







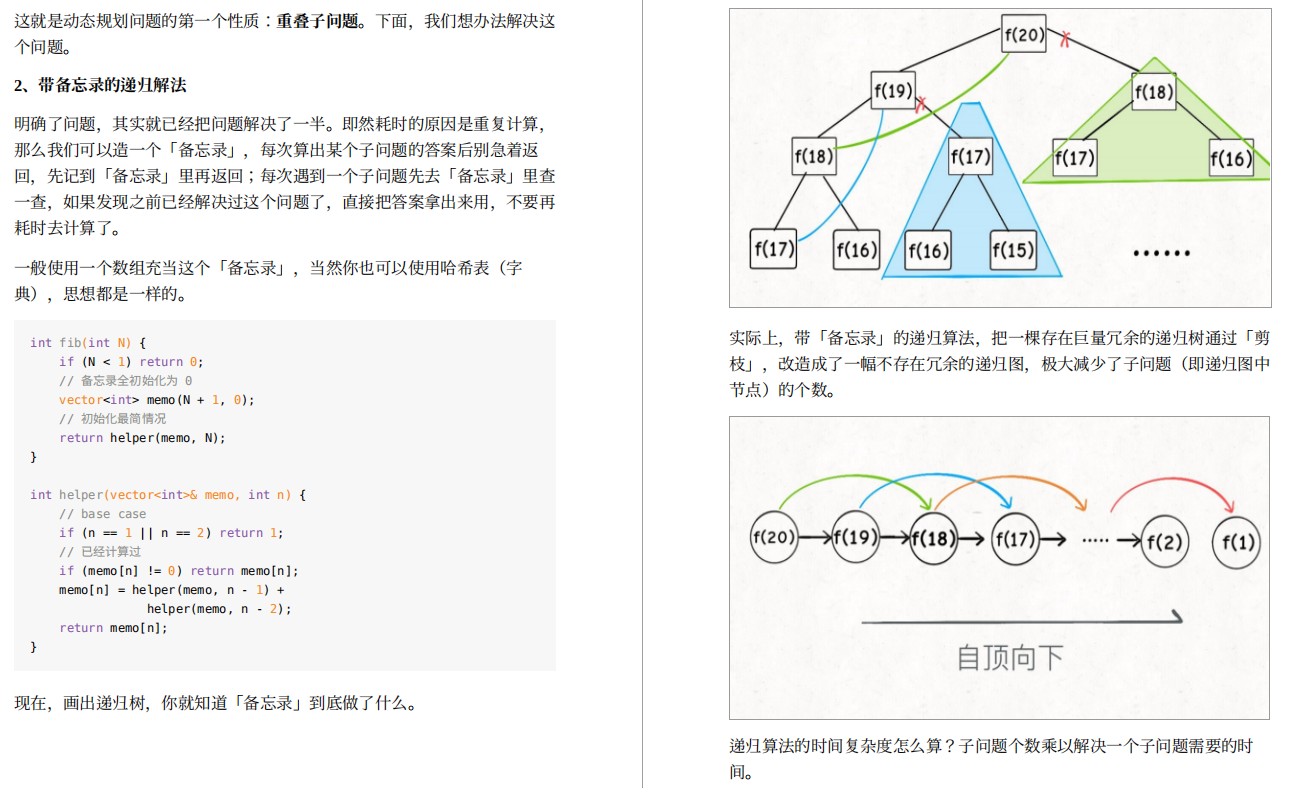
现在我们需要将原先分布在broker 1-3节点上的分区重新分布到broker 1-4节点上,借助kafka-reassign-partitions.sh工具生成reassign plan,不过我们先得按照要求定义一个文件,里面说明哪些topic需要重新分区,文件内容如下:
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ cat reassign.json {
"topics":[{"topic":"heima-par"}],
"version":1
}
然后使用 kafka-reassign-partitions.sh 工具生成reassign plan
然后执行脚本 bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to -move-json-file reassign.json --broker-list "0,1,2,3" --generate
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-reassign-
partitions.sh --zookeeper localhost:2181 --topics-to
-move-json-file reassign.json --broker-list "0,1,2,3" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"heima-par","partition":2,"replicas": [1,0,2],"log_dirs":["any","any","any"]},
{"topic":"heima- par","partition":1,"replicas":[0,2,1],"log_dirs":["any","any","any"]},
{"topic":"heima-par","partition":0,"replicas":[2,1,0],"log_dirs": ["any","any","any"]},
{"topic":"heima-par","partition":3,"replicas": [2,1,0],"log_dirs":["any","any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"heima-par","partition":0,"replicas": [1,2,3],"log_dirs":["any","any","any"]},
{"topic":"heima- par","partition":2,"replicas":[3,0,1],"log_dirs":["any","any","any"]},
{"topic":"heima-par","partition":1,"replicas":[2,3,0],"log_dirs": ["any","any","any"]},
{"topic":"heima-par","partition":3,"replicas": [0,1,2],"log_dirs":["any","any","any"]}]}
上面命令中
--generate 表示指定类型参数
--topics-to-move-json-file 指定分区重分配对应的主题清单路径
注意:
命令输入两个Json字符串,第一个JSON内容为当前的分区副本分配情况,第二个为重新分配的候选方案,注意这里只是生成一份可行性的方案,并没有真正执行重分配的动作。
我们将第二个JSON内容保存到名为result.json文件里面(文件名不重要,文件格式也不一定要以json为结尾,只要保证内容是json即可),然后执行这些reassign plan:
重新分配JSON文件
{
"version": 1,
"partitions": [ {
"topic": "heima-par",
"partition": 0,
"replicas": [ 1,2,3 ],
"log_dirs": [ "any", "any", "any" ]
},{
"topic": "heima-par",
"partition": 2,
"replicas": [ 3,0,1 ],
"log_dirs": [ "any", "any", "any" ]
},{
"topic": "heima-par",
"partition": 1,
"replicas": [ 2,3,0 ],
"log_dirs": [ "any", "any", "any" ]
},{
"topic": "heima-par",
"partition": 3,
"replicas": [ 0,1,2 ],
"log_dirs": [ "any", "any", "any" ]
}
]
}
执行分配策略
