






Monkey : Image Resolution and Text Label Are Important Things for Large Multi-modal Models
动机
- **提高可处理的像素大小:**以往方法对于处理高分辨率图像有困难。因此Monkey的核心创新在于通过将高分辨率图像划分为较小的均匀patch,每个patch的大小与预训练的视觉编码器的原始训练尺寸相匹配(如448×448),并且都配备了独立的adapter,使得Monkey能够处理高达1344×896像素的分辨率。通过这种方法,Monkey能够更详细地捕捉复杂的视觉信息。
- **训练数据的增强:**以往多模态训练数据集如COYO and LAION 的caption都很短,导致模型不能很好地学习从而对image精细化描述。因此Monkey还引入了多层次描述生成方法,丰富了场景-对象的关联上下文,从而更有效地从生成的数据中学习。
方法
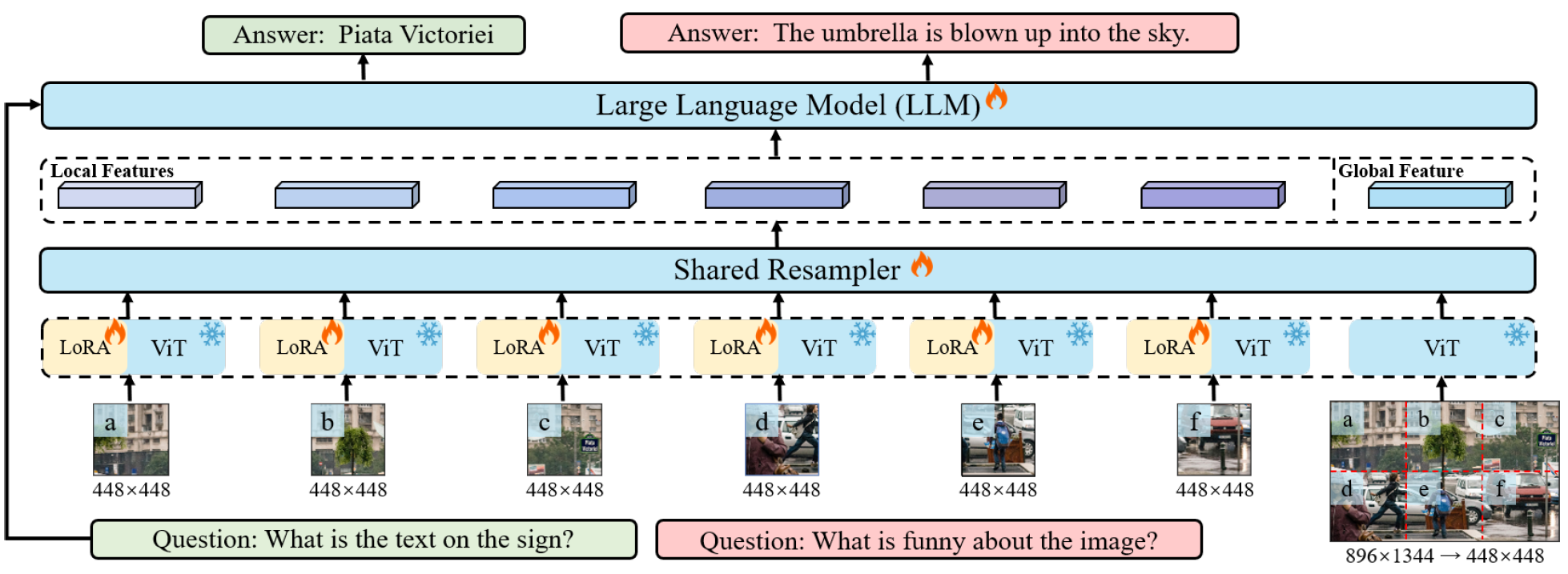
1. 增强输入分辨率 (Enhancing Input Resolution)
