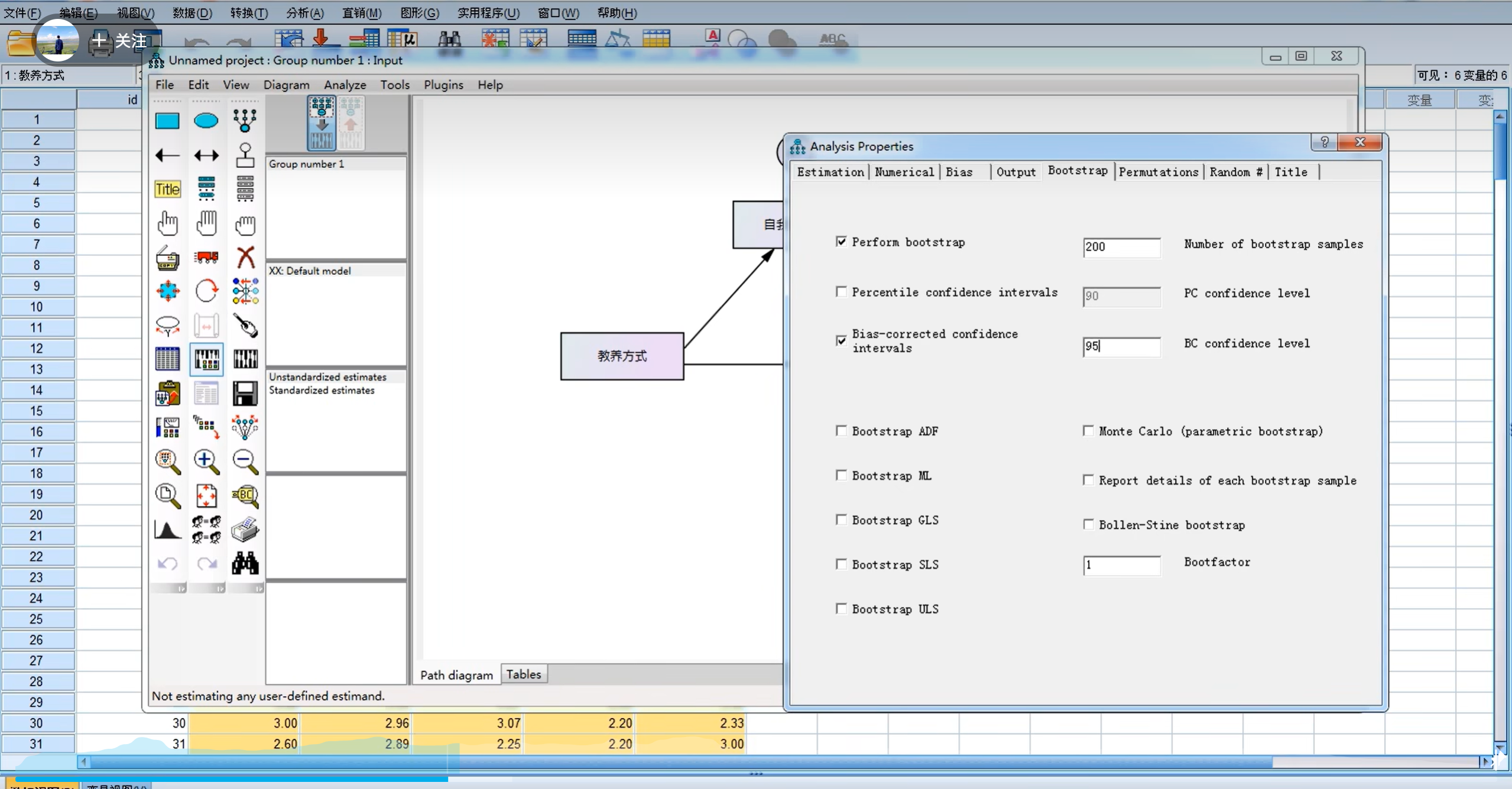
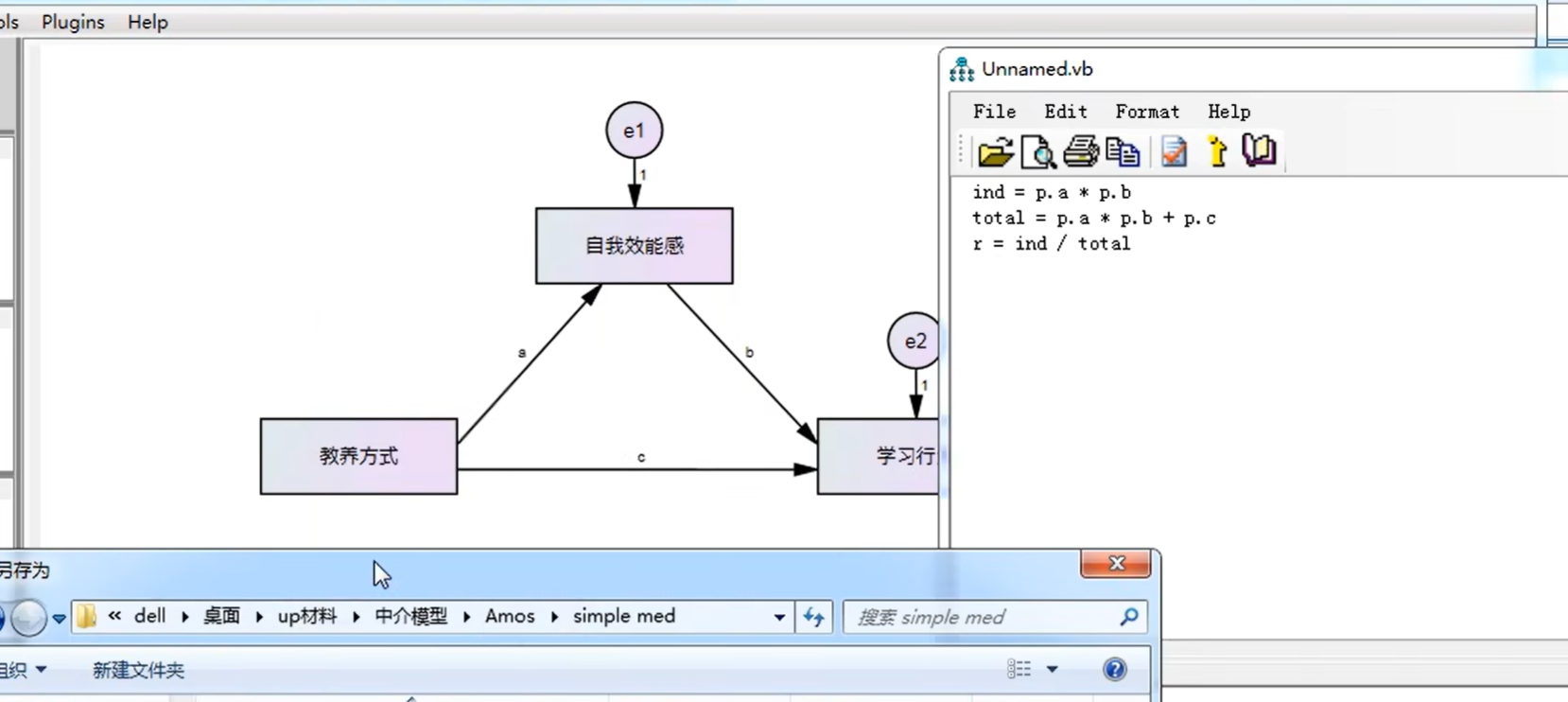
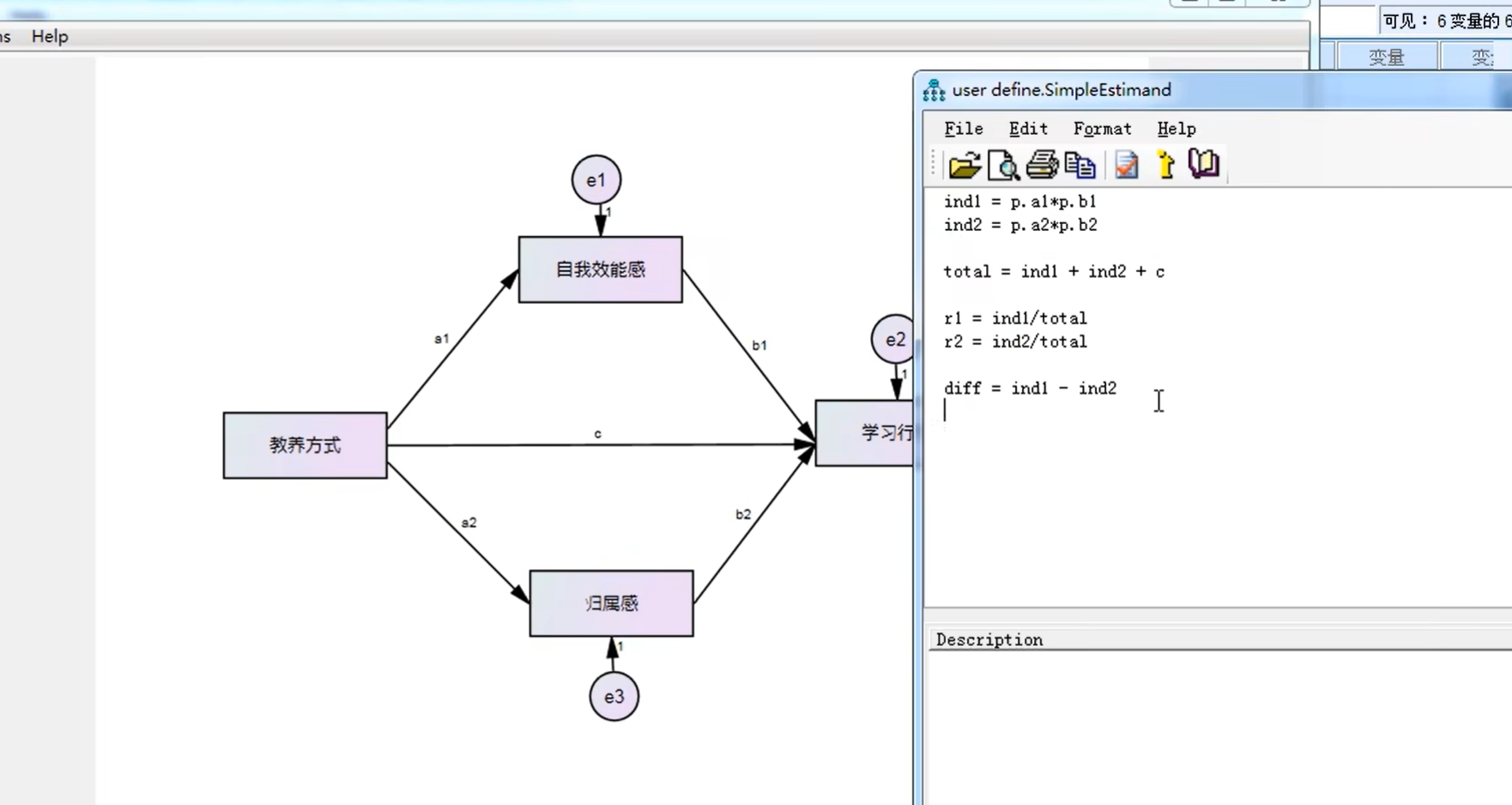
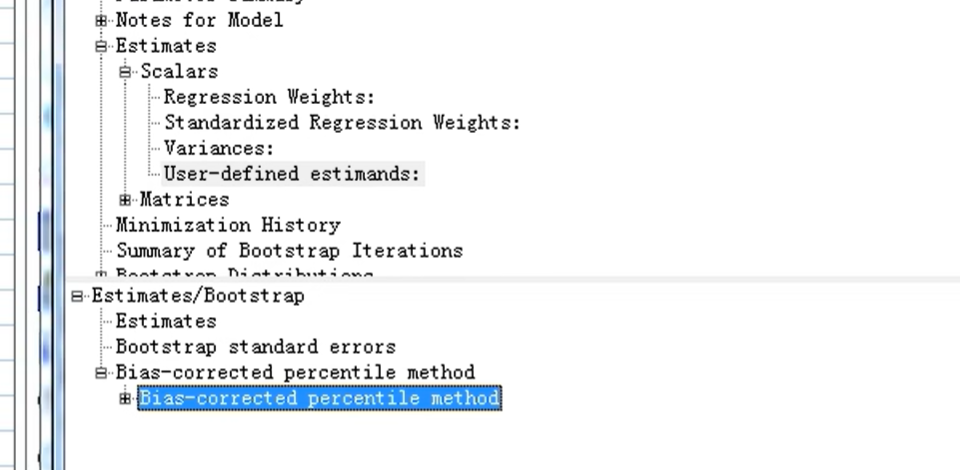
3.中介效应(5000,95)
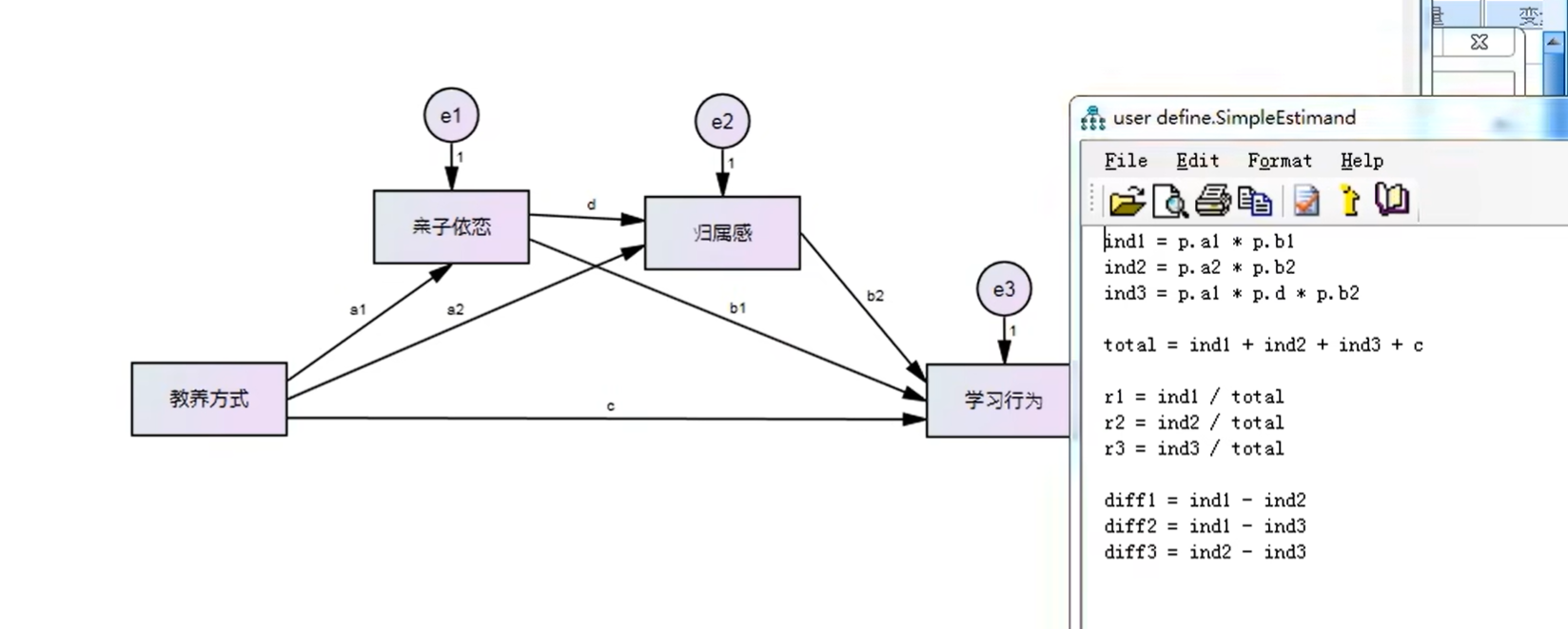
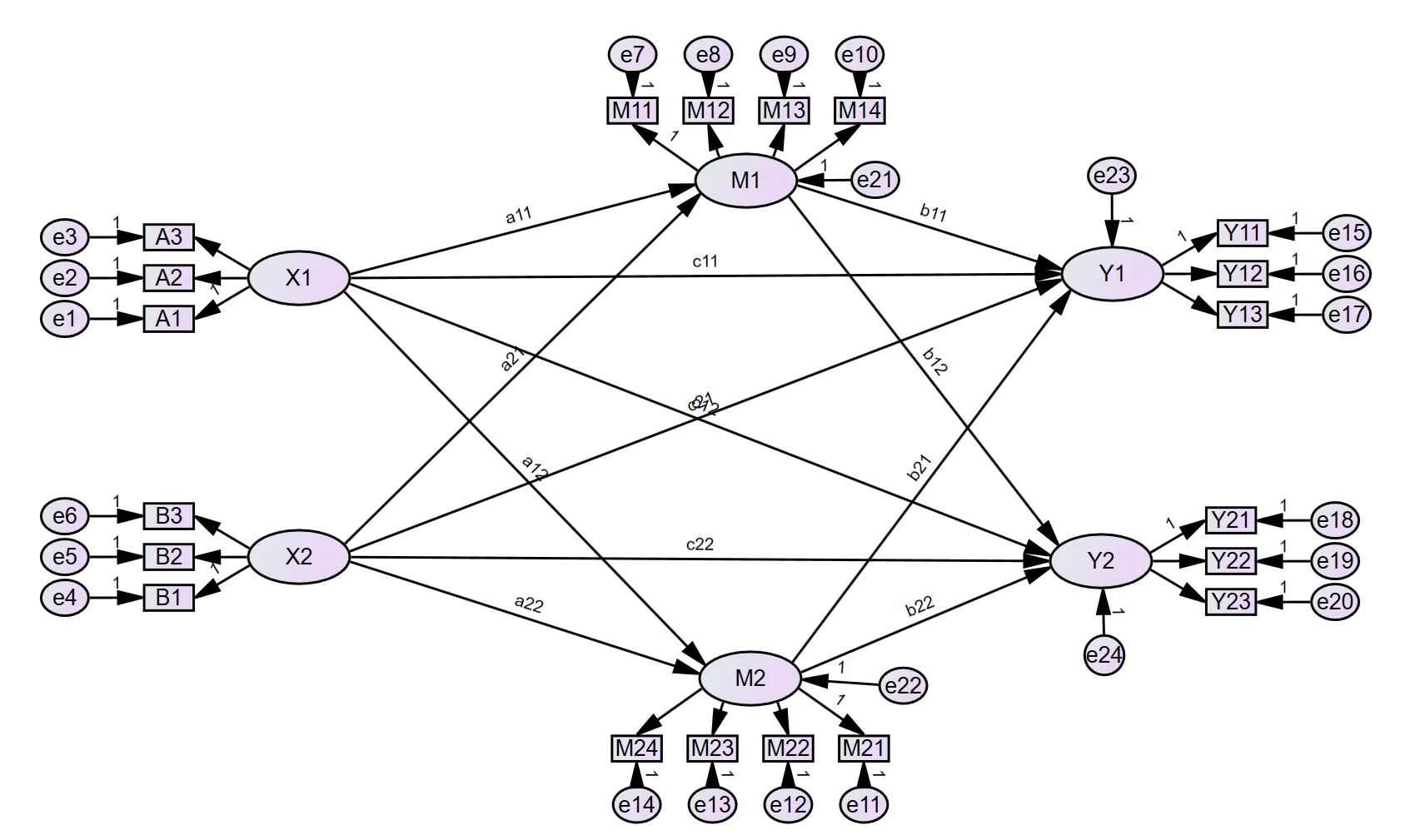
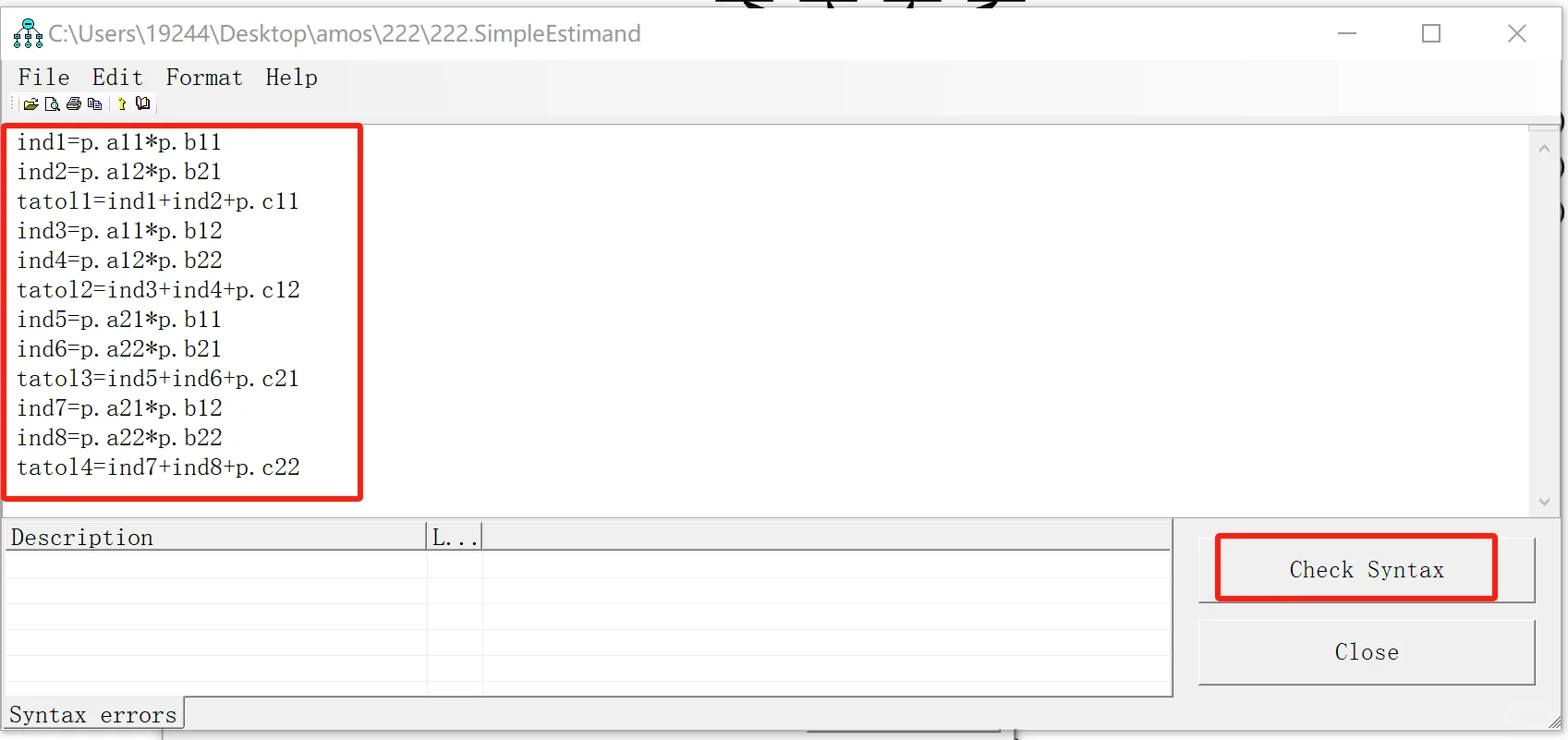
4.具体案例
1.案例1
(一)结构方程模型分析
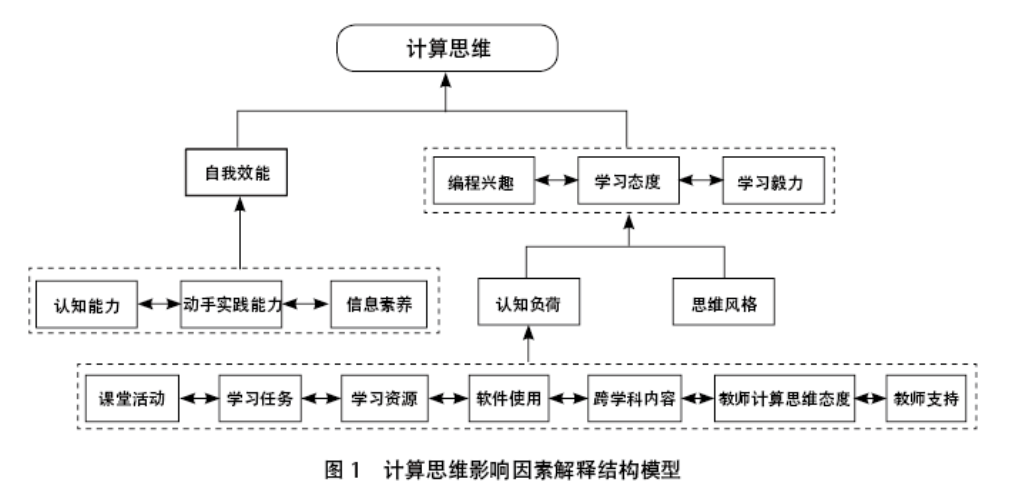
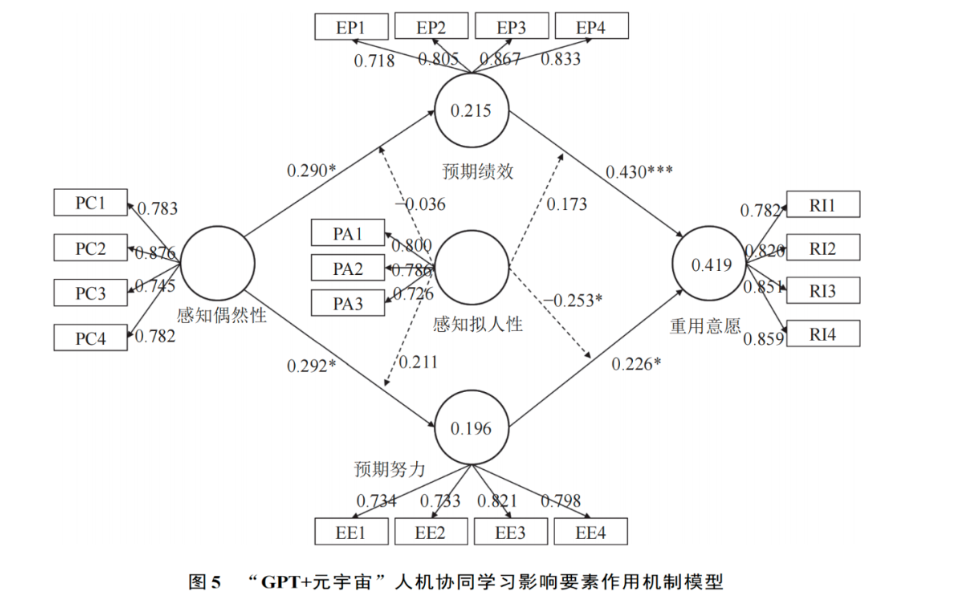
基于上述研究假设,运用Amos 24.0软件绘制硕士研究生学习投入度影响因素的初始模型,并验证潜在变量间的影响关系。如图2所示,初始模型中个体因素、院校因素、互动因素属于外生潜变量,分别对应读研动机、教学服务质量、与导师关系融洽等12个外生显变量,用字母RZR1—RZR3、XWR1—XWR3、QGR1—QGR6测量学习投入度, 认知投入、行为投入、情感投入属于内生潜变量,分别对应独立思考、积极参与研究课题、导师的辅导等14个内生显变量,用字母GTR1—GTR6、YXR1—YXR4、HDR1—HDR4表示学习投入度影响因素的测量指标。
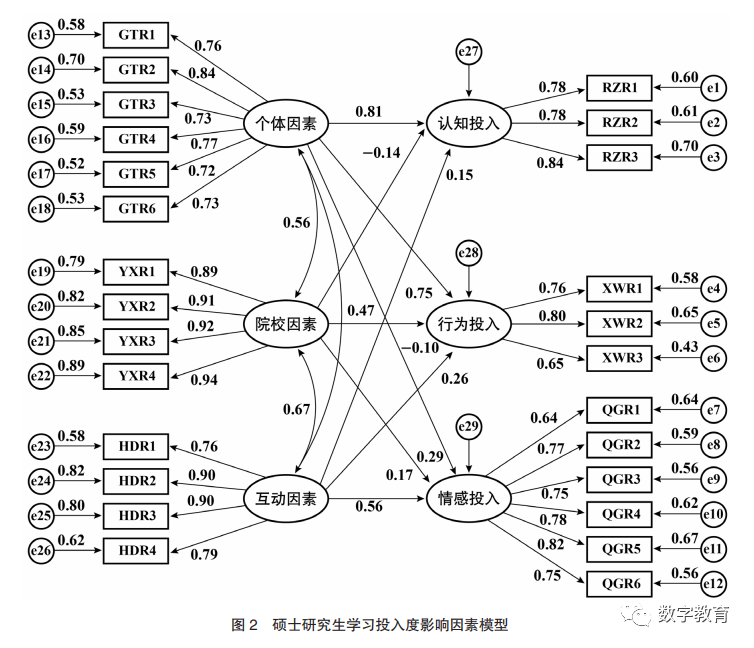
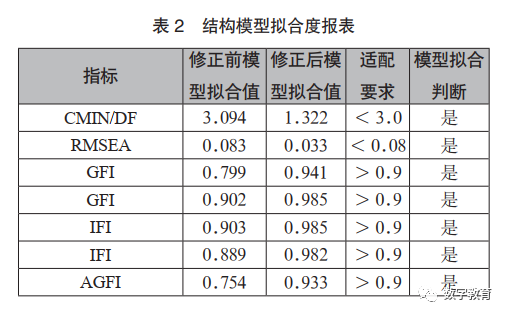
1.模型拟合度检验
假设模型中变量的估计值均为正数且显著,表明变量未违反估计值,进而对模型的拟合度进行考察,在模型适配检验中,模型拟合度指标CMIN/DF、RMSEA、GFI、TLI、AGFI均未达到适配要求,仅有CFI、IFI值满足适配要求,即需对假设模型进行修正。
2.结构模型的修正
结构模型中输入的数据呈现非正态,造成卡方差异值因数据违反多元正态而膨胀,由此导致模型拟合度变差,在AMOS软件中采用Bollen-Stine方法修正卡方值,利用Bollen-Stine p-value估计的卡方值重新修正模型整体模型拟合度[6]。修正后模型拟合度值均达到标准,如表2所示。
(二)学习投入度影响因素分析与假设验证
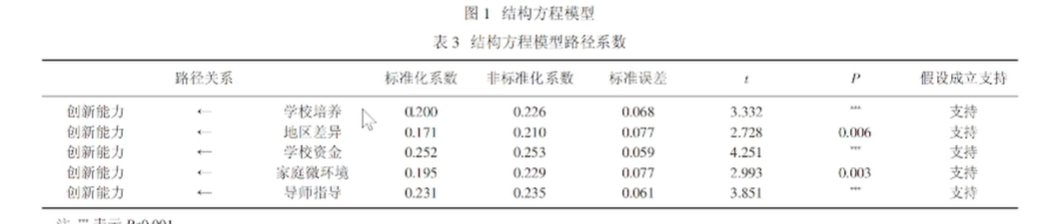
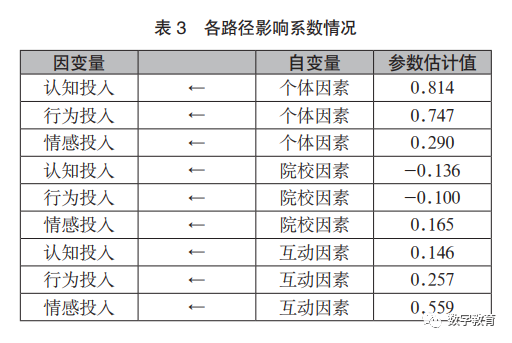
1.硕士研究生学习投入度影响因素分析
如表3所示,根据修正后的硕士研究生学习投入度影响因素模型可知,个体因素对认知投入影响最大,其中拥有坚定的学习信念,在硕士研究生期间达到自己设定的目标的对学习投入影响较大,只是为了顺利毕业的硕士研究生对学习投入影响最小。院校因素中学校设置的课程结构对学习投入影响较高,对学习投入影响最小的是学校的教学服务质量。互动因素对认知投入、行为投入影响较低,对情感投入影响处于中值,其中导师的指导方式影响互动因素最大,导师指导研究生数量是否合理对互动因素的影响最小。
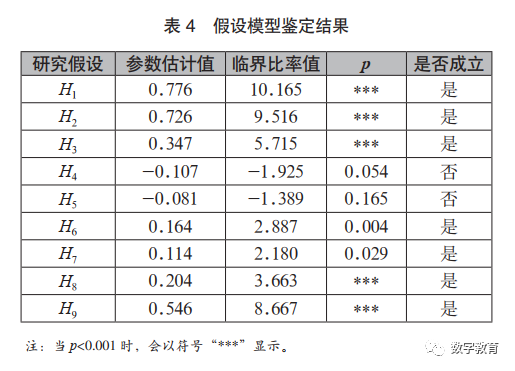
2.研究假设验证
假设模型鉴定结果如表4所示:院校因素对认知投入、行为投入呈负值,未产生正向影响,即假设4、假设5不成立,个体因素对学习投入具有极其显著的影响,互动因素对行为和情感投入影响极其显著。
2.案例2
(一)共同方法偏差检验
本研究使用Harman单因素检验对所有研究变量的题项进行未旋转的主成分因子分析,结果显示,共有6个因子特征值大于1,且第一因子解释变异量为37.88%,低于40%的临界值,说明本研究数据不存在严重的共同方法偏差。
(二)量表信效度检验
为保证研究的信效度水平,先期对测量工具进行一个包括6个一阶因子的验证性因子分析,结果显示测量模型的拟合指数良好:x²(468)=1 555.78,p<0.001,RMSEA=0.05,TLI=0.95,CFI=0.95。各因子题项的载荷值均不小于0.60,而且t值在0.001水平上显著。所有因子的AVE值均大于0.5,AVE的根号值均大于因子之间的相关数,表明区别效度良好。所有因子的克隆巴赫系数均大于0.85,组合信度均大于0.8,表明因子的信度较好。本研究测量工具的信效度水平较好,适合做进一步分析。
(三)描述统计分析
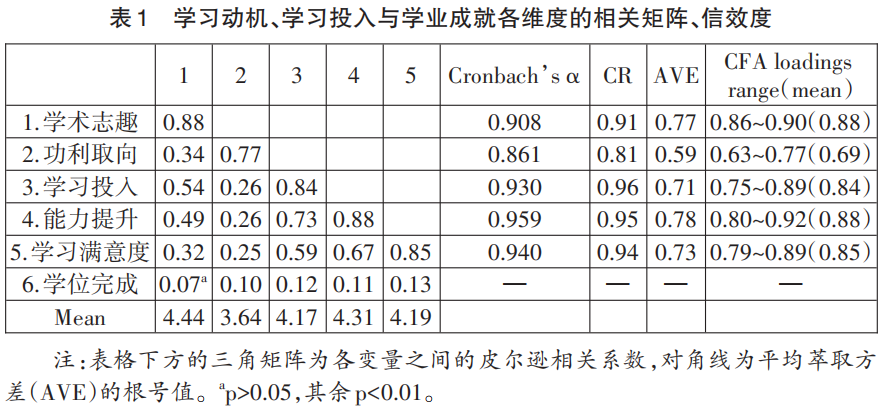
根据表1各研究变量的平均分数和相关系数可以发现,在学习动机方面,教育博士生的学术志趣与功利取向动机均高于理论中值3分,表明教育博士生动机水平整体较强,且学术志趣(M=4.44)高于功利取向(M=3.64),这与人们的传统认知存在一定偏差,需要进一步深入分析。在学习投入方面,教育博士生自我感知学习投入水平较高(M=4.17),表明教育博士生能够充分利用时间来开展学习研究活动。在学业成就方面,教育博士生通用能力(M=4.31)和学习满意度(M=4.19)均较高,这表明教育博士生在主观感知上对自己的能力提升持有较好的评价,且对教育博士期间的学习具有积极的体验。但在学位完成方面,在本研究766个样本数据中,教育博士生延期毕业602人,延期毕业率高达78.59%,反映了教育博士生在客观学业成就上的不理想状况。教育博士生主观感知到的高动机、高学习投入、高学习满意度和高能力提升与客观学业成就学业完成度较低之间存在鲜明的差异,值得进一步分析探讨。
