







1 什么是TensorRT
一般的深度学习项目,训练时为了加快速度,会使用多 GPU 分布式训练。但在部署推理时,为了降低成本,往往使用单个 GPU 机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如 caffe,TensorFlow 等。由于训练的网络模型可能会很大(比如,inception,resnet 等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。所以为了提高部署推理的速度,出现了很多轻量级神经网络,比如 squeezenet,mobilenet,shufflenet 等。基本做法都是基于现有的经典模型提出一种新的模型结构,然后用这些改造过的模型重新训练,再重新部署。
而 TensorRT 则是对训练好的模型进行优化。 TensorRT 就只是推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进 TensorRT中,而不再需要依赖深度学习框架(Caffe、TensorFlow 等)
2 TensorRT安装
TensorRT 的安装方式很简单,只需要注意一些环境的依赖关系就可以,我们以 TensorRT 8.6.1.6 版本为例,参考官网安装教程,这里简单总结一下步骤
2.1 环境确认
确认 CUDA 版本是多少本次CUDA版本是11.8,可通过运行 nvcc -V 指令来查看 CUDA,如果不是 9.0 以上,则需要先把 CUDA 版本更新一下
cudnn 版本是要和CUDA对应,如果不满足要求,按照《Linux之cudnn升级方法》进行升级
需安装有 TensorFlow,uff模块需要。
2.2 下载安装包
进入下载链接
点击下载TensorRT(需要登录英伟达账号,没有的注册一个)
选择下载的版本
选择同意协议
