







学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
load_time:将先前转储的数据帧加载到内存所需的时间save_ram_delta_mb:在数据帧保存过程中最大的内存消耗增长load_ram_delta_mb:数据帧加载过程中最大的内存消耗增长
注意,当我们使用有效压缩的二进制数据格式(例如Parquet)时,最后两个指标变得非常重要。它们可以帮助我们估算加载串行化数据所需的RAM数量,以及数据大小本身。我们将在下一部分中更详细地讨论这个问题。
对比
现在开始对前文介绍的5种数据格式进行比较,为了更好地控制序列化的数据结构和属性我们将使用自己生成的数据集。
下面是生成测试数据的代码,我们随机生成具有数字和分类特征的数据集。数值特征取自标准正态分布。分类特征以基数为C的uuid4随机字符串生成,其中2 <= C <= max_cat_size。
def generate_dataset(n_rows, num_count, cat_count, max_nan=0.1, max_cat_size=100): dataset, types = {}, {} def generate_categories(): from uuid import uuid4 category_size = np.random.randint(2, max_cat_size) return [str(uuid4()) for _ in range(category_size)] for col in range(num_count): name = f'n{col}' values = np.random.normal(0, 1, n_rows) nan_cnt = np.random.randint(1, int(max_nan*n_rows)) index = np.random.choice(n_rows, nan_cnt, replace=False) values[index] = np.nan dataset[name] = values types[name] = 