






项目背景
针对特定领域或特定任务问答场景,通用大模型存在术语不精准、逻辑不严谨等问题,本项目通过领域微调构建高效智能问答系统,提升模型对专业内容的生成质量,结合前后端形成可落地应用方案。
环境准备
算力平台
https://www.autodl.com/
稳定组合:PyTorch 2.1.0+Python 3.10+Cuda 12.1,RTX 4090 * 1卡(就用1卡吧,多卡真用不起了)
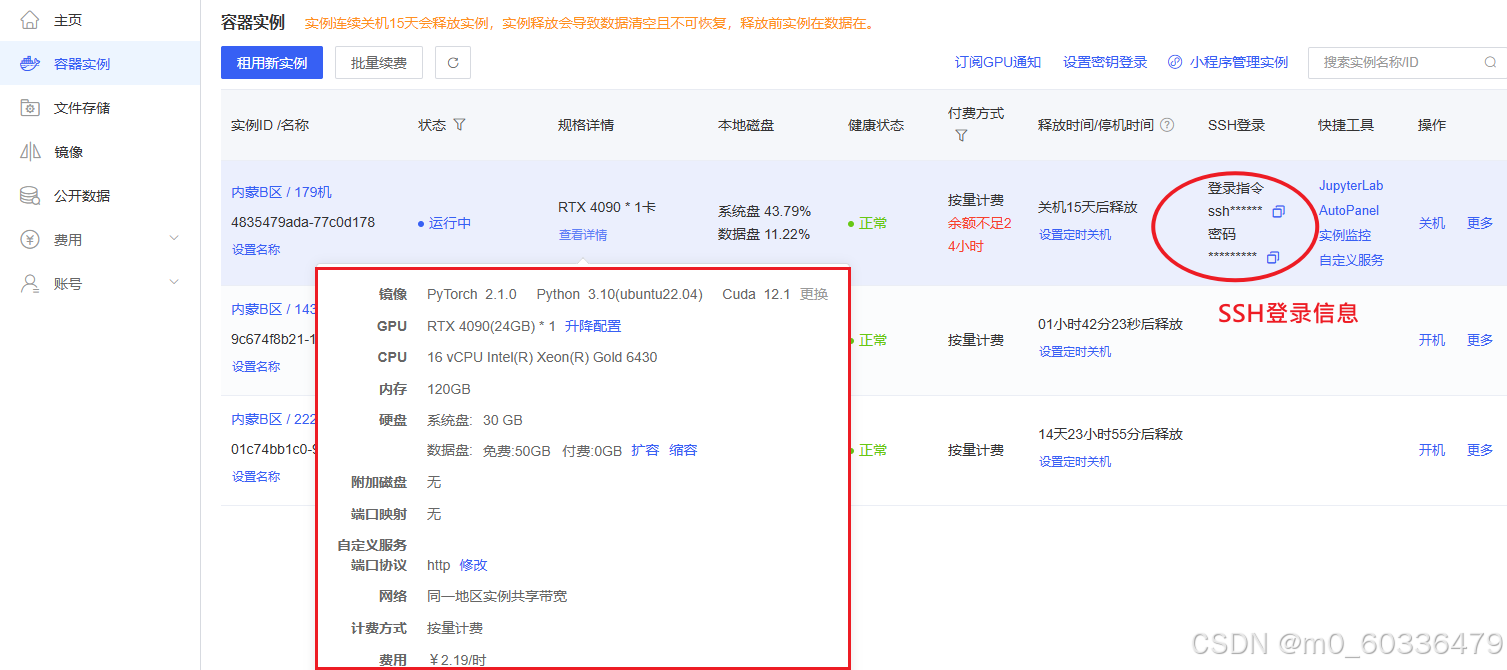
VSCode
使用本地VSCode进行远程开发,需要安装插件Remote-SSH,再进行配置。
配置参照:AutoDL帮助文档,写的挺详细。
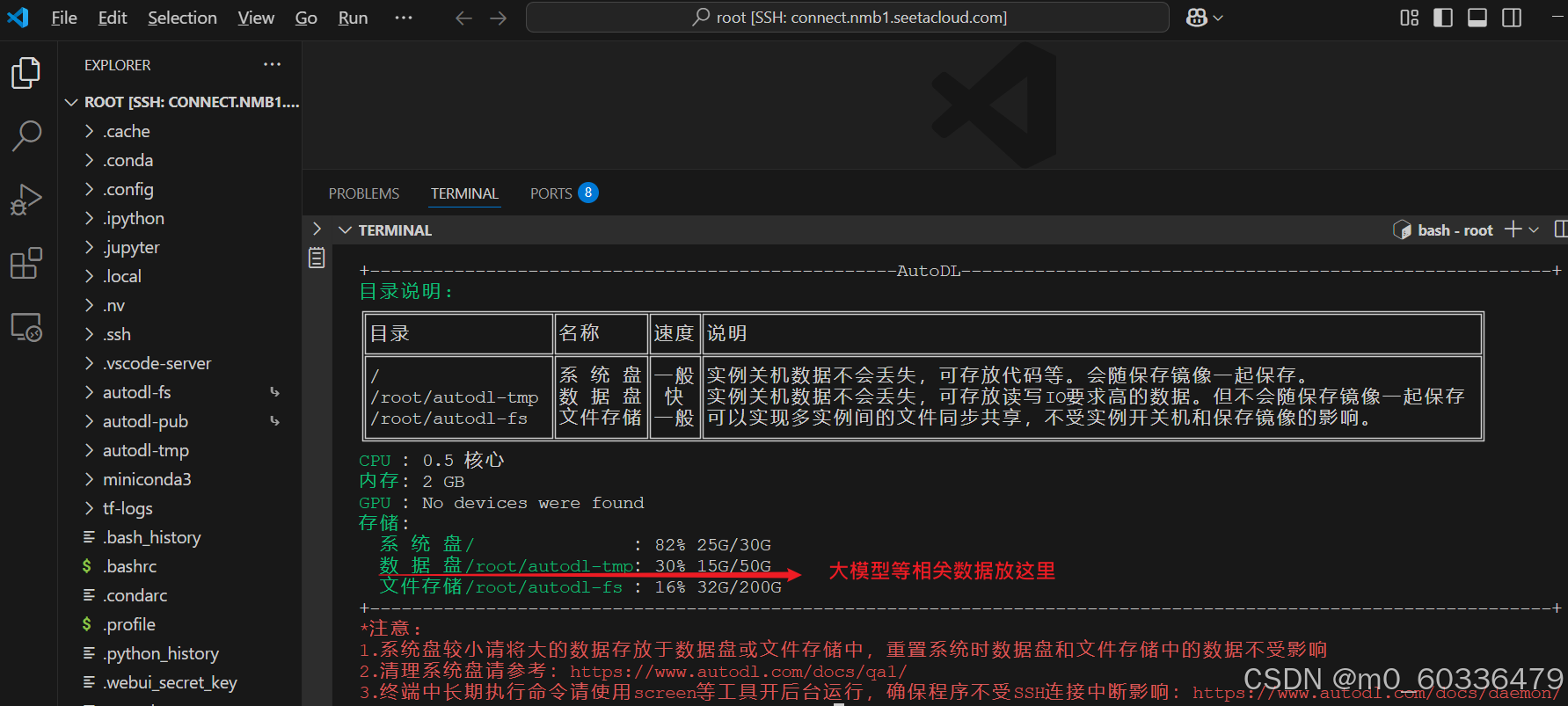
nvitop
查看配置及资源占用:pip install nvitop
微调
环境
官网参考
LlamaFactory:
https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/installation.html
vLLM: 看中文的
https://vllm.hyper.ai/docs/
LlamaFactory
安装框架
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git

注意:
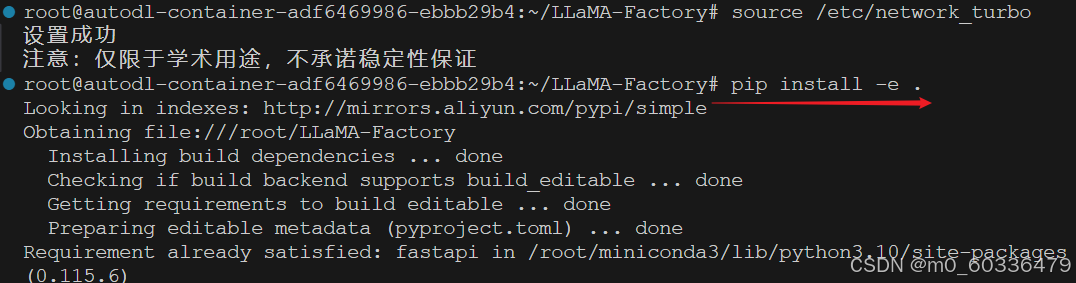
- 先学术加速可能会更快(source /etc/network_turbo)
- autodl一定放在数据盘拉取(autodl-tmp)
安装依赖
先进目录
cd LLaMA-Factory/

安装依赖
pip install -e .
