







本文目标
对app.py文件中DA-CLIP模型的创建过程中模型配置读取、预训练权重地址读取、相关参数等代码进行解析。下面是DA-CLIP模型的创建过程执行的代码
clip_model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=opt['path']['daclip'])
输入的参数
# 自定义的daclip_ViT-B-32模型名称,该模型基于VIT-B-32训练
# pretrained用的是test.yml的模型地址,,读取pt文件
clip_model = clip_model.to(device)
本文当初写的时候主要是对我探究过程的一个记录, 不想看过程的也可以直接看结果。
小结
最外层:open_clip\factory.py
open_clip.create_model_and_transforms,open_clip.create_model_from_pretrained
次外层:open_clip\factory.py
create_model()
第三层:
这个比较多样。以openai模型为例,open_clip\openai.py。还有CoCa、CustomTextCLIP、CLIP等直接创建类实例,而非第五层才创建,该途径需要根据create_model()输入的custom_text布尔值设置。具体见create_model()
load_openai_model()
第四层:open_clip\model.py
以openai模型为例
build_model_from_openai_state_dict()
第五层:
CLIP类、CustomTextCLIP类 open_clip\model.py
CoCa类 open_clip\coca_model.py
DA-CLIP接受一个CLIP实例作为参数初始化
def __init__(self, clip_model: CLIP):
一、daclip_ViT-B-32.json模型配置读取
open_clip.create_model_from_pretrained()根据模型配置和预训练权重加载模型
这是调用universal-image-restoration文件夹下open_clip包的init.py中,从factory.py定义的函数。
yml文件提供了对应预训练权重路径,已读取到opt['path']['daclip']参数中。
返回的clip_model 是加载的 CLIP 模型。函数定义如下:
def create_model_from_pretrained(
model_name: str,
pretrained: Optional[str] = None,
precision: str = 'fp32',
device: Union[str, torch.device] = 'cpu',
jit: bool = False,
force_quick_gelu: bool = False,
force_custom_text: bool = False,
force_image_size: Optional[Union[int, Tuple[int, int]]] = None,
return_transform: bool = True,
image_mean: Optional[Tuple[float, ...]] = None,
image_std: Optional[Tuple[float, ...]] = None,
cache_dir: Optional[str] = None,
):
model = create_model(
model_name,
pretrained,
precision=precision,
device=device,
jit=jit,
force_quick_gelu=force_quick_gelu,
force_custom_text=force_custom_text,
force_image_size=force_image_size,
cache_dir=cache_dir,
require_pretrained=True,
)
if not return_transform:
return model
image_mean = image_mean or getattr(model.visual, 'image_mean', None)
image_std = image_std or getattr(model.visual, 'image_std', None)
preprocess = image_transform(
model.visual.image_size,
is_train=False,
mean=image_mean,
std=image_std,
)
return model, preprocess这个函数的设计允许用户灵活地创建和定制模型,包括选择不同的预训练权重来源、设置运行精度、移动设备、以及加载预处理配置等。
继续深挖该函数寻找'daclip_ViT-B-32'配置藏在哪里,我们可以发现该str为create_model()的输入参数,同级目录下的create_model()函数将近160行代码
深挖:factor.py下的create_model()寻找'daclip_ViT-B-32'配置
def create_model(
model_name: str,
pretrained: Optional[str] = None,
precision: str = 'fp32',
device: Union[str, torch.device] = 'cpu',
jit: bool = False,
force_quick_gelu: bool = False,
force_custom_text: bool = False,
force_patch_dropout: Optional[float] = None,
force_image_size: Optional[Union[int, Tuple[int, int]]] = None,
pretrained_image: bool = False,
pretrained_hf: bool = True,
cache_dir: Optional[str] = None,
output_dict: Optional[bool] = None,
require_pretrained: bool = False,
):参数解释
model_name: 模型名称,用于指定要创建的模型类型。pretrained: 预训练权重的来源,可以是一个URL、文件路径或预训练模型的名称。precision: 指定模型运行时的数值精度,如 'fp32', 'fp16', 'bf16' 等。device: 指定模型应该运行在的设备,如 'cpu' 或具体的GPU设备名称。jit: 是否将模型转换为 PyTorch 的 JIT(Just-In-Time)编译版本。force_quick_gelu: 是否强制使用 QuickGELU 激活函数。force_custom_text: 是否强制使用自定义的文本编码器。force_patch_dropout: 是否强制设置特定的补丁丢弃(patch dropout)值。force_image_size: 是否强制设置特定的图像大小。pretrained_image: 是否预训练图像塔(image tower)。pretrained_hf: 是否使用预训练的Hugging Face(HF)文本模型。cache_dir: 缓存目录,用于存储下载的预训练权重和配置文件。output_dict: 是否将模型的输出格式设置为字典。
代码逻辑配置加载和预训练参数地址加载过程
1.model_name 初步判断:Hugging Face模型检测
has_hf_hub_prefix = model_name.startswith(HF_HUB_PREFIX)
if has_hf_hub_prefix:
model_id = model_name[len(HF_HUB_PREFIX):]
checkpoint_path = download_pretrained_from_hf(model_id, cache_dir=cache_dir)
config_path = download_pretrained_from_hf(model_id, filename='open_clip_config.json', cache_dir=cache_dir)
with open(config_path, 'r', encoding='utf-8') as f:
config = json.load(f)
pretrained_cfg = config['preprocess_cfg']
model_cfg = config['model_cfg']
else:
model_name = model_name.replace('/', '-') # for callers using old naming with / in ViT names
checkpoint_path = None
pretrained_cfg = {}
model_cfg = None检查 model_name 是否以Hugging Face Hub的前缀开头,如果是,说明用户希望从HF Hub加载模型,函数会下载相应的配置文件和预训练权重。