(四)教育博士学习动机与学业成就影响机制模型检验
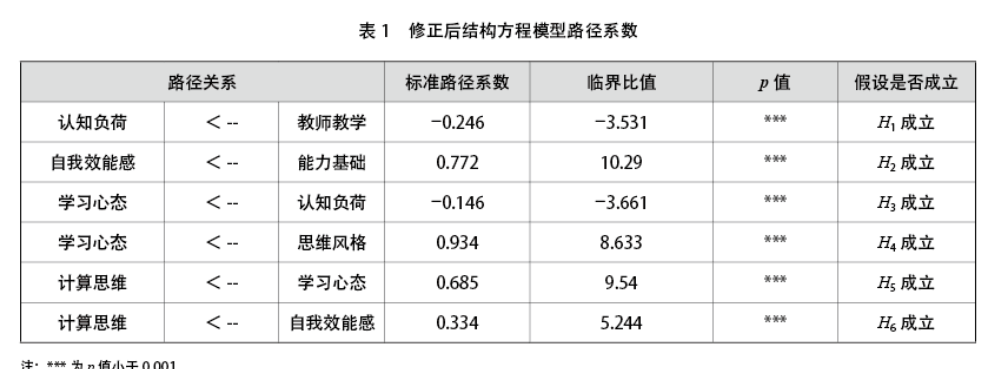
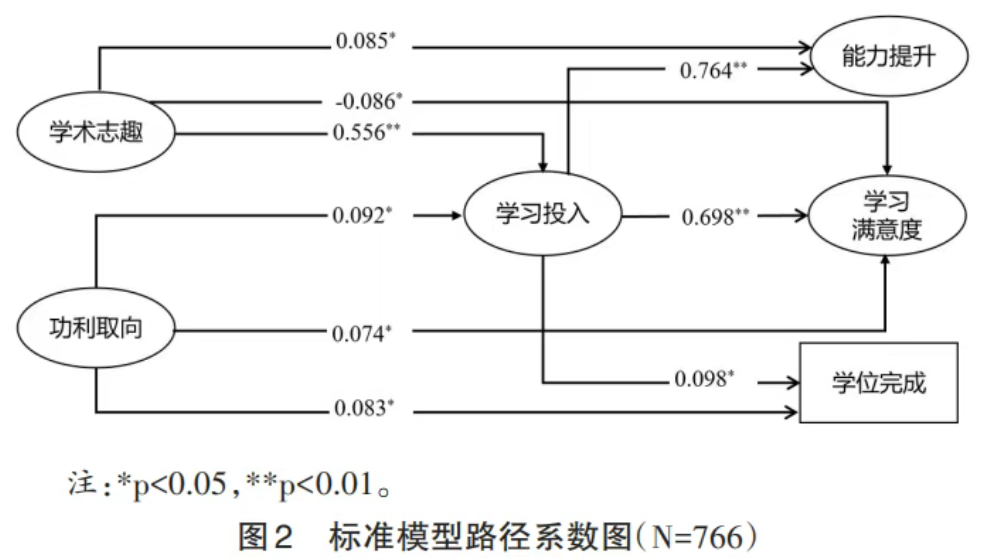
1. 结构方程模型拟合。通过结构方程模型分析教育博士生学术志趣、功利取向、学习投入、能力提升、学习满意度和学位完成情况之间的关系,结果显示模型拟合指数良好:X2/df=3.92,p<0.01,RMSEA=0.06,TLI=0.94,CFI=0.95。整体而言,教育博士生学习动机与学业成就影响机制研究假设得到支持,教育博士生学习动机通过影响学习投入,进而影响能力提升与学习满意度以及学位完成。(见图2)
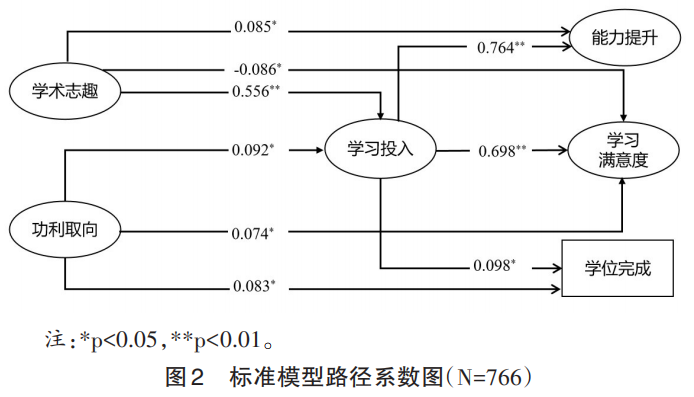
2.路径系数分析。从各变量间路径来看,(见表2)教育博士生学习动机对学业成就影响路径的系数存在差异,主要体现在以下几个方面。
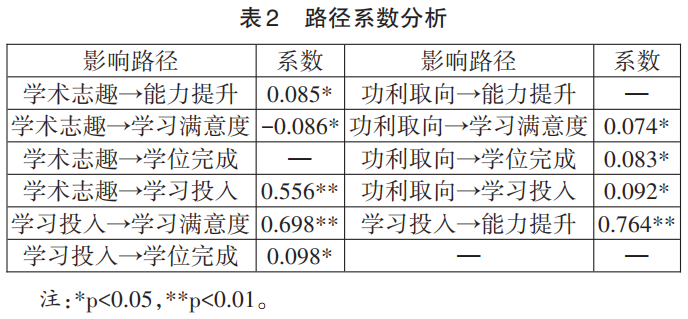
第一,教育博士生学术志趣和功利取向对学习投入的影响存在显著差异。具体来说,学术志趣对学习投入有更强的正向影响(β=0.556,p<0.01),表明学术志趣能够显著提升学生的学习投入。相比之下,功利取向对学习投入的影响较小(β=0.092,p<0.05),这表明虽然功利取向也能促进学习投入,但其效果不如学术志趣显著。
第二,教育博士生学习投入是学习满意度、能力提升和学位完成的关键预测因素。学习投入对学习满意度的影响系数为0.698(p<0.01),显示出极强的正向关系;对能力提升的影响系数为0.764(p<0.01),是所有路径中影响最强的;对学位完成的影响系数为0.098(p<0.05),虽然相对较小,但仍然显示出正向关系。这些结果表明学习投入在学业成就中有重要的价值,能显著影响教育博士生的能力提升和学习满意度,也能影响其学位完成的进程。
第三,教育博士生功利取向对学习满意度和学位完成有正向影响,其对学习满意度的影响系数为0.074(p<0.05),对学位完成的影响系数为0.083(p<0.05)。但功利取向对能力提升没有显著影响,这可能意味着功利取向更多地与学位获得与社会认可等相关,却与内在能力的提升没有直接相关。
第四,教育博士生学术志趣对学习满意度具有较弱的负向影响(β=-0.086,p<0.05)。这似乎与直觉相悖,可能的解释是教育博士生大多肩负着工作、家庭和学业的多重压力,但学术志趣与教育培养制度存在一定的偏差,从而降低其对培养过程的学习满意度。这也从侧面反映出当前院校支持体系和培养制度可能无法满足教育博士生的学术需求。
3. 学习投入的中介作用检验。为进一步验证学习投入的中介效应,本研究在模型拟合的基础上使用Amos 25.0软件通过Bootstrap法(抽样的次数设定为5000次)进行检验。研究发现,学术志趣、功利取向→学习投入→学习满意度、能力提升和学位完成的6条路径的95%置信区间都没有包括0,且p值均小于0.001,具有统计学意义。结果见表3。
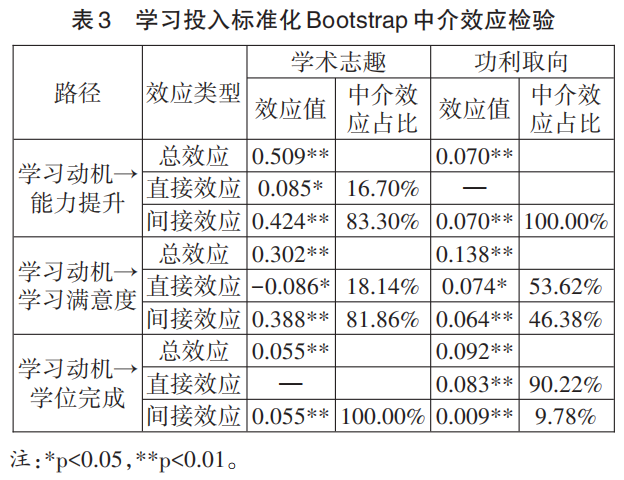
第一,在学习动机对学业成就的总效应中,学术志趣与功利取向均能显著预测能力提升、学习满意度与学位完成,且学术志趣对能力提升与学习满意度的预测程度远远高于功利取向(0.509>0.070,0.302>0.138)。但在促进学位完成方面却存在分歧,功利取向对学位完成的预测程度高于学术志趣,说明无论是学术志趣还是功利取向对于教育博士生而言都具有重要的价值,学术志趣指向能力提升与学习满意度,而功利取向更有利于学位的顺利完成。
第二,在学习动机对学业成就的中介效应中,学术志趣对学位完成与功利取向对能力提升的中介作用均属于完全中介作用,即二者均需通过学习投入促进学业成就。对于教育博士生而言,虽然学术志趣的自我评价较高,但学习投入仍是提升学业成就的重要因素。比较而言,功利取向对学位完成的中介作用属于部分中介作用,且直接效应(90.22%)占比较大,这也说明功利取向不仅能够直接影响学位获得,也能通过学习投入促进学位完成。
第三,特别值得关注的是,学术志趣对学习满意度的直接效应为-0.086,与间接效应0.388的符号相反,属于遮掩效应,即学习投入在学术志趣与学习满意度之间起到部分遮掩效应。这说明学术志趣通过学习投入对学习满意度的正向预测遮掩了学术志趣对学习满意度的负向预测,反映了当前教育博士的学习动机实质上没有得到学校教育与培养制度的有效支持,导致了学术志趣越高学习满意度较低的现实。综上,学术志趣和功利取向两种不同的学习动机对教育博士生的学习投入和学业成就具有显著的差异性影响。
4. 教育博士生学习动机影响因素回归分析。上述研究已揭示教育博士生学习动机对其学业成就的影响机制,但要全面探究教育博士生学业成就的形成机制,需要对影响教育博士生学习动机的“前因”进行系统分析,为提升教育博士生学习动机提供实证依据。已有研究表明,博士生学习动机具有动态性和情境性,受个人、学校和社会等多种因素的影响,并随时间和情境的不断变化而调整。博士生学习动机受课程教学、导师指导、学习氛围和个人因素等因素影响。课程教学质量高低可以激发博士生的学术兴趣,使博士生更愿意投入时间和精力。导师尊重博士生的研究兴趣可以增强学习动机,缺乏有效指导可能会导致博士生失去学习兴趣,最终导致学习动机低迷。博士生所处的学习环境,尤其是同伴和团队的影响,对学习动机有显著作用。良好的学习氛围能激发博士生的竞争意识和自我提升的欲望。这些因素相互作用共同影响着博士生的学习动机。