**问题背景:**传统的大型多模态模型(如LLaVA1.5、Qwen-VL)在处理高分辨率图像时存在挑战,通常使用较小分辨率(如448×448)的图像进行训练。在处理更大的图像时,通常使用插值方法直接扩大输入尺寸,然而,这种方法效果有限并且需要大量计算资源。
Monkey的方法:
- 图像划分策略: 先将输入图像 I ∈ R H × W × 3 I \in \mathbb{R}^{H \times W \times 3} I∈RH×W×3 按照支持的分辨率 W ∈ R H v × W v W \in \mathbb{R}^{H_v \times W_v} W∈RHv×Wv 使用滑动窗口划分为较小的局部图像块。
- 局部编码处理: 每个图像块由一个共享的视觉编码器(Vision Transformer,ViT)进行处理。为了适应不同部分的视觉特征,引入LoRA进行调整。
- 全局与局部特征结合: 为了保持输入图像的整体结构信息,Monkey同时使用视觉编码器和视觉重采样器(Visual Resampler)处理全局图像和局部图像块。视觉重采样器使用了基于Flamingo模型的机制,通过交叉注意力模块将图像特征映射到语言特征空间,生成更高语义层次的视觉表示。
这种方法在保持详细视角和整体视角的平衡的同时,避免了计算需求的大幅增加。