否则,根据 model_name 加载或设置模型配置。如果 model_name 包含特定的路径分隔符(如'/'),则将其替换为连字符('-'),以匹配新的命名约定。
2.pretrained判断,该代码读取了daclip模型配置和预训练模型参数
代码很长就不完全截取,只选取与daclip有关部分
输入参数为model_name='daclip_ViT-B-32', pretrained=opt['path']['daclip']
elif "daclip" in model_name:
clip_model = CLIP(**model_cfg, cast_dtype=cast_dtype)
model = DaCLIP(clip_model)读取配置的简要伪代码上下文:
- 如果指定了
pretrained参数并且其值为 'openai',则从OpenAI加载预训练模型。- 否则,model_cfg = model_cfg or get_model_config(model_name)
- 如果 custom_text值存在
model_name包含 'coca'model_name包含'daclip',则创建特定的模型实例DaCLIP。
在else中根据model_name进行了判断,,
model_cfg,是上文Hugging Face模型名称检测中生成的变量,显然daclip不满足该判断。model_cfg为返回值NONE,执行get_model_config()
def get_model_config(model_name):
if model_name in _MODEL_CONFIGS:
return deepcopy(_MODEL_CONFIGS[model_name])
else:
return None重返该factor.py文件头部代码查找相关函数和变量,定义了模块级别变量,并执行了模型配置文件扫描函数。
HF_HUB_PREFIX = 'hf-hub:'
_MODEL_CONFIG_PATHS = [Path(__file__).parent / f"model_configs/"]
_MODEL_CONFIGS = {} # directory (model_name: config) of model architecture configs
def _natural_key(string_):
return [int(s) if s.isdigit() else s for s in re.split(r'(\d+)', string_.lower())]
def _rescan_model_configs():
global _MODEL_CONFIGS
config_ext = ('.json',)
config_files = []
for config_path in _MODEL_CONFIG_PATHS:
if config_path.is_file() and config_path.suffix in config_ext:
config_files.append(config_path)
elif config_path.is_dir():
for ext in config_ext:
config_files.extend(config_path.glob(f'*{ext}'))
for cf in config_files:
with open(cf, 'r') as f:
model_cfg = json.load(f)
if all(a in model_cfg for a in ('embed_dim', 'vision_cfg', 'text_cfg')):
_MODEL_CONFIGS[cf.stem] = model_cfg
_MODEL_CONFIGS = {k: v for k, v in sorted(_MODEL_CONFIGS.items(), key=lambda x: _natural_key(x[0]))}
_rescan_model_configs() # initial populate of model config registry结论:daclip_ViT-B-32.json模型配置定义在model_configs目录下。
配置如下
{
"embed_dim": 512,
"vision_cfg": {
"image_size": 224,
"layers": 12,
"width": 768,
"patch_size": 32
},
"text_cfg": {
"context_length": 77,
"vocab_size": 49408,
"width": 512,
"heads": 8,
"layers": 12
},
"custom_text": true
}配置解读:
-
embed_dim: 嵌入维度,这是模型中嵌入层的维度。在这个配置中,嵌入维度被设置为 512。 -
vision_cfg: 视觉配置对象,包含了构建视觉塔(处理图像的神经网络部分)所需的配置信息:image_size: 输入图像的大小,这里设置为 224x224 像素。layers: 视觉塔中的层数,这里设置为 12 层。width: 视觉塔中层的宽度,即每层的神经元数量,这里设置为 768。patch_size: 图像分块(patch)的大小,这是视觉变换器中使用的图像分割大小,这里设置为 32x32 像素。
-
text_cfg: 文本配置对象,包含了构建文本处理部分(如文本编码器)所需的配置信息:context_length: 上下文长度,即模型在处理文本时考虑的最大长度,这里设置为 77 个token。vocab_size: 文本词汇表的大小,这里设置为 49,408 个不同的token。width: 文本处理部分的宽度,即每层的神经元数量,这里设置为 512。heads: 多头注意力机制中的头数,这里设置为 8 个头。layers: 文本处理部分的层数,这里设置为 12 层。
-
custom_text: 一个布尔值,指示是否使用自定义的文本处理配置。这里设置为true,意味着模型将使用特定的文本处理设置,而不是默认的配置。
二、读取pretrained预训练权重地址
还是在create_model()函数中
if pretrained:
checkpoint_path = ''
f "daclip" in model_name:
pretrained_cfg = get_pretrained_cfg(model_name[7:], pretrained)
else:
pretrained_cfg = get_pretrained_cfg(model_name, pretrained)
if pretrained_cfg:
checkpoint_path = download_pretrained(pretrained_cfg, cache_dir=cache_dir)
elif os.path.exists(pretrained):
checkpoint_path = pretrained
pretrained_cfg = get_pretrained_cfg(model_name[7:], pretrained)
如果模型名称包含 "daclip",则调用 get_pretrained_cfg 函数来获取与模型名称后缀(去掉 "daclip" 前缀的部分)和预训练配置相关的信息。
这里 model_name[7:] 是因为 "daclip" 通常是模型名称的前缀。
该get_pretrained_cfg函数在pretrained.py中,该文件包含所有读取预训练权重文件的配置
def get_pretrained_cfg(model: str, tag: str):
if model not in _PRETRAINED:
return {}
model_pretrained = _PRETRAINED[model]
return model_pretrained.get(_clean_tag(tag), {}) 对 model_name='daclip_ViT-B-32' 执行 model_name[7:] 将会返回字符串 'ViT-B-32'。
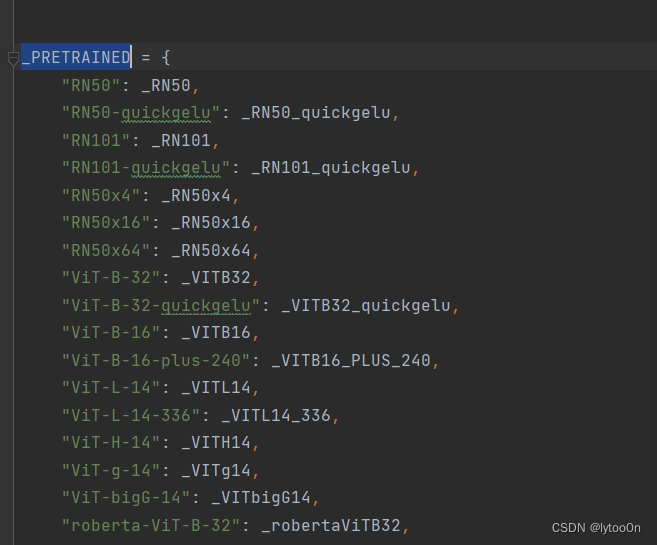
尽管model_pretrained获取了模型名称对应的地址字典,由于返回函数中执行模型路径判断.get(),对清理后的_clean_tag(tag),即本地test.yml设置的模型参数地址。显然字典里是没有该本地地址的。所以最后函数返回{}。
return model_pretrained.get(_clean_tag(tag), {})
def _clean_tag(tag: str):
# normalize pretrained tags
return tag.lower().replace('-', '_')再次回看代码判断,故执行最后一个elseif
elif os.path.exists(pretrained):
checkpoint_path = pretrained
成功读取到本地权重地址。
继续进行下列代码。
if checkpoint_path:
logging.info(f'Loading pretrained {model_name} weights ({pretrained}).')
