







起因:
虽然在本机Windows部署成功运行,但是由于计算资源少只有6G的GPU无法计算手机拍摄图像复原和其他一些数据集测试,尝试租用AutoDL的服务器部署测试
租AutoDL
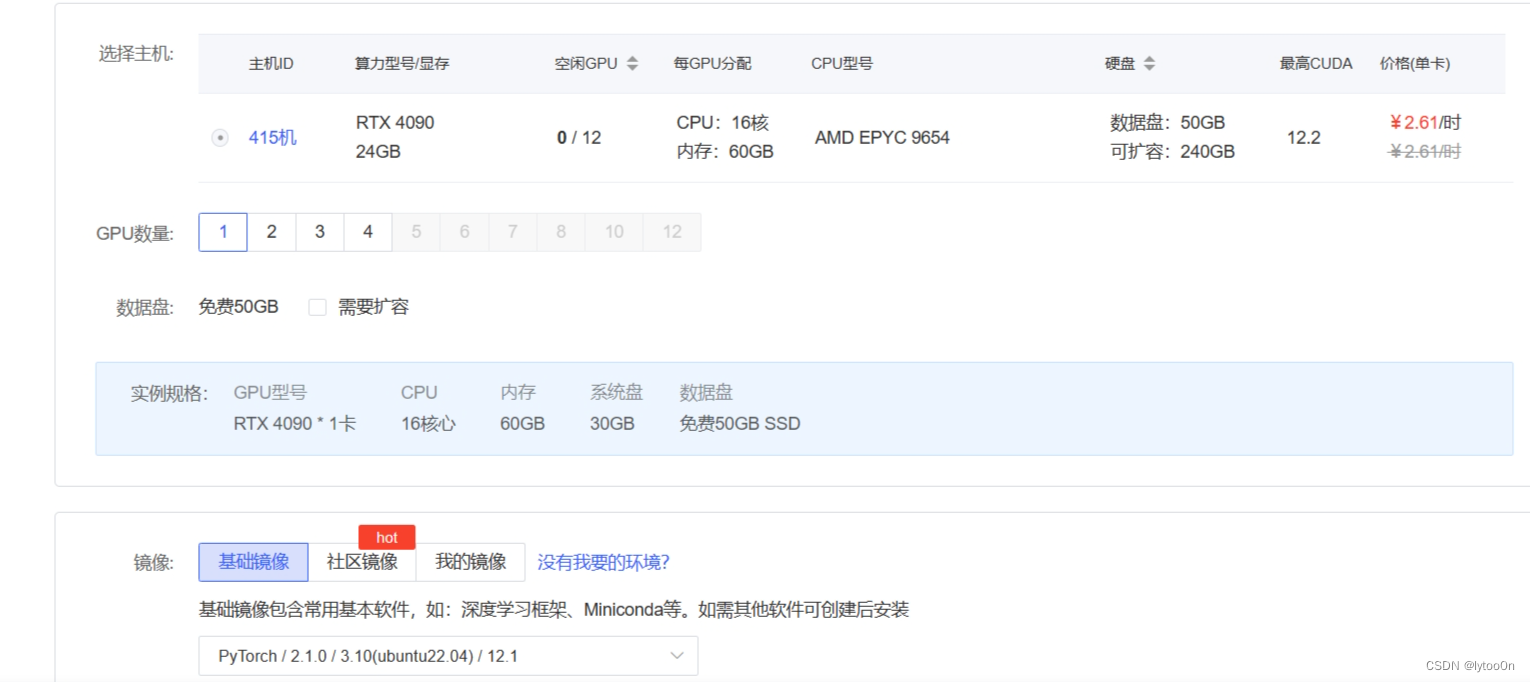
租的人很多,刚确定运行的镜像环境就报告说这个机子已经没卡了,又换了一台4090

上传权重文件、项目文件
没用网盘和filezilla那些AutoDL帮助文档,一开始AutoDL文件存储 传了不同区,还有filezilla输了地址密码却连不上