2. 多层次描述生成 (Multi-level Description Generation)
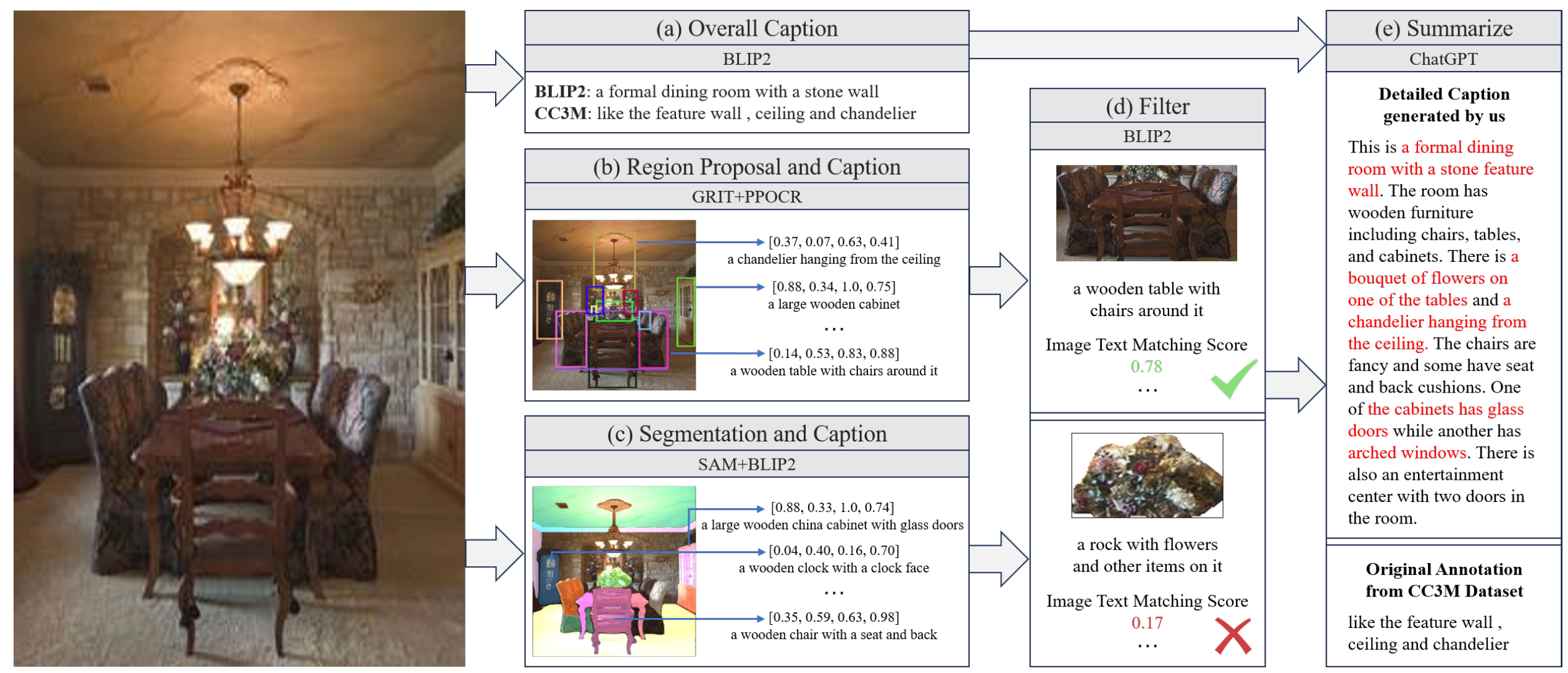
**背景问题:**现有的数据集(如LAION、COYO、CC3M)通常只提供简单的图像-文本对(例如,一句话描述复杂的图像),缺乏详细的图像描述,这使得即使在高分辨率图像上训练的模型也难以准确地将视觉特征与基本描述关联。
**Monkey的多层次描述生成方法:**为了克服这一局限,Monkey开发了一种自动化的多层次描述生成方法,旨在创建高质量、丰富的图像描述数据。该方法通过集成多种先进系统的输出,提供更为全面和分层次的描述生成:
- 系统组合: 结合了多个高级系统的特点:BLIP2:深刻理解图像与文本的关系。PPOCR:强大的光学字符识别系统。GRIT:专注于图像-文本匹配的细节。SAM:用于语义对齐的动态模型。ChatGPT:借助其上下文理解和语言生成能力。
- 生成流程: 图像描述过程从BLIP2生成整体描述开始,随后GRIT模型生成特定区域、对象及其特征的详细描述。PPOCR从图像中提取文本,SAM对图像进行分割并识别对象。最后,将所有描述数据输入ChatGPT进行微调,生成准确且丰富的图像描述。
