







Flink快速入门
Flink概念
Flink是什么?
官网介绍:Apache Flink® — Stateful Computations over Data Streams
翻译:Apache Flink ——数据流上的有状态计算

Flink定义:
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
数据可以被作为 无界 或者 有界 流来处理。
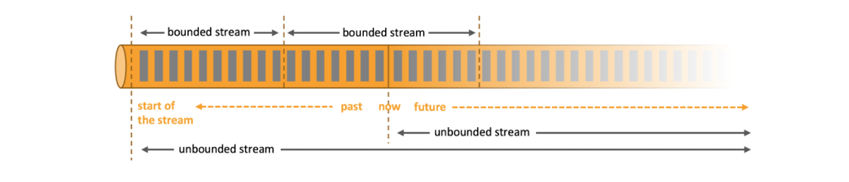
1.无界流:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
2.有界流: 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
Flink组件栈

从下至上:
1、部署:Flink 支持本地运行(IDE 中直接运行程序)、能在独立集群(Standalone 模式)或者在被 YARN、 Mesos、K8s 管理的集群上运行,也能部署在云上。
2、运行:Flink 的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理。
3、API:DataStream、DataSet、Table、SQL API。
4、扩展库:Flink 还包括用于 CEP(复杂事件处理)、机器学习、图形处理等场景。
Flink名词介绍
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
Flink整个系统包含三个部分:
•Client:
Flink Client主要给用户提供向Flink系统提交用户任务(流式作业)的能力。
•TaskManager:
Flink系统的业务执行节点,执行具体的用户任务。TaskManager可以有多个,各个TaskManager都平等。
•JobManager:
Flink系统的管理节点,管理所有的TaskManager,并决策用户任务在哪些Taskmanager执行。JobManager在HA模式下可以有多个,但只有一个主JobManager。
Flink系统提供的关键能力:
•低时延提供ms级时延的处理能力。
•Exactly Once提供异步快照机制,保证所有数据真正只处理一次。
•HAJobManager支持主备模式,保证无单点故障。
•水平扩展能力TaskManager支持手动水平扩展。
Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性。
Flink应用场景
以阿里为例:

Flink角色分工
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









