







你打算利用空闲时间来做兼职工作赚些零花钱。
这里有 n 份兼职工作,每份工作预计从 startTime[i] 开始到 endTime[i] 结束,报酬为 profit[i]。
给你一份兼职工作表,包含开始时间 startTime,结束时间 endTime 和预计报酬 profit 三个数组,请你计算并返回可以获得的最大报酬。
注意,时间上出现重叠的 2 份工作不能同时进行。
如果你选择的工作在时间 X 结束,那么你可以立刻进行在时间 X 开始的下一份工作。
示例 1:

输入:startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70]
输出:120
解释:
我们选出第 1 份和第 4 份工作,
时间范围是 [1-3]+[3-6],共获得报酬 120 = 50 + 70。
示例 2:
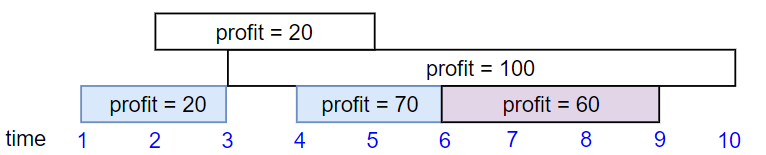
输入:startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60]
输出:150
解释:
我们选择第 1,4,5 份工作。
共获得报酬 150 = 20 + 70 + 60。
示例 3:

输入:startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4]
输出:6
提示:
·1 <= startTime.length == endTime.length == profit.length <= 5 * 10^4
·1 <= startTime[i] < endTime[i] <= 10^9
·1 <= profit[i] <= 10^4
题目大意:选择时间上不重叠且总报酬最大的工作,返回最大报酬
分析:设dp[k]为截止到time=k时可获得的最大报酬,profit[t]表示第t份(按结束时间升序排序)工作的收益
(1)由题得,dp[j]=max(dp[j-1],dp[i]+m),m为开始时间为i、结束时间为j的工作的报酬;
(2)由于endTime数组的值数量级过高,会使dp数组元素数量过大超出内存上限,需对dp数组大小优化,因此将dp[k]重定义为前k份工作可得的最大报酬,则dp[k]=max(dp[k-1],dp[q]+profit[k]),q表示第k份工作开始前已结束的工作数;
(3)由(2)的解法可知计算dp[k]时需查找确定q的值,只需从工作序号在[1,k-1]中查找最大的q并使其满足endTime[q]<=startTime[k]。因为将endTime数组升序排序,所以可用二分搜索优化查找过程。
class Solution {
public:
int jobScheduling(vector<int>& startTime, vector<int>& endTime, vector<int>& profit) {
int N=startTime.size();
vector<int> dp(N+1);
vector<int> index(N);
//对工作按照endTime升序排序
iota(index.begin(),index.end(),0);
sort(index.begin(),index.end(),[&](int id1,int id2){
return endTime[id1]<endTime[id2];
});
dp[0]=0;
for(int i=0;i<N;++i){
//二分搜索满足endTime[q]<startTime[i]的最大的q
int l=0,r=i-1,mid;
int tar=startTime[index[i]];
while(l<=r){
mid=(l+r)/2;
if(endTime[index[mid]]<=tar) l=mid+1;
else r=mid-1;
}
//计算dp[i+1]
dp[i+1]=max(dp[i],dp[l]+profit[index[i]]);
}
return dp[N];
}
};














 2127
2127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