我是直接JupyterLab上传的,因为本来以为能用ipynb输出Gradio的公网链接。
总共1.6G左右,接近花了20分钟才上传完成
文件夹是上传压缩包后解压的,只是演示的话只上传universal-image-restoration这个文件夹就行
修改test.yml文件里的权重文件地址,最好是绝对值地址
安装环境
requirement里面包含了torch和cudnn11的依赖。但是我选择的环境是与Windows相同的torch2.1.2+cu121并且已经安装好了。所以我把相关的依赖删了没有install免得重复。
运行
一开始我的考虑是懒得远程链接服务器,用ipynb创建一个Gradio公网链接。ipynb放在app.py文件目录下,对app.py的内容做了点界面修改。不能用命令行参数,我改为直接读yml文件。
但是没成功,有内网链接,但是我咋看啊?点进去啥也没有,frpc弄了但是没反应,可能是服务器挂了代理,开不了链接。
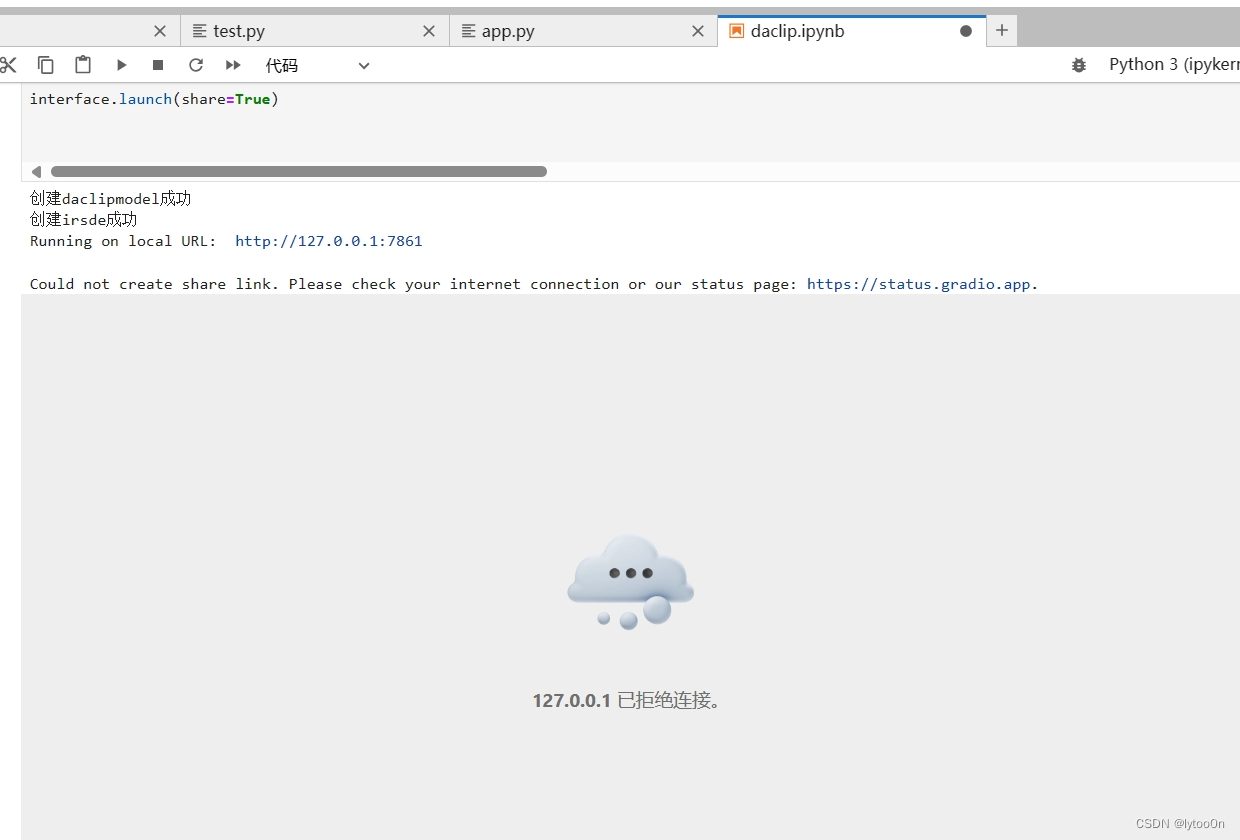
之前项目只用过pycharm专业版连服务器,不过认证过期了用不了,也懒得找种子卸载了。
转为vscode,跟了csdn的教程,本地链接打开能用,同样无公网链接

运行成功。
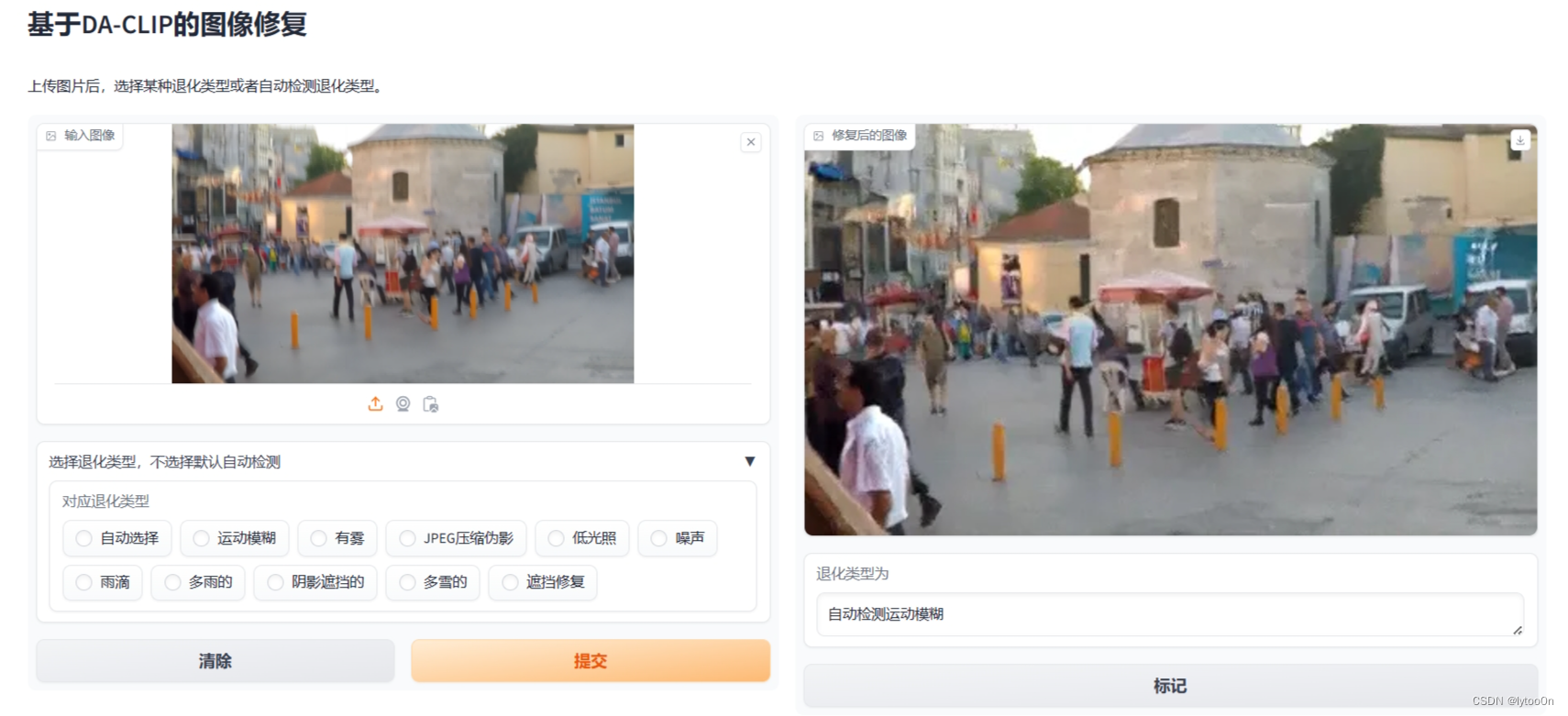 疑问