结合我国教育博士的培养现状及相关文献,本研究从个体、院校和社会支持三个层面对影响教育博士生学习动机的因素展开分析,其中,个体层面涉及学科背景、年龄、研究基础和实践经验等变量。院校层面涉及学校资源、课程教学、同伴互助、导师指导和学业管理等变量。社会支持层面涉及工作单位支持与家庭支持2个变量。其中,学科背景将教育学类专业赋值1,其他赋值2,其余变量均采用李克特五点量表计分法赋值。从回归结果来看,两个模型都通过了显著性检验。(见表4)
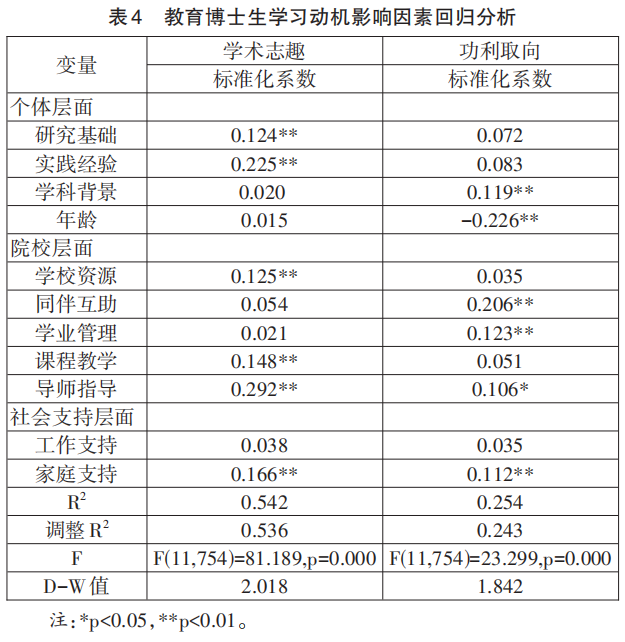
第一,在个体层面,研究基础与实践经验对学术志趣影响显著,而学科背景对功利取向影响显著,表明非教育学类博士生具有较高的功利动机。年龄对功利取向影响显著,年龄越大,功利取向越小,表明年龄较长的教育博士生追求功利性目标的驱动力降低,转而更注重通过学习解决实践问题能力的提升等。
第二,在院校层面,学校资源与课程教学对学术志趣影响显著,说明学校提供的学术资源和活动能激发和维持教育博士生的学术热情。教育博士生通过系统课程学习,能够深化对教育问题的理解,激发与维持学术研究的兴趣和热情。同伴互助、学业管理对功利取向影响显著,在同伴互助的过程中,教育博士生可能会感知到同伴的竞争压力和毕业压力,促使他们更加关注功利性结果。而院校通过及时的跟踪和考核,为教育博士生提供明确的学业进展反馈和培养质量管控,进一步激发了他们追求功利性目标的动机。值得关注的是,导师指导对学术志趣和功利取向影响均显著,且对学术志趣的影响大于功利取向(0.292>0.106)。这说明导师通过专业的学术指导和培养过程管理,有助于学生在学术道路上不断取得进步,从而增强他们的学术自信和志趣,也能督促教育博士生尽快完成学业,强化教育博士生更加关注功利性目标。
第三,在社会支持层面,家庭支持对学术志趣和功利取向影响均显著,且对学术志趣的影响大于功利取向(0.166>0.112)。这说明家庭支持不仅有利于教育博士生更专注学术研究,而且会促使教育博士生更加关注功利性目标。而工作单位支持对学术志趣和功利取向的影响均不显著。
整体而言,教育博士生学术志趣动机更多地受到培养过程中良好的学术氛围、导师的指导、高质量的课程和家庭支持等内在性因素影响,而功利取向动机更多地受到同伴间交流、学校的督促与管理等一些外在性因素影响。
三、SmartPLS结果(中介效应、调节效应)
利用PLS算法求得每条路径的路径系数值,然后利用自助法(Bootstrapping)检验路径系数的显著性,将其子样本设置为1000。
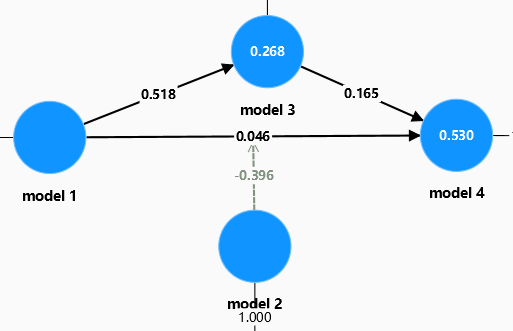
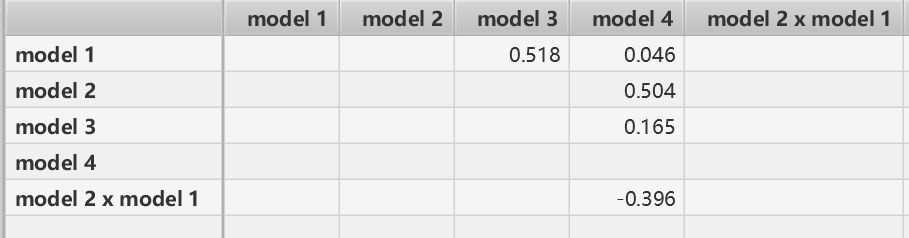
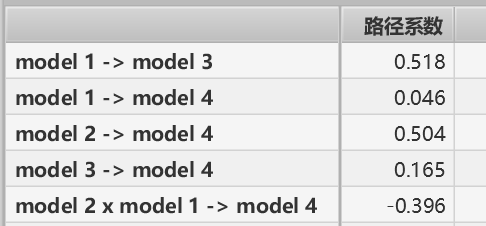
1.路径系数(直接影响/直接效应)
model 1 和 model 3 成正相关,model 1 2 3 和model 4 都成正相关;
在model 2 的调节下,model 1 和 model 4 成负相关
2.间接影响/间接效应
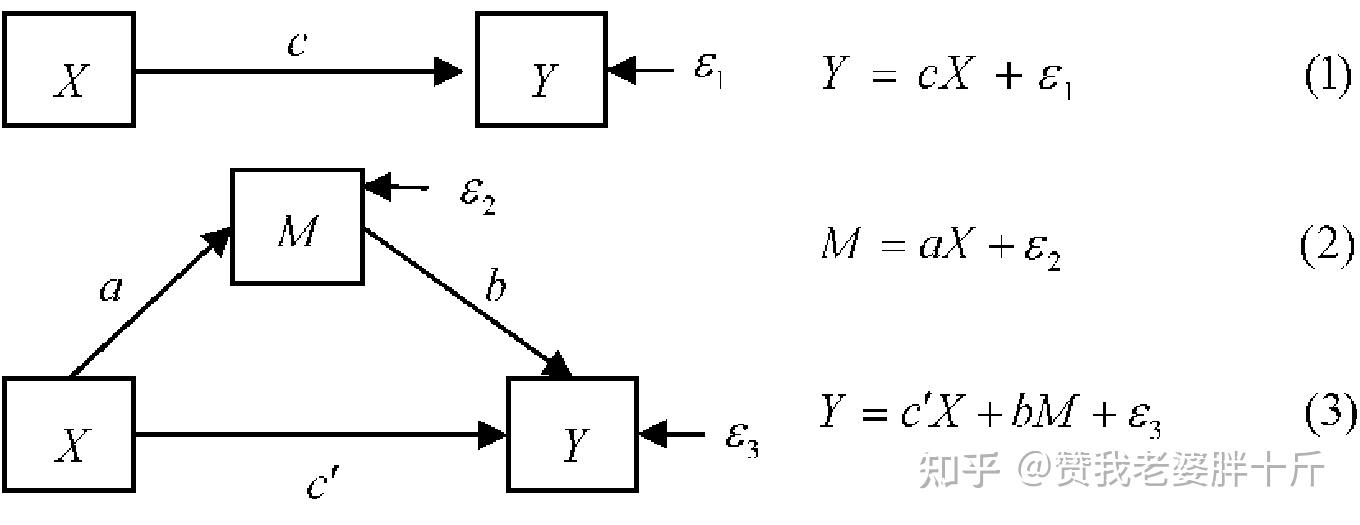
当增加一个中介变量时,X对Y的作用分为了两个部分,
其一是直接效应(c´)在中介模型中,X对Y的直接影响。
其二是间接效应(ab),X通过M对Y的影响。
3.总影响/总效应
当只考虑X和Y两个变量时,我们将X对Y的总影响称为总效应(c)。
总效应=直接效应+间接效应
4.外部负载
5.潜在变量(相关性、协方差、描述)
6.残差(外部模型/内部模型的得分/相关性)
7.简单的坡度分析
8.R方差(调整前后)
R方值是衡量回归模型拟合优度的统计量,它表示回归模型对观测值的拟合程度,代表了模型中因变量可由自变量解释的百分比。R方值的取值范围在0到1之间,R方值越大,说明回归模型对观测值的拟合程度越好。比如R方为0.5,说明所有自变量可以解释因变量50%的变化原因。
调整后R方是修正自由度的决定系数,在多元线性回归中,R方有个致命的问题,那就是随着自变量X的个数增加,R方会越来越大,R方越来越大就会认为模型拟合越来越好,但是实际上可能是由于自变量个数的增加导致的R方增大。这样看来,R方就不是一个比较客观的指标,此时将自变量个数考虑进公式中,就得到了调整后R方。
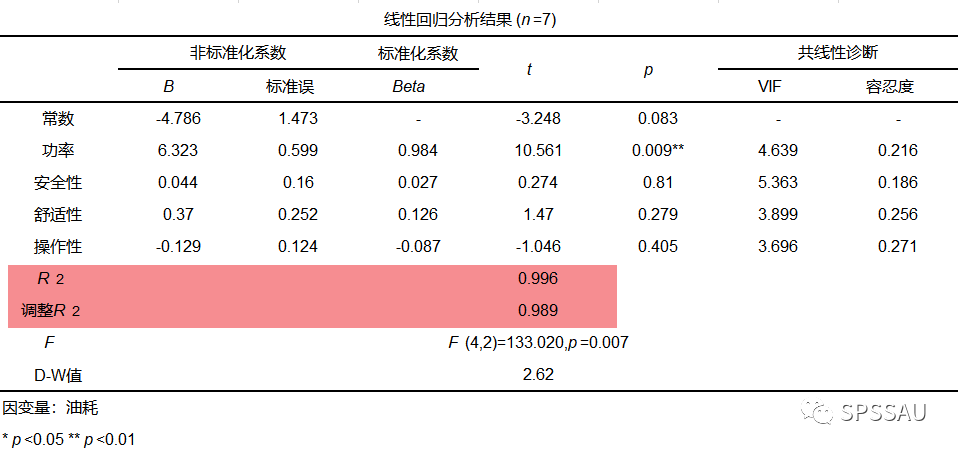
9.F平方
- 结构模型中的变量可能会受到许多不同变量的影响。
- 删除外生变量会影响因变量。
- F 方是从模型中删除外生变量时 R 方的变化。
- f 方是效应大小(>=0.02 是小;>= 0.15 是中等;>= 0.35 很大)(Cohen,1988 年)。
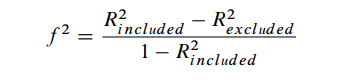
10.结构可靠性和有效性(克隆巴赫系数Cronbach's alpha、rho_a、rho_c、平均萃取量AVE)
(1)克隆巴赫系数Cronbach's alpha
Cronbach’s α(克朗巴哈系数)是一种用于衡量测量工具(如问卷、测验)内部一致性信度的统计指标。内部一致性:指同一量表中各项目是否测量同一潜在概念(如焦虑、满意度)。若项目间高度相关,则内部一致性好。
