






一:设计思路
数据去重的 最终目标是让 原始数据中 出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是reduce的 输入应该以 数据作为 key,而对value-list则 没有要求。当reduce接收到一个<key,value-list>时就 直接将key复制到输出的key中,并将value设置成 空值。
在MapReduce流程中,map的输出<key,value>经过shuffle过程聚集成<key,value-list>后会交给reduce。所以从设计好的reduce输入可以反推出map的输出key应为数据,value任意。继续反推,map输出数据的key为数据,而在这个实例中每个数据代表输入文件中的一行内容,所以map阶段要完成的任务就是在采用Hadoop默认的作业输入方式之后,将value设置为key,并直接输出(输出中的value任意)。map中的结果经过shuffle过程之后交给reduce。reduce阶段不会管每个key有多少个value,它直接将输入的key复制为输出的key,并输出就可以了(输出中的value被设置成空了)。
二:代码
package exer1;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FileMerge1 {
//此类继承自Mapper类,负责重写Map方法
public static class map extends Mapper<LongWritable, Text, Text, NullWritable> {
//读取输入的第一行文本设为line,类型为text
private static Text line = new Text();
//重写map方法
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
line = value;
context.write(line, NullWritable.get());
}
}
//此类继承Reducer类,负责重写reduce方法
public static class reduce extends Reducer<Text, NullWritable, Text, NullWritable>{
//重写reduce方法
@Override
protected void reduce(Text key, Iterable<NullWritable> value,
Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
//1获取job
//传递配置信息
Configuration conf = new Configuration();
Job job = Job.getInstance(conf ,"去重");
//2设置jar路径
//关联jar包
job.setJarByClass(FileMerge1.class);
//3关联mapper和reducer
//mapper,reducer,driver建立联系,通过job纽带连载一起
job.setMapperClass(map.class);
job.setReducerClass(reduce.class);
//4设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//5设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//6设置输入路径和输出路径
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7提交job,结束程序
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
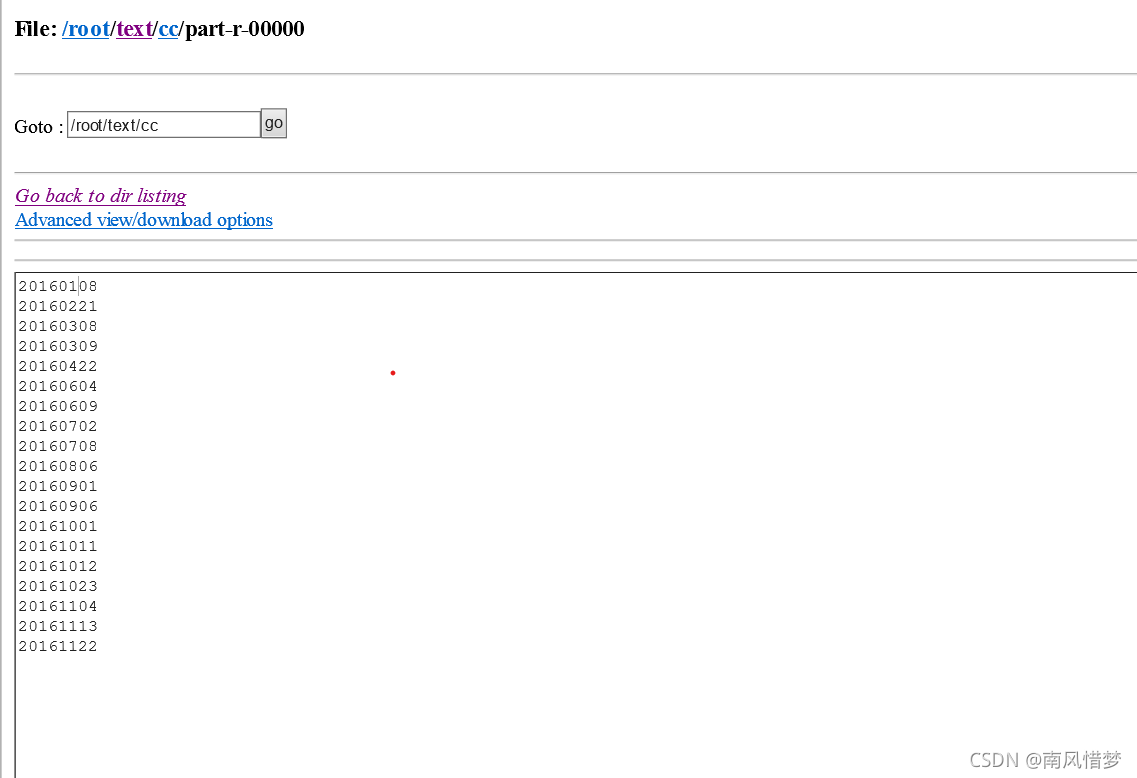
三:目标文件
A:
20160708
20161113
20160702
20160906
20161011
20160901
20160108
20160609
20160221
20160308
20161001
20161012
20160309
20161023
20161104
20160806B:
20160708
20161113
20160422
20160604
20161122
20160308
20161001
20161012四:将本地文件提交到HDFS目录
使用上传命令
hdfs dfs -put /(路径) /(将要上传到的hdfs路径)
五:将java程序导出为jar包
导出jar包
六:在虚拟机上运行jar包,并开始任务
hadoop jar /(jar包) /(上传的hdfs目录) /(hdfs 输出路径)
七:运行成功


















 3030
3030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