根据自己的系统版本和 CUDA 版本,选择安装包,如图所示(如果是完整安装,建议选择Tar File Install Packages,这样可以自行选择安装位置)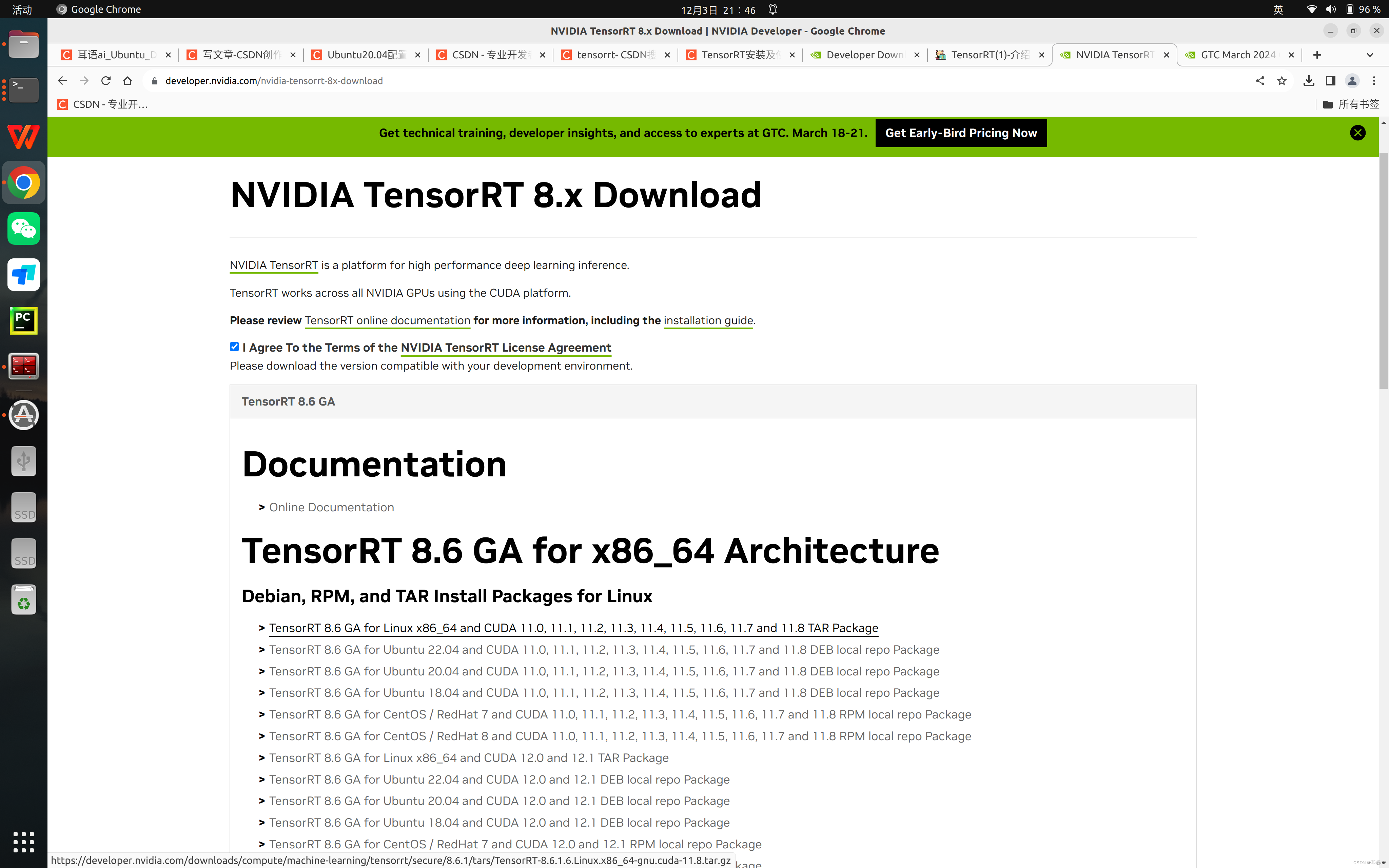
2.3 安装指令
安装时只需要把压缩文件解压,相应的库文件拷贝到系统路径下即可
#在home下新建文件夹,命名为tensorrt_tar,然后将下载的压缩文件拷贝进来解压
tar xzvf TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-11.8.tar.gz#解压得到TensorRT-8.6.1.6的文件夹,将里边的lib绝对路径添加到环境变量中
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/sxj/xiazai/TensorRT-8.6.1.6/lib
# 重新加载环境变量
source ~/.bashrc为了避免其它软件找不到 TensorRT 的库,建议把 TensorRT 的库和头文件添加到系统路径下
# TensorRT路径下
sudo cp -r ./lib/* /usr/lib
sudo cp -r ./include/* /usr/include要使用 python 版本,则使用 pip 安装,执行下边的指令
# 安装TensorRT
cd TensorRT-8.6.1.6/python
pip install tensorrt-8.6.1-cp38-none-linux_x86_64.whl
# 安装UFF,支持tensorflow模型转化
cd TensorRT-8.6.1.6/uff
pip install uff-0.6.9-py2.py3-none-any.whl
# 安装graphsurgeon,支持自定义结构
cd TensorRT-8.6.1.6/graphsurgeon