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-reassign-
partitions.sh --zookeeper localhost:2181 --reassignm
ent-json-file result.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"heima-par","partition":2,"replicas": [1,0,2],"log_dirs":["any","any","any"]},
{"topic":"heima- par","partition":1,"replicas":[0,2,1],"log_dirs":["any","any","any"]},
{"topic":"heima-par","partition":0,"replicas":[2,1,0],"log_dirs": ["any","any","any"]},
{"topic":"heima-par","partition":3,"replicas": [2,1,0],"log_dirs":["any","any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
查看分区重新分配的进度:
itcast@Server-node:/mnt/d/kafka-cluster/kafka-1$ bin/kafka-reassign-
partitions.sh --zookeeper localhost:2181 --reassignment-json-file result.json --
verify
Status of partition reassignment:
Reassignment of partition heima-par-3 completed successfully
Reassignment of partition heima-par-0 is still in progress
Reassignment of partition heima-par-2 is still in progress
Reassignment of partition heima-par-1 is still in progress
从上面信息可以看出 heima-par-3已经完成,其他三个正在进行中。
四、修改副本因子
场景
实际项目中我们可能在创建topic时没有设置好正确的replication-factor,导致kafka集群虽然是高可用的,但是该topic在有broker宕机时,可能发生无法使用的情况。topic一旦使用又不能轻易删除重建,因此动态增加副本因子就成为最终的选择。
说明:kafka 1.0版本配置文件默认没有default.replication.factor=x, 因此如果创建topic时,不指定– replication-factor 想, 默认副本因子为1. 我们可以在自己的server.properties中配置上常用的副本因子,省去手动调整。例如设置default.replication.factor=3
首先我们配置topic的副本,保存为json文件
{
"version":1,
"partitions":[
{"topic":"heima","partition":0,"replicas":[0,1,2]},
{"topic":"heima","partition":1,"replicas":[0,1,2]},
{"topic":"heima","partition":2,"replicas":[0,1,2]}
]
}
然后执行脚本 bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file replication-factor.json --execute
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-reassign-partitions.sh --
zookeeper localhost:2181 --reassignment-json-file replication-factor.json --
execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topic0703","partition":1,"replicas": [1,0],"log_dirs":["any","any"]},
{"topic":"topic0703","partition":0,"replicas": [0,1],"log_dirs":["any","any"]},
{"topic":"topic0703","partition":2,"replicas": [2,0],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions.