'float32' for col in range(cat_count): name = f'c{col}' cats = generate_categories() values = np.array(np.random.choice(cats, n_rows, replace=True), dtype=object) nan_cnt = np.random.randint(1, int(max_nan*n_rows)) index = np.random.choice(n_rows, nan_cnt, replace=False) values[index] = np.nan dataset[name] = values types[name] = 'object' return pd.DataFrame(dataset), types
现在我们以CSV文件保存和加载的性能作为基准。将五个随机生成的具有百万个观测值的数据集转储到CSV中,然后读回内存以获取平均指标。并且针对具有相同行数的20个随机生成的数据集测试了每种二进制格式。
同时使用两种方法进行对比:
- 1.将生成的分类变量保留为字符串
- 2.在执行任何I/O之前将其转换为pandas.Categorical数据类型
1.以字符串作为分类特征
下图显示了每种数据格式的平均I/O时间。这里有趣的发现是hdf的加载速度比csv更低,而其他二进制格式的性能明显更好,而feather和parquet则表现的非常好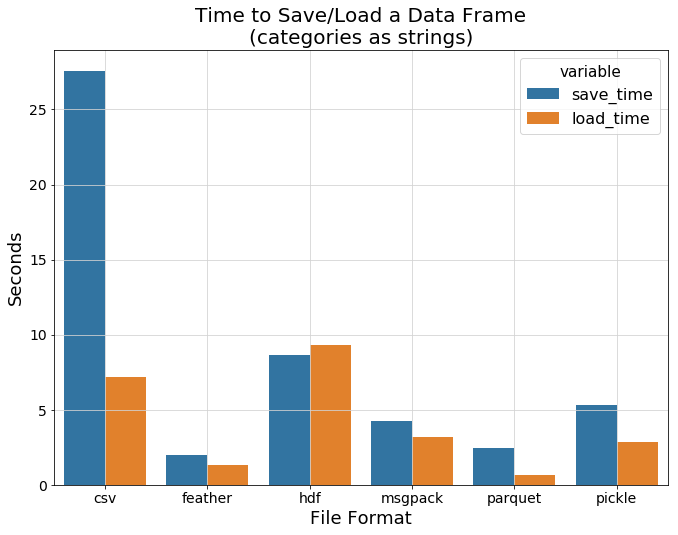
保存数据并从磁盘读取数据时的内存消耗如何?下一张图片向我们展示了hdf的性能再次不那么好。但可以肯定的是,csv不需要太多额外的内存来保存/加载纯文本字符串,而feather和parquet则非常接近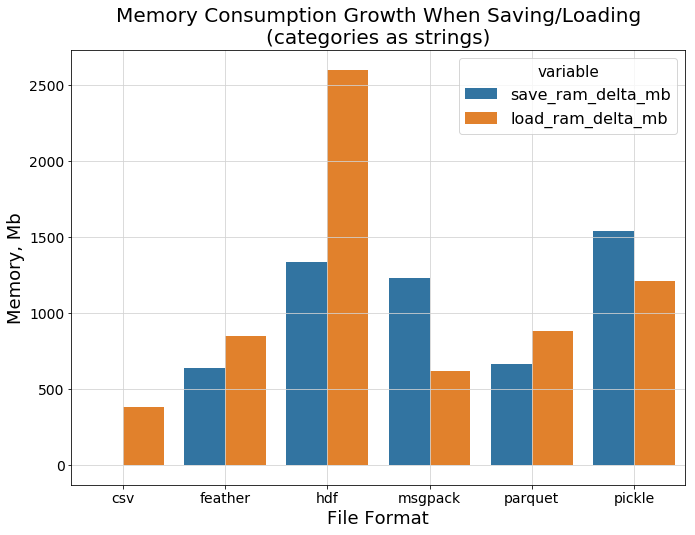
最后,让我们看一下文件大小的对比。这次parquet显示出非常好的结果,考虑到这种格式是为有效存储大量数据而开发的,也是理所当然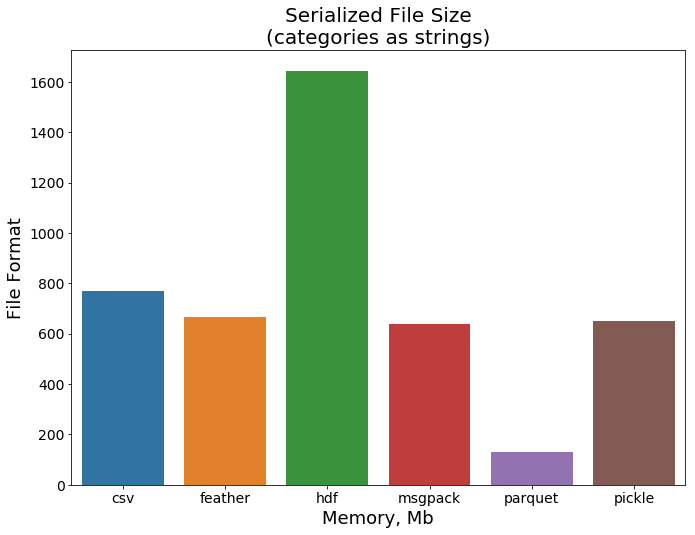