取值范围:0到1,值越高表示信度越好。一般标准:α≥0.9:极佳(如标准化考试)。
0.8≤α<0.9:良好。0.7≤α<0.8:可接受。
α<0.6:需修订或删除部分项目。
(2)rho_a、rho_c
Composite reliability (rho_c):也被称为Jöreskog’s rho,它基于所谓的“模型无误差”的情况来计算。即假设所有的测量项负载都是完美的,没有任何测量误差。
Composite reliability (rho_a):也被称为Dijkstra-Henseler’s rho,它则是将测量误差考虑在内的可靠性。即它容忍测量项中存在的误差。因此,通常比rho_c更为保守。
一般来说,如果这两个值都达到了可接受的水平(通常大于0.7),则可以认为该模型的内在一致性是良好的。如果rho_a低于0.7,但rho_c大于0.7的话,可能需要重新调整测量模型了,例如通过删除一些测量项来提高一致性。
(3)平均萃取量AVE
在进行收敛效度分析时,则可使用AVE值(Average Variances Extracted,平均方差萃取值)和CR(Composite Reliability,组合信度)这两个指标进行分析,如果每个因子的AVE值大于0.5,并且CR值大于0.7(也有说法认为CR大于0.6即可),则说明具有良好的收敛效度;同时,一般要求每个测量项对应的因子载荷系数(Factor loading)值大于0.7。
区分效度(Discriminant validity):强调潜在变量之间的区分性。AVE的平方根值大于“该因子与其它因子间的相关系数”,此时说明具有良好的区分效度。
11.区分效力(HTMT异质-单质比率、Fornell-Larcker Criterion)
(1)异质-单质比率HTMT
也就是特质间相关(between-trait)与特质内(within-trait)相关的比率。它是不同构面间指标相关的均值相对于相同构面间指标相关的均值的比值。
HTMT表格结果用于区分效度的判断,可以取代的是AVE平方根表。
HTMT < 0.85(严格标准为0.90):说明两个构念间具有较好的区分效度。
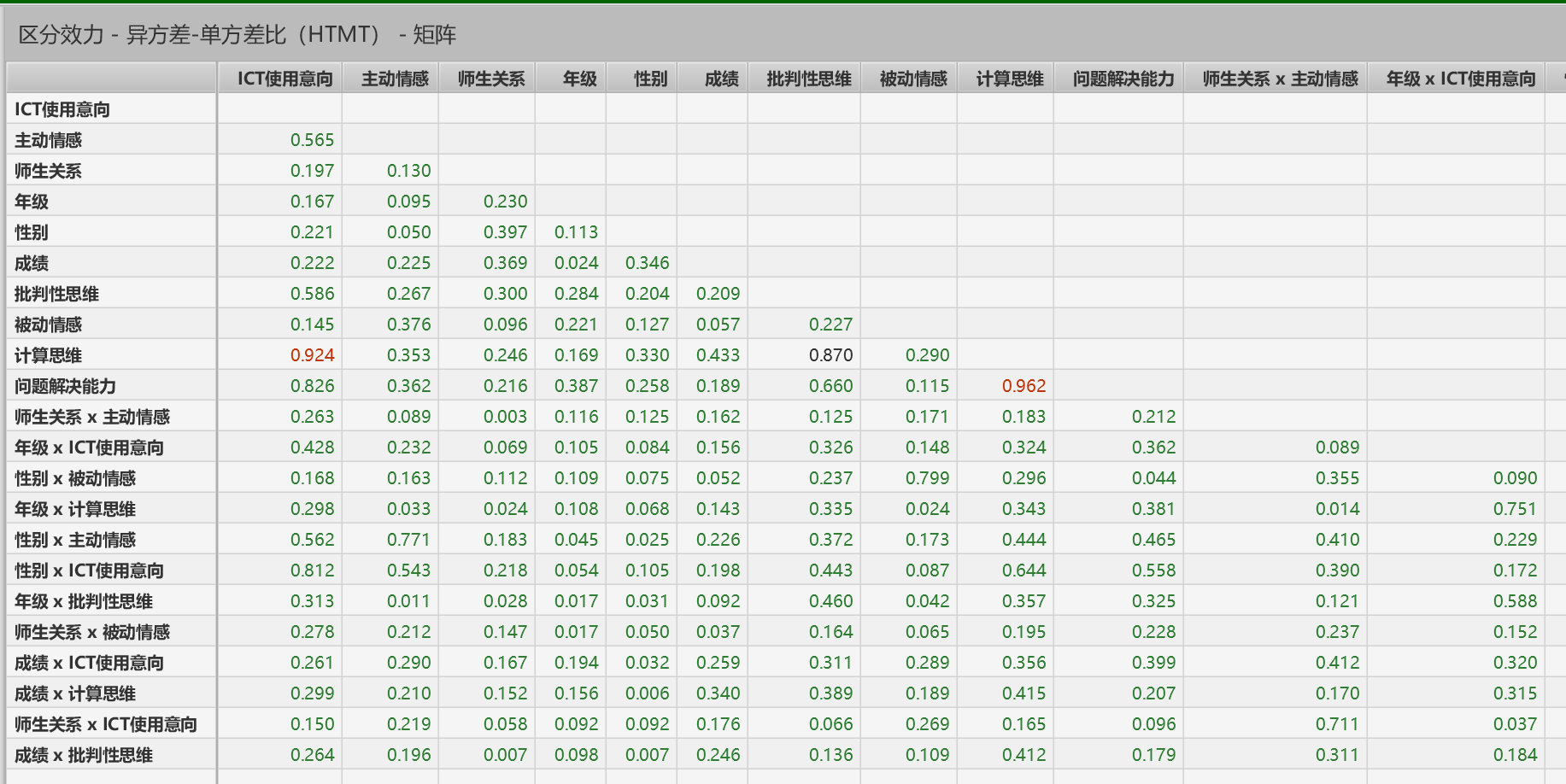
(2)Fornell-Larcker标准
成立条件:构面的平均萃取变异量(AVE)是否大于该构面与其它构面相关系数的平方。这句话可以这样表达,即构面平均萃取变异量的平方根是否大于该构面与其它构面的相关系数。
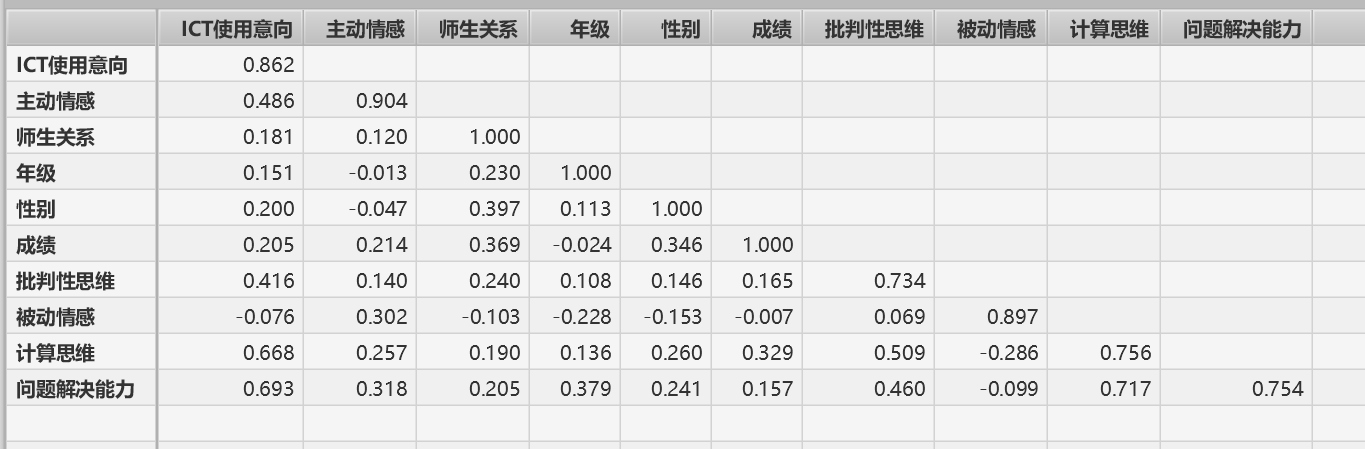
12.共线性统计(VIF、Tolerance、相关系数矩阵)
多重共线性可以用统计量VIF(variance inflation factor)进行检测。
VIF的平方根表示变量回归参数的置信区间能膨胀为模型无关的预测变量的程度。一般认为VIF开根号大于2表明存在多重共线性。
一般认为,VIF值大于5或者10表明存在严重的多重共线性,需要进一步处理。
容忍度(Tolerance):这是VIF的倒数,较低的容忍度值(通常小于0.1)表明高共线性。
相关系数矩阵:检查预测变量之间的相关系数。高度相关(例如,相关系数大于0.8或小于-0.8)可能指示共线性。
13.模型匹配(SRMR、d_ULS、d_G、RMS_theta奇异方差、NFI)
SRMR即标准化均方根残差(Standardized root mean square residual)一般认为SRMR<0.08表示模型拟合良好,SRMR<0.1表示该模型拟合在可接受范围内。
NFI即规范拟合度指标(Normed fit index),NFI介于0-1之间,NFI越接近1代表拟合越好,NFI>0.9表示模型拟合可接受,因此不建议采用其作为拟合指标
d_ULS即欧几里得距离平方(the Squared Euclidean Distance)
d_G即测地线距离(Geodesic Distance)
它们用来对经验协方差矩阵和复合因子模型隐含协方差矩阵的差异进行基于bootstrap法的统计推断.对于d_ULS和d_G的拟合标准,应该将他们的点估计值与对应的置信区间比较,置信区间的上限若大于点估计值,则表明模型拟合良好。SmartPLS默认提供95%和99%置信区间的上限。除此之外,SRMR也可以用同样的方法来判断模型拟合是否良好。
RMS_theta为外模型残差的均方根残差协方差矩阵,其值越接近0代表模型拟合越好,一般认为RMS_theta<0.12代表模型拟合良好。
14.模型选择标准(BIC贝叶斯信息标准)
AIC(Akaike Information Criterion)和BIC(Bayesian Information Criterion)是两种常用的模型选择准则,用于在给定一组模型中选择最佳模型。
贝叶斯信息准则,也称为Bayesian Information Criterion(BIC)。贝叶斯决策理论是主观贝叶斯派归纳理论的重要组成部分。是在不完全情报下,对部分未知的状态用主观概率估计,然后用贝叶斯公式对发生概率进行修正,最后再利用期望值和修正概率做出最优决策。
可通过比较AIC、BIC值的大小来比较模型的拟合效果,如果模型的AIC值和BIC值越小,说明模型估计越准确。

三、结构方程模型图
四、结构方程模型分析应该怎么写呢?要写哪些内容呢?
