






我们所期望的最理想的情况就是河流在到达最终目的地(最低点)之前不会停下。在机器学习中,这等价于我们已经找到了从初始点(山顶)开始行走的全局最小值(或最优值)。然而,可能由于地形原因,河流的路径中会出现很多坑洼,而这会使得河流停滞不前。在机器学习术语中,这种坑洼称为局部最优解,而这不是我们想要的结果。有很多方法可以解决局部最优问题。
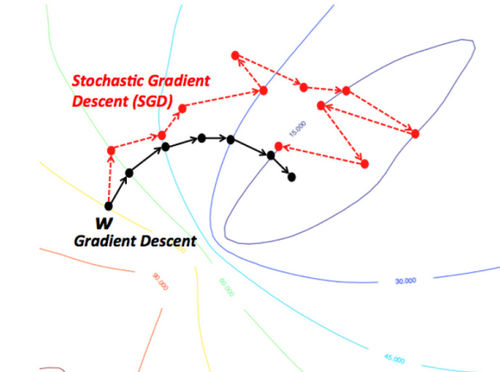
因此,由于地形(即函数性质)的限制,梯度下降算法很容易卡在局部最小值。但是,如果能够找到一个特殊的山地形状(比如碗状,术语称作凸函数),那么算法总是能够找到最优点。在进行最优化时,遇到这些特殊的地形(凸函数)自然是最好的。另外,山顶初始位置(即函数的初始值)不同,最终到达山底的路径也完全不同。同样,不同的流速(即梯度下降算法的学习速率或步长)也会导致到达目的地的方式有差异。是否会陷入或避开一个坑洼(局部最小值),都会受到这两个因素的影响。
3、学习率衰减
调整随机梯度下降优化算法的学习速率可以提升性能并减少训练时间。这被称作学习率退火或自适应学习率。训练中最简单也最常用的学习率自适应方法就是逐渐降低学习率。在训练初期使用较大的学习率,可以对学习率进行大幅调整;在训练后期,降低学习率,以一个较小的速率更新权重。这种方法在早期可以快速学习获得较好的权重,并在后期对权重进行微调。

两个流行而简单的学习率衰减方法如下:
- 线性地逐步降低学习率
- 在特定时点大幅降低学习率
4、Dropout
拥有大量参数的深度神经网络是非常强大的机器学习系统。然而,在这样的网络中,过拟合是一个很严重的问题。而且大型网络的运行速度很慢,这就使得在测试阶段通过结合多个不同的大型神经网络的预测来解决过拟合问题是很困难的。Dropout 方法可以解决这个问题。
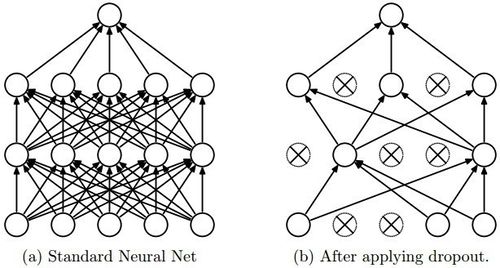
其主要思想是,在训练过程中随机地从神经网络中删除单元(以及相应的连接),这样可以防止单元间的过度适应。训练过程中,在指数级不同“稀疏度”的网络中剔除样本。在测试阶段,很容易通过使用具有较小权重的单解开网络(single untwined network),将这些稀疏网络的预测结果求平均来进行近似。这能有效地避免过拟合,并且相对于其他正则化方法能得到更大的性能提升。Dropout 技术已经被证明在计算机视觉、语音识别、文本分类和计算生物学等领域的有监督学习任务中能提升神经网络的性能,并在多个基准数据集中达到最优秀的效果。
5、最大池
最大池是一种基于样本的离散化方法。目标是对输入表征(图像、隐藏层输出矩阵等)进行下采样,降低维度并且允许对子区域中的特征进行假设。
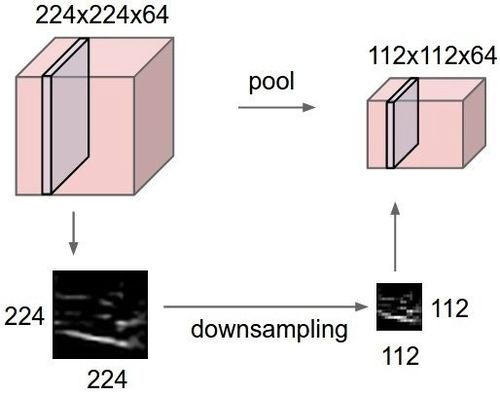
通过提供表征的抽象形式,这种方法可以在某种程度上解决过拟合问题。同样,它也通过减少学习参数的数目以及提供基本的内部表征转换不变性来减少计算量。最大池是通过将最大过滤器应用于通常不重叠的初始表征子区域来完成的。
6、批量标准化
当然,包括深度网络在内的神经网络需要仔细调整权重初始值和学习参数。批量标准化能够使这个过程更加简单。
权重问题:
无论怎么设置权重初始值,比如随机或按经验选择,初始权重和学习后的权重差别都很大。考虑一小批权重,在最初时,对于所需的特征激活可能会有很多异常值。
深度神经网络本身就具有病态性,即初始层的微小变化就会导致后一层的巨大变化。
在反向传播过程中,这些现象会导致梯度的偏移,这就意味着在学习权重以产生所需要的输出之前,梯度必须补偿异常值。而这将导致需要额外的时间才能收敛。