验证安装
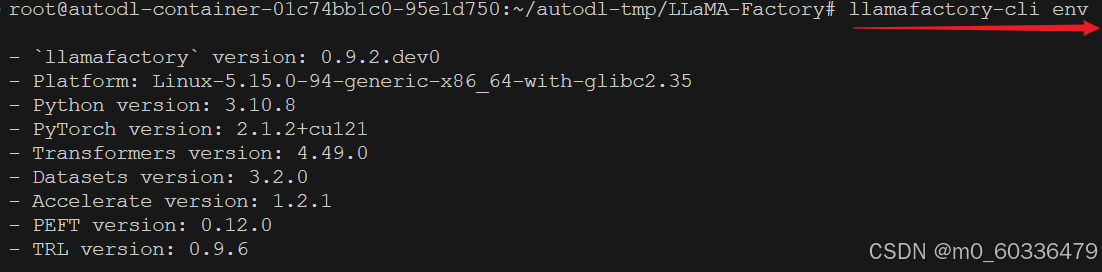
查看LlamaFactory的版本信息:llamafactory-cli env
vLLM
conda环境:
创建一个新的 conda 环境:
conda create -n myenv python=3.10 -y
conda activate myenv
这里单独安装隔离环境,
- 避免依赖冲突:不同项目可能依赖同一库的不同版本,独立环境可隔离版本差异,防止因版本不兼容导致的运行错误
- 资源隔离:单独环境可限制 vLLM 的 CPU/GPU 资源占用,避免与其他进程竞争资源,尤其在多任务场景下提升推理稳定性
安装框架
pip install vllm
验证安装
vllm --version

其他:
如果依赖的包不存在错误,直接安装即可。
数据
下载数据集
开源数据集:https://www.modelscope.cn/datasets/xiaofengalg/HuatuoGPT-sft-data-v1/dataPeview
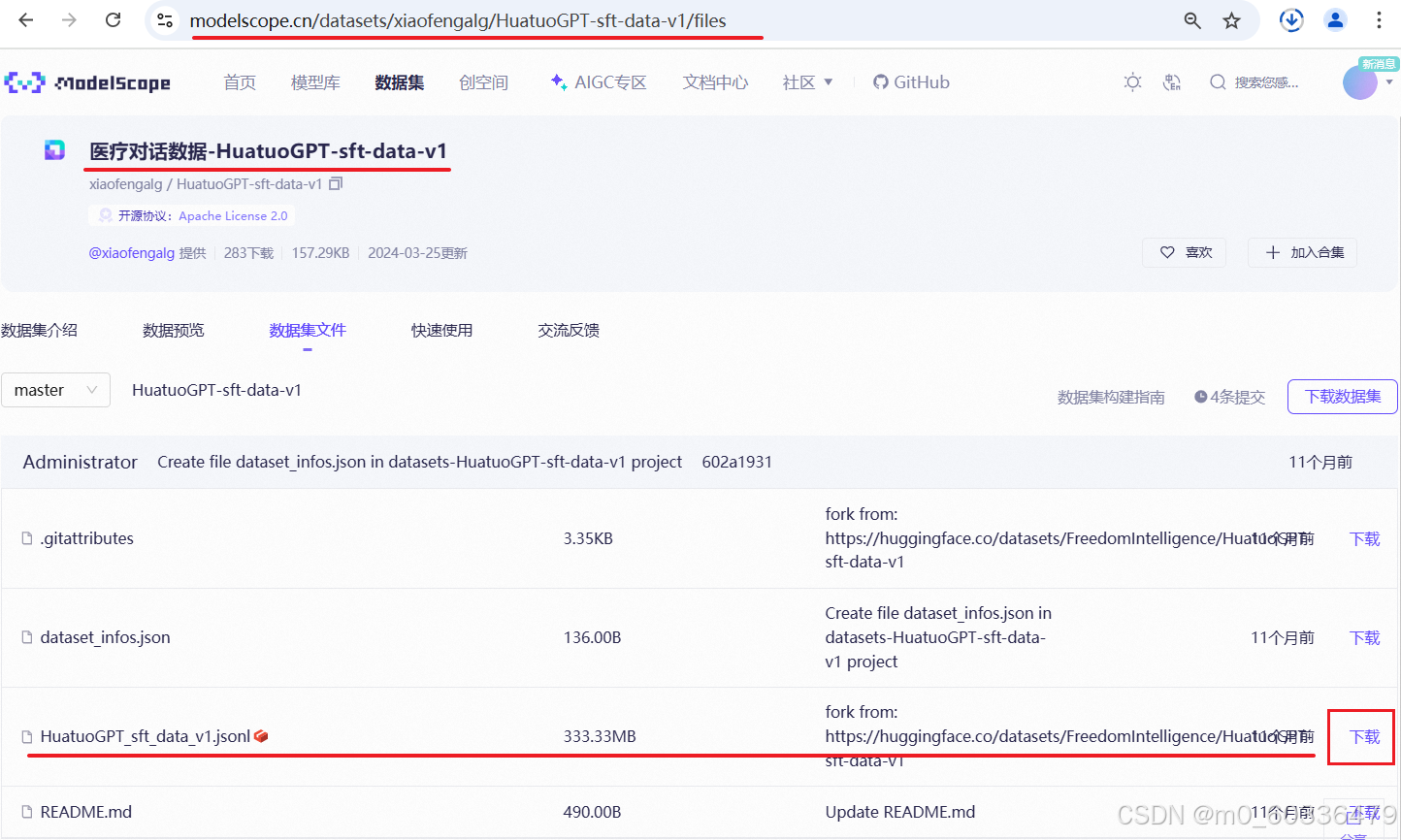
上传至服务器
利用服务器的算力对数据集进行处理,故上传
格式转化
选择数据集格式
由于,