疑问
显存占用问题:
一开始是0显存占用
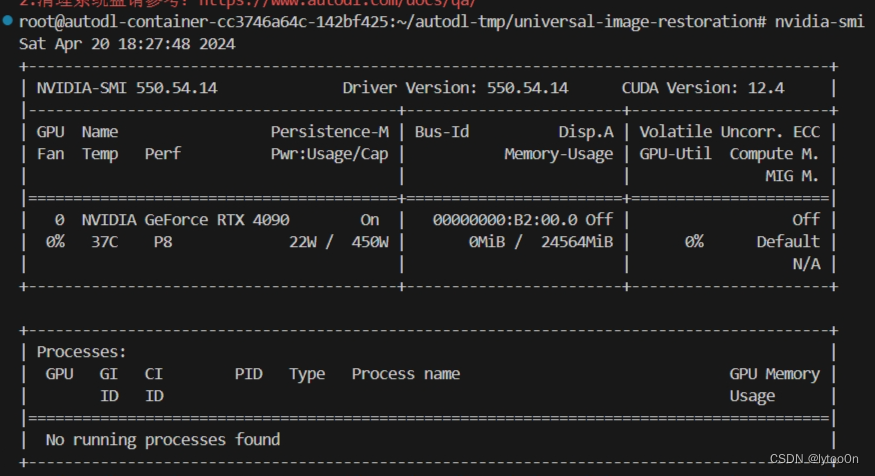
加载完模型没处理时是daclip模型的1.6G
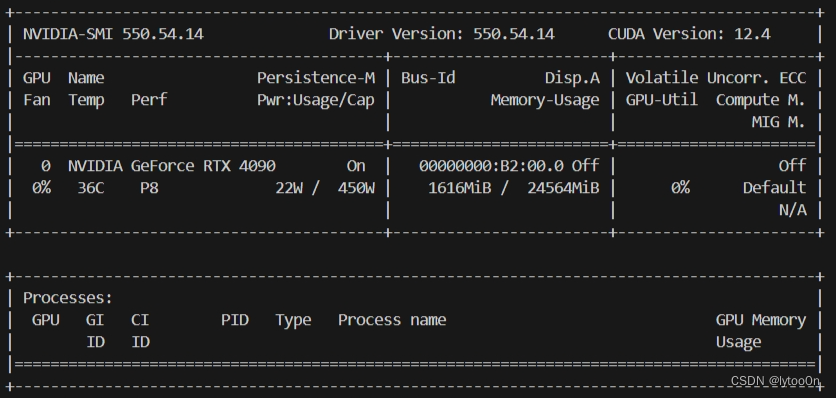
处理完第一张图后是9个G
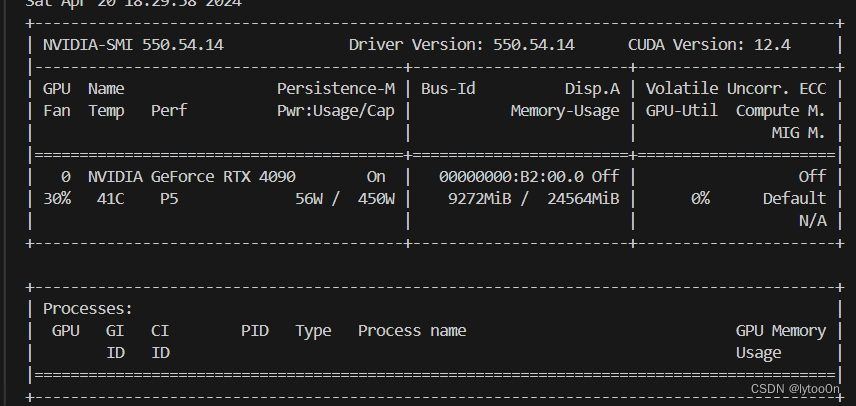
但是加载完第二张图准备复原时显存一下子到了16G并且报错OOM
一时半会也搞不懂显存里有什么,而且计算量这么大吗,比模型参数都大了很多。
可能是有未释放的缓存和内存碎片?