if pretrained_cfg and "daclip" in model_name:
load_checkpoint(model.clip, checkpoint_path)
model.initial_controller()
model.lock_clip()load_checkpoint()函数加载预训练权重到模型实例
def load_checkpoint(model, checkpoint_path, strict=True):
state_dict = load_state_dict(checkpoint_path)
# detect old format and make compatible with new format
if 'positional_embedding' in state_dict and not hasattr(model, 'positional_embedding'):
state_dict = convert_to_custom_text_state_dict(state_dict)
resize_pos_embed(state_dict, model)
incompatible_keys = model.load_state_dict(state_dict, strict=strict)
return incompatible_keys参数解释
model: 要加载预训练权重的模型实例。checkpoint_path: 预训练权重文件的路径。strict: 布尔值,指示在加载状态字典时是否要求模型和权重的键完全匹配。
函数逻辑
-
state_dict = load_state_dict(checkpoint_path): 调用load_state_dict函数来加载指定路径下的预训练权重文件,并将其内容存储在state_dict变量中。 -
接下来的代码块检查
state_dict中是否存在positional_embedding键,并且模型实例中没有positional_embedding属性。这可能意味着模型的结构已经更新,而预训练权重是按照旧格式保存的。 -
如果检测到这种情况,调用
convert_to_custom_text_state_dict函数来将权重转换成与新模型格式兼容的形式。 -
resize_pos_embed(state_dict, model): 调用resize_pos_embed函数来调整(如果需要的话)位置嵌入(positional embedding)的大小,以匹配模型的期望大小。 -
incompatible_keys = model.load_state_dict(state_dict, strict=strict): 使用load_state_dict方法将处理后的state_dict加载到模型中。这个方法会尝试匹配并加载所有键,如果strict为True,那么只有完全匹配的键才会被加载,不匹配的键将被报告为不兼容的键。如果strict为False,那么即使键不完全匹配,也会尝试加载权重。 -
return incompatible_keys: 返回一个包含不兼容键的列表,这些键在加载过程中没有被加载到模型中。
返回值
函数返回一个列表,包含在加载过程中检测到的不兼容键。
总结
load_checkpoint 函数负责加载预训练权重到模型实例中,并处理可能的格式不兼容问题。这个函数确保了即使在模型结构发生变化的情况下,也能够尽可能地加载预训练权重。通过返回不兼容的键,它还提供了有关哪些权重未能加载的信息,这对于调试和进一步的模型调整非常有用
load_checkpoint(model.clip, checkpoint_path)
model.initial_controller()
model.lock_clip()
该代码依赖于读取配置阶段执行生成的model实例
三、model.py和daclip_model.py的CLIP模型加载
尽管我们在open_clip文件夹下的factory.py找到了模型配置。并有了create_model()和create_model_from_pretrained()的相关默认参数配置,然而这些都只是外层包装,更深入的代码需要我们查看model.py中的CLIP()和daclip_model.py下的DACLIP()
elif "daclip" in model_name:
clip_model = CLIP(**model_cfg, cast_dtype=cast_dtype)
model = DaCLIP(clip_model)-
clip_model = CLIP(**model_cfg, cast_dtype=cast_dtype): 这行代码创建了一个CLIP类的实例,名为clip_model。这个类的实例化是通过传递model_cfg字典中的配置参数以及cast_dtype参数来完成的。model_cfg包含了初始化CLIP模型所需的配置,如嵌入维度、视觉和文本配置等。 -
model = DaCLIP(clip_model): 紧接着,使用刚刚创建的clip_model实例作为参数,创建了另一个类的实例,名为model。这个类是DaCLIP,它是CLIP类的一个扩展或变体,用于实现特定的功能或适配。
**model_cfg: 这是 Python 中的参数解包语法,它将model_cfg字典中的键值对作为关键字参数传递给CLIP类的构造函数。例如,如果model_cfg包含了{'embed_dim': 512, 'vision_cfg': {...}, 'text_cfg': {...}},那么这些键值对将会被用作CLIP类构造函数的参数。cast_dtype: 这是一个变量,它指定了模型参数和激活值的数据类型。这个参数可能会被用来设置模型的精度,例如在混合精度训练中使用torch.float16或torch.bfloat16。
关于cast_dtype,根据create_model()的预设参数和处理函数
precision: str = 'fp32'cast_dtype = get_cast_dtype(precision)
结合model.py 中get_cast_dtyp()的定义,可了解该处理流程
def get_cast_dtype(precision: str):
cast_dtype = None
if precision == 'bf16':
cast_dtype = torch.bfloat16
elif precision == 'fp16':
cast_dtype = torch.float16
return cast_dtypeclip_model = CLIP(**model_cfg, cast_dtype=cast_dtype) 根据模型配置文件初始化模型
下文只对init()和配置参数传递流程解读,该类下的其他方法可参考
open_clip仓库成分与模型文件model.py 介绍 http://t.csdnimg.cn/rirBq
http://t.csdnimg.cn/rirBq
初始化_init_()
def __init__(
self,
embed_dim: int,
vision_cfg: CLIPVisionCfg,
text_cfg: CLIPTextCfg,
quick_gelu: bool = False,
cast_dtype: Optional[torch.dtype] = None,
output_dict: bool = False,
):
super().__init__()
self.output_dict = output_dict
self.visual = _build_vision_tower(embed_dim, vision_cfg, quick_gelu, cast_dtype)
text = _build_text_tower(embed_dim, text_cfg, quick_gelu, cast_dtype)
self.transformer = text.transformer
self.context_length = text.context_length
self.vocab_size = text.vocab_size
self.token_embedding = text.token_embedding
self.positional_embedding = text.positional_embedding
self.ln_final = text.ln_final
self.text_projection = text.text_projection
self.register_buffer('attn_mask', text.attn_mask, persistent=False)
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))参数
embed_dim: 嵌入维度,这是模型中嵌入层的维度。vision_cfg: 图像配置对象,包含了构建视觉塔(处理图像的神经网络部分)所需的配置信息。text_cfg: 文本配置对象,包含了构建文本处理部分(如文本编码器)所需的配置信息。quick_gelu: 布尔值,指示是否使用快速的GELU(Gaussian Error Linear Unit)激活函数。cast_dtype: 可选参数,指定数据类型,用于将模型参数转换为指定的数据类型。output_dict: 布尔值,指示模型输出是否应该是一个字典。
方法体解释