- 不同大模型微调框架来说,数据集的格式不同,这里是LlamaFactory框架;
- 同时,在医疗领域,上下文信息对生成回答的影响较大
所以,
- 选择带多轮对话的指令监督微调数据集,其格式要求 如下

数据集格式转换
将jsonl转成json格式且符合LlamaFactory框架支持的监督微调格式
| 转化前 | 转换后 |
| 226043行,318M
文件名:HuatuoGPT_sft_data_v1.jsonl | 3056516行,516M,多轮对话模式拆分了更多的行
文件名:huatuo.json |
| 转化:/root/autodl-tmp/project/huatuo/data/huatuo.json 数据集较大,跑了2个小时,还没收敛,为了往下继续,裁剪数据集(141条) | |


数据集配置
将格式化的数据拷贝到LlamaFactory的data目录,并添加到data_info.json配置文件中,这样LlamaFactory才能识别到。
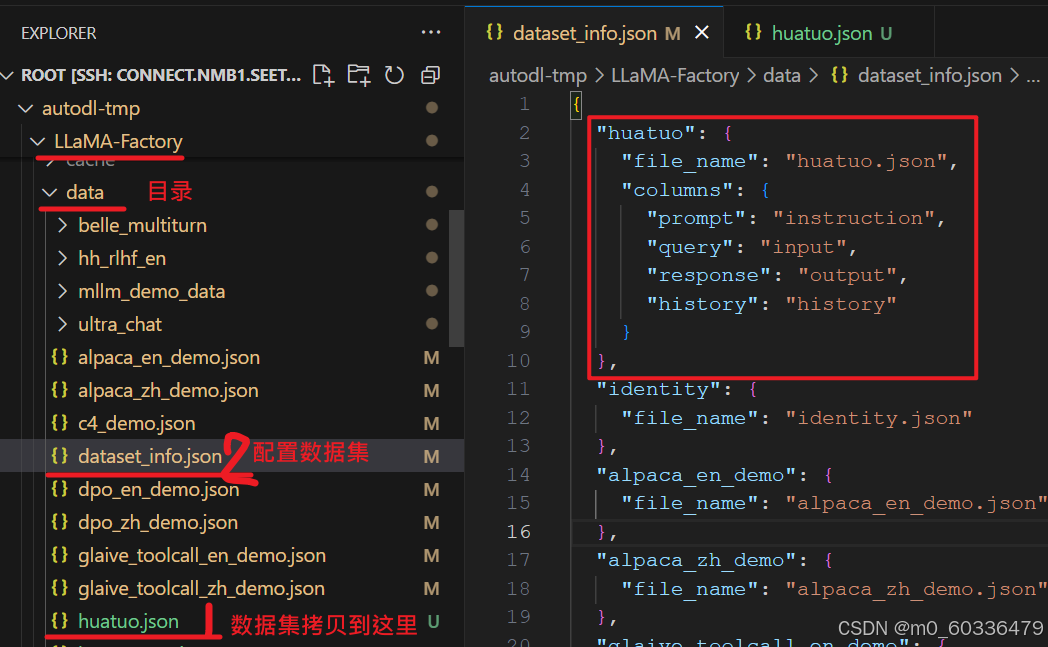
注意,通过多轮对话,columns字段请正确对应,尤其是history
数据集切分
- 比例:小数据集(6训练:2测试:2验证),小数据集(7训练:2测试:1验证)