1.案例1
使用PLS-SEM来评估测量模型并评估本研究收集的数据的有效性和可靠性。在PLS-SEM分析中,四个参数 - Outer Loading, Cronbach’s Alpha, Composite Reli- ability, and Average Variance Extracted - 必须分别超过0.7、0.7、0.7、0.7和0.5的阈值,以确保数据可靠性和有效性(Hair等,2022)。
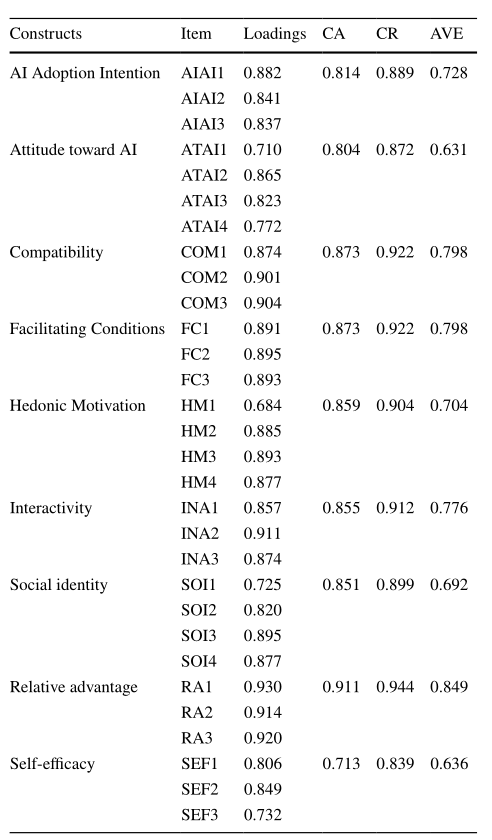
为了在模型的构建体之间建立判别有效性,杂型单观(HTMT)比率(用于评估判别有效性)必须小于0.9(Henseler等人,2015年)。表4显示了所有变量均不同,因为所有构造的HTMT值彼此相比均低于0.9(Hair等,2022; Henseler等,2015)。
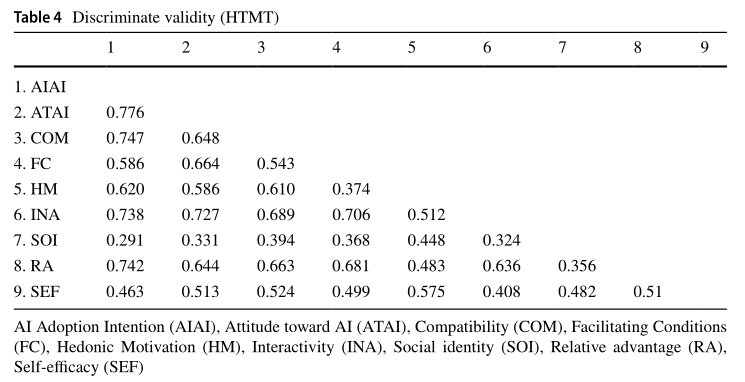
2.Multivariate skewness and kurtosis
根据Hair等人的建议,在这项研究中评估了多元偏度和峰度。研究结果表明,数据集并未证明多元正态性。具体而言,Mardia’s表明多元偏度(β= 9.951,p <0.01)和多元峰度(β= 121.655,p <0.01),证实了数据缺乏多变量正常性。
偏度主要用于判断数据的偏斜程度。偏度S>0,拖尾在右边,为正偏态,偏度S<0,拖尾在左边,为负偏态,偏度S≈0为正态,绝对值越大,偏态越严重。峰度是用于判定数据分布的陡缓程度。当峰度K>0时,分布的峰态陡峭(高尖),当峰度K<0时,分布的峰态平缓(矮胖),当K≈0时,可认为数据服从正态分布(不胖不瘦)。
3.路径系数,标准误差,T值和p值
因此,根据Becker等人,该研究介绍了结构模型的路径系数,标准误差,T值和p值。为此,按照Ramayah等人概述的方法,采用了10,000个子样本的重新采样方法。该研究还建立了评估产生的假设的标准,如表5所述。与Hahn and Ang(2017)的一致性,即P值不足以确定假设的意义,该研究利用了标准的组合,包括P值,置信区间和效果(表5)。
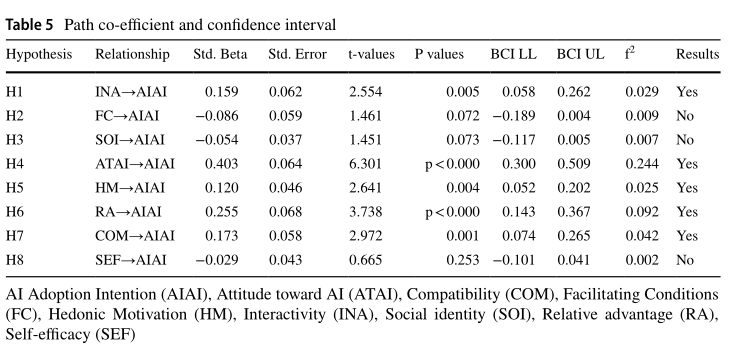
标准回归系数(Standard regression coefficient,Std. Beta ):
标准差(Standard Deviation):
标准误差(Standard Error):
通过样本(sample)估计总体(population)的时候,样本分布的标准差。
t-values:
P values:
BCI LL:
BCI UL:
f2:
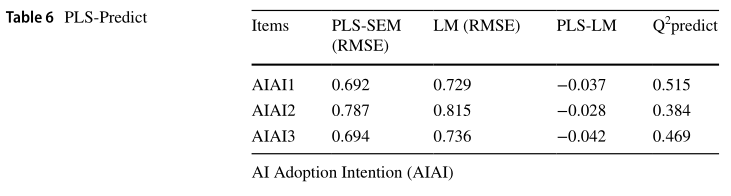
表5列出了这项研究的发现。根据这项研究的发现(图2),相互作用与AI采用意图显着相关(β= 0.159,t = 2.554和p <0.05),表明H1在统计上得到了支持。但是,该研究揭示了促进条件与AI采用意图之间微不足道的关联。AI采用意图(β= 0.173,t = 2.972和p <0.05)。这表明H7在统计上接受。但是,这项研究的发现无法确认自我效能和AI采用意图之间的任何关联(β= -0.029,t = 0.665和p> 0.05),表明不支持H8。
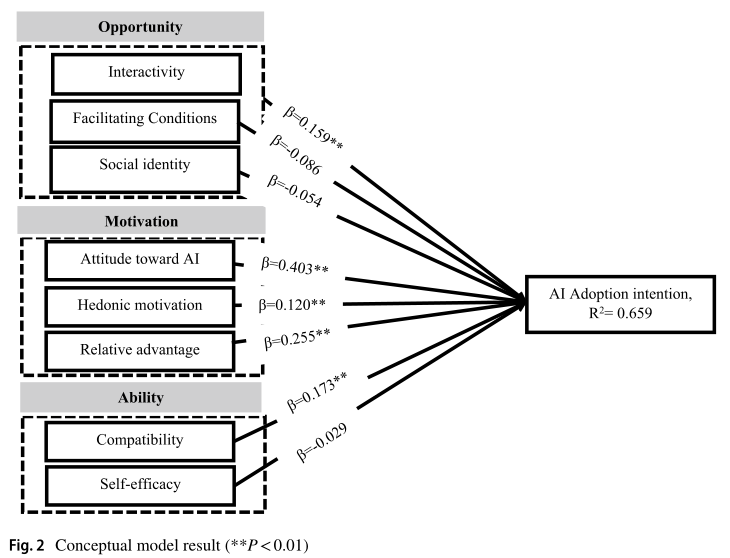
根据Shmueli等人(2019年)的研究,部分最小二乘预测(PLS-PREDICT)是一种在案例级别生成项目或构造的预测技术。它采用了部分最小二乘测量方法,并采用了十倍的交叉验证程序,样本量超过200,以评估模型的预测意义。 Shmueli等人(2019年)的发现表明,如果所有部分最小二乘根平方均方根误差(PLS-RMSE)值低于线性回归模型均方根误差(LM-RMSE)的值,则模型被认为具有很高的预测能力。相反,如果每个单独的PLSRMSE值都超过其LM-RMSE对应物,则不会确定结构模型的预测重要性。但是,如果大多数PLS-RMSE值较低,则表明研究中采用的模型表现出适度的预测潜力。如果仅少数值较低,则表明该模型具有较低的预测功效。表6中列出的结果表明,部分最小二乘模型(PLS-RMSE)中的所有误差都小于线性回归模型(LM-RMSE)中的误差。因此,本研究中使用的模型表明了高度的预测能力。
2.案例2
(一)信效度检验
对于小样本而言,偏最小二乘法(Partial Least Square,PLS)具有更佳的因果关系分析能力,故使用SmartPLS 3.0软件对问卷的信效度进行分析,并建立结构方程模型,对关系模型及研究假设进行检验。问卷的信度及收敛效度检验结果如表3所示;问卷的区别效度检验结果如表4所示。
表3 信度及收敛效度检验值
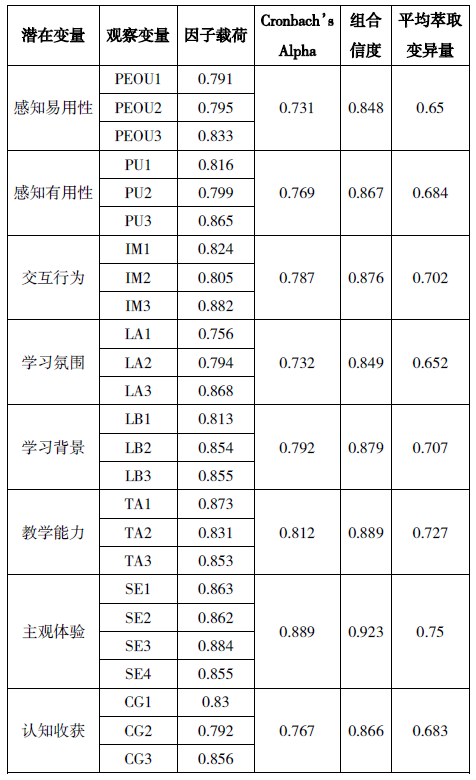
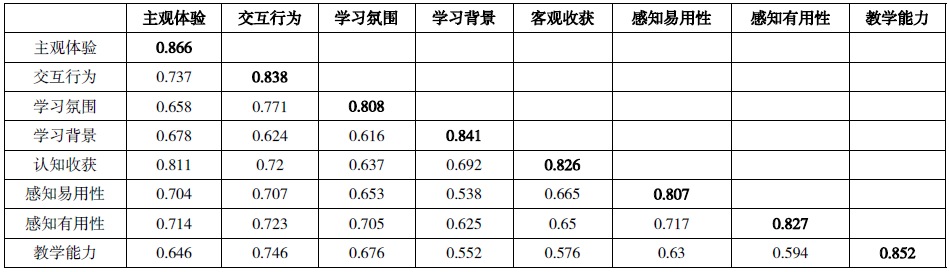
表4 区别效度检验值
1.信度检验
通过计算Cronbach’s Alpha值、组合信度(CR)、平均萃取变异量(AVE)及因子载荷对问卷的整体信度进行检验。一般来说,Cronbach’s Alpha值大于0.9表示非常可信,在0.7与0.9之间表示很可信,CR值的判定标准与Cronbach’s Alpha相同。在模型信度检验中,由表3可知,学生学习预备、教师教学能力、感知易用性、感知有用性、交互行为、学习氛围、主观体验、认知收获等八个维度的Cronbach’s Alpha值在0.731~0.889之间,均大于0.70,其组合信度在0.848~0.923之间,均大于0.8,属于高信度区间,说明潜在变量的内在质量良好。综合以上评价指标,该测量模型的信度较好。
2.效度检验
在模型效度检验中,采用平均萃取变异量及因子载荷等指标项进行模型效度判别。各潜在变量的平均萃取变异量均大于0.5,且各个观察变量问题项的因子载荷均大于0.7,表明其具有很好的收敛效度;另外,如表4所示,各个构念之间的相关系数均小于AVE的平方根,表明本文中构念的区别效度良好。综合上述评价指标,该测量模型的效度良好。
(二)结构方程模型的建立及分析
1.拟合优度检验
拟合优度是SmartPLS中用来衡量结构方程模型整体预测效果的重要指标,值在0到1之间,数值越大模型拟合度越好。
其公式为:
![]()
。其中,Community是共性方差,一般要求共性方差大于0.50,R2是判定系数。马丁·韦策尔斯(Martin Wetzels)等认为,GOF值的三个临界值为0.10、0.25、0.36。GOF的值在0.10~0.25之间时,表示拟合度较弱;GOF的值在0.25~0.36之间时,表示拟合度适中;GOF的值大于0.36,表明拟合度较好[22]。通过上述GOF的公式进行计算得到模型中的
