







文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
(二)OpenCV结合其他 OCR 引擎或库来实现完整的文字识别功能
在实际应用中,可以根据项目需求选择合适的 OCR 引擎,并结合 OpenCV 进行图像处理和文字区域检测,以实现准确的文字识别功能。
下面补充一些关于OpenCV文字识别与OCR的信息:
- Tesseract OCR:Tesseract 是一个开源的 OCR 引擎,由 Google 开发和维护。它支持多种语言,并且具有较高的文字识别准确性。你可以使用 Tesseract OCR 库来配合 OpenCV 进行文字识别。
- OCRopus:OCRopus 是基于 Tesseract 的 OCR 引擎,提供了更多的自定义和扩展性。它允许你根据特定需求进行训练和优化,以提高文字识别的效果。
- Google Cloud Vision API:Google Cloud Vision 是一种云端 OCR 服务,提供了强大的文字识别功能。它可以处理多种图像类型,包括扫描文档、照片、屏幕截图等,并提供了准确的文字识别结果。
- 图像预处理技术:在文字识别之前,通常需要对图像进行预处理来提高识别准确性。常见的预处理技术包括灰度化、二值化、去噪、图像增强等。OpenCV 提供了丰富的图像处理函数和算法,可以用于这些预处理步骤。
- 文字区域检测技术:在文字识别过程中,需要确定图像中的文字区域。常用的文字区域检测技术包括边缘检测、轮廓检测、连通组件分析等。OpenCV 提供了这些功能的实现方法,可以帮助你找到图像中的文字区域。
总之,OpenCV 是一个强大的计算机视觉库,可以与 OCR 引擎结合使用,实现图像中的文字识别。通过合理选择 OCR 引擎,并结合适当的图像预处理和文字区域检测技术,可以获得准确和高效的文字识别结果。
二、图像预处理示例代码
 以下是使用 OpenCV 进行图像预处理的示例代码,包括灰度化、二值化和滤波:
以下是使用 OpenCV 进行图像预处理的示例代码,包括灰度化、二值化和滤波:
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
P = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 中值滤波
filtered = cv2.medianBlur(binary, 3)
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Grayscale Image', gray)
cv2.imshow('Binary Image', binary)
cv2.imshow('Filtered Image', filtered)
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述示例中,首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.threshold() 函数对灰度图像进行二值化处理。通过设定阈值和使用 OTSU 自适应阈值算法,将灰度图像转换为二值图像,将结果存储在 binary 变量中。
最后,使用 cv2.medianBlur() 函数对二值图像进行中值滤波,以去除噪声。将滤波后的图像存储在 filtered 变量中。
最后,使用 cv2.imshow() 函数显示原始图像、灰度图像、二值图像和滤波后的图像。使用 cv2.waitKey() 函数等待键盘输入,最后使用 cv2.destroyAllWindows() 函数关闭窗口。
这些预处理步骤可以根据需要进行调整和组合,以提高文字识别的准确性和质量。请根据实际情况选择适合的预处理方法。
三、文字区域检测示例代码
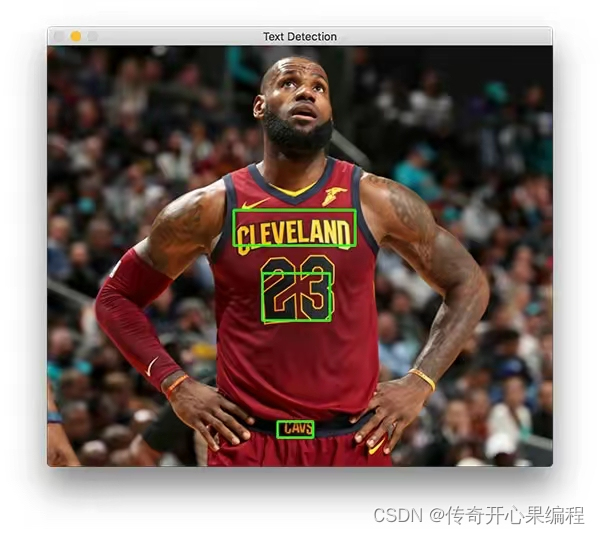 以下是使用 OpenCV 进行文字区域检测的示例代码,包括边缘检测和轮廓检测:
以下是使用 OpenCV 进行文字区域检测的示例代码,包括边缘检测和轮廓检测:
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 边缘检测
edges = cv2.Canny(gray, 50, 150)
# 轮廓检测
contours, _ = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制矩形框
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
在上述示例中,首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.Canny() 函数进行边缘检测,将结果存储在 edges 变量中。在这个示例中,我们使用 Canny 边缘检测算法,设定阈值为 50 和 150。
最后,使用 cv2.findContours() 函数对边缘图像进行轮廓检测,将轮廓结果存储在 contours 变量中。我们使用 cv2.RETR_EXTERNAL 参数表示只检测外部轮廓,并使用 cv2.CHAIN_APPROX_SIMPLE 参数表示使用简化的轮廓表示。
接下来,使用 cv2.rectangle() 函数在原始图像上绘制矩形框,标识出文字区域。通过 cv2.boundingRect() 函数获取每个轮廓的边界框坐标,然后使用 cv2.rectangle() 函数绘制矩形框。
最后,使用 cv2.imshow() 函数显示原始图像和边缘图像。使用 cv2.waitKey() 函数等待键盘输入,最后使用 cv2.destroyAllWindows() 函数关闭窗口。
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行参数调整和算法优化,以达到更好的文字区域检测效果。
四、文字识别示例代码
 以下是使用 OpenCV 进行文字识别的示例代码,结合 Tesseract OCR 引擎进行光学字符识别:
以下是使用 OpenCV 进行文字识别的示例代码,结合 Tesseract OCR 引擎进行光学字符识别:
import cv2
import pytesseract
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 使用 Tesseract 进行文字识别
result = pytesseract.image_to_string(binary, lang='eng')
# 打印识别结果
print(result)
在上述示例中,首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.threshold() 函数对灰度图像进行二值化处理,将结果存储在 binary 变量中。在这个示例中,我们使用了 OTSU 自适应阈值算法。
最后,使用 pytesseract.image_to_string() 函数将二值图像传递给 Tesseract OCR 引擎进行文字识别。通过指定 lang 参数来选择使用的语言,这里使用了英文 'eng'。
识别结果会存储在 result 变量中,你可以根据需要进行后续处理或打印输出。
请注意,这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行图像预处理、文字区域检测等步骤,以达到更好的文字识别效果。此外,你也可以选择其他 OCR 引擎或库来替代 Tesseract,如 OCRopus 或 Google Cloud Vision,使用方法类似。
五、文字后处理示例代码
 文字后处理是在文字识别完成后对识别结果进行进一步处理的步骤,常见的后处理操作包括去除噪声、校正错误和整理格式。以下是一个简单的示例代码,展示了如何使用 Python 进行文字后处理:
文字后处理是在文字识别完成后对识别结果进行进一步处理的步骤,常见的后处理操作包括去除噪声、校正错误和整理格式。以下是一个简单的示例代码,展示了如何使用 Python 进行文字后处理:
import re
def postprocess\_text(text):
# 去除非字母和数字的字符
text = re.sub(r'[^a-zA-Z0-9]', '', text)
# 校正错误
# ...
# 整理格式
# ...
return text
# 假设识别结果存储在 result 变量中
result = "H3llo, W0r1d!"
# 进行文字后处理
processed_text = postprocess_text(result)
# 打印处理后的结果
print(processed_text)
在上述示例中,我们定义了一个 postprocess_text() 函数来执行文字后处理操作。这个函数使用正则表达式 re.sub() 来去除非字母和数字的字符,只保留字母和数字。你可以根据实际需求定制自己的规则来去除其他特定字符。
除了去除噪声外,文字后处理还可以用于校正识别错误和整理识别结果的格式。校正错误的方法可以根据实际情况选择,例如使用拼写纠正算法或者通过与词典进行比对来进行修正。整理格式的方法也可以根据需求进行定制,例如添加分隔符、调整字母大小写等。
在示例代码中,我们假设识别结果存储在 result 变量中,然后将其传递给 postprocess_text() 函数进行后处理。处理后的结果存储在 processed_text 变量中,并打印输出。
请注意,这只是一个简单的示例代码,实际的文字后处理操作可能会更加复杂,需要根据具体需求进行定制。你可以根据实际情况来编写适合你的后处理函数,以提高文字识别结果的准确性和质量。
六、OpenCV结合Tesseract OCR库实现文字识别示例代码
 以下是一个示例代码,展示了如何结合 OpenCV 和 Tesseract OCR 进行文字识别:
以下是一个示例代码,展示了如何结合 OpenCV 和 Tesseract OCR 进行文字识别:
import cv2
import pytesseract
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 使用 Tesseract 进行文字识别
result = pytesseract.image_to_string(binary, lang='eng')
# 打印识别结果
print(result)
在上述示例中,我们首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.threshold() 函数对灰度图像进行二值化处理,将结果存储在 binary 变量中。在这个示例中,我们使用了 OTSU 自适应阈值算法。
最后,使用 pytesseract.image_to_string() 函数将二值图像传递给 Tesseract OCR 引擎进行文字识别。通过指定 lang 参数来选择使用的语言,这里使用了英文 'eng'。
识别结果会存储在 result 变量中,你可以根据需要进行后续处理或打印输出。
请注意,运行此代码之前,你需要先安装并配置好 OpenCV 和 Tesseract OCR。你可以通过 pip install opencv-python 和 pip install pytesseract 命令来安装相应的库。同时,确保已经下载并安装了 Tesseract OCR 的语言数据包,以支持相应语言的识别。
这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行图像预处理、文字区域检测等步骤,以达到更好的文字识别效果。你还可以通过调整 Tesseract OCR 的参数来优化识别结果,例如设置字典、调整识别方式等。
七、OpenCV结合OCRopus库文字识别示例代码
 OCRopus 是一个基于 Tesseract 的 OCR 引擎,它提供了更多的自定义和扩展性,允许你根据特定需求进行训练和优化,以提高文字识别的效果。下面是一个使用 OpenCV 结合 OCRopus 进行文字识别的示例代码:
OCRopus 是一个基于 Tesseract 的 OCR 引擎,它提供了更多的自定义和扩展性,允许你根据特定需求进行训练和优化,以提高文字识别的效果。下面是一个使用 OpenCV 结合 OCRopus 进行文字识别的示例代码:
import cv2
from ocropy import ocrolib
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 二值化
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# 保存图像到临时文件
cv2.imwrite('temp.png', binary)
# 使用 OCRopus 进行文字识别
ocrolib.iopen('temp.png').binarize().write_page('temp.ocropus')
ocrolib.tesseract_page('temp.ocropus').write_text()
# 读取识别结果
with open('temp.txt', 'r', encoding='utf-8') as file:
result = file.read()
# 打印识别结果
print(result)
在上述示例中,我们首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
接下来,使用 cv2.cvtColor() 函数将彩色图像转换为灰度图像,将结果存储在 gray 变量中。
然后,使用 cv2.threshold() 函数对灰度图像进行二值化处理,将结果存储在 binary 变量中。在这个示例中,我们使用了 OTSU 自适应阈值算法。
接下来,我们将二值图像保存到临时文件 temp.png 中,以便 OCRopus 进行处理。
然后,使用 OCRopus 的 ocrolib 模块来进行文字识别。我们首先使用 ocrolib.iopen() 函数打开二值图像文件,然后使用 .binarize() 方法对图像进行二值化处理,并将处理结果保存为 OCRopus 的页面格式 temp.ocropus。
接着,使用 ocrolib.tesseract_page() 函数对页面进行 OCR 识别,并将识别结果保存为文本文件 temp.txt。
最后,我们读取文本文件中的识别结果,并将其存储在 result 变量中。你可以根据需要进行后续处理或打印输出。
请注意,在运行此代码之前,你需要先安装并配置好 OCRopus 和 Tesseract OCR。你可以通过 pip install ocropy 命令来安装 OCRopus。同时,确保已经下载并安装了 Tesseract OCR 的语言数据包,以支持相应语言的识别。
这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行图像预处理、文字区域检测等步骤,以达到更好的文字识别效果。你还可以根据需要调整 OCRopus 的参数和配置文件,以优化识别结果。
八、OpenCV 结合Google Cloud Vision API 文字识别示例代码
要结合 OpenCV 和 Google Cloud Vision API 进行文字识别,你需要先设置好 Google Cloud 平台的相关服务,并安装 google-cloud-vision 库。下面是一个示例代码,展示了如何使用 OpenCV 结合 Google Cloud Vision API 进行文字识别:
import cv2
from google.cloud import vision
# 读取图像
image = cv2.imread('image.jpg')
# 将图像转换为字节流
_, img_encoded = cv2.imencode('.jpg', image)
img_bytes = img_encoded.tobytes()
# 使用 Google Cloud Vision API 进行文字识别
client = vision.ImageAnnotatorClient()
image = vision.Image(content=img_bytes)
response = client.text_detection(image=image)
texts = response.text_annotations
# 打印识别结果
for text in texts:
print(text.description)
在上述示例中,我们首先使用 cv2.imread() 函数读取图像文件,将图像存储在 image 变量中。
然后,我们使用 cv2.imencode() 函数将图像编码为 JPG 格式的字节流,然后将其转换为字节字符串 img_bytes。
接下来,我们使用 google-cloud-vision 库中的 ImageAnnotatorClient 类创建一个 Cloud Vision API 的客户端。
然后,我们将图像字节字符串传递给 vision.Image 类创建一个图像对象 image。
接着,我们使用 client.text_detection() 方法对图像进行文字识别,返回一个包含文字信息的响应对象 response。
最后,我们从响应对象中提取出识别结果 texts,并遍历打印每个文字块的内容。
请注意,在运行此代码之前,你需要先在 Google Cloud 平台上创建一个项目,并启用 Vision API 服务。然后,你需要安装 google-cloud-vision 库,并配置好你的身份验证凭据。
此外,你还可以根据需要,使用 Cloud Vision API 的其他功能,如检测文字语言、识别文本坐标等。具体的 API 使用方法和参数设置可以参考 Google Cloud Vision API 的官方文档。
这只是一个简单的示例代码,实际应用中可能需要根据具体情况进行图像预处理、文字区域检测等步骤,以达到更好的文字识别效果。同时,你需要根据你的实际需求和云平台的限制,选择适合的服务套餐和配置。
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 4637
4637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