- 所有数据皆同一来源,免因来源差异导致评估偏差
- 训练集包含所有数据,测试集直接从训练集中随机筛选出一部分
- 通过合理划分数据集并结合任务特性调整策略,可有效提升模型泛化能力与评估可靠性
模型
硬件需求
GPU选择
目前微调项目模型(1.5-8B),8B可满足中小企业对话需求,2张及以上24GB以上显存(RTX4090)
硬件配套
主要是CUP、内存、存储,影响数据的加载、预处理,避免在此处产生瓶颈。
基座模型
选择模型
BASE模型主要是用来理解数据本身特征含义,但选择模型要考虑:
- 数据规模匹陪:较少的数据集难以撼动较大的模型微调,即大的模型难以在小数量的数据集上收敛
- 垂直领域匹配:优先选择在目标领域有预训练基础的模型,较少知识重构成本
所以,选择基座模型时,不选过大的,够用就行;可以先不做训练直接拿原始数据对模型进行测试,通过对比找出表现较好的模型。
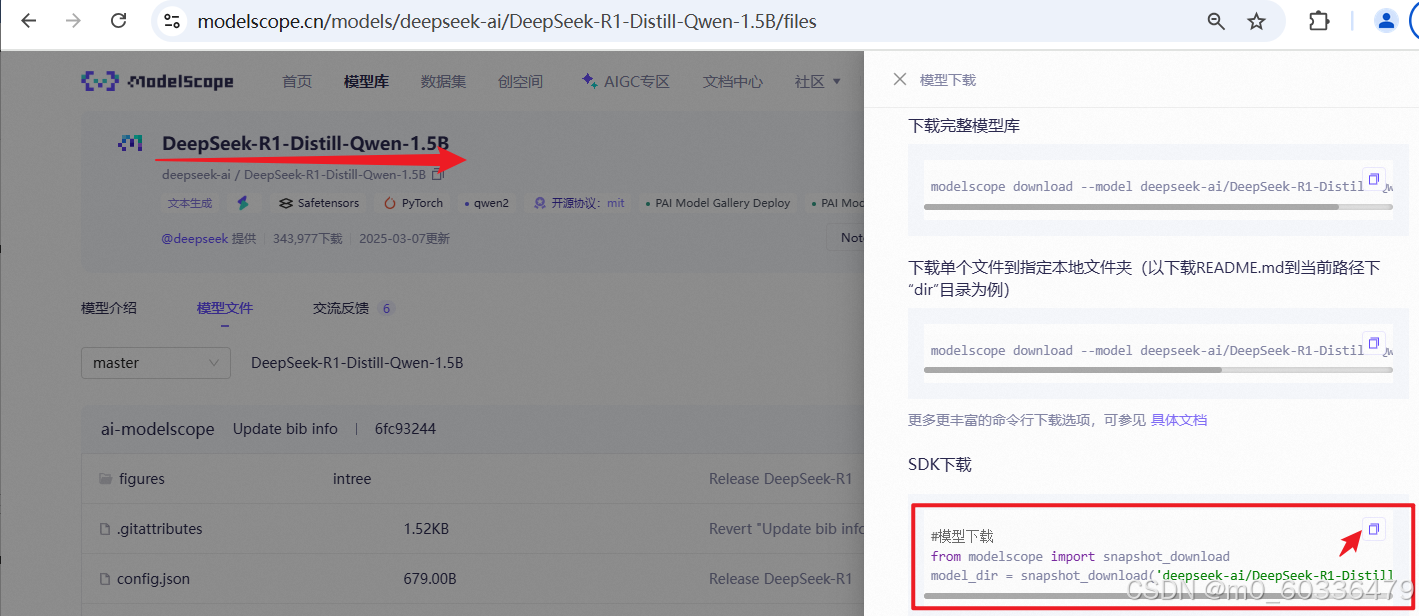
7B的,训练时间太长了,用1.5B的演示。
下载模型
下载模型时间较长,可以使用无卡模型开始,省钱。
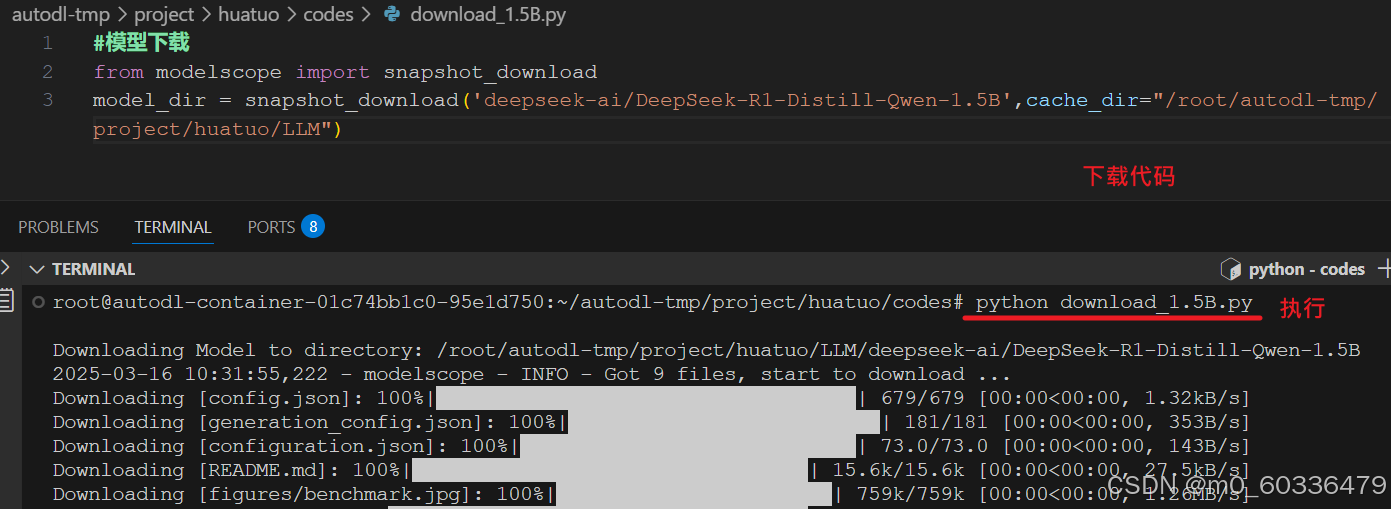
根据提示:pip install modelscope