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.83 GiB. GPU 0 has a total capacty of 23.64 GiB of which 1.73 GiB is free. Process 930717 has 1.79 GiB memory in use. Process 947502 has 17.54 GiB memory in use. Process 947745 has 2.58 GiB memory in use. Of the allocated memory 2.01 GiB is allocated by PyTorch, and 107.05 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
无从下手,ps -ef根本找不到对应的process
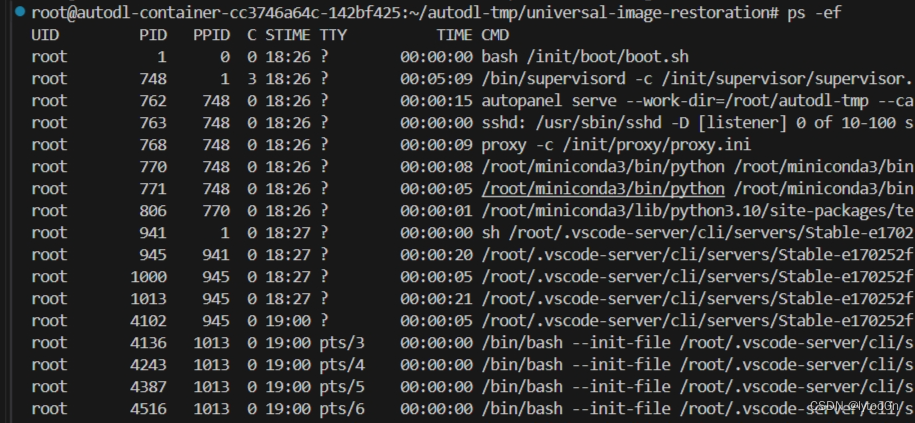
nvidia-smi 又只有一个process
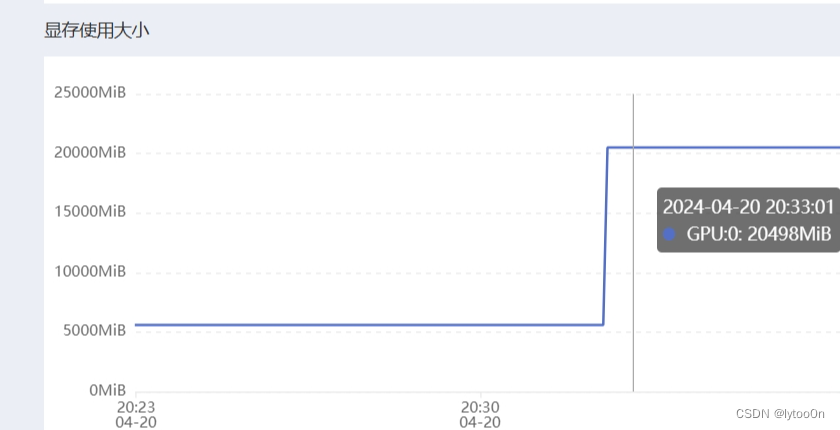
一下子从5G到20G
感觉缺少释放显存的方式?但是运行明显不那么需要显存的图像时,显存并没有增长。
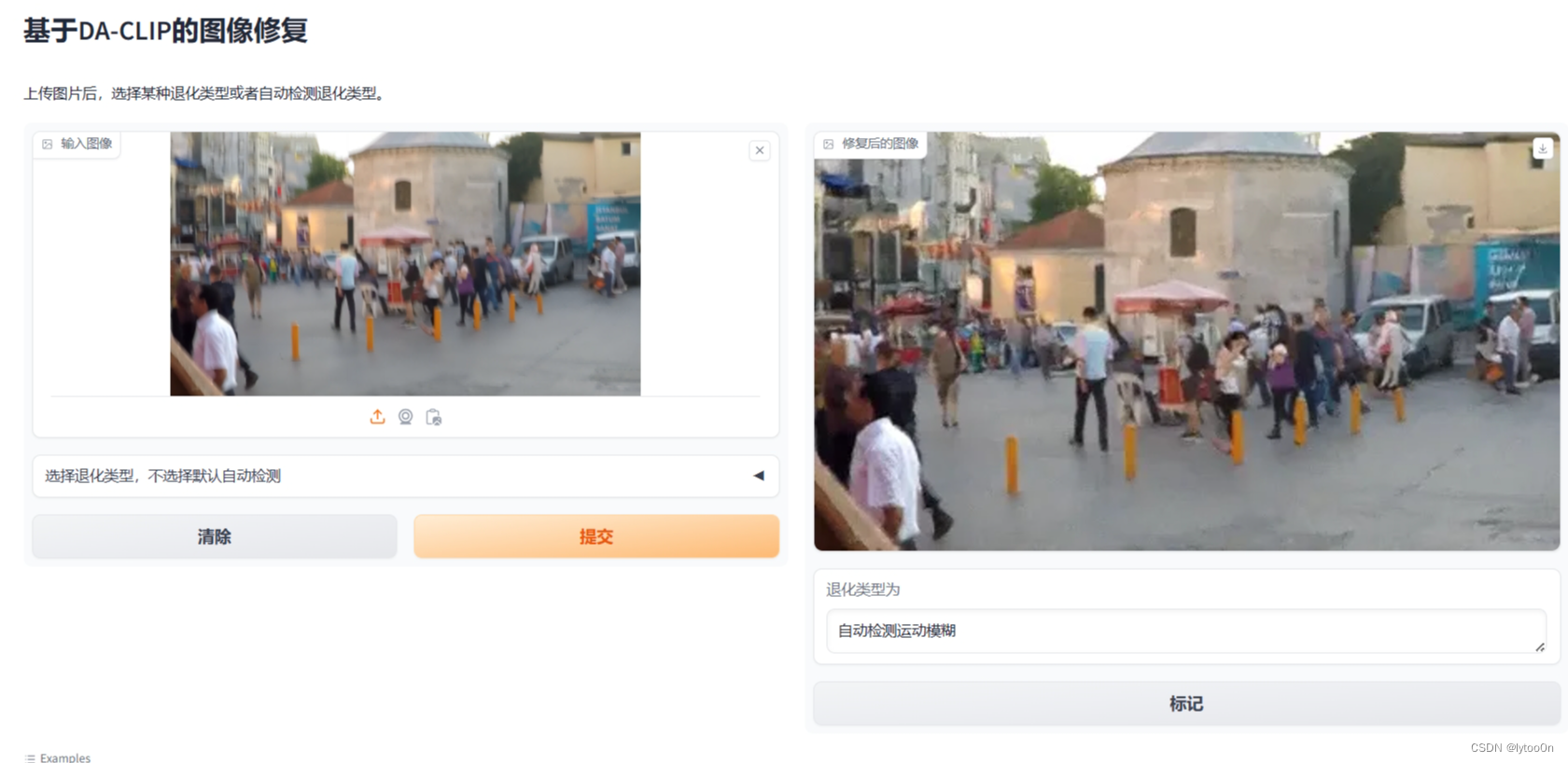
手机照片和Gopro运动模糊OOM
感觉是不是跟图像尺寸有关