pip install graphsurgeon-0.4.6-py2.py3-none-any.whl
2.4安装完之后运行下边指令验证安装
python
import tensorrt
tensorrt.__version__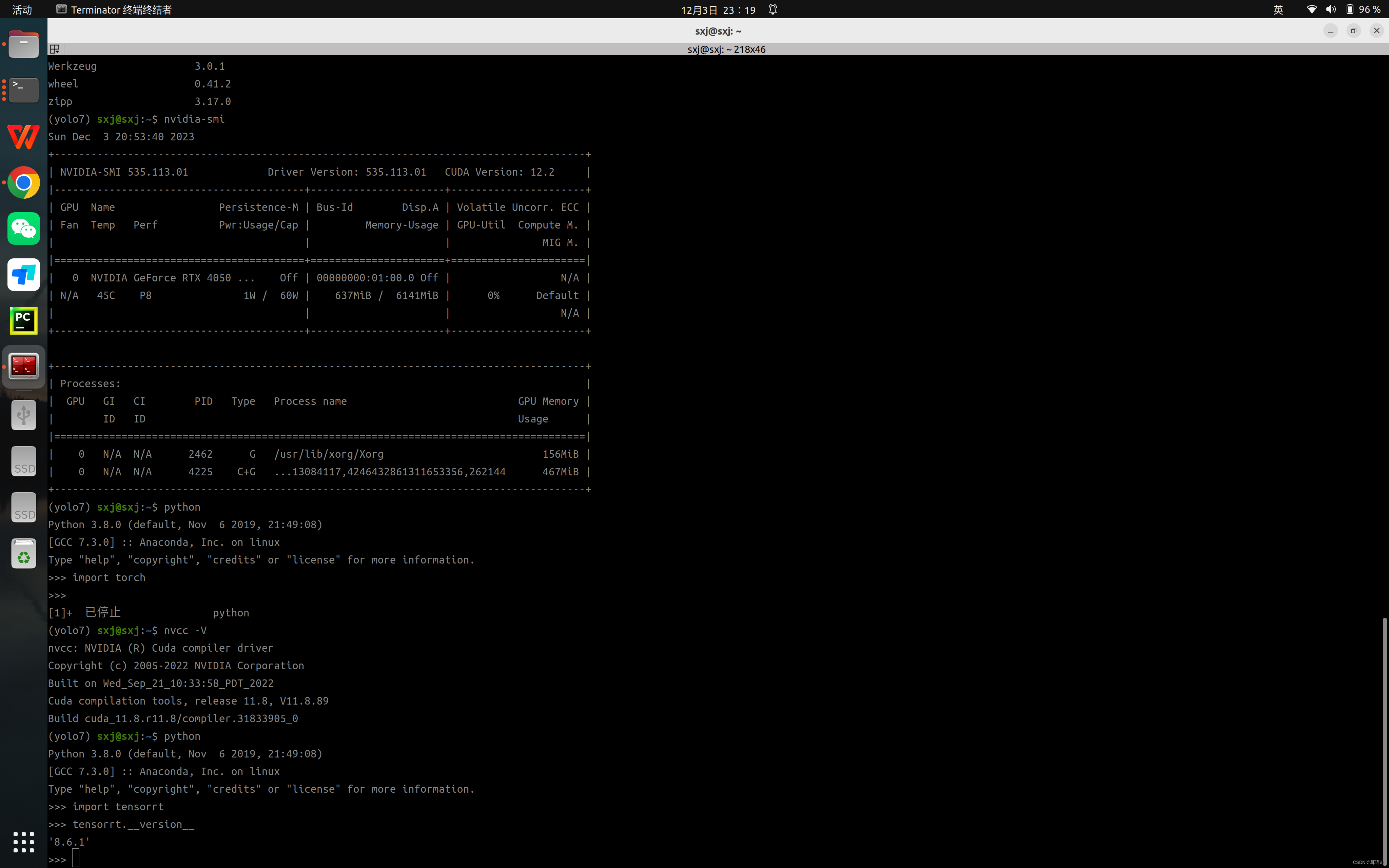
例程测试:
cd samples/sampleOnnxMNIST/
make -j8
cd ../../bin
bin ./sample_onnx_mnist+++++++++++++++++++++++++++++++++++++++++++++++++++++
3. PyTorch模型转ONNX模型
TensorRT 概述
TensorRT 是由 Nvidia 发布的一个机器学习框架,用于在其硬件上运行机器学习推理。其能针对 Nvidia 系列硬件进行优化加速,实现最大程度的利用 GPU 资源,提升推理性能。在训练了神经网络之后,TensorRT 可以对网络进行压缩、优化以及运行时部署,并且没有框架的开销。
TensorRT 部署流程主要有以下五步:
- 训练模型
- 导出模型为 ONNX 格式
- 选择精度
- 转化成 TensorRT 模型
- 部署模型
主要难度在第二步、第四步和第五步。其中 ONNX 格式的导出和运行设备无关,可以在自己的电脑上导出,其他设备上使用。而第四步转化得到的 TensorRT 模型文件是和设备绑定的,在哪个设备上生成就只能在该设备使用。
一般来说,模型训练和导出 ONNX 都在服务器上进行,得到 ONNX 模型。TensorRT 模型转化和部署都是在实际设备上进行。这样的话实际设备不需要 PyTroch 环境,只需要配置好 TensorRT 环境即可。
首先通过命令使用你自己生成的权重文件best.pt通过以下命令生成ONNX文件。--weights 可以指定模型文件路径,--simplify进行ONNX模型简化,--grid使输出为一个tensor,--img-size为输入图片尺寸,--batch-size设置batch size的大小