super().__init__(): 调用父类的构造函数。self.output_dict = output_dict: 存储传入的output_dict参数,这可能影响模型输出的格式。self.visual = _build_vision_tower(...): 调用一个内部函数_build_vision_tower来构建视觉塔,并存储结果。text = _build_text_tower(...): 调用一个内部函数_build_text_tower来构建文本塔,并存储结果。self.transformer = text.transformer: 从文本塔中提取变换器(transformer)模块。self.context_length = text.context_length: 存储文本塔的上下文长度。self.vocab_size = text.vocab_size: 存储文本塔的词汇表大小。self.token_embedding = text.token_embedding: 存储文本塔的词嵌入层。self.positional_embedding = text.positional_embedding: 存储文本塔的位置嵌入层。self.ln_final = text.ln_final: 存储文本塔的最终层归一化(Layer Normalization)。self.text_projection = text.text_projection: 存储文本塔的文本投影层。self.register_buffer('attn_mask', text.attn_mask, persistent=False): 注册一个缓冲区,用于存储文本塔的注意力掩码(attention mask),这个掩码在自注意力机制中用于指示哪些位置应该被模型关注。self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07)): 创建一个可学习的参数,用于缩放模型的输出(logits),初始化为一个全1的向量,乘以一个基于经验的对数缩放因子。
调用的 CLIPVisionCfg类进行视觉配置
class CLIPVisionCfg:
layers: Union[Tuple[int, int, int, int], int] = 12
width: int = 768
head_width: int = 64
mlp_ratio: float = 4.0
patch_size: int = 16
image_size: Union[Tuple[int, int], int] = 224
ls_init_value: Optional[float] = None # layer scale initial value
patch_dropout: float = 0. # what fraction of patches to dropout during training (0 would mean disabled and no patches dropped) - 0.5 to 0.75 recommended in the paper for optimal results
input_patchnorm: bool = False # whether to use dual patchnorm - would only apply the input layernorm on each patch, as post-layernorm already exist in original clip vit design
global_average_pool: bool = False # whether to global average pool the last embedding layer, instead of using CLS token (https://arxiv.org/abs/2205.01580)
attentional_pool: bool = False # whether to use attentional pooler in the last embedding layer
n_queries: int = 256 # n_queries for attentional pooler
attn_pooler_heads: int = 8 # n heads for attentional_pooling
output_tokens: bool = False
timm_model_name: str = None # a valid model name overrides layers, width, patch_size
timm_model_pretrained: bool = False # use (imagenet) pretrained weights for named model
timm_pool: str = 'avg' # feature pooling for timm model ('abs_attn', 'rot_attn', 'avg', '')
timm_proj: str = 'linear' # linear projection for timm model output ('linear', 'mlp', '')
timm_proj_bias: bool = False # enable bias final projection
timm_drop: float = 0. # head dropout
timm_drop_path: Optional[float] = None # backbone stochastic depth类是一个配置类,用于定义和存储与 CLIP 模型中视觉(图像处理)部分相关的配置参数。这个类提供了一系列的属性,允许用户自定义和初始化 CLIP 模型的视觉塔(Vision Transformer)的各种设置。下面是对这个类的主要属性的解释:
layers: 视觉塔中的层数,可以是一个整数或者一个包含四个整数的元组,表示不同层的层数。width: 视觉塔中每层的宽度,即特征维度。head_width: 头部(分类器)的宽度,通常是视觉塔最后一层的特征维度。mlp_ratio: MLP(多层感知机)中的隐藏层宽度与输入层宽度的比率。patch_size: 图像分块的大小,决定了如何将图像切分成小块来输入模型。image_size: 输入图像的大小,可以是一个整数或者一个包含两个整数的元组,表示图像的宽度和高度。
接下来是一些与正则化和池化相关的选项:
ls_init_value: 层尺度(Layer Scale)的初始值,用于正则化。patch_dropout: 训练过程中要丢弃的补丁(patch)的比例,用于正则化。input_patchnorm: 是否在每个补丁上使用输入层归一化(input layernorm)。global_average_pool: 是否使用全局平均池化来代替使用 CLS 标记的策略。attentional_pool: 是否在最后一层嵌入层使用注意力池化器(attentional pooler)。n_queries: 注意力池化器使用的查询数。attn_pooler_heads: 注意力池化器的头数。
最后是与使用 timm 库相关的配置选项:
timm_model_name: 如果提供了有效的模型名称,将覆盖layers,width,patch_size等参数。timm_model_pretrained: 是否使用预训练的(在 ImageNet 上)timm 模型权重。timm_pool: timm 模型的特征池化类型。timm_proj: timm 模型输出的线性投影类型。timm_proj_bias: 是否在最终投影中启用偏置。timm_drop: 头部丢弃(head dropout)的比率。timm_drop_path: 背部随机深度(backbone stochastic depth)的比率。
调用的 CLIPTextCfg进行文本处理相关配置
class CLIPTextCfg:
context_length: int = 77
vocab_size: int = 49408
width: int = 512
heads: int = 8
layers: int = 12
ls_init_value: Optional[float] = None # layer scale initial value
hf_model_name: str = None
hf_tokenizer_name: str = None
hf_model_pretrained: bool = True
proj: str = 'mlp'
pooler_type: str = 'mean_pooler'
embed_cls: bool = False
pad_id: int = 0
output_tokens: bool = FalseCLIPTextCfg 类是一个配置类,用于定义和存储与 CLIP 模型中文本处理部分相关的配置参数。这个类提供了一系列的属性,允许用户自定义和初始化 CLIP 模型的文本塔(Text Transformer)的各种设置。下面是对这个类的主要属性的解释:
context_length: 文本处理的上下文长度,即模型一次性处理的最大文本长度。vocab_size: 文本词汇表的大小,表示模型能够识别的不同词汇的数量。width: 文本塔中每层的宽度,即特征维度。heads: 多头注意力机制中的头数,用于并行处理信息。layers: 文本塔中的层数。ls_init_value: 层尺度(Layer Scale)的初始值,用于正则化。
接下来是与使用 Hugging Face(HF)相关的配置选项:
hf_model_name: Hugging Face 模型的名称,用于加载预训练的文本模型。hf_tokenizer_name: Hugging Face 分词器的名称,用于将文本转换为模型可以理解的格式。hf_model_pretrained: 是否使用预训练的 Hugging Face 模型权重。
其他配置选项:
proj: 文本投影的类型,这里是 'mlp',表示使用多层感知机进行投影。pooler_type: 池化器的类型,这里是 'mean_pooler',表示使用平均池化器来聚合文本信息。embed_cls: 是否将分类标记(通常是一个特殊的 [CLS] 标记)嵌入到文本中。pad_id: 填充标记的 ID,用于处理不同长度的文本序列。output_tokens: 是否输出每个文本标记的特征,而不是仅仅输出文本的整体表示
_build_vision_tower():根据提供的配置创建不同的视觉模型架构
def _build_vision_tower(
embed_dim: int,
vision_cfg: CLIPVisionCfg,
quick_gelu: bool = False,
cast_dtype: Optional[torch.dtype] = None
):
if isinstance(vision_cfg, dict):
vision_cfg = CLIPVisionCfg(**vision_cfg)