训练
启动web服务
cd LLaMA-Factory/
llamafactory-cli webui
nohup llamafactory-cli webui &(后台运行)

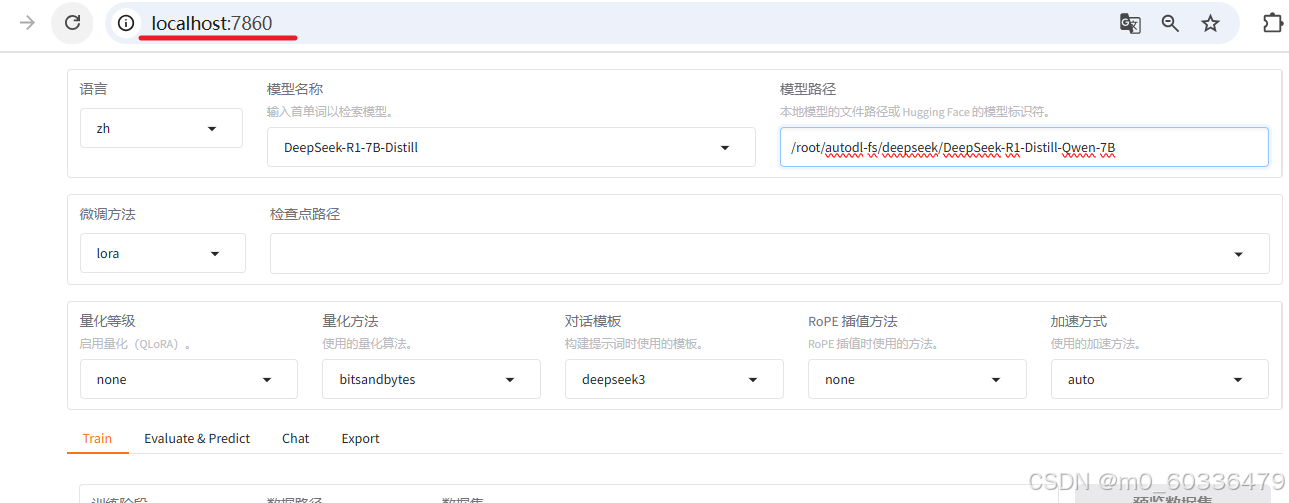
配置训练参数
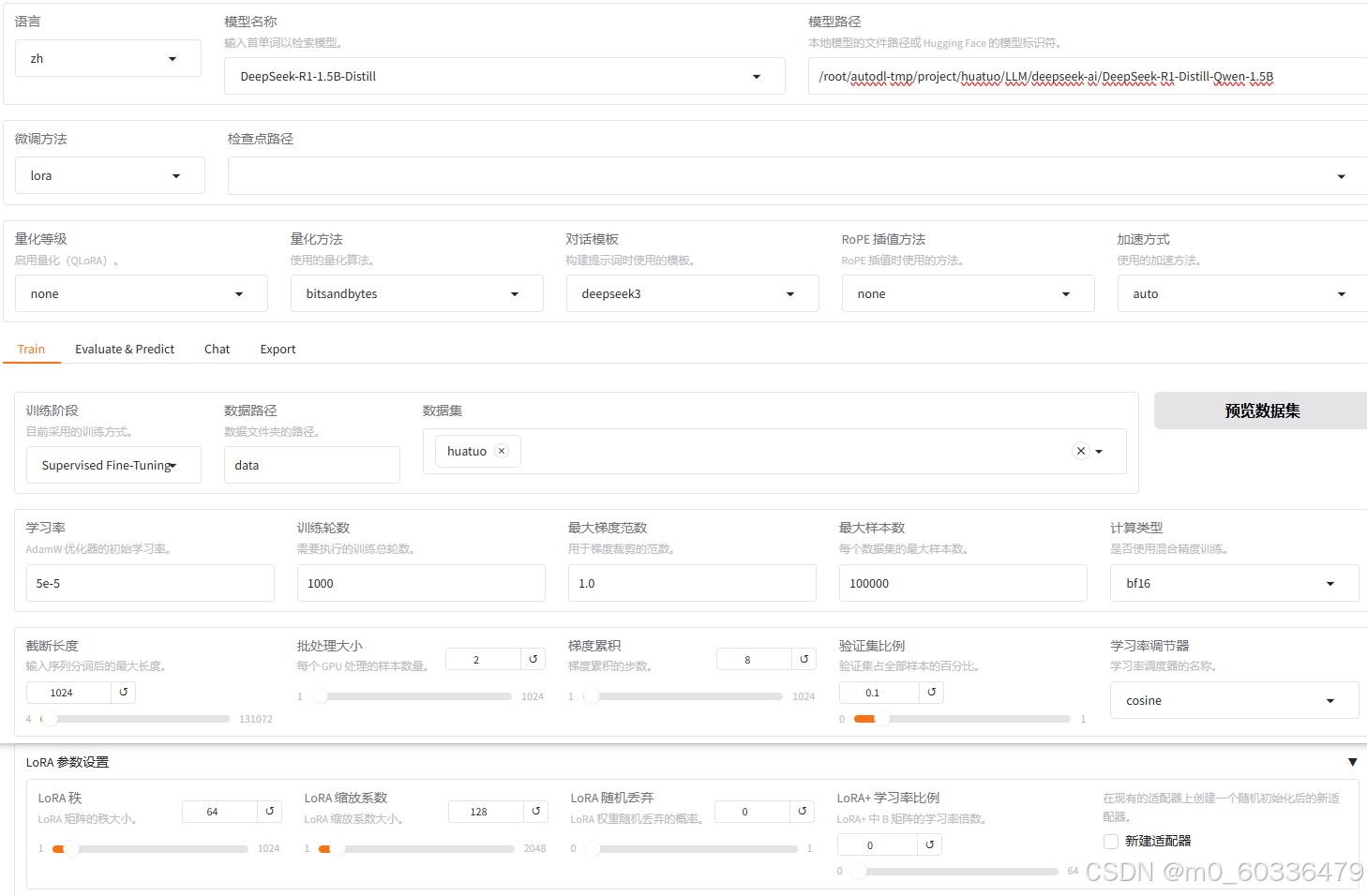

- 模型路径:本地路径(私有化部署),否则从Huggingface上在线下载
- 对话模版:选择
- LoRa微调:主流的核心微调方法(默认选择)
- 训练轮数:可以多给一些,看情况主动停止
- 最大样本数:防止数据集过大,造成内存溢出问题,所以根据数据集真实情况来判定
- 验证集比例:0.02做验证集,其余做训练集
- LoRA 参数设置:经验值,LoRA秩*2=缩放系数
开始训练
点击“开始”,则启动微调训练。
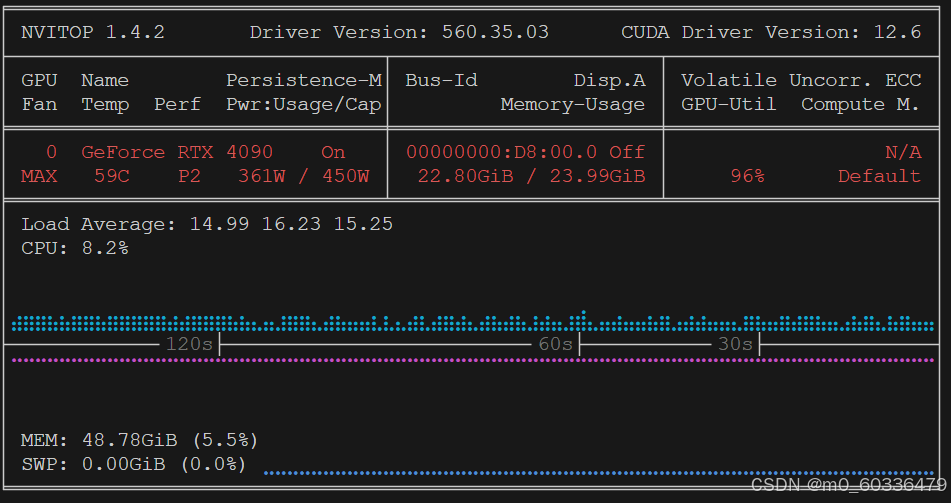
资源最优化
通过不断调整微调参数,以最大化资源利用率目标,不断调整,直至最优化。

何时停止?
- 需要结合验证集性能收敛和过拟合信号来终止;
- 在医疗问答系统的微调项目中,泛化能力强的模型通常优于过拟合的模型,但具体需结合场景权衡