YOLOv7 源码修改
首先下载 yolov7 最新的源码
下载好为了成功导出 yolov7 ONNX 模型,需要根据上述的注意事项修改 YOLOv7 的源码。
需要注意的是:下述的代码修改仅为了导出 ONNX 模型用于 TensorRT 部署,训练网络或者跑 detect.py 运行 demo 的时候需要改回来,否则会出错。
此外,YOLOv7 默认输出为三个不同尺度的张量,分别为不同层特征金字塔的检测结果,该输出需要结合锚框信息才能转化为预测框。(在此没有作修改直接跳过这个步骤)
YOLOv7 导出 ONNX 模型
Pytorch 导出 ONNX 文件注意事项
由于 ONNX 对很多 Pytorch 的操作的支持不好,若直接导出很容易失败。
即使成功导出,也会增加模型的复杂度 (可能会产生很多 Gather, Shape, ScatterND 等节点,使模型复杂,可视效果差),产生很多后续问题如 ONNX 模型转成 TensorRT 模型失败。
Pytorch 模型导出 ONNX 模型时需要注意以下几点:
- 对于任何用到
shape、size返回值的参数时,例如:tensor.view(tensor.size(0), -1)这类操作,避免直接使用tensor.size的返回值,而是加上int转换,如tensor.view(int(tensor.size(0)), -1) - 对于
nn.Upsample或nn.functional.interpolate函数,使用scale_factor指定倍率,而不是使用size参数指定大小 - 对于
reshape、view操作时,-1 的指定要放到batch维度。其他维度可以计算出来即可。batch维度禁止指定为大于-1 的明确数字。 - 导出时
opset_version不要低于 11
导出 ONNX 模型
到 yolov7 源文件根目录下,运行