# OpenAI models are pretrained w/ QuickGELU but native nn.GELU is both faster and more
# memory efficient in recent PyTorch releases (>= 1.10).
# NOTE: timm models always use native GELU regardless of quick_gelu flag.
act_layer = QuickGELU if quick_gelu else nn.GELU
if vision_cfg.timm_model_name:
visual = TimmModel(
vision_cfg.timm_model_name,
pretrained=vision_cfg.timm_model_pretrained,
pool=vision_cfg.timm_pool,
proj=vision_cfg.timm_proj,
proj_bias=vision_cfg.timm_proj_bias,
drop=vision_cfg.timm_drop,
drop_path=vision_cfg.timm_drop_path,
patch_drop=vision_cfg.patch_dropout if vision_cfg.patch_dropout > 0 else None,
embed_dim=embed_dim,
image_size=vision_cfg.image_size,
)
elif isinstance(vision_cfg.layers, (tuple, list)):
vision_heads = vision_cfg.width * 32 // vision_cfg.head_width
visual = ModifiedResNet(
layers=vision_cfg.layers,
output_dim=embed_dim,
heads=vision_heads,
image_size=vision_cfg.image_size,
width=vision_cfg.width,
)
else:
vision_heads = vision_cfg.width // vision_cfg.head_width
norm_layer = LayerNormFp32 if cast_dtype in (torch.float16, torch.bfloat16) else LayerNorm
visual = VisionTransformer(
image_size=vision_cfg.image_size,
patch_size=vision_cfg.patch_size,
width=vision_cfg.width,
layers=vision_cfg.layers,
heads=vision_heads,
mlp_ratio=vision_cfg.mlp_ratio,
ls_init_value=vision_cfg.ls_init_value,
patch_dropout=vision_cfg.patch_dropout,
input_patchnorm=vision_cfg.input_patchnorm,
global_average_pool=vision_cfg.global_average_pool,
attentional_pool=vision_cfg.attentional_pool,
n_queries=vision_cfg.n_queries,
attn_pooler_heads=vision_cfg.attn_pooler_heads,
output_tokens=vision_cfg.output_tokens,
output_dim=embed_dim,
act_layer=act_layer,
norm_layer=norm_layer,
)
return visual
参数解释
embed_dim: 嵌入维度,这是模型中嵌入层的维度。vision_cfg: 视觉配置对象,包含了构建视觉塔所需的配置信息。quick_gelu: 布尔值,指示是否使用快速的GELU激活函数。cast_dtype: 可选参数,指定数据类型,用于将模型参数转换为指定的数据类型。
函数逻辑
-
如果
vision_cfg是一个字典,那么使用这个字典来创建一个CLIPVisionCfg实例。 -
根据
quick_gelu参数的值选择使用QuickGELU激活层还是使用 PyTorch 原生的nn.GELU。 -
如果
vision_cfg包含timm_model_name,则使用TimmModel来创建一个基于 timm 库的模型。 -
如果
vision_cfg.layers是一个元组或列表,假设配置是一个修改版的 ResNet 架构,使用ModifiedResNet来创建模型。 -
如果上述条件都不满足,那么使用
VisionTransformer来创建一个标准的 Vision Transformer 架构。 -
在创建
VisionTransformer时,根据vision_cfg中的参数配置模型的不同部分,如层数、头数、激活层、归一化层等。 -
返回创建好的
visual模型实例。
_build_text_tower()创建不同的文本模型架构
def _build_text_tower(
embed_dim: int,
text_cfg: CLIPTextCfg,
quick_gelu: bool = False,
cast_dtype: Optional[torch.dtype] = None,
):
if isinstance(text_cfg, dict):
text_cfg = CLIPTextCfg(**text_cfg)
if text_cfg.hf_model_name:
text = HFTextEncoder(
text_cfg.hf_model_name,
output_dim=embed_dim,
proj=text_cfg.proj,
pooler_type=text_cfg.pooler_type,
pretrained=text_cfg.hf_model_pretrained,
output_tokens=text_cfg.output_tokens,
)
else:
act_layer = QuickGELU if quick_gelu else nn.GELU
norm_layer = LayerNormFp32 if cast_dtype in (torch.float16, torch.bfloat16) else LayerNorm
text = TextTransformer(
context_length=text_cfg.context_length,
vocab_size=text_cfg.vocab_size,
width=text_cfg.width,
heads=text_cfg.heads,
layers=text_cfg.layers,
ls_init_value=text_cfg.ls_init_value,
output_dim=embed_dim,
embed_cls=text_cfg.embed_cls,
output_tokens=text_cfg.output_tokens,
pad_id=text_cfg.pad_id,
act_layer=act_layer,
norm_layer=norm_layer,
)
return text
函数逻辑
-
如果
text_cfg是一个字典,那么使用这个字典来创建一个CLIPTextCfg实例。 -
如果
text_cfg包含hf_model_name,则使用HFTextEncoder来创建一个基于 Hugging Face 的文本编码器。 -
如果上述条件不满足,那么使用
TextTransformer来创建一个标准的文本 Transformer 架构。 -
在创建
TextTransformer时,根据text_cfg中的参数配置模型的不同部分,如上下文长度、词汇表大小、激活层、归一化层等。 -
返回创建好的
text模型实例。
根据daclip_ViT-B-32.json文件里的字典通过__init__()到_build_vision_tower()再到
CLIPVisionCfg()这样的流程完成了参数传递。
{
"embed_dim": 512,
"vision_cfg": {
"image_size": 224,
"layers": 12,
"width": 768,
"patch_size": 32
},
"text_cfg": {
"context_length": 77,
"vocab_size": 49408,
