







目录
一、准备深度学习环境
下载yolov7代码
二、 准备自己的数据集
一般标注的数据格式是VOC,而YOLOv7能够直接使用的是YOLO格式的数据,因此下面将介绍如何将自己的数据集转换成可以直接让YOLOv7进行使用。(数据集已经是yolo格式的直接跳过)
1.因为现在使用车牌检测使用的是yolo格式直接讲yolo格式
首先把dataset_DY的车牌数据集放在yolov7的主目录下
2.在主目录下打开终端激活进入你自己创建的虚拟环境里面,确定你配置的训练环境没有问题之后,使用安装命令:
pip3 install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple 没有报错即安装完成
3.在主目录下新建一个split.py文件,里面内容如下:
import shutil
import random
import os
# 原始路径
image_original_path = r"/home/sxj/yolov7-7/dataset_DY/Images/train"
label_original_path = r"/home/sxj/yolov7-7/dataset_DY/labels/train"
cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "datasets/images/train/")
train_label_path = os.path.join(cur_path, "datasets/labels/train/")
print("----------")
# 验证集路径
val_image_path = os.path.join(cur_path, "datasets/images/val/")
val_label_path = os.path.join(cur_path, "datasets/labels/val/")
print("----------")
# 测试集路径
test_image_path = os.path.join(cur_path, "datasets/images/test/")
test_label_path = os.path.join(cur_path, "datasets/labels/test/")
print("----------")
# 训练集目录
list_train = os.path.join(cur_path, "datasets/train.txt")
list_val = os.path.join(cur_path, "datasets/val.txt")
list_test = os.path.join(cur_path, "datasets/test.txt")
print("----------")
train_percent = 0.8
val_percent = 0.1
test_percent = 0.1
print("----------")
def del_file(path):
for i in os.listdir(path):
file_data = path + "/" + i
os.remove(file_data)
def mkdir():
if not os.path.exists(train_image_path):
os.makedirs(train_image_path)
else:
del_file(train_image_path)
if not os.path.exists(train_label_path):
os.makedirs(train_label_path)
else:
del_file(train_label_path)
if not os.path.exists(val_image_path):
os.makedirs(val_image_path)
else:
del_file(val_image_path)
if not os.path.exists(val_label_path):
os.makedirs(val_label_path)
else:
del_file(val_label_path)
if not os.path.exists(test_image_path):
os.makedirs(test_image_path)