python export.py --grid --weight ./best.pt --dynamic --img-size 640 480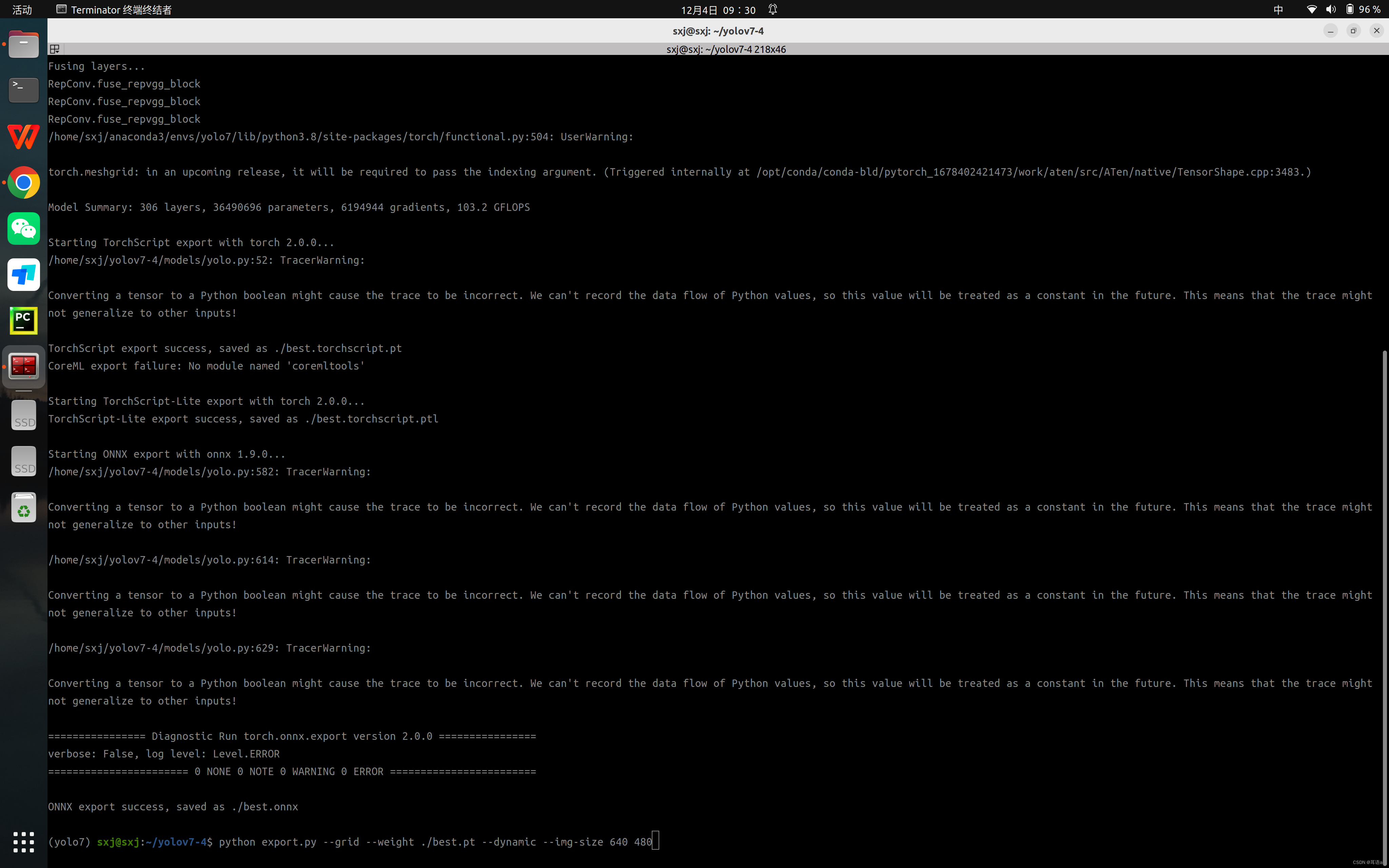
由于我们之后输入图像尺寸固定为640×480大小,直接指定模型输入大小与其一致可以减少后续推理时图像预处理和计算结果的后处理部分,节省算力。
若导出成功,终端会有 ONNX export success 的提示,如上图。其中会有一些 warning,无需理会即可。导出成功,得到 yolov7-tiny-ft-best.onnx文件。
得到 onnx 模型之后,可以使用模型可视化工具 https://netron.app/ 进行可视化,如下:
或者
2)下载本地版
终端进行安装:
pip install netron
安装完成后,在脚本中 调用包
python
import netron
运行程序
netron.start('best.onnx')会自动打开浏览器进行可视化
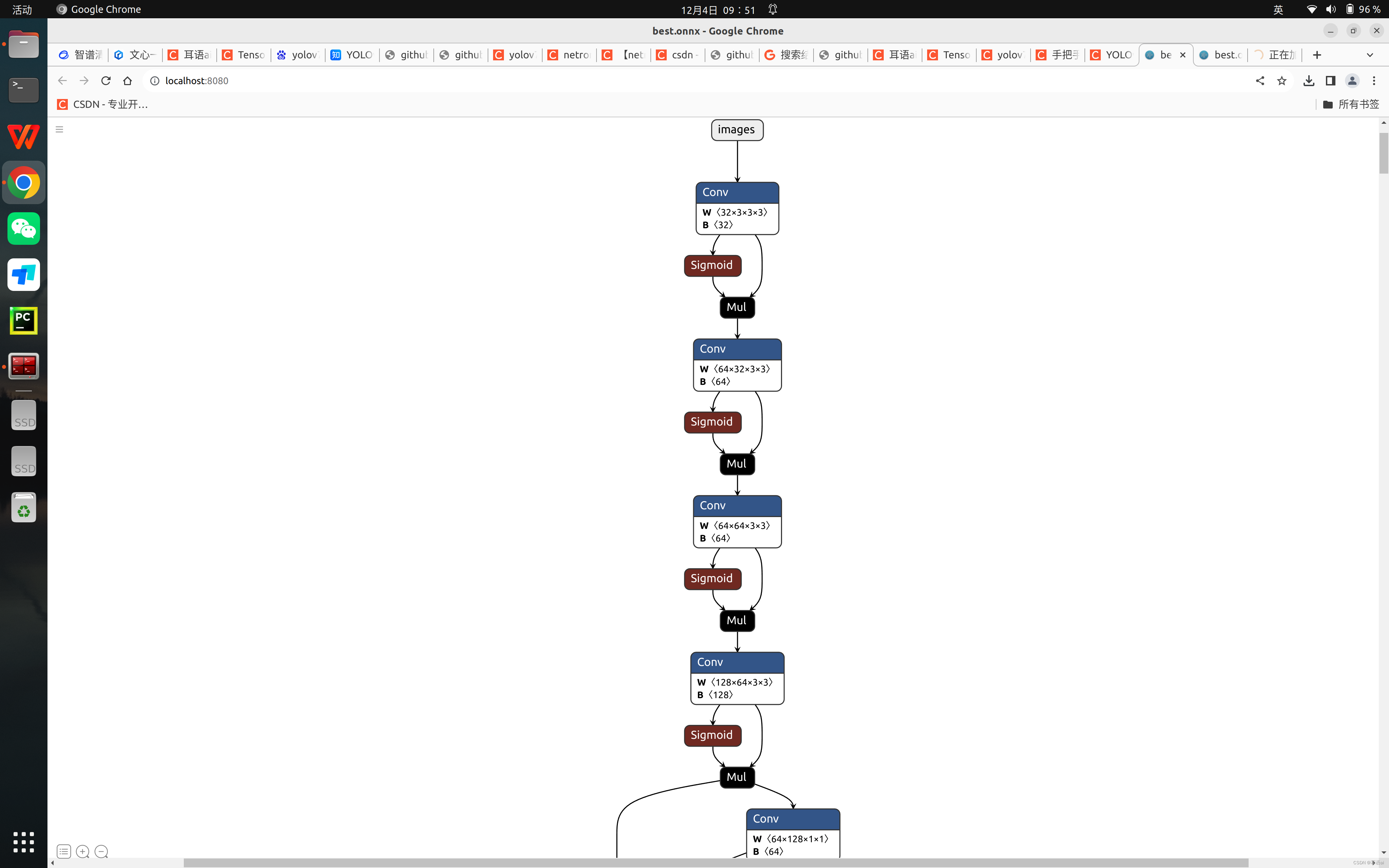

模型导出的 ONNX 文件是通用的,所以可以在任意设备上进行导出,在其他设备上使用。
TensorRT 模型推理(C++)
git clone https://github.com/shouxieai/tensorRT_Pro.gitTensorRT C++ 模型推理我用了上述的 Github 仓库。该仓库也包含了 TensorRT Python 模型推理的源码。 对于 YOLO C++ 部署只需要下载文件夹 tensorRT_Pro/example-simple_yolo/即可。
该开源项目有以下优点
- 依赖少:仅依赖官方的 TensorRT 和 OpenCV
- 文件少:只有 simple_yolo.hpp 和 simple_yolo.cu 两个文件