![]()
,
![]()
=0.550,GOF=0.458(大于0.36),因此该模型的拟合度良好。
2.路径系数分析
在SmartPLS 3.0中建立的结构方程模型如图2所示。
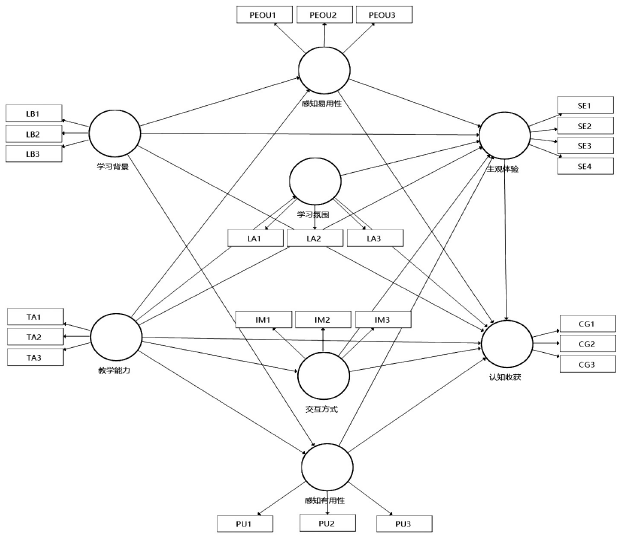
图2 结构方程模型图
首先利用PLS算法求得每条路径的路径系数值,然后利用自助法(Bootstrapping)检验路径系数的显著性,将其子样本设置为1000。路径系数的显著性可通过P值进行判断,当P值小于0.05时,路径系数显著,假设成立。假设检验结果如表5所示。
表5 假设检验结果
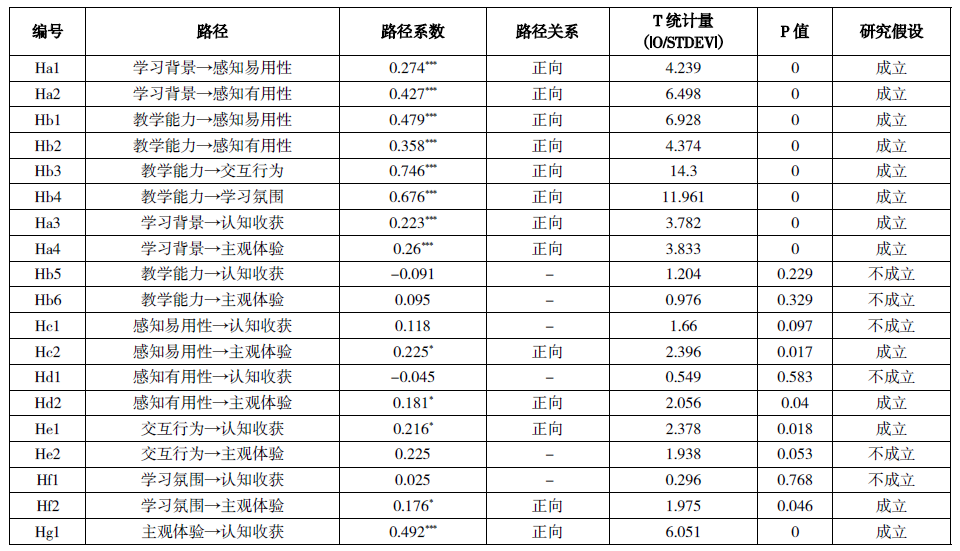
注:*、**、***分别表示P≤0.05、P≤0.01、P≤0.001(下同)
基于假设检验结果对初始关系模型进行重绘,最终结果如图3所示。学生的学习背景对其学习过程中的感知易用性和感知有用性均有正向显著影响,说明充分的混合式学习背景、相关平台使用经历能够显著影响学生学习过程中的感知体验。此外,学习背景对最终的认知收获和主观情感体验均有显著正向影响,即学习背景是学生在混合式学习中收获良好学习效果的基础和前提。教师教学能力对学习过程维度中的四个变量均有显著正向影响,说明教师教学能力是影响学生学习过程的重要因素。一方面,能够直接影响学生的感知体验;另一方面,经由教学组织影响学生的互动体验和对学习氛围的感知。
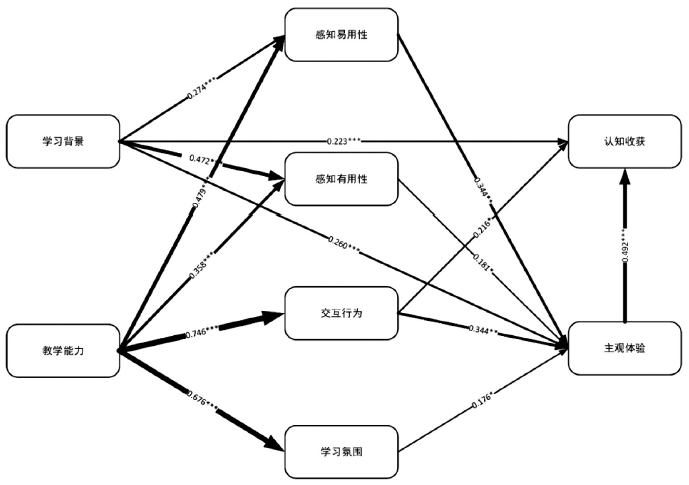
图3 经检验的关系模型图
从学习过程到学习结果这一区间内,感知易用性、感知有用性、交互行为、学习氛围均能显著正向影响学生对混合式学习的主观情感体验,即能影响学生对混合式学习方式的积极态度。由此可见,学习过程对学习结果中学生的情感态度有重要的正向作用。同时,交互行为也能显著影响学生的客观认知收获。学生的主观情感体验会对其客观认知收获产生显著影响。
3.影响效应分析
本文主要从变量间的总效应及间接效应两种角度,分析学生混合式学习中学习预备、学习过程和学习结果三个阶段各要素之间的作用机制。
(1)总效应和直接效应分析
由表6可知,以教学能力为自变量,教师教学能力对各因变量的总效应程度由高到低依次为:交互行为(β=0.746)、学习氛围(β=0.676)、感知易用性(β=0.479)、主观体验(β=0.426)、感知有用性(β=0.358)、认知收获(β=0.337),说明教师教学能力对学生学习过程产生的作用略大于学习结果。
表6 总效应检验
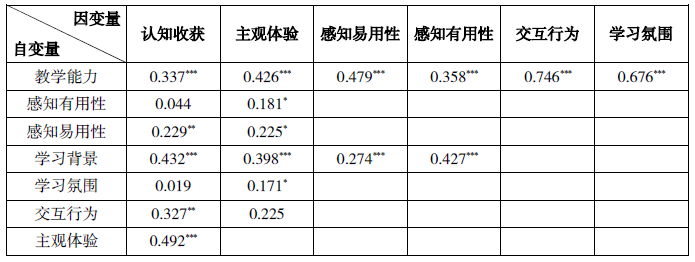
以学习背景为自变量,其对各因变量的总效应程度由高到低依次为:认知收获(β=0.432)、感知有用性(β=0.427)、主观体验(β=0.398)、感知易用性(β=0.274),说明学习背景与学习过程、学习结果均存在明显的正相关关系。
(2)间接效应分析
间接效应也称中介效应,即在结构模型中,变量A能够通过变量B对变量C产生影响。经由间接效应检验发现,在本文中,存在感知有用性、感知易用性、主观体验及交互行为四个中介变量,如表7所示。
表7 间接效应检验
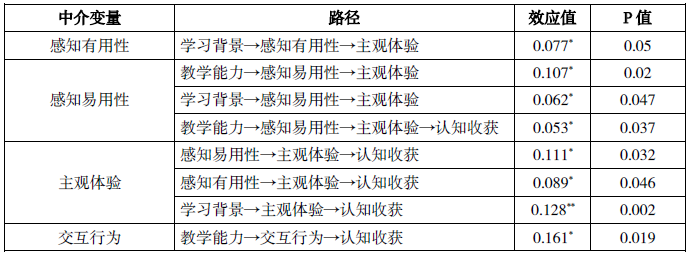
经检验,学习背景能够经由感知有用性对主观体验产生间接作用;教学能力、学习背景均能经由感知易用性对主观体验产生间接作用;感知易用性、感知有用性、学习背景能够通过影响主观体验对认知收获产生正向影响;教师教学能力能够经由交互行为对学生认知收获产生正向影响。
3.案例3
(一)信效度检验
采用SPSS 25软件计算克隆巴赫系数(Cronach's Alpha)对量表信度的检验进行判断。采用Cronach's Alpha系数对模型中每个测量项目的内部一致性与稳定性进行检验,该系数只要超过0.7,其信度就可接受。如表1所示,量表各题项及各潜在变量的Cronach′s Alpha系数均在0.9以上,说明题项内部一致性较好,信度可以接受。
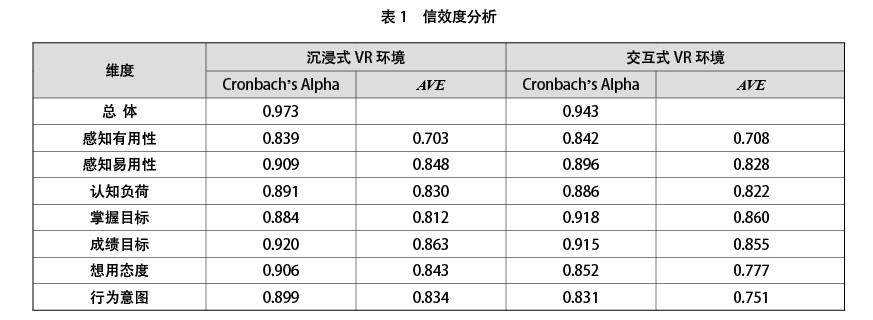
平均提取方差值可以作为收敛效度与区别效度的检验指标,一般认为,若AVE>0.5,则模型内部具有良好的一致性。效度检验通过SmartPLS 4分析,分析结果如表1所示,沉浸式VR接受度模型各维度AVE均大于0.7,内部具有良好的一致性;交互式VR接受度模型各维度AVE均大于0.70,内部具有良好的一致性。
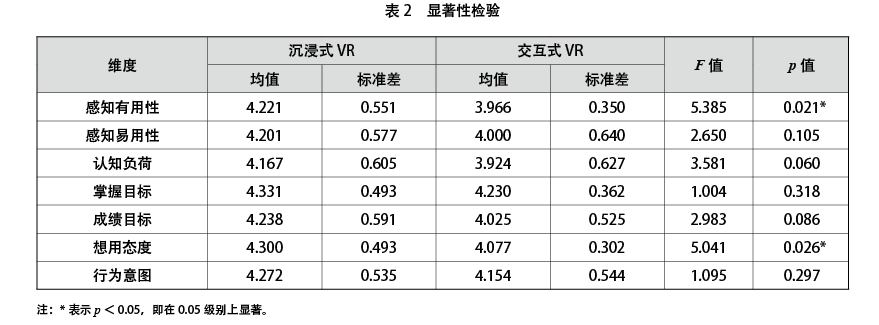
(二)显著性检验
显著性检验通过SPSS 25软件,采用单因素分析对比两种VR环境下各维度是否有显著性差异,分析结果如表2所示。各维度均值分析表明,沉浸式VR环境下的各个维度得分均高于交互式VR环境;单因素分析表明,两种VR环境在感知有用性和想用态度两个维度上有显著差异,且两个维度上沉浸式VR环境的得分高于交互式VR环境,其余维度无显著差异。
(三)假设检验
影响路径系数(Path Coefficients)可以反映模型中两个潜在变量间的关系强度,以此对研究假设进行检验。通过将数据导入SmartPLS 4中,采用偏最小二乘法(PLS-SEM),根据研究模型分析各潜在变量间的影响路径系数,分析结果及假设检验结果如表3所示。
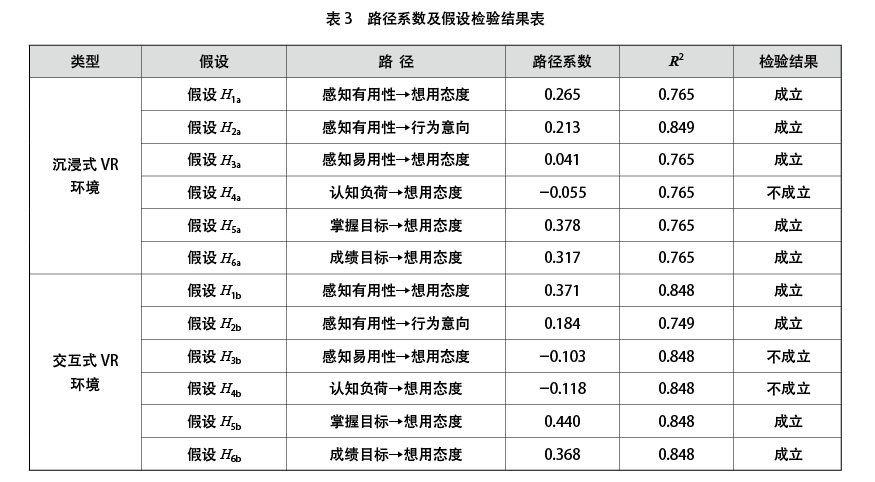
沉浸式VR环境的思政课中,想用态度R2(被解释方差比例)为76.5%,行为意向R2为84.9%,表明模型内部解释性好,研究模型捕获到了自变量较为重要的影响因素。感知有用性对想用态度有正向影响,假设H1a成立;感知有用性对行为意向有正向影响,假设H2a成立;感知易用性对想用态度有正向影响,假设H3a成立;掌握目标对想用态度有正向影响,假设H5a成立;成绩目标对想用态度有正向影响,假设H6a成立。
交互式VR环境的思政课中,想用态度R2(被解释方差比例)为84.8%,行为意向R2为84.9%,表明模型内部解释性好,研究模型捕获到了自变量较为重要的影响因素。感知有用性对想用态度有正向影响,假设H1b成立;感知有用性对行为意向有正向影响,假设H2b成立;掌握目标对想用态度有正向影响,假设H5b成立;成绩目标对想用态度有正向影响,假设H6b成立。
(四)结果分析
实证结果表明,本研究构建的模型解释性较好。研究发现,在两种类型VR环境的思政课中呈现出如下特点。