GOPRO图像,虽然图像不大,但是分辨率比其他LQ图像都要大,尺寸一般五六百左右
就算我用了这个24G的4090还是跑不起LQ-image的运动模糊
File "/root/miniconda3/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
File "/root/autodl-tmp/universal-image-restoration/config/daclip-sde/models/modules/attention.py", line 180, in forward
sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 12.36 GiB. GPU 0 has a total capacty of 23.64 GiB of which 6.86 GiB is free. Process 94706 has 1.57 GiB memory in use. Process 177125 has 15.21 GiB memory in use. Of the allocated memory 14.55 GiB is allocated by PyTorch, and 192.95 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF两次都是重启了程序上传图片后一下子从3G跑到17G然后跟我讲OOM
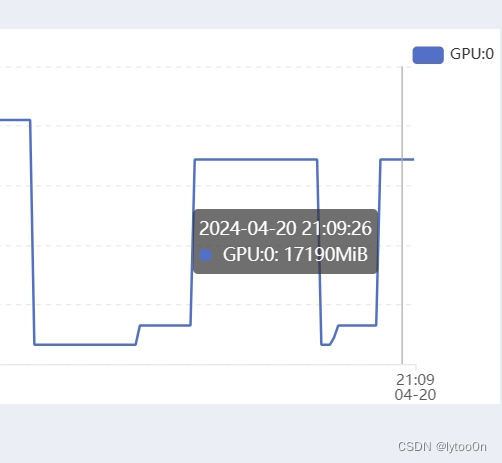
于是我用wps修改了一下图像的size,从右边改到左边,然后就跑出来了

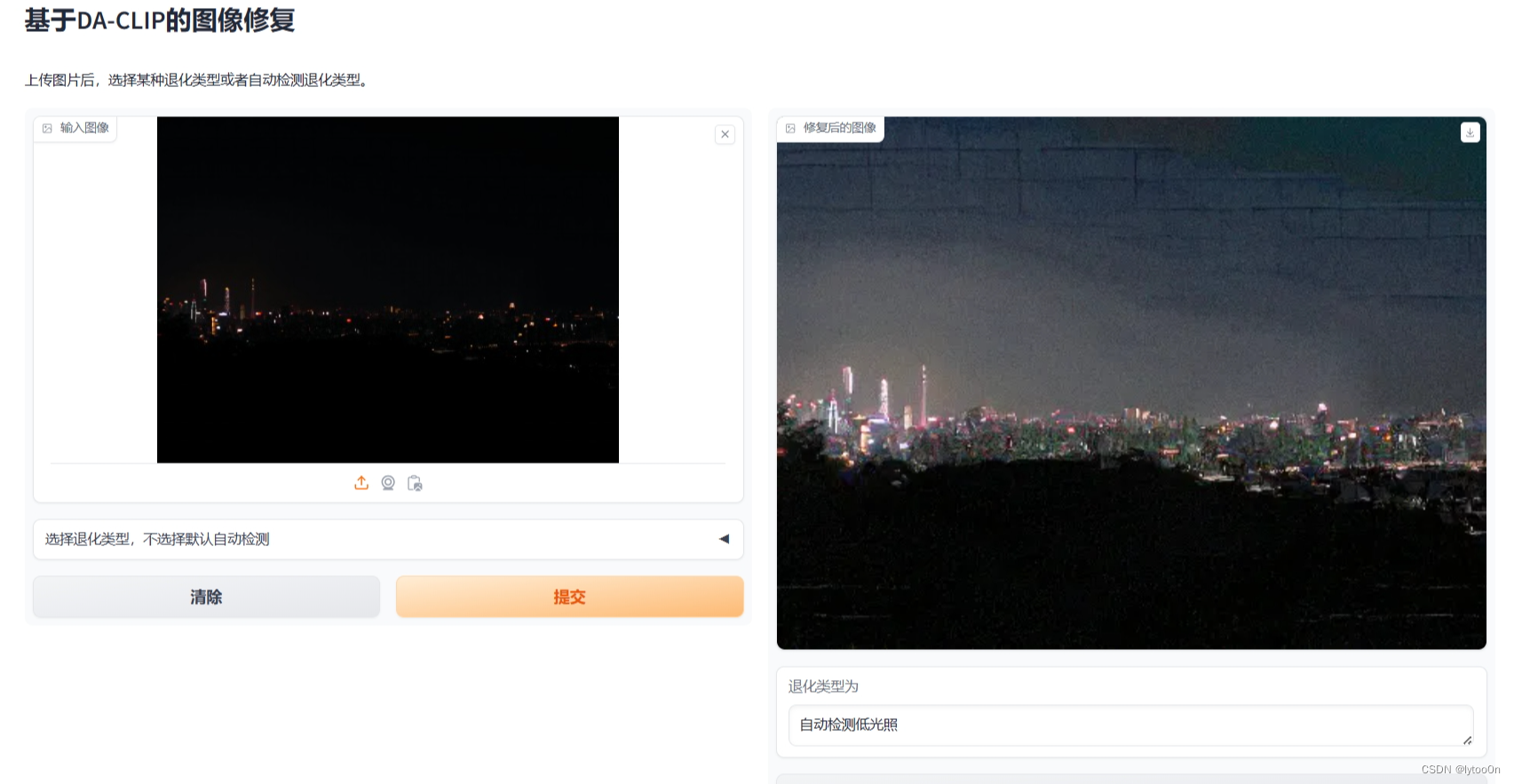
手机拍摄的照片同理,这两张在白云山拍的本来分辨率4000左右直接缩小八倍
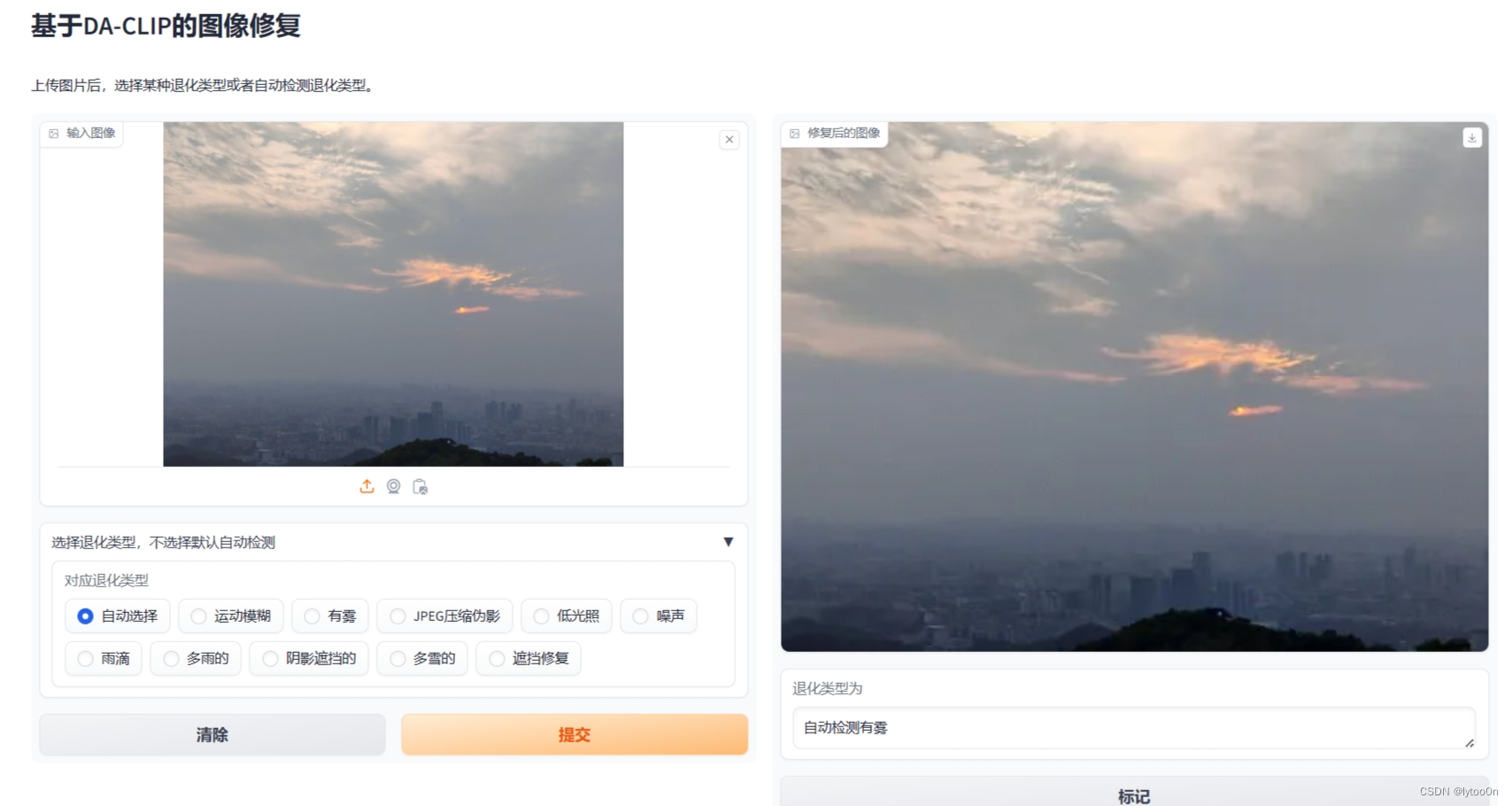
但是问题是,在图像预处理明明设置了resize,而且读进去的图像在复原前也是224*224的图像大小,难道说这个插值计算花了显存?但是没to(device)啊,搞不懂哪里在吃显存
def clip_transform(np_image, resolution=224):
# 这一行定义了一个名为clip_transform的函数,它接受两个参数:np_image(一个NumPy数组格式的图像)和resolution(一个可选参数,默认值为224,表示图像的目标分辨率)。
pil_image = Image.fromarray((np_image * 255).astype(np.uint8))
# 这一行将NumPy数组格式的图像转换为PIL(Python Imaging Library)图像。首先,将NumPy数组中的像素值乘以255,然后转换为无符号的8位整数格式,这是因为图像的像素值通常在0到255的范围内。
return Compose([
# 来自torchvision.transforms
# 这一行开始定义一个转换流程,Compose是来自albumentations库的一个函数,用于组合多个图像转换操作。
Resize(resolution, interpolation=InterpolationMode.BICUBIC),
# 这一行使用Resize操作来调整图像大小到指定的分辨率。interpolation=InterpolationMode.BICUBIC指定了使用双三次插值方法来调整图像大小,这是一种高质量的插值算法。
CenterCrop(resolution),
# 这一行应用CenterCrop操作,将调整大小后的图像进行中心裁剪,以确保图像的尺寸严格等于指定的分辨率
ToTensor(),
# 这一行使用ToTensor操作将PIL图像转换为PyTorch张量。这是为了使图像能够被深度学习模型处理。
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))])(pil_image)
# 这一行应用Normalize操作,对图像的每个通道进行标准化。它使用两组参数,分别对应图像的均值和标准差。这些参数通常是根据预训练模型的要求来设置的。有没有朋友能提供一下思路















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