- 观察训练状态,实际上,
- 只要loss一直往下降,就可以继续训练;
- 当loss躺平,可以通过主观评测,如果结果错误,再继续训练,直至精度95%以上,可停下来
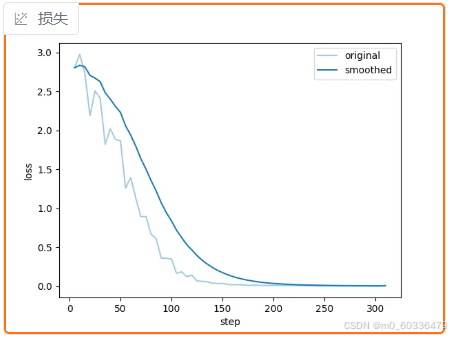
太好了,不用等半天还没收敛,这里很快躺平了;躺平说明收敛,是否达到预期需实际测试才知道。
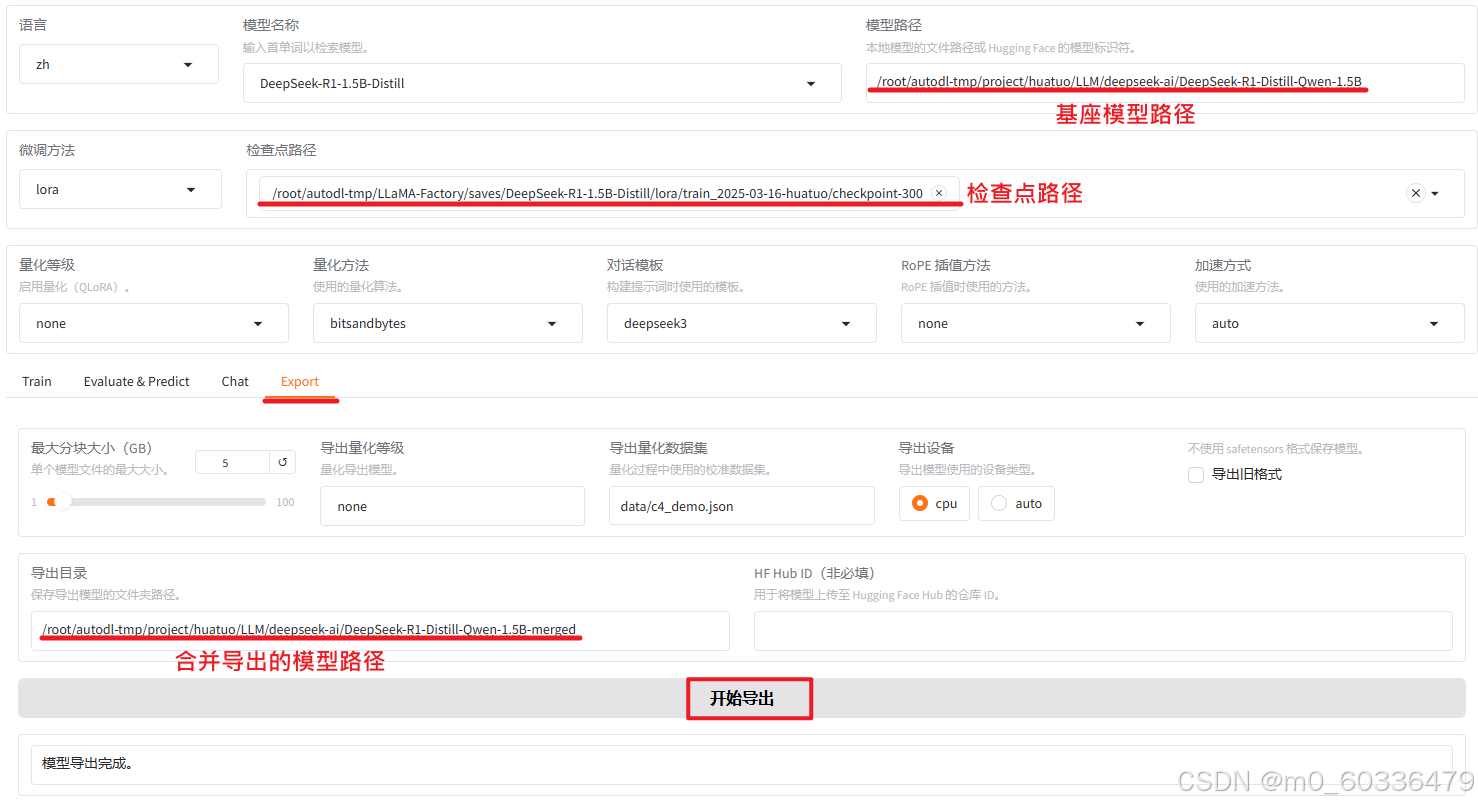
训练后合并
通过评估测试,确认模型效果后,通过合并导出操作完成模型的训练(阶段)。
评测
主观评测
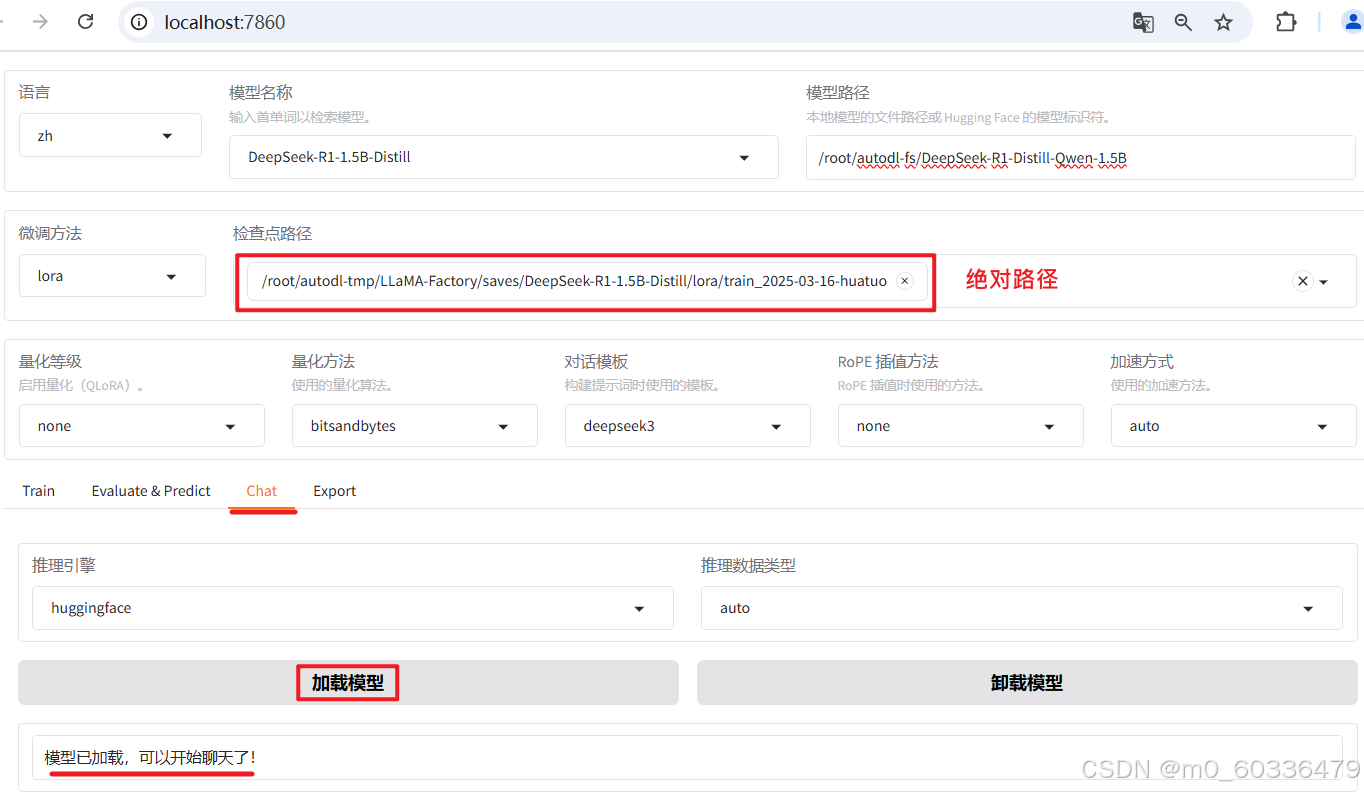
通过LLaMA-Factory的Chat模块加载微调模型,通过交互式对话测试生成质量;
当然,也可以使用其他方法或框架进行主观评估判断,只是这里使用LlamaFactory更方便,直接chat也不用对模型进行Merge操作,加载检查点即可完成评估操作。
参数配置:
通过LLaMA-Factory的Chat模块加载微调模型,通过交互式对话测试生成质量;下面,关键参数配置后,点击加载模型,可以进行chat推理
模型推理
将准备好的问题,输入模型,通过对话判断训练的效果;

客观评测
评估数据集
上传数据集