- 使用方便:包含了ONNX 模型转 TRT 引擎,图像输入的预处理和后处理,集成了 NMS 非极大抑制算法,且封装简单,易于使用。
该仓库非常简单易用,根据其 ReadMe 文件操作即可。
实际使用,只需要修改下src/main文件主函数的参数

test函数最后一个参数为 ONNX 模型的文件名,- 比如
yolov7.onnx就输入yolov7即可 - 该 ONNX 模型文件需要放到可执行文件同目录下。
- 比如
- 第二个参数为指定模型的运算精度
- 可以为
SimpleYolo::Mode::FP32或者SimpleYolo::Mode::FP16。 - 更低的运算精度部署后速度更快。
- 可以为
再修改下CMakeLists.txt文件,主要需要修改下面几个参数,对于 CUDA_GEN_CODE 参数,Jetson NX 和 Jetson AGX 都为"-gencode=arch=compute_72,code=sm_72"。
# 如果你是不同显卡,请设置为显卡对应的号码参考这里:https://developer.nvidia.com/zh-cn/cuda-gpus#compute
set(CUDA_GEN_CODE "-gencode=arch=compute_72,code=sm_72")
# 如果你的opencv找不到,可以自己指定目录
set(OpenCV_DIR "/usr/include/opencv4/")
set(CUDA_DIR "/usr/local/cuda-10.2")然后编译运行即可:
mkdir build
cd build
cmake ..
make -j8
cd ../workspace
./pro(参考文章 YOLOv7 部署到 TensorRT(C++ ))















 1730
1730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