验证
itcast@Server-node:/mnt/d/kafka_2.12-2.2.1$ bin/kafka-topics.sh --describe --
zookeeper localhost:2181 --topic topic0703
Topic:topic0703 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: topic0703 Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 0
Topic: topic0703 Partition: 1 Leader: 1 Replicas: 0,1,2 Isr: 1,0
Topic: topic0703 Partition: 2 Leader: 2 Replicas: 0,1,2 Isr: 2,0
五、分区分配策略
按照Kafka默认的消费逻辑设定,一个分区只能被同一个消费组(ConsumerGroup)内的一个消费者消费。假设目前某消费组内只有一个消费者C0,订阅了一个topic,这个topic包含7个分区,也就是说这个消费者C0订阅了7个分区,参考下图
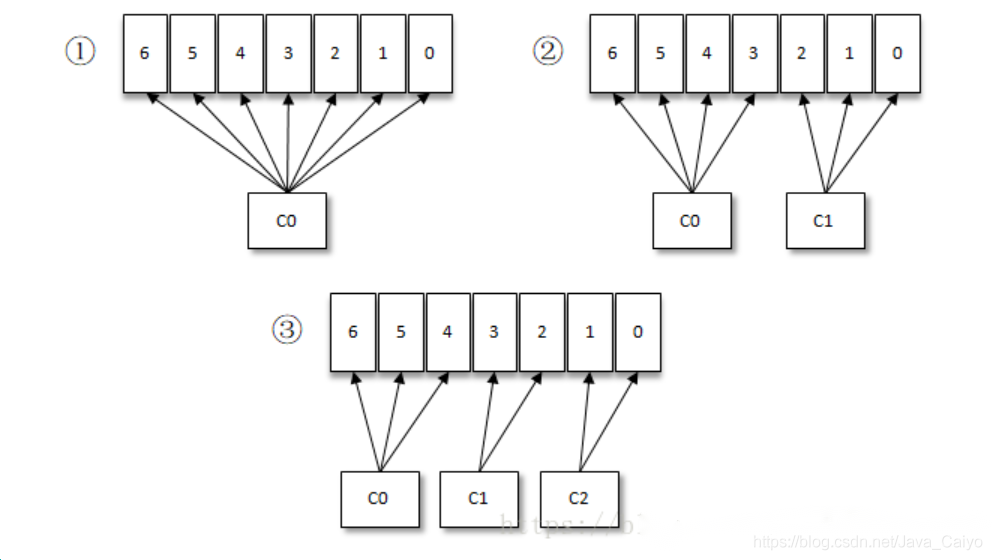
此时消费组内又加入了一个新的消费者C1,按照既定的逻辑需要将原来消费者C0的部分分区分配给消费者C1消费,情形上图(2),消费者C0和C1各自负责消费所分配到的分区,相互之间并无实质性的干扰。
接着消费组内又加入了一个新的消费者C2,如此消费者C0、C1和C2按照上图(3)中的方式各自负责消费所分配到的分区。
如果消费者过多,出现了消费者的数量大于分区的数量的情况,就会有消费者分配不到任何分区。参考下图,一共有8个消费者,7个分区,那么最后的消费者C7由于分配不到任何分区进而就无法消费任何消息。
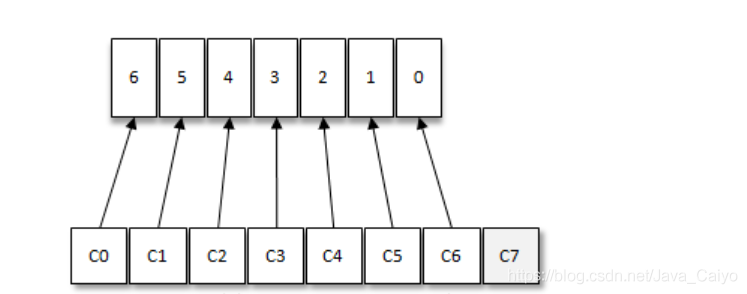
上面各个示例中的整套逻辑是按照Kafka中默认的分区分配策略来实施的。Kafka提供了消费者客户端参数partition.assignment.strategy用来设置消费者与订阅主题之间的分区分配策略。默认情况下,此参数的值为:org.apache.kafka.clients.consumer.RangeAssignor,即采用RangeAssignor分配策略。除此之外,Kafka中还提供了另外两种分配策略: RoundRobinAssignor和StickyAssignor。消费者客户端参数partition.asssignment.strategy可以配置多个分配策略,彼此之间以逗号分隔。
1.RangeAssignor分配策略
参考源码:org.apache.kafka.clients.consumer.RangeAssignor
RangeAssignor策略 的原理是 按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。 对于每一个topic, RangeAssignor策略会将消费组内所有订阅这个topic的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
假设n=分区数/消费者数量,m=分区数%消费者数量,那么前m个消费者每个分配n+1个分区,后面的(消费者数量-m)个消费者每个分配n个分区。
假设消费组内有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有4个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t0p3、t1p0、t1p1、t1p2、t1p3。最终的分配结果为:
消费者C0:t0p0、t0p1、t1p0、t1p1
消费者C1:t0p2、t0p3、t1p2、t1p3
假设上面例子中2个主题都只有3个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
消费者C0:t0p0、t0p1、t1p0、t1p1
消费者C1:t0p2、t1p2
可以明显的看到这样的分配并不均匀,如果将类似的情形扩大,有可能会出现部分消费者过载的情况。
2.RoundRobinAssignor分配策略
参考源码:org.apache.kafka.clients.consumer.RoundRobinAssignor
RoundRobinAssignor策略 的原理是将消费组内所有消费者以及消费者所订阅的所有topic的partition按照字典序排序,然后通过轮询方式逐个将分区以此分配给每个消费者。 RoundRobinAssignor策略对应的partition.assignment.strategy参数值为:org.apache.kafka.clients.consumer.RoundRobinAssignor。