第一,基于VR的思政课接受度较高。单因素分析结果中,沉浸式VR环境和交互式VR环境各维度的得分均在4分(比较同意)左右。想用态度维度上,沉浸式VR环境(4.300)>交互式VR环境(4.077);行为意图维度上,沉浸式VR环境(4.272)>交互式VR环境(4.154)。这表明基于VR的思政课接受度较高,同时,在思政课中,学生在沉浸式VR环境中的接受度要高于交互式VR环境。
第二,感知有用性与想用态度在两种VR环境中有显著差异。通过单因素分析发现,在两种类型的VR环境中,感知有用性(p<0.05)与想用态度(p<0.05)有显著性差异,沉浸式VR环境的得分要高于交互式VR环境。可能原因是沉浸式VR环境的思政课主要通过全景VR一体机为学生还原教学情境,帮助学生理解教学内容、感受课程情感价值,更加贴合思政课情感与价值的教学需要。
第三,感知易用性与VR认知负荷在两种VR环境中均对想用态度无明显影响。通过结构模型的效验发现,在沉浸式VR环境的思政课中,感知易用性、认知负荷对想用态度的影响路径系数分别为0.041、-0.055;在交互式VR环境的思政课中,感知易用性、认知负荷对想用态度的影响路径系数分别为-0.103、-0.118。与TAM应用于其他领域的研究结果不同的是,在两种VR环境下,感知易用性对于想用态度没有较强的正向影响,认知负荷对接受度没有正向影响。这意味着在VR环境的思政课中,学生并不因为操作困难、难以接受VR环境所蕴含的教学信息等原因而影响其对于VR技术的想用态度。
第四,影响想用态度和行为意图的主要变量是感知有用性、掌握目标与成绩目标。通过结构模型的效验发现,在沉浸式VR环境的思政课中,感知有用性、掌握目标、成绩目标对想用态度的影响路径系数分别为0.265、0.378、0.317;在交互式VR思政课中,感知有用性、掌握目标、成绩目标对想用态度的影响路径系数分别为0.371、0.440、0.368。这说明在两种VR环境中,对想用态度和行为意图有影响的主要变量是感知有用性、掌握目标与成绩目标。当大学生有积极的、合理的成就目标时,不论是掌握目标还是成绩目标,都对其在思政课中接受和使用VR有积极影响,使其愿意在思政课中使用VR。
4.案例4
(四)分析方法
1. 模型检验
运用 SmartPLS3.0 软件对本科/高职教育满意度模型质量进行检验,包括对信度指标、效度指标和模型整体适配度指标等进行检验。与前两轮一样,通过Bootstrap方法对模型进行检验后可知,本科/高职教育期望、教育质量、教育公平、教育环境和总体满意度的内部一致性系数约大于等于0.7,组合信度(CR)均大于0.8,区别效度(AVE)约大于等于0.6;各维度测定系数约大于等于0.4,各指标基本符合模型质量检验要求。另外,为确保满意度模型具有较好的解释力,要求总体满意度R2值要大于0.65。此次调查,本科/高职教育总体满意度 R2分别为 0.729/0.790,均大于0.65标准(表2,表3)。总体来看,模型中的各指标均能较好反映潜变量(维度),在实际运算过程中可纳入PLS结构方程模型进行运算。
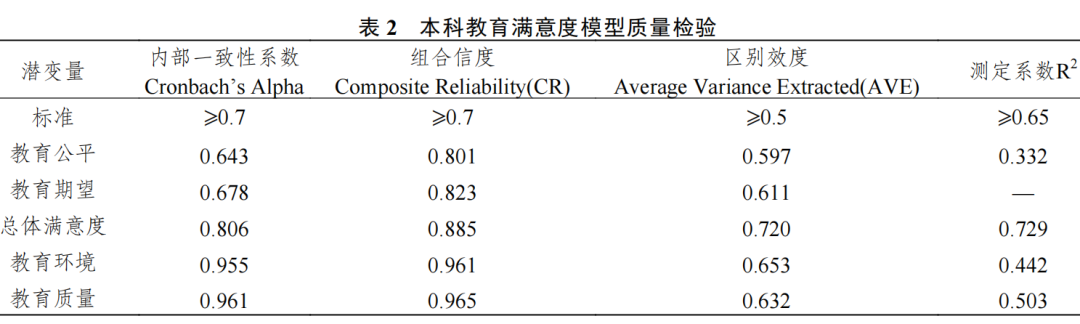
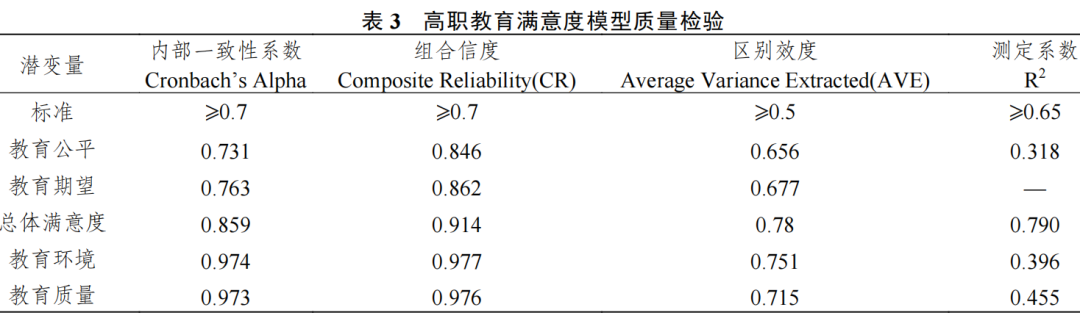
2. 高等教育满意度指数计算方法
高等教育满意度总指数由本科教育满意度指数和高职教育满意度指数加权计算而成。具体过程是先分别依据PLS结构方程模型得到本科和高职学生每个测量指标的权重系数,利用每位学生的测量指标值和权重系数进行加权,可得到每位本科学生和高职学生各潜变量指数值。计算公式为:
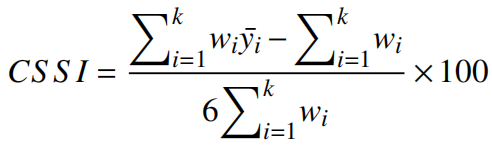
其中,yi是学生满意度的测量指标,wi是各个测量指标对应的权重,k是满意度测量指标的个数,以总体满意度为例,k=3。
若将潜变量中各显变量的权重进行归一化之后,该方程可进一步简化为:
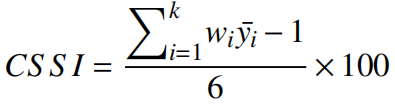
全国高等教育满意度总指数,采用加权系数进行计算,加权系数是各地区当年毕业生人数占全国毕业生总人数的比例。高等教育满意度指数采用百分制表示。
3. 质性分析
2021年高等教育满意度调查新增了质性分析方法,运用Nvivo软件对抽样本科生和高职生的开放性问答题进行了质性编码分析和关键词提取,从大量开放性问答题中提炼出学生最关心、最希望学校改进的问题,以便对我国高等教育的下一阶段发展提供建议参考。据分析,开放性问答题的前十关键词包括学生、学校、希望、加强、教学、实践、课程、设施、专业、管理。在对学校工作的改进建议中,累计被提及超过100条建议的维度(由多到少排列)见表4。

作为补充,分别对研究生和教师的开放性问答题也进行了相关分析,累计被提及超过100条的改进工作建议的维度中,相较本科生和高职生更加关注实习实践、教学、师资、就业、设施设备,研究生对校园内资源信息的公平公开以及心理教育则更为关切。本科教师和高职教师均关注教师队伍建设、学校管理、教学和人才培养理念,回答主要包含教师队伍建设、学校管理、教学、人才培养理念、实习实践等问题,其中,高职教师比本科教师更加关注实习实践工作的改进。
4. 显著性检验
从样本显著性检验分析结果来看,一是东部和中部地区、东部和西部地区、中部和西部地区总体满意度检验结果显示p值均小于0.001,意味着高等教育总体满意度在区域分布上存在统计意义上的显著性差异。二是本科和高职的总体满意度t=3.608,p=0.00,差异性显著,表明本科和高职学生总体满意度具有统计学差异。
5.案例5
(一)配对样本 t 检验
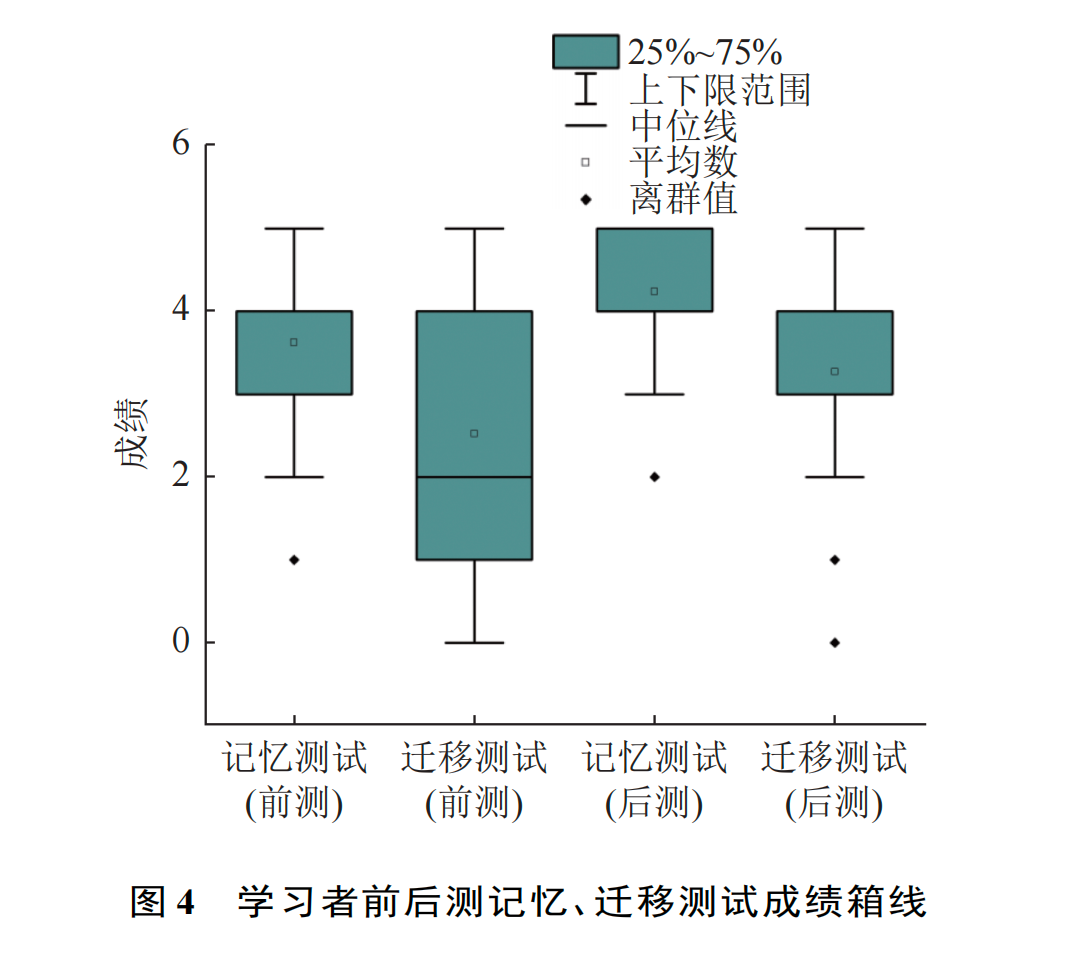
本研究对学习者准实验前后的随堂检测数据进行配对样本 t 检验,结果表明,学生的记忆性知识(MD=0.131,t=4.694,p<0.01)和迁移性知识(MD=0.174,t=4.322,p<0.01)有显著差异,且后测成绩均高于前测(见图 4)。
(二)测量模型分析
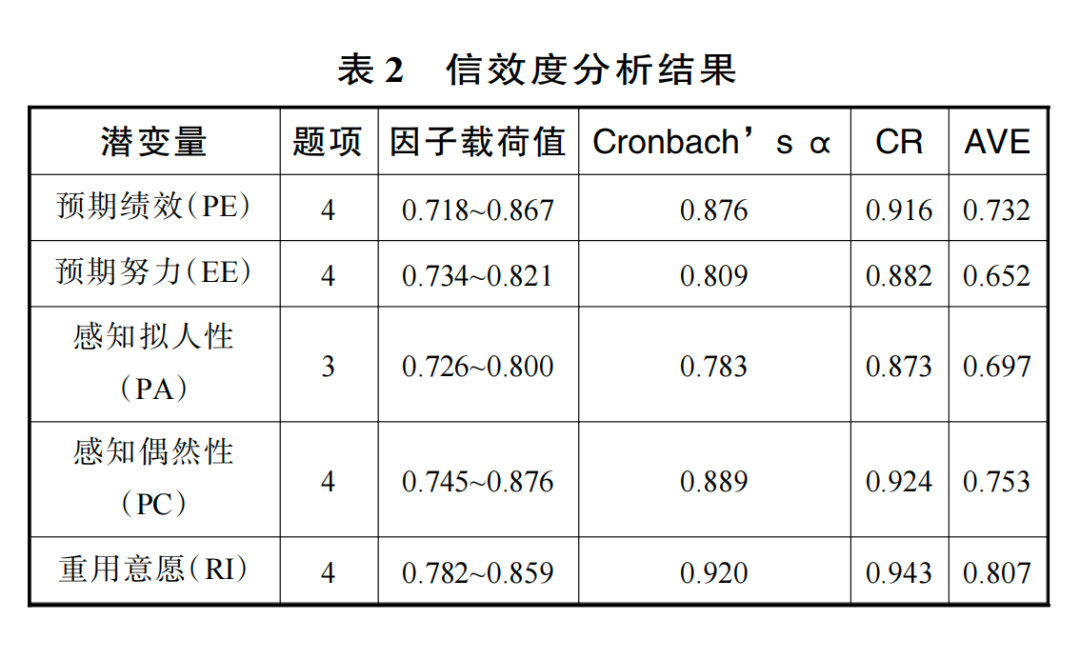
本研究采用主成分分析法进行探索性因子分析,检验测量工具的结构效度。降维结果显示,数据的 KMO 值为 0.801,大于 0.6,且通过 Bartlett 球形检验(p<0.05),适合进行因子分析。所有测量题项的因子载荷均在 0.7 以上,且大于其他潜变量间的交叉因子载荷,符合各项指标要求(见表 2)。信度分析结果显示, Cronbach’s α 值均大于 0.7,具有良好的内部一致性(Hair et al.,2019)。
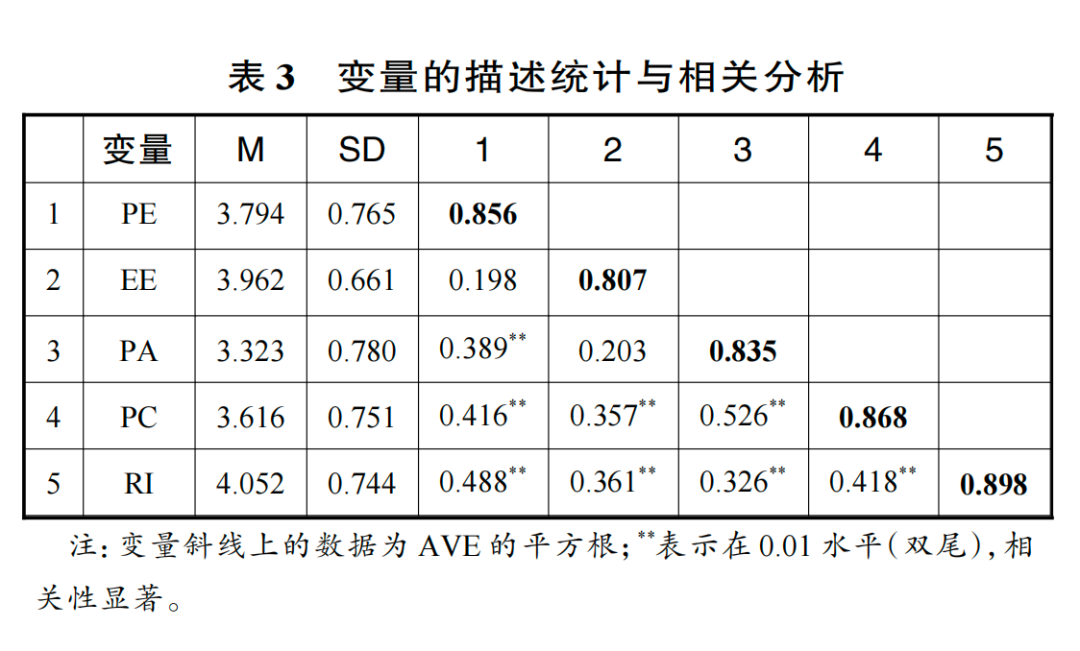