else:
del_file(test_image_path)
if not os.path.exists(test_label_path):
os.makedirs(test_label_path)
else:
del_file(test_label_path)
def clearfile():
if os.path.exists(list_train):
os.remove(list_train)
if os.path.exists(list_val):
os.remove(list_val)
if os.path.exists(list_test):
os.remove(list_test)
def main():
mkdir()
clearfile()
file_train = open(list_train, 'w')
file_val = open(list_val, 'w')
file_test = open(list_test, 'w')
total_txt = os.listdir(label_original_path)
num_txt = len(total_txt)
list_all_txt = range(num_txt)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# train从list_all_txt取出num_train个元素
# 所以list_all_txt列表只剩下了这些元素
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = image_original_path + '/' + name + '.jpg'
srcLabel = label_original_path + '/' + name + ".txt"
if i in train:
dst_train_Image = train_image_path + name + '.jpg'
dst_train_Label = train_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
file_train.write(dst_train_Image + '\n')
elif i in val:
dst_val_Image = val_image_path + name + '.jpg'
dst_val_Label = val_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
file_val.write(dst_val_Image + '\n')
else:
dst_test_Image = test_image_path + name + '.jpg'
dst_test_Label = test_label_path + name + '.txt'
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
file_test.write(dst_test_Image + '\n')
file_train.close()
file_val.close()
file_test.close()
if __name__ == "__main__":
main()4.新建datasets文件夹,里面放置好images和labels文件夹
接着根据split.py文件修改配置文件,路径没有问题运行该split.py文件会在datasets文件夹下生成test.txt、train.txt、val.txt文件
5.接着新建一个Car.yaml文件里面和coco文件类似,需要修改里面配置文件路径如下:
需要根据你自己路径修改
# COCO 2017 dataset http://cocodataset.org
# download command/URL (optional)
# download: bash ./scripts/get_coco.sh
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /home/sxj/yolov7-7/datasets/train.txt # 118287 images
val: /home/sxj/yolov7-7/datasets/val.txt # 5000 images