"width": 512,
"heads": 8,
"layers": 12
},
"custom_text": true
}model = DaCLIP(clip_model)
class DaCLIP(nn.Module):
def __init__(self, clip_model: CLIP):
super().__init__()
self.clip = clip_model
self.visual = clip_model.visual
self.visual_control = copy.deepcopy(clip_model.visual)
self.visual_control.transformer = ControlTransformer(self.visual_control.transformer)
self.logit_scale = copy.deepcopy(clip_model.logit_scale)
def initial_controller(self):
for (kv, param_v), (kc, param_c) in zip(self.clip.visual.named_parameters(), self.visual_control.named_parameters()):
if 'transformer' not in kv:
param_c.data.copy_(param_v.data)
for param_v, param_c in zip(self.clip.visual.transformer.parameters(), self.visual_control.transformer.parameters()):
param_c.data.copy_(param_v.data)
self.logit_scale.data.copy_(self.clip.logit_scale.data)
def lock_clip(self):
for param in self.clip.parameters():
param.requires_grad = False
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
self.clip.visual.set_grad_checkpointing(enable)
self.clip.transformer.grad_checkpointing = enable
self.visual_control.set_grad_checkpointing(enable)
def encode_image(self, image, control=False, normalize: bool = False):
if control:
degra_features, hiddens = self.visual_control(image, output_hiddens=True)
image_features = self.clip.visual(image, control=hiddens)
image_features = F.normalize(image_features, dim=-1) if normalize else image_features
degra_features = F.normalize(degra_features, dim=-1) if normalize else degra_features
return image_features, degra_features
else:
return self.clip.encode_image(image, normalize)
def encode_text(self, text, normalize: bool = False):
return self.clip.encode_text(text, normalize)
def forward(
self,
image: Optional[torch.Tensor] = None,
text: Optional[torch.Tensor] = None,
):
(caption, degradation) = text.chunk(2, dim=-1) if text is not None else (None, None)
image_features, image_degra_features = self.encode_image(image, control=True, normalize=True) if image is not None else None
text_features = self.encode_text(caption, normalize=True) if text is not None else None
text_degra_features = self.encode_text(degradation, normalize=True) if degradation is not None else None
return {
"image_features": image_features,
"text_features": text_features,
"image_degra_features": image_degra_features,
"text_degra_features": text_degra_features,
"logit_scale": self.logit_scale.exp()
}在这个例子中,CLIP 类是父类,而 DaCLIP 类是子类。DaCLIP 类继承自 CLIP 类,并在其基础上进行了扩展和修改。以下是子类 DaCLIP 相对于父类 CLIP 所做的主要更改和添加:
-
初始化 (
__init__方法):DaCLIP类在初始化时创建了clip_model的一个副本,命名为self.visual,并创建了一个名为self.visual_control的控制塔,它是self.visual的深拷贝,但使用了ControlTransformer替换了原有的transformer。DaCLIP还复制了父类的logit_scale参数。
-
控制塔 (
initial_controller方法):DaCLIP类提供了一个方法来初始化控制塔的参数,确保它们与父类的visual塔的参数一致。
-
锁定 (
lock_clip方法):DaCLIP类添加了一个方法来锁定父类CLIP的所有参数,使其在训练过程中不会更新。
-
梯度检查点设置 (
set_grad_checkpointing方法):DaCLIP类扩展了父类的方法,同时为clip和visual_control设置梯度检查点。
-
图像编码 (
encode_image方法):DaCLIP类重写了图像编码方法,允许控制塔生成特征,并将这些特征与父类CLIP生成的特征结合起来。
-
前向传播 (
forward方法):DaCLIP类修改了前向传播方法,以处理额外的degradation输入,并输出控制塔生成的图像和文本的退化特征。
init方法
def __init__(self, clip_model: CLIP):
super().__init__()
self.clip = clip_model
self.visual = clip_model.visual
self.visual_control = copy.deepcopy(clip_model.visual)
self.visual_control.transformer = ControlTransformer(self.visual_control.transformer)
self.logit_scale = copy.deepcopy(clip_model.logit_scale)创建 self.visual:
- 在
DaCLIP类的__init__方法中,首先创建了一个名为self.visual的属性,它是clip_model(即父类CLIP的实例)的visual属性的一个引用。这意味着self.visual直接指向了父类中的visual属性,它们指向相同的对象。
深拷贝 self.visual 以创建 self.visual_control:该代码就是论文所需的Image Controller部分
- 接下来,使用
copy.deepcopy方法对self.visual进行了深拷贝,创建了一个新的对象self.visual_control。深拷贝意味着创建了self.visual中所有属性和子对象的完整副本,而不是简单地复制引用。这样,self.visual_control就是一个独立的、与self.visual完全相同的新对象,对它的任何修改都不会影响原始的self.visual。