2.对特征进行转换
在上一节中,我们没有尝试有效地存储分类特征,而是使用纯字符串,接下来我们使用专用的pandas.Categorical类型再次进行比较。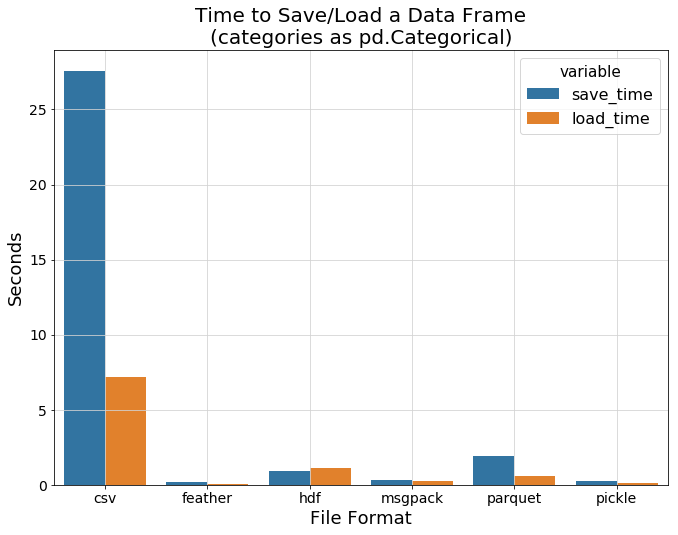
从上图可以看到,与纯文本csv相比,所有二进制格式都可以显示其真强大功能,效率远超过csv,因此我们将其删除以更清楚地看到各种二进制格式之间的差异。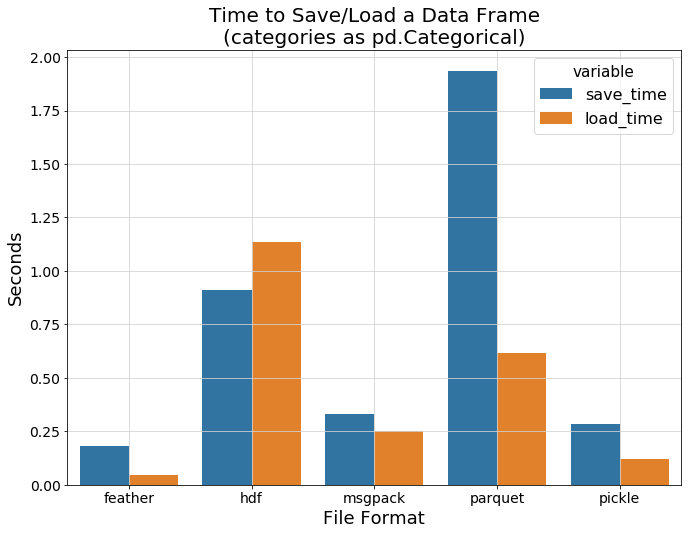
可以看到feather和pickle拥有最快的I/O速度,接下来该比较数据加载过程中的内存消耗了。下面的条形图显示了我们之前提到的有关parquet格式的情况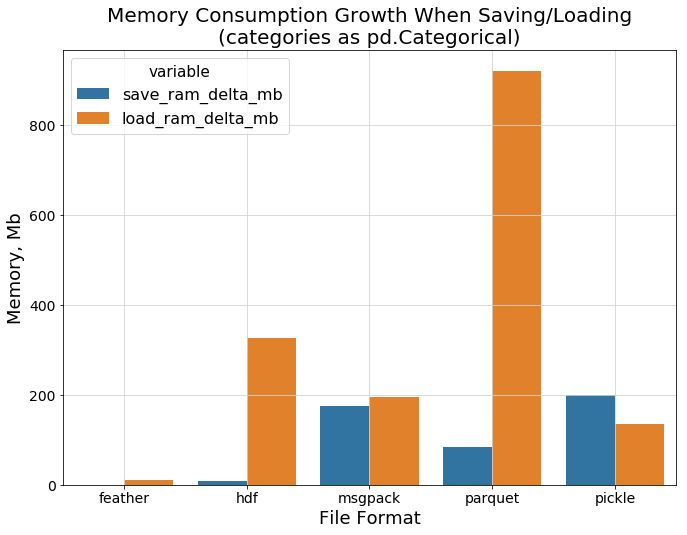
为什么parquet内存消耗这么高?因为只要在磁盘上占用一点空间,就需要额外的资源才能将数据解压缩回数据帧。即使文件在持久性存储磁盘上需要适度的容量,也可能无法将其加载到内存中。
最后我们看下不同格式的文件大小比较。所有格式都显示出良好的效果,除了hdf仍然需要比其他格式更多的空间。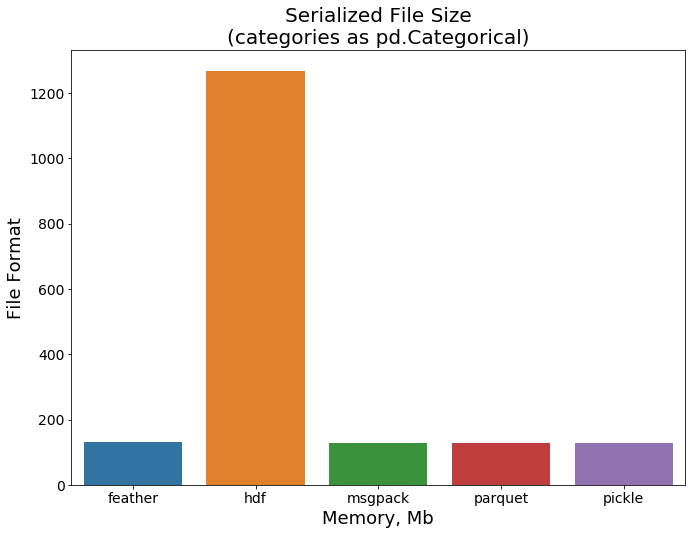
结论
正如我们的上面的测试结果所示,feather格式似乎是在多个Jupyter之间存储数据的理想选择。它显示出很高的I/O速度,不占用磁盘上过多的内存,并且在装回RAM时不需要任何拆包。
当然这种比较并不意味着我们应该在每种情况下都使用这种格式。例如,不希望将feather格式用作长期文件存储。此外,当其他格式发挥最佳效果时,它并未考虑所有可能的情况。所以我们也需要根据具体情况进行选择!
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
朋友们如果需要这份完整的资料可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具

三、入门学习视频
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