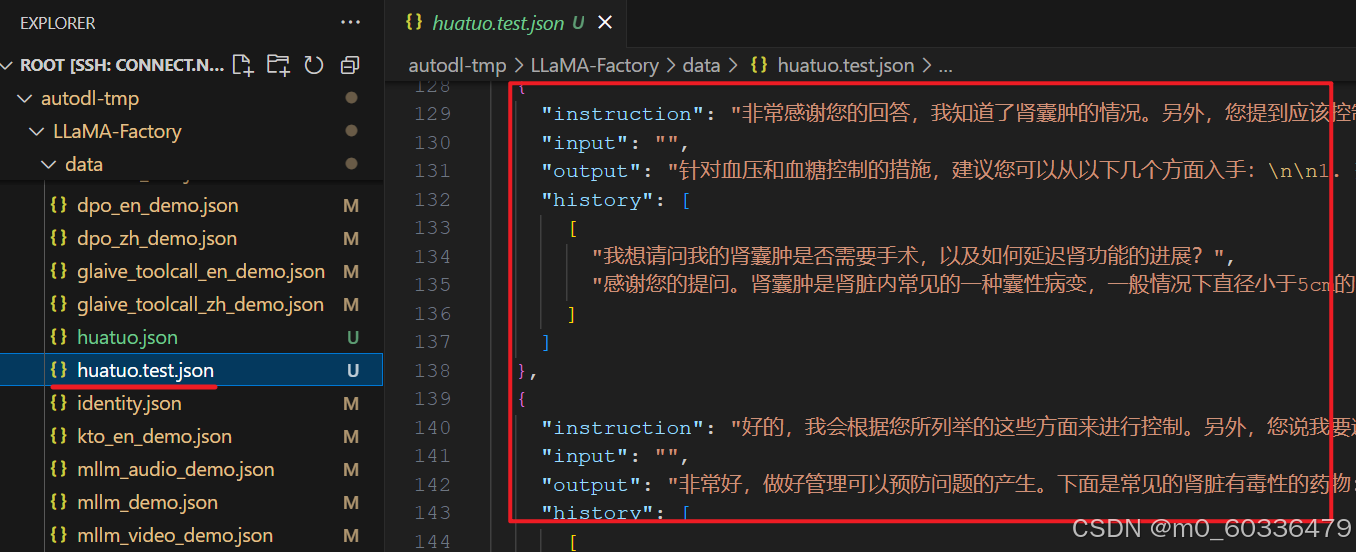
数据集配置
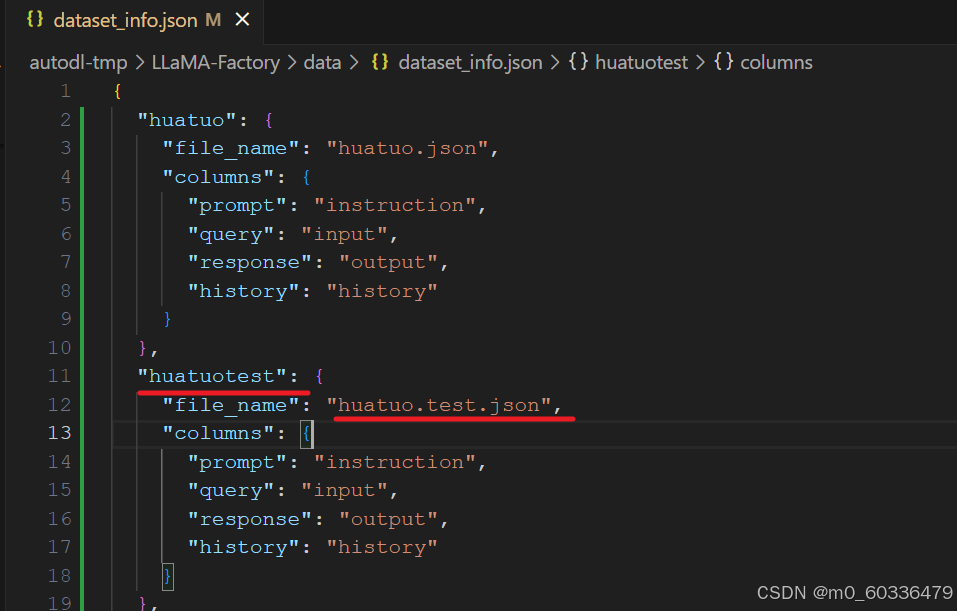
配置评测参数
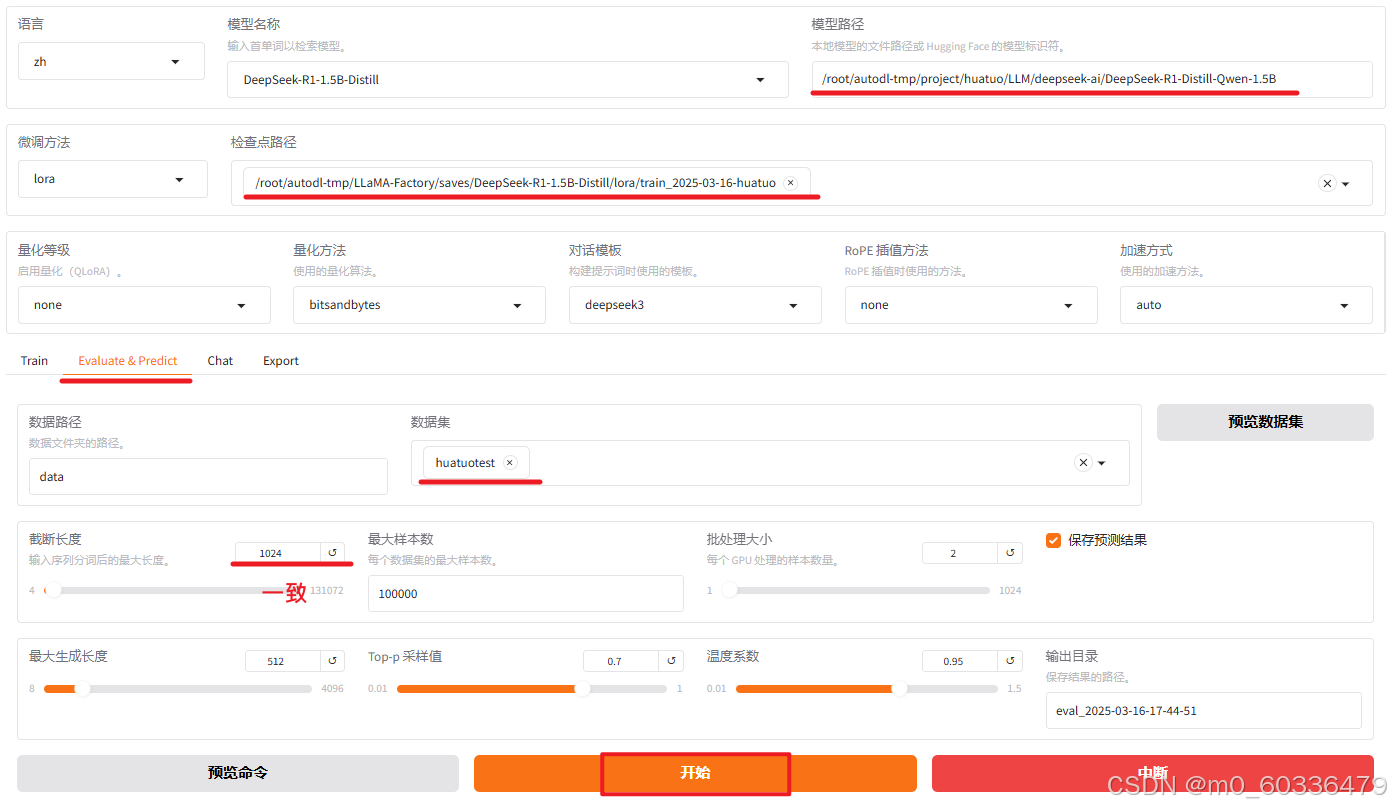
开始评估测试
- 点击“开始”,进行评估测试
- 点击开始后,看vscode控制台,报错,提示安装包,直接安装后再点击开始直至正常
pip install jieba //分词工具
pip install nltk
pip install rouge_chinese

输出评估结果
准确率(predict_bleu-4)和召回率(predict_rouge-1)都高,结果才有效
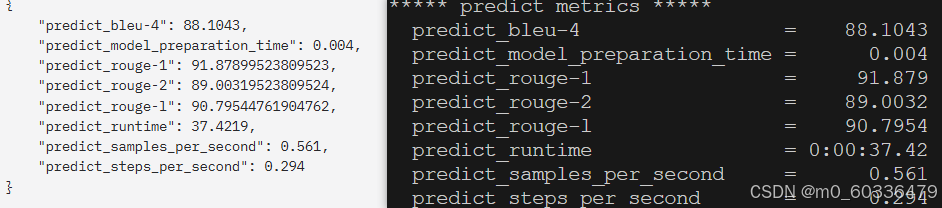
上面得分,BLEU-4和ROUGE系列指标得分高,生成文本与目标文本匹配度高。模型准备时间短,但运行效率较低,处理速度有待提升。总体而言,在质量和效率间取得了一定平衡,适用于多种文本生成任务。
评测结果处理
如果评测未达预期,可以回到训练阶段,重新进行训练,即:
设定参数(学习率、训练轮次、批处理大小等超参数)->微调->评测,不断迭代,直至达标。
部署
vLLM服务
准备环境