test: /home/sxj/yolov7-7/datasets/test.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 1
# class names
names: ['Car']同样修改cfg/training下yolov7.yaml文件(改成自己的识别类别数)
三、模型训练
1、下载预训练模型
在YOLOv7的GitHub开源网址上下载对应版本的模型
新建一个weights文件夹把yolov7.pt文件放进去
2、训练
在正式开始训练之前,需要对train.py进行以下修改:
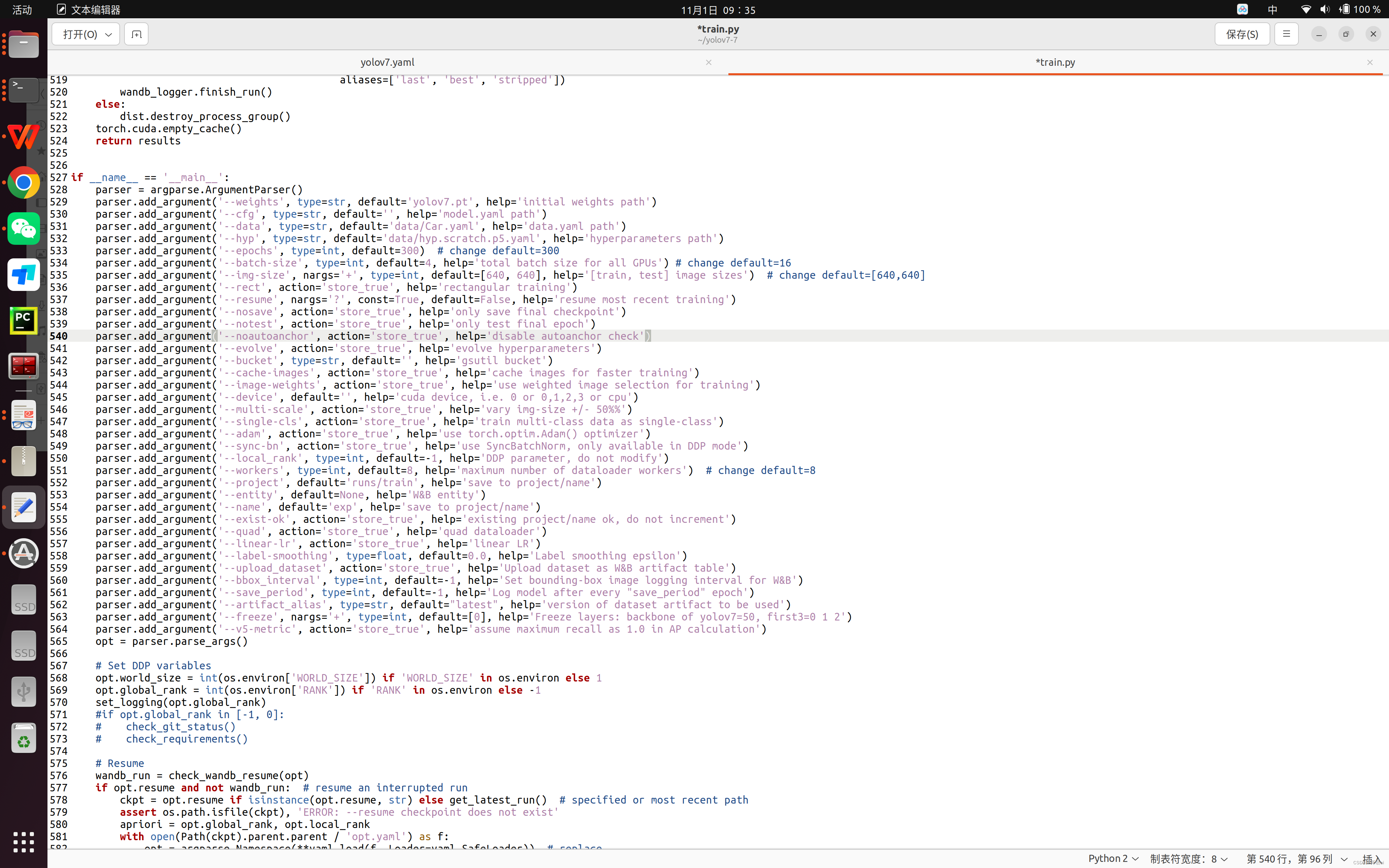
以上参数解释如下:
epochs:指的就是训练过程中整个数据集将被迭代多少次,显卡不行你就调小点。
batch-size:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点。
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
img-size:输入图片宽高,显卡不行你就调小点。
之后运行训练命令如下:
python train.py --weights weights/yolov7.pt --cfg cfg/training/yolov7-Car.yaml --data data/Car.yaml --device 0 --batch-size 1 --epoch 100
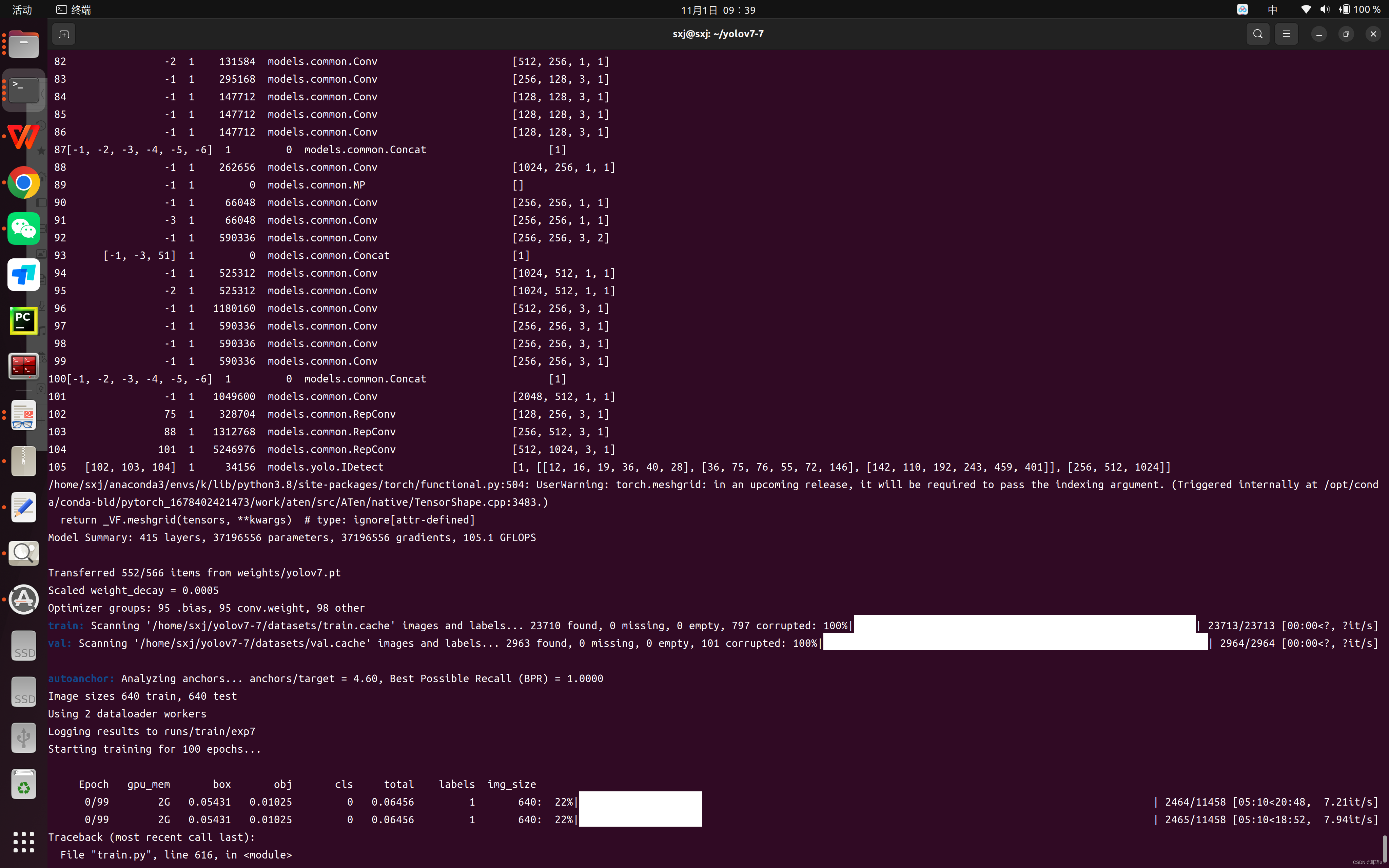
运行成功之后显示如下(训练完成在runs/train文件夹下可以查看权重文件和模型评估)
四、模型测试
评估模型好坏就是在有标注的测试集或者验证集上进行模型效果的评估,在目标检测中最常使用的评估指标为mAP。在test.py文件中指定数据集配置文件和训练结果模型,如下:
其中best.pt是训练好的权重路径,需要改成自己权重文件路径
python detect.py --weights /home/sxj/yolov7-7.2/runs/train/exp46/weights/best.pt --source datasets/images/test五、裁剪图像
主要内容为:在识别出来目标照片后,对目标进行裁剪
1.准备照片与标签
标签的生成在执行代码中加入–save-txt,完整命令如下:
python detect.py --weights /home/sxj/yolov7-7.2/runs/train/exp22/weights/best.pt --source datasets/images/test --save-txt 上面的文件路径根据实际情况修改即可
执行后,会生成一个labels文件,里面是yolo格式的标签,将labels与图片放到同一个文件夹

2.代码
根据实际情况,修改文件路径即可。w、h的值,根据需要可自行调整
# -*- coding: utf-8 -*-
# @Author : 耳语ai
# @Function:图片裁剪
import os
import cv2
import shutil
def caijian():
# 仅支持JPEG,PNG,JPG格式图片
path = "/home/sxj/yolov7-7.2/exp2/labels" # jpg图片和对应的生成结果的txt标注文件,放在一起
path3 = "/home/sxj/yolov7-7.2/exp2/cut/roi" # 裁剪出来的小图保存的根目录
path6 = "/home/sxj/yolov7-7.2/exp2/cut" # 裁剪出来的小图保存的根目录
w = 4000 # 原始图片resize
h = 4000
img_total = []
txt_total = []
file = os.listdir(path)
for filename in file:
first, last = os.path.splitext(filename)
# if (last in [".jpg",".jpeg","png"] ): # 图片的后缀名
# img_total.append(first)
# # print(img_total)
# else:
# txt_total.append(first)
if (last in [".txt"]): # 图片的后缀名