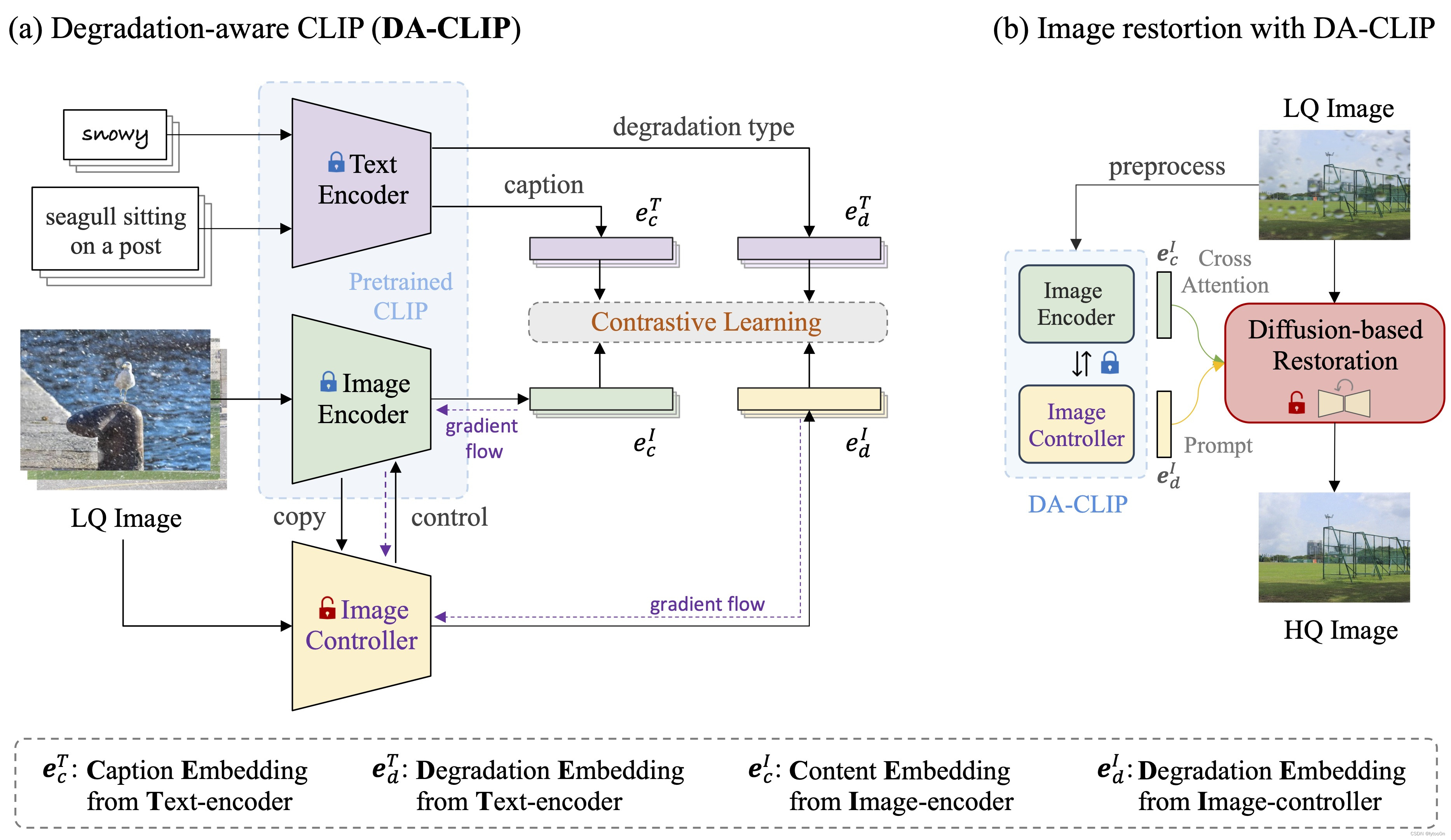
替换 self.visual_control 中的 transformer:
- 然后,
DaCLIP类将self.visual_control中的transformer属性替换为ControlTransformer类的实例。ControlTransformer是一个自定义的Transformer类,它可能包含了一些额外的逻辑或参数,用于实现对特征的控制。这一步是DaCLIP类区别于父类CLIP的关键之处,因为它引入了控制机制。
复制 logit_scale 参数:
- 最后,
DaCLIP类创建了logit_scale参数的一个深拷贝,并将其存储在self中。这样做是为了确保DaCLIP实例有自己的logit_scale参数,它的初始值与父类CLIP实例中的logit_scale相同。
ControlTransformer类
class ControlTransformer(nn.Module):
def __init__(self, transformer):
super().__init__()
self.transformer = transformer
self.layers = transformer.layers
self.width = transformer.width
self.zero_modules = nn.ModuleList([
self.zero_module(nn.Linear(self.width, self.width, 1))
for _ in range(self.layers)]).cuda()
self.grad_checkpointing = transformer.grad_checkpointing
def zero_module(self, module):
"""
Zero out the parameters of a module and return it.
"""
for p in module.parameters():
p.detach().zero_()
return module
def forward(self, x: torch.Tensor, attn_mask: Optional[torch.Tensor] = None,
output_hiddens: Optional[bool] = False, control: Optional[torch.Tensor] = None):
if output_hiddens:
hiddens = []
for z, r in zip(self.zero_modules, self.transformer.resblocks):
if self.grad_checkpointing and not torch.jit.is_scripting():
# TODO: handle kwargs https://github.com/pytorch/pytorch/issues/79887#issuecomment-1161758372
x = checkpoint(r, x, None, None, attn_mask)
else:
x = r(x, attn_mask=attn_mask)
zx = z(x)
if output_hiddens:
hiddens.append(zx)
if control is not None:
x += control.pop()
return (x, hiddens) if output_hiddens else x
这个类的目的是在 Transformer 模型的基础上添加控制机制,以便在前向传播过程中对特征进行调整。下面是对这个类的主要组成部分的详细解释:
初始化 (__init__ 方法):
self.transformer: 存储传入的 Transformer 模型,这个模型的参数将被用于初始化ControlTransformer。self.layers: 获取 Transformer 模型中的层数。self.width: 获取 Transformer 模型的宽度,即特征的维度。self.zero_modules: 创建一个模块列表,其中包含self.layers个nn.Linear层,每个层都是一个全连接层,用于生成控制信号。这些层的权重被初始化为零,这意味着它们不会对输入x产生影响,直到它们被进一步训练或调整。self.grad_checkpointing: 从传入的 Transformer 模型中获取梯度检查点设置。
零化模块 (zero_module 方法):
- 这个方法用于将给定模块的参数设置为零。这在初始化控制模块时很有用,因为它确保了控制模块在训练开始时不会对模型的行为产生影响。
前向传播 (forward 方法):
x: 输入特征张量。attn_mask: 可选的注意力掩码,用于 Transformer 中的自注意力机制。output_hiddens: 可选的布尔值,指示是否输出每个层的隐藏状态。control: 可选的控制张量,用于调整 Transformer 层的输出。
在前向传播过程中,ControlTransformer 执行以下步骤:
- 如果
output_hiddens为True,则创建一个空列表hiddens用于存储每个层的输出。 - 遍历
self.zero_modules和 Transformer 的残差块 (self.transformer.resblocks)。 - 对于每个残差块
r和对应的零化模块z:- 如果启用了梯度检查点 (
self.grad_checkpointing为True) 并且不是在 JIT 脚本模式下运行,则使用checkpoint函数来保存梯度。 - 应用残差块
r到输入x上,得到输出。 - 应用零化模块
z到输出上,得到zx。 - 如果
output_hiddens为True,则将zx添加到hiddens列表中。 - 如果提供了控制张量
control,则将控制信号添加到输出x上。
- 如果启用了梯度检查点 (
- 如果
output_hiddens为True,则返回(x, hiddens),否则只返回x。
ControlTransformer 类的关键特性是它允许通过 control 参数动态调整 Transformer 层的输出,这为模型提供了额外的灵活性和控制能力。
initial_controller(self)
def initial_controller(self):
for (kv, param_v), (kc, param_c) in zip(self.clip.visual.named_parameters(), self.visual_control.named_parameters()):
if 'transformer' not in kv:
param_c.data.copy_(param_v.data)
for param_v, param_c in zip(self.clip.visual.transformer.parameters(), self.visual_control.transformer.parameters()):
param_c.data.copy_(param_v.data)
self.logit_scale.data.copy_(self.clip.logit_scale.data) 这个方法的目的是确保 DaCLIP 实例在开始任何进一步的操作之前,其控制塔的参数与父类 CLIP 模型中的视觉塔参数保持一致。这样,控制塔就可以在保持父类模型特征的基础上,通过额外的控制信号来调整输出特征,从而实现更灵活的特征表示。
参数复制:
- 方法首先遍历
self.clip.visual(即父类CLIP的视觉塔)的所有参数及其对应的名称。 - 对于每一对参数(
kv,param_v)和(kc,param_c),如果参数名称不包含'transformer',则将控制塔中相应参数的值设置为视觉塔中参数的值。这样做是为了确保控制塔的非Transformer部分与父类模型的视觉塔具有相同的初始参数。
Transformer参数复制:
- 接下来,方法遍历
self.clip.visual.transformer的所有参数,并将其与self.visual_control.transformer的参数进行比较。 - 对于每一对参数(
param_v,param_c),将父类模型的视觉塔中的参数值复制到控制塔的对应参数中。这样做是为了确保控制塔的Transformer部分也具有与父类模型相同的初始参数。
Logit Scale参数复制:
- 最后,方法将父类
CLIP模型中的logit_scale参数值复制到DaCLIP实例中的同名参数中。
encode_image()