在“环境准备”已经安装,下面激活该环境。
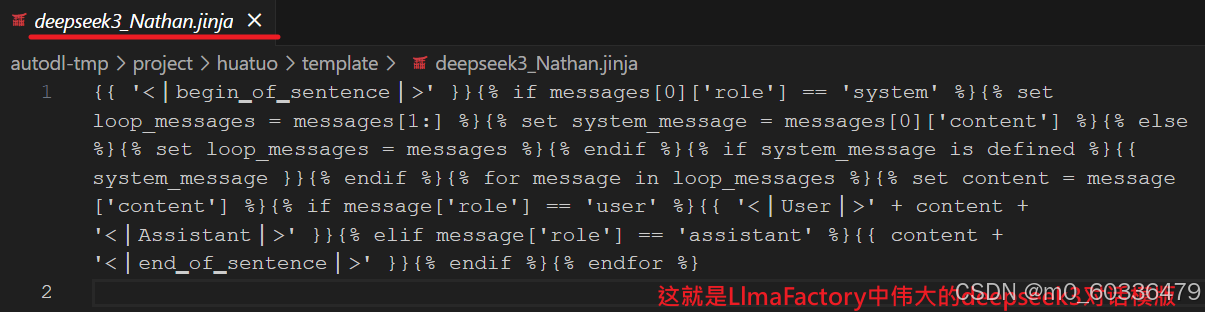
准备聊天模版
DeepSeek-R1是带有思维链的模型;蒸馏模型“DeepSeek-R1-Distill-Qwen”经过定制化训练之后,其输入格式已与Qwen完全不同;所以,在进行推理时候,需要明确指定微调时使用的模版,否则在服务器将无法处理聊天请,聊天请求将出错或推理时微调效果会被遗忘。
启服务开端口
vllm serve <model> --chat-template ./path-to-chat-template.jinja

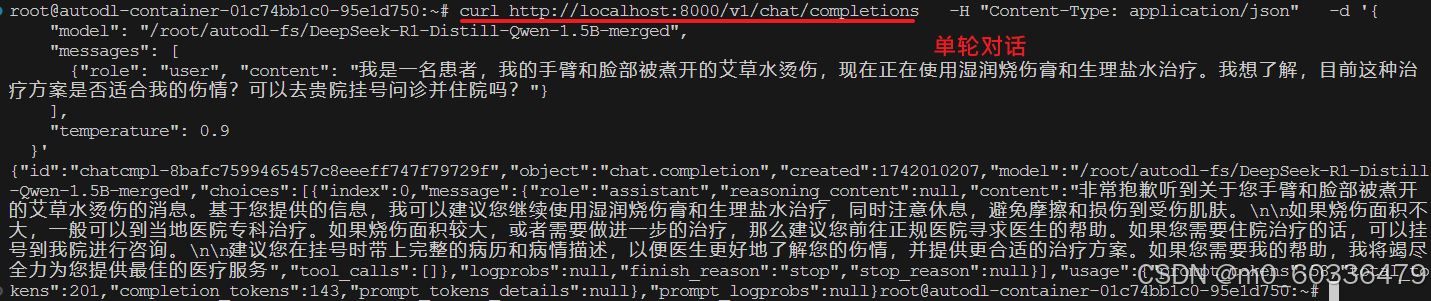
验证
单轮对话
多轮对话
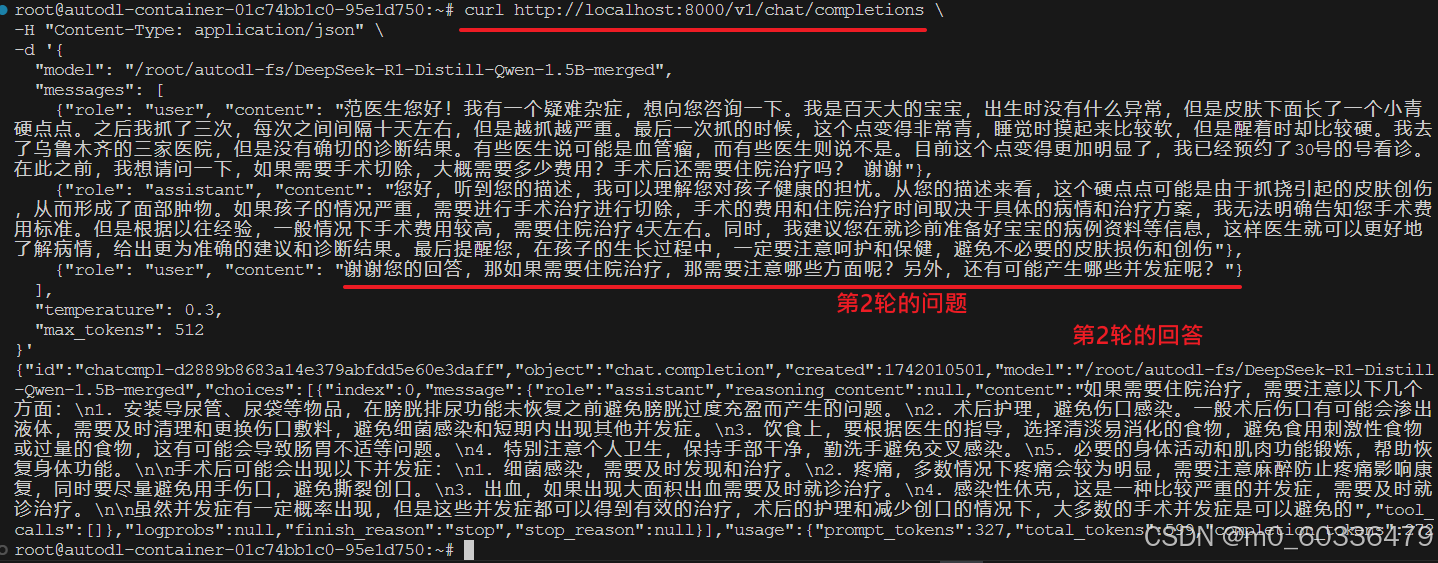
前端
后端
日志
| 日期 | 内容 |
| 2025-3-16 | 搞了小一天,充了2次值 想一下子把将其呈现出来还真不是件容易的事 整理过程发现很多细节,真想停下来想一想 明天又是周一 |

















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