由验证性因子分析结果可知,各变量的提取方差(AVE)最小值为 0.652,大于 0.5;组合信度(CR)最小值为 0.873,大于 0.8。这表明该测量模型收敛效度较好(Hair et al.,2019)。同时,潜变量间的相关系数均小于各潜在变量 AVE 的算数平方根(见表 3),异质—单质比率(Heterotrait-Monotrait Ratio of Correlations,HTMT)小于 0.85(见表 4),这表明该测量模型区分效度良好(Hair et al.,2019)。
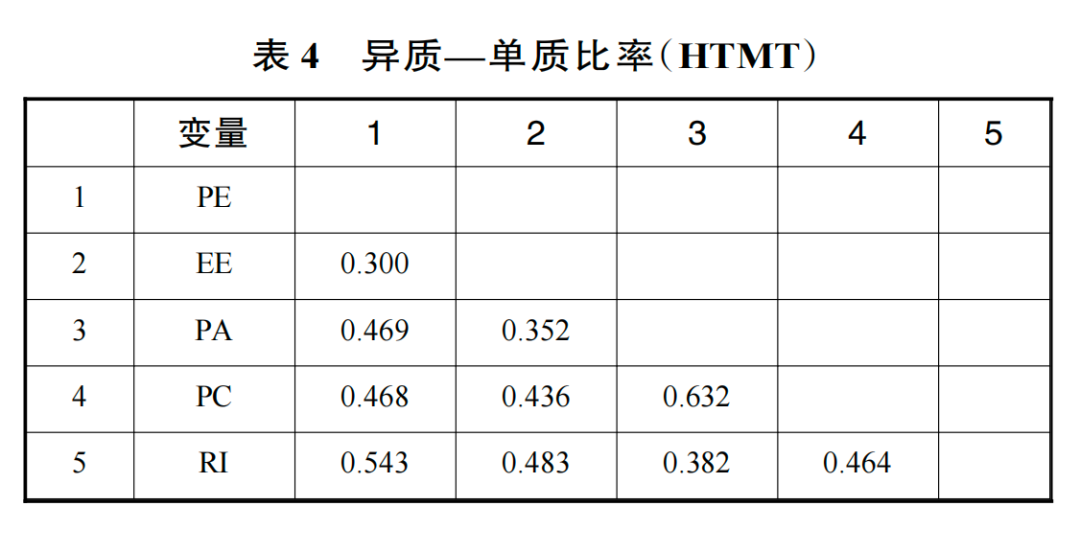
为检验变量间的同源误差程度,本研究进行了 Harman 单因素检验。结果显示,公因子一在未经旋转前解释的变异量为 38.042%,未达半数,即没有发生单一因子解释大部分变异量的情况。因此,本研究不存在严重的共同方法偏差(Podsakoff et al.,2003)。结构模型的多重共线性通过潜变量的方差膨胀系数(Variance Inflation Factor,VIF)评估,潜变量间的 VIF 值在 1.153~1.523 之间,均小于 3,即不存在多重共线性问题(Hair et al.,2019)。
(三)结构模型分析
本研究利用 SmartPLS4.0 建立偏最小二乘结构方程模型,分析学习者基于生成式人工智能与元宇宙开展翻转课堂学习的重用意愿,运用包含 5000 个子样本和 95% 置信区间的偏差矫正自举法(Bootstrapping)评估全样本(N=86)结构模型假设关系(Hair et al.,2021)。本研究进一步选用 PLSpredict 算法验证模型,折叠 10 次且重复 10 次进行验证(见表 5)。在 Q predict^2 大于 0 的基础上,该模型的均方根误差(root Mean Squared Error,RMSE)均小于线性回归模型(linear regression Model,LM),表明该模型预测能力良好(Shmueli et al.,2019)。
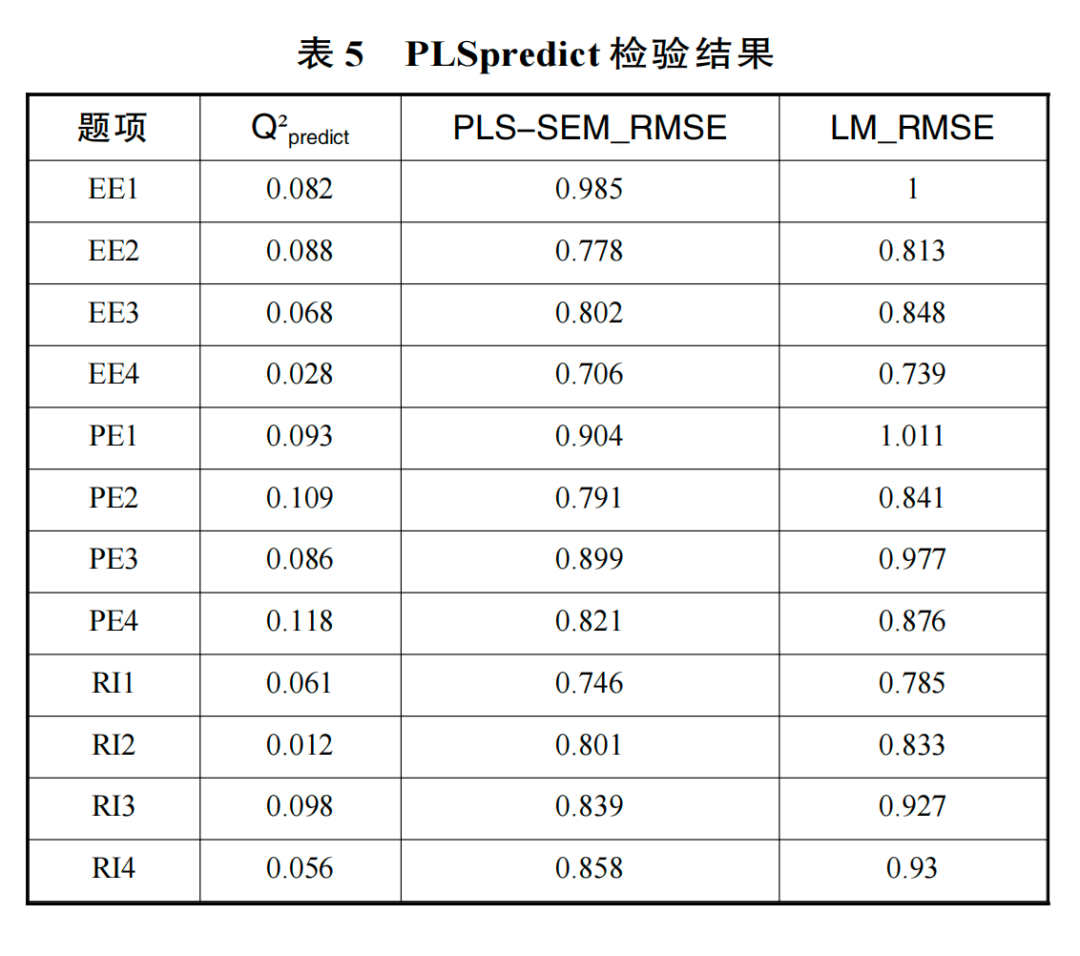
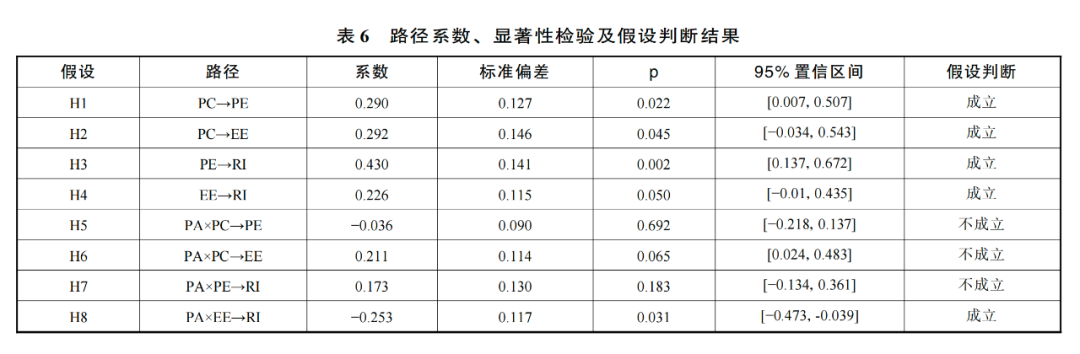
数据显示,感知偶然性对预期绩效(β=0.290,p<0.05)、预期努力(β=0.292,p<0.05)存在显著正向影响,表明 H1、H2 成立。预期绩效(β=0.430, p<0.005)与预期努力(β=0.226,p≤0.05)对学习者重用意愿存在显著正向影响,表明 H3、H4 成立。这说明学习者感知偶然性对重用意用的作用受预期绩效与预期努力的中介影响。让人意外的是,感知拟人性的调节作用均不显著,表明 H5、H6、H7 不成立。但感知拟人性在预期努力和重用意愿之间存在负向调节作用,表明 H8 成立。重用意愿的总体解释度 R2 解释值为 0.419(见表 6 和图 5)。
6.案例6
(一)二阶变量与批判性思维相关性分析
用Pearson 相关性分析各变量之间及与批判性思维的相关性,结果如表1 所示。
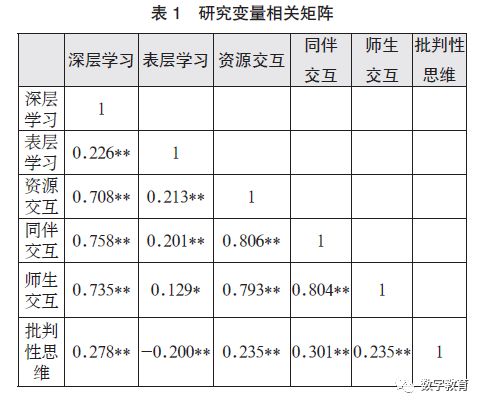
在自变量与因变量的相互关系中,在线交互与批判性思维呈现相关性,在线交互中各个维度与批判性思维皆呈显著正相关(资源交互,r=0.235,P < 0.01;同伴交互,r=0.301,P < 0.01;师生交互, r=0.235,P < 0.01),也就是通过交互策略的优化能够在一定程度上促进学习者的批判性思维发展。
自变量与中介变量的相互关系中,同伴交互与深层学习的相关度较高(r=0.758,P < 0.01),说明了在线交互有助于提高学生的深层学习动机和深层学习策略;在线交互的各变量均与深层学习达到了0.7 以上的显著水平。而在线交互中的各变量与表层学习也呈现显著正相关关系,但低于深层学习取向与在线学习交互的相关度,说明在线学习交互对于学生学习动机和学习策略有正向影响。
中介变量深层学习(r=0.278,P <0.01)与批判性思维的关系呈现显著正相关,而表层学习与批判性思维之间呈现显著负相关关系(r=-0.200,P <0.01), 符合学习过程理论模型的两种学习取向定论,表层的学习动机和学习策略对学习者批判性思维有负向影响。
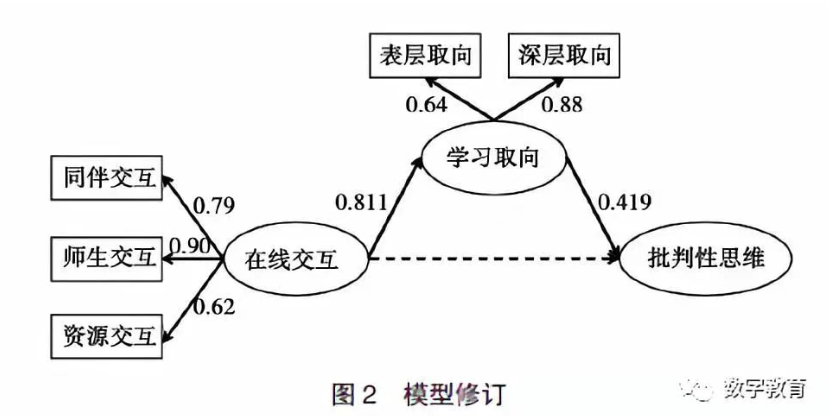
(二)结构模型检验
从上述内容可以看出,在线交互、学习取向的二阶变量与批判性思维具有一定的相关性,在一定程度上可以映射出一阶变量之间的关系。然而各个变量之间关系究竟如何还需要更进一步探究,在对各变量相关性进行分析的基础上,使用结构方程模型进行直接效应的检验,结果如表2 所示。
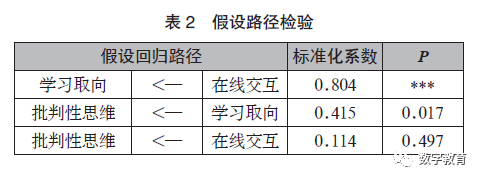
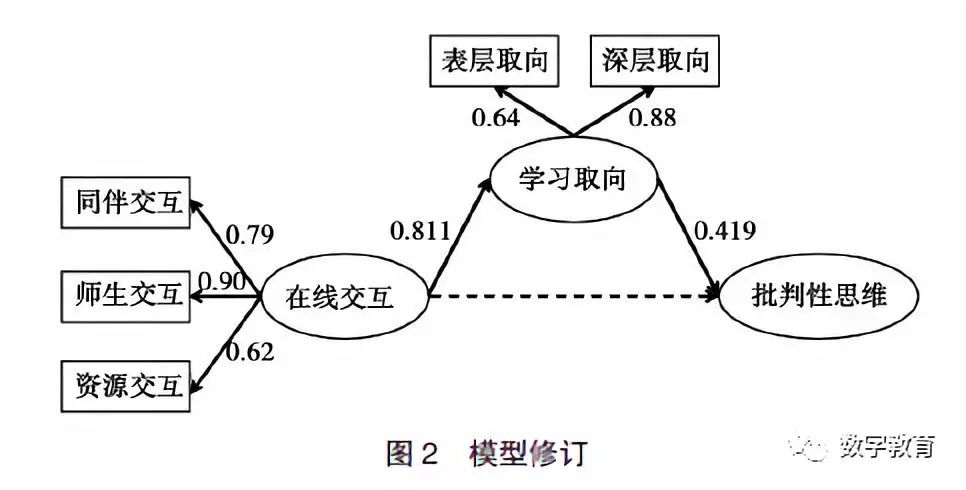
如表2 所示,在线交互对学习取向具有直接正向影响(β=0.804,P < 0.001);学习取向对批判性思维也具有直接的正向影响(β=0.415,P <0.05); 在线交互对批判性思维不具有直接作用(β=0.114, P>0.05)。然而从表1 可知,不同交互维度都与批判性思维具有正相关,因此为更进一步探究二者之间的关系,需要对去中介效应进行检验,以验证二者之间是否存在间接效应。
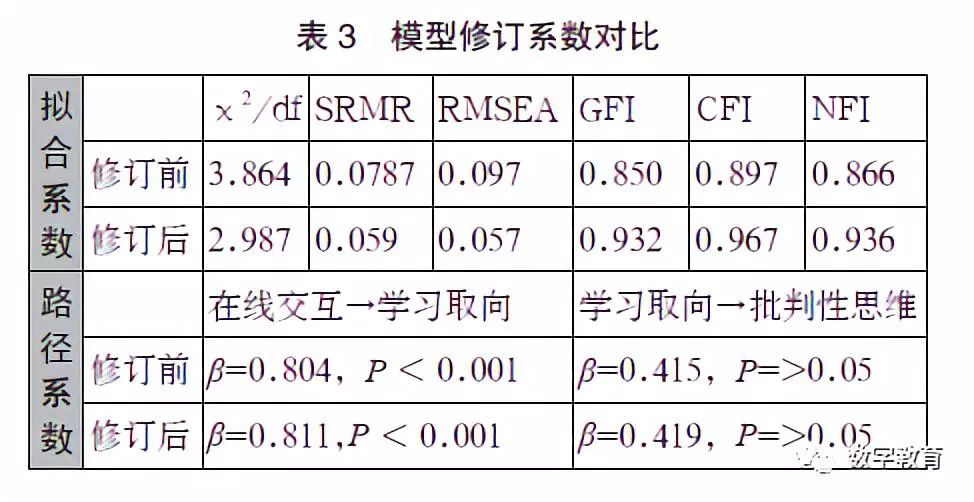
首先建立结构方程模型,模型包括在线交互、学习取向、批判性思维三个潜变量,通过验证性因素发现模型拟合度尚可(χ2/df=3.864,SRMR=0.0787, R M S E A = 0 . 0 9 7 , G F I = 0 . 8 5 0 , C F I = 0 . 8 9 7, NFI=0.866)。其次,根据温忠麟等人的研究,在只有一个中介变量的前提下,中介效应为自变量、中介变量、因变量之间系数的乘积[18],所以本研究的中介变量效应系数为0.804×0.415=0.334,结果显著,中介变量学习取向在本研究具有完全中介作用。
在上述研究的基础上,精简模型,删除在线交互对批判性思维的直接影响路径。再次进行模型拟合度检验(χ2/df=2.987,SRMR=0.059,RMSEA=0.057, GFI=0.932,CFI=0.967,NFI=0.936),在线交互对学习取向的影响依然显著(β=0.811,P < 0.001), 学习取向对批判性思维的正向影响依然显著(β=0.419, P <0.05),模型拟合度更加优秀,回归系数更加显著, 说明本研究模型修订具有一定的合理性,模型修订前后对比如表3所示。修订完成的模型图如图2 所示。

















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