批量标准化将这些梯度从异常值调整为正常值,并在小批量范围内(通过标准化)使其向共同的目标收敛。
学习率问题:
通常来说,学习率都比较小,这样只有一小部分的梯度用来校正权重,因为异常激活的梯度不应该影响已经学习好的权重。
通过批量标准化,这些异常激活的可能性会被降低,就可以使用更大的学习率加速学习过程。
7、长短期记忆
长短期记忆网络(LSTM)和其他递归神经网络中的神经元有以下三个不同点:
它可以决定何时让输入进入神经元
它可以决定何时记住上一个时间步中计算的内容
它可以决定何时让输出传递到下一个时间戳 LSTM的强大之处在于它可以只基于当前的输入就决定上述所有。请看下方的图表:
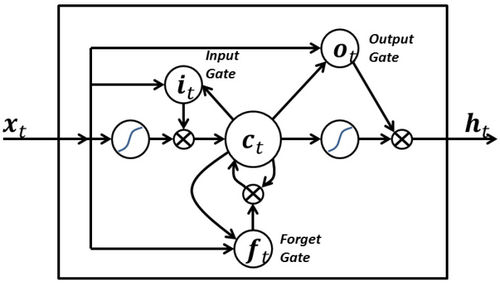
当前时间戳的输入信号 x(t) 决定了上述三点。
- 输入门(input gate)决定了第一点,
- 遗忘门(forget gate)决定了第二点,
- 输出门(output gate)决定了第三点。 只依赖输入就可以完成这三项决定。这是受到大脑工作机制的启发,大脑可以基于输入来处理突然的上下文语境切换。
8、Skip-gram
词嵌入模型的目的是针对每个词学习一个高维密集表征,其中嵌入向量之间的相似性显示了相应词语之间语义或句法的相似性。Skip-gram 是一种学习词嵌入算法的模型。 skip-gram 模型(包括很多其它词嵌入模型)背后的主要思想是:如果两个词汇项有相似的上下文,则它们是相似的。
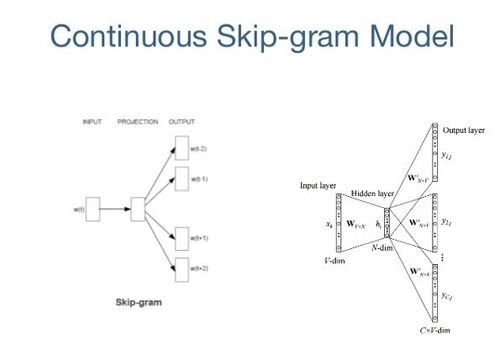
换句话说,假设有一个句子,比如“cats are mammals”,如果用“dogs”替换“cats”,该句子仍然是有意义的。因此在这个例子中,“dogs”和“cats”有相似的上下文(即“are mammals”)。
基于以上假设,我们可以考虑一个上下文窗口(包含 K 个连续项)。然后跳过其中一个词,试着学习一个可以得到除了跳过的这个词以外所有词项,并且可以预测跳过的词的神经网络。因此,如果两个词在一个大语料库中多次具有相似的上下文,那么这些词的嵌入向量将会是相似的。
9、连续词袋模型
在自然语言处理中,我们希望将文档中的每一个单词表示为一个数值向量,使得出现在相似上下文中的单词具有相似或相近的向量表示。在连续词袋模型中,我们的目标是利用一个特定单词的上下文,预测该词。

首先在一个大的语料库中抽取大量的句子,每看到一个单词,同时抽取它的上下文。然后我们将上下文单词输入到一个神经网络,并预测在这个上下文中心的单词。
当我们有成千上万个这样的上下文词汇和中心词时,我们就得到了一个神经网络数据集的实例。然后训练这个神经网络,在经过编码的隐藏层的最终输出中,我们得到了特定单词的嵌入式表达。当我们对大量的句子进行训练时也能发现,类似上下文中的单词都可以得到相似的向量。
10、迁移学习
我们来考虑一下卷积神经网络是如何处理图像的。假设有一张图像,对其应用卷积,并得到像素的组合作为输出。假设这些输出是边缘,再次应用卷积,那么现在的输出将是边缘或线的组合。然后再次应用卷积,此时的输出将是线的组合,以此类推。可以把它想象成是在每一层寻找一个特定的模式。神经网络的最后一层通常会变得非常特别。
如果基于 ImageNet 进行训练,那么神经网络的最后一层或许就是在寻找儿童、狗或者飞机之类的完整图像。再往后倒退几层,可能会看到神经网络在寻找眼睛、耳朵、嘴巴或者轮子等组成部分。
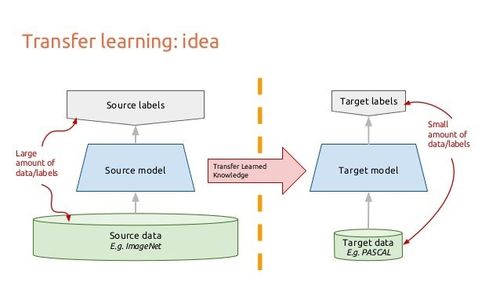
深度卷积神经网络中的每一层逐步建立起越来越高层次的特征表征,最后几层通常是专门针对输入数据。另一方面,前面的层则更为通用,主要用来在一大类图片中有找到许多简单的模式。
迁移学习就是在一个数据集上训练卷积神经网络时,去掉最后一层,在不同的数据集上重新训练模型的最后一层。直观来讲,就是重新训练模型以识别不同的高级特征。因此,训练时间会减少很多,所以在没有足够的数据或者需要太多的资源时,迁移学习是一个很有用的工具。
总结:
深度学习是非常注重技术实践,所谓的百看不如一练。当然这里讲的还是非常肤浅,如果能够引起小伙伴们对深度学习的兴趣,我就觉得很开心了。
结尾给大家推荐一个非常好的学习教程,希望对你学习Python有帮助!
Python基础入门教程推荐:更多Python视频教程-关注B站:Python学习者
【Python教程】全网最容易听懂的1000集python系统学习教程(答疑在最后四期,满满干货)
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