def encode_image(self, image, control=False, normalize: bool = False):
if control:
degra_features, hiddens = self.visual_control(image, output_hiddens=True)
image_features = self.clip.visual(image, control=hiddens)
image_features = F.normalize(image_features, dim=-1) if normalize else image_features
degra_features = F.normalize(degra_features, dim=-1) if normalize else degra_features
return image_features, degra_features
else:
return self.clip.encode_image(image, normalize)这个方法提供了两种不同的编码方式,一种是正常的编码,另一种是通过控制塔进行的编码。下面是对这个方法的详细解释:
方法逻辑:
-
正常编码:
如果 control 参数为 False,则直接调用父类 CLIP 的 encode_image 方法来编码图像,并返回结果。这是标准的编码流程,不涉及控制塔。
-
控制编码:
如果 control 参数为 True,则执行以下步骤:
- 首先,调用
self.visual_control方法来生成控制信号。这个方法接收图像作为输入,并返回控制塔的输出特征degra_features和每个层的隐藏状态hiddens。 - 然后,使用父类
CLIP的visual属性来编码图像,并将hiddens作为控制信号传递给self.clip.visual。这样,控制信号就可以影响图像编码的过程。 - 如果
normalize参数为True,则对生成的图像特征image_features和degra_features进行归一化处理。归一化通常是将特征向量的范数缩放到一个固定值,例如 1,这有助于提高模型的泛化能力。 - 最后,返回处理后的图像特征
image_features和控制塔生成的退化特征degra_features。
这个方法的设计允许 DaCLIP 模型在需要时使用控制信号来调整图像编码,这可以用于各种高级任务,如图像编辑、风格迁移等。通过设置 control 参数,用户可以选择使用标准的图像编码方式,或者使用包含控制信号的编码方式。
forward()
def forward(
self,
image: Optional[torch.Tensor] = None,
text: Optional[torch.Tensor] = None,
):
(caption, degradation) = text.chunk(2, dim=-1) if text is not None else (None, None)
image_features, image_degra_features = self.encode_image(image, control=True, normalize=True) if image is not None else None
text_features = self.encode_text(caption, normalize=True) if text is not None else None
text_degra_features = self.encode_text(degradation, normalize=True) if degradation is not None else None
return {
"image_features": image_features,
"text_features": text_features,
"image_degra_features": image_degra_features,
"text_degra_features": text_degra_features,
"logit_scale": self.logit_scale.exp()
}forward 方法是 DaCLIP 类的核心方法,它定义了模型如何处理输入的图像和文本数据,并输出相应的特征表示。这个方法接收两个可选参数 image 和 text,分别代表输入的图像张量和文本张量。以下是该方法的详细解释:
方法逻辑:
处理文本输入:
如果 text 不为 None,则使用 chunk 方法将文本张量分成两部分,这里假设文本张量是由两部分组成的,可能是描述(caption)和退化(degradation)信息。如果没有提供文本,这两部分都设置为 None。
编码图像:
如果 image 不为 None,则调用 self.encode_image 方法来编码图像。这里使用 control=True 来告诉 encode_image 方法使用控制塔生成的特征,normalize=True 表示输出的特征需要进行归一化处理。如果没有提供图像,image_features 和 image_degra_features 将被设置为 None。
编码文本特征:
使用 self.encode_text 方法分别对 caption 和 degradation 进行编码,生成文本特征和退化特征。如果 caption 或 degradation 为 None,则不会生成相应的特征。
返回结果:
最后,方法返回一个字典,包含以下键值对:
"image_features": 编码后的图像特征。
"text_features": 编码后的文本特征。
"image_degra_features": 控制塔生成的图像退化特征。
"text_degra_features": 控制塔生成的文本退化特征。
"logit_scale": logit_scale 参数的指数,通常用于调整模型输出的缩放。
这个方法的设计使得 DaCLIP 模型能够同时处理图像和文本输入,并且能够利用控制塔来调整特征表示。这对于执行复杂的多模态任务非常有用,例如在图像和文本之间建立细粒度的关联,或者在生成任务中控制生成内容的风格和质量。通过这种方式,DaCLIP 模型可以灵活地适应各种应用场景。
经过以上方法生成了DaCLIP模型实例但还未加载模型参数
加载模型参数
load_checkpoint(model.clip, checkpoint_path)
model.initial_controller()
model.lock_clip()
load_checkpoint
在第二章末尾介绍了 load_checkpoint函数,根据checkpoint_path的本地模型参数地址,经过一系列处理后使用model.load_state_dict(state_dict, strict=strict),初始化了model.clip
关于model.clip:
model.clip 指的是 DaCLIP 类的一个属性,它直接引用了 DaCLIP 实例中的 CLIP 模型。这里的 model 是 DaCLIP 类的一个实例,而 clip_model 是在创建 DaCLIP 实例时传入的 CLIP 模型的实例。
在 DaCLIP 类的 __init__ 方法中,clip_model 被用作参数来创建 DaCLIP 实例。这个参数是一个 CLIP 类的实例,它包含了原始的 CLIP 模型的所有组件,如视觉塔(visual)、文本塔(text)等。DaCLIP 类通过 self.clip = clip_model 将这个原始的 CLIP 模型实例存储为 DaCLIP 实例的一个属性。
因此,当你访问 model.clip 时,你实际上是访问了 DaCLIP 实例中嵌入的原始 CLIP 模型。这意味着你可以通过 model.clip 访问和使用原始 CLIP 模型的所有功能和属性,例如编码图像和文本、生成特征表示等。这种设计允许 DaCLIP 在保留原始 CLIP 模型功能的基础上,增加额外的控制机制和可能的其他功能。
调用DaCLIP的initial_controller()参考上文
lock_clip冻结预训练模型
遍历 DaCLIP 实例中的 CLIP 模型的所有参数,并将它们的 requires_grad 属性设置为 False。这样做会锁定这些参数,使它们在后续的训练过程中不会更新。
def lock_clip(self):
for param in self.clip.parameters():
param.requires_grad = False
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