假设消费组中有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有3个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
消费者C0:t0p0、t0p2、t1p1
消费者C1:t0p1、t1p0、t1p2
如果同一个消费组内的消费者所订阅的信息是不相同的,那么在执行分区分配的时候就不是完全的轮询分配,有可能会导致分区分配的不均匀。如果某个消费者没有订阅消费组内的某个topic,那么在分配分区的时候此消费者将分配不到这个topic的任何分区。
假设消费组内有3个消费者C0、C1和C2,它们共订阅了3个主题:t0、t1、t2,这3个主题分别有1、2、 3个分区,即整个消费组订阅了t0p0、t1p0、t1p1、t2p0、t2p1、t2p2这6个分区。具体而言,消费者C0订阅的是主题t0,消费者C1订阅的是主题t0和t1,消费者C2订阅的是主题t0、t1和t2,那么最终的分配结果为:
消费者C0:t0p0
消费者C1:t1p0
消费者C2:t1p1、t2p0、t2p1、t2p2
可以看到RoundRobinAssignor策略也不是十分完美,这样分配其实并不是最优解,因为完全可以将分区t1p1分配给消费者C1。
最后的内容
在开头跟大家分享的时候我就说,面试我是没有做好准备的,全靠平时的积累,确实有点临时抱佛脚了,以至于我自己还是挺懊恼的。(准备好了或许可以拿个40k,没做准备只有30k+,你们懂那种感觉吗)
如何准备面试?
1、前期铺垫(技术沉积)
程序员面试其实是对于技术的一次摸底考试,你的技术牛逼,那你就是大爷。大厂对于技术的要求主要体现在:基础,原理,深入研究源码,广度,实战五个方面,也只有将原理理论结合实战才能把技术点吃透。
下面是我会看的一些资料笔记,希望能帮助大家由浅入深,由点到面的学习Java,应对大厂面试官的灵魂追问,有需要的话就戳这里:蓝色传送门打包带走吧。
这部分内容过多,小编只贴出部分内容展示给大家了,见谅见谅!
- Java程序员必看《Java开发核心笔记(华山版)》

- Redis学习笔记
- Java并发编程学习笔记
四部分,详细拆分并发编程——并发编程+模式篇+应用篇+原理篇
- Java程序员必看书籍《深入理解 ava虚拟机第3版》(pdf版)

- 大厂面试必问——数据结构与算法汇集笔记
其他像Spring,SpringBoot,SpringCloud,SpringCloudAlibaba,Dubbo,Zookeeper,Kafka,RocketMQ,RabbitMQ,Netty,MySQL,Docker,K8s等等我都整理好,这里就不一一展示了。
2、狂刷面试题
技术主要是体现在平时的积累实用,面试前准备两个月的时间再好好复习一遍,紧接着就可以刷面试题了,下面这些面试题都是小编精心整理的,贴给大家看看。
①大厂高频45道笔试题(智商题)

②BAT大厂面试总结(部分内容截图)
③面试总结
3、结合实际,修改简历
程序员的简历一定要多下一些功夫,尤其是对一些字眼要再三斟酌,如“精通、熟悉、了解”这三者的区别一定要区分清楚,否则就是在给自己挖坑了。当然不会包装,我可以将我的简历给你参考参考,如果还不够,那下面这些简历模板任你挑选:
以上分享,希望大家可以在金三银四跳槽季找到一份好工作,但千万也记住,技术一定是平时工作种累计或者自学(或报班跟着老师学)通过实战累计的,千万不要临时抱佛脚。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
考参考,如果还不够,那下面这些简历模板任你挑选:
[外链图片转存中…(img-3FIsJKs6-1628093358749)]
以上分享,希望大家可以在金三银四跳槽季找到一份好工作,但千万也记住,技术一定是平时工作种累计或者自学(或报班跟着老师学)通过实战累计的,千万不要临时抱佛脚。
另外,面试中遇到不会的问题不妨尝试讲讲自己的思路,因为有些问题不是考察我们的编程能力,而是逻辑思维表达能力;最后平时要进行自我分析与评价,做好职业规划,不断摸索,提高自己的编程能力和抽象思维能力。
以上文章中,提及到的所有的笔记内容、面试题等资料,均可以免费分享给大家学习,有需要的话就戳这里打包带走吧。















 1234
1234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