txt_total.append(first)
# print(img_total)
else:
img_total.append(first)
if os.path.exists(path3):
shutil.rmtree(path3)
os.mkdir(path3)
else:
os.mkdir(path3)
for img_ in img_total:
if img_ in txt_total:
filename_img = img_ + ".jpg" # 图片的后缀名
# print('filename_img:', filename_img)
path1 = os.path.join(path, filename_img)
a = os.path.exists(path1)
if (a == False):
filename_img = img_ + ".jpeg" # 图片的后缀名
# print('filename_img:', filename_img)
path1 = os.path.join(path, filename_img)
a = os.path.exists(path1)
if (a == False):
filename_img = img_ + ".png" # 图片的后缀名
# print('filename_img:', filename_img)
path1 = os.path.join(path, filename_img)
a = os.path.exists(path1)
print("文件是否存在{}".format(a))
img = cv2.imread(path1)
img = cv2.resize(img, (w, h), interpolation=cv2.INTER_CUBIC) # resize 图像大小,否则提取先验框时因原图差异区域可能会报错
filename_txt = img_ + ".txt"
# print('filename_txt:', filename_txt)
n = 1
with open(os.path.join(path, filename_txt), "r+", encoding="utf-8", errors="ignore") as f:
for line in f:
aa = line.split(" ")
x_center = w * float(aa[1]) # aa[1]左上点的x坐标
y_center = h * float(aa[2]) # aa[2]左上点的y坐标
width = int(w * float(aa[3])) # aa[3]图片width
height = int(h * float(aa[4])) # aa[4]图片height
lefttopx = int(x_center - width / 2.0)
lefttopy = int(y_center - height / 2.0)
roi = img[lefttopy + 1:lefttopy + height + 3,
lefttopx + 1:lefttopx + width + 1] # [左上y:右下y,左上x:右下x] (y1:y2,x1:x2)需要调参,否则裁剪出来的小图可能不太好
print('roi:', roi)
filename_last = img_ + "_" + str(n) + ".jpg" # 裁剪出来的小图文件名
# print(filename_last)
path2 = os.path.join(path6, "roi") # 需要在path3路径下创建一个roi文件夹
print('path2:', path2) # 裁剪小图的保存位置
cv2.imwrite(os.path.join(path2, filename_last), roi)
n = n + 1
else:
continue
if __name__ == '__main__':
caijian()
运行该代码会图像会出现在你保存的目录下
















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