**优势:**这种方法有效地结合了各个系统的优势,实现了图像描述生成的分层和全面化风格,捕捉到广泛的视觉和文本细节。
3. 多任务训练 (Multi-task Training)
**目标:**训练一个成本效益高且能够理解各种类型图像以执行多种任务的模型。
**训练策略:**通过整合不同数据集并为所有任务提供统一的指令来增强模型的学习能力和训练效率。训练任务包括生成图像描述、回答基于图像的问题等:
- 指令设计: 对于图像描述任务,使用简单的“Generate the caption in English:”指令;对于更复杂的描述,使用“Generate the detailed caption in English:”指令。对于图像问答任务,使用直接的格式:“{question} Answer: {answer}”。
- 数据集整合: 使用多种公共数据集(如COCO Caption、TextCaps、VQAV2、OKVQA、GQA、ScienceQA、VizWiz等)训练模型,并利用多层次描述生成方法重新生成了约427k的图像-文本对数据,以确保训练的平衡性。
实验
实现细节(Implementation Details)
模型配置:
- 实验基于预训练的ViT-BigG视觉编码器和来自Qwen-VL的LLM大语言模型。
- 在指令调优阶段,Monkey设置输入分辨率 H v , W v H_v, W_v Hv,Wv 为448,以匹配Qwen-VL的视觉编码器。
- 使用一致的重采样器处理所有图像块,每个块使用相同的256个可学习查询(learnable queries)。
- 由于训练时间限制,主要实验使用的图像尺寸为896×896。
- LoRA模块的设置:注意力模块的秩(rank)设为16,MLP模块的秩设为32
结果
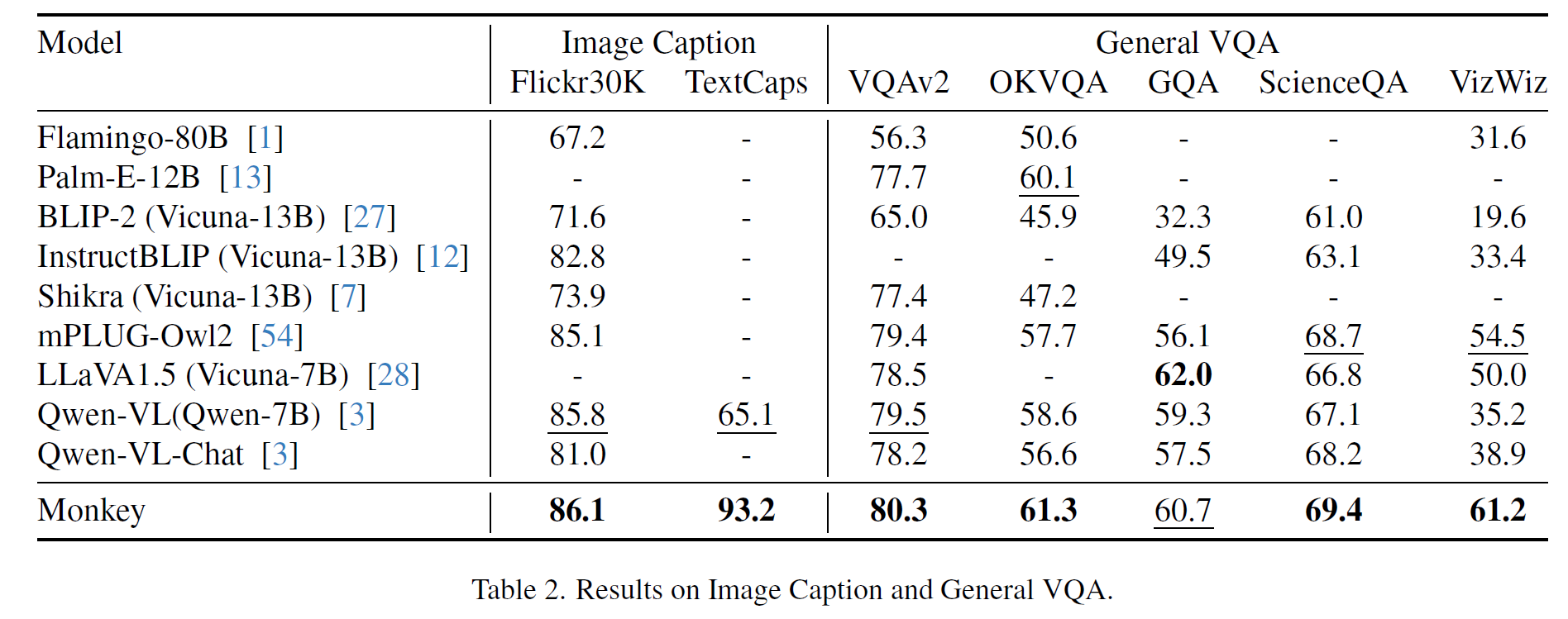
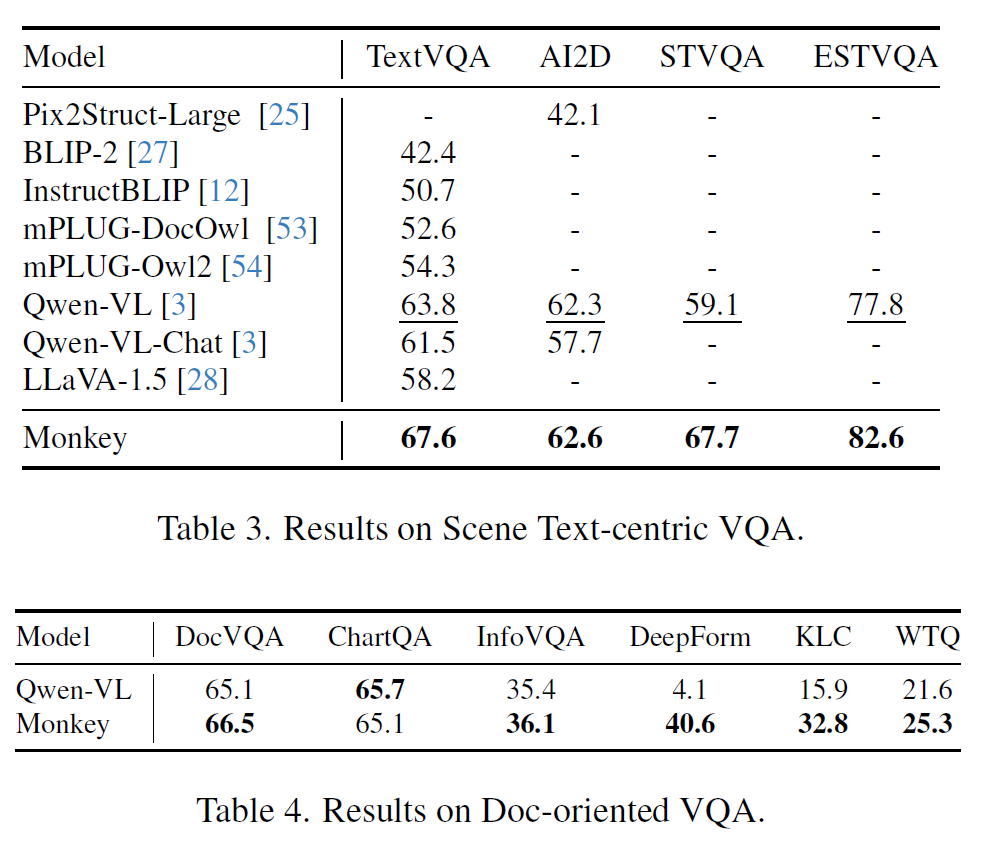
消融
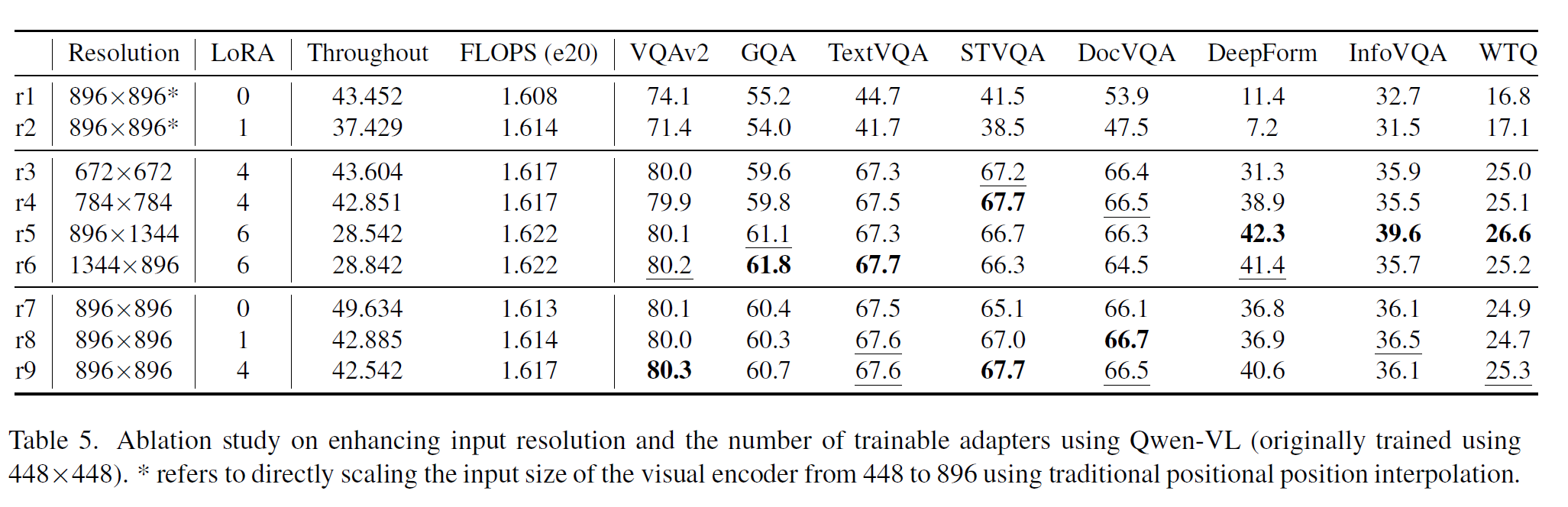
限制
Monkey模型在处理输入图像时受限于语言模型的输入长度,最多只能支持六个图像块,这限制了输入分辨率的进一步扩展。此外,多层次描述生成方法只能描述图像中呈现的场景,其范围受限于BLIP2和原始CC3M注释中封装的世界知识。
















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









