






User-Agent 在网络请求中充当什么角色?
在网络请求当中,User-Agent 是标明身份的一种标识,服务器可以通过请求头参数中的 User-Agent 来判断请求方是否是浏览器、客户端程序或者其他的终端(当然,User-Agent 的值为空也是允许的,因为它不是必要参数)。
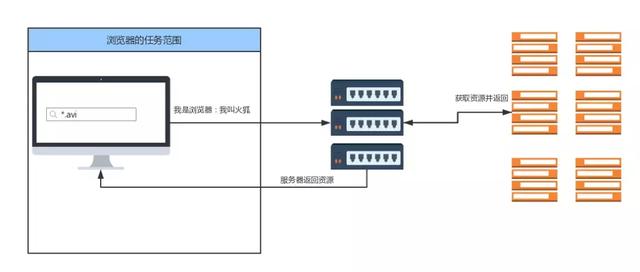
浏览器的角色,如上图方框中所示,那么 User-Agent 的角色,就是表明身份。
为什么反爬虫会选择 User-Agent 这个参数呢?
从上面的介绍中,可以看出它是终端的身份标识。意味着服务器可以清楚的知道,这一次的请求是通过火狐浏览器发起的,还是通过 IE 浏览器发起的,甚至说是否是应用程序(比如 Python )发起的。
网站的页面、动效和图片等内容的呈现是借助于浏览器的渲染功能实现的,浏览器是一个相对封闭的程序,因为它要确保数据的成功渲染,所以用户无法从浏览器中大规模的、自动化的获取内容数据。
而爬虫却不是这样的,爬虫生来就是为了获取网络上的内容并将其转化为数据。这是两种截然不同的方式,你也可以理解为通过编写代码来大规模的、自动化的获取内容数据,这是一种骚操作。

回到正题,为什么会选择 User-Agent 这个参数呢?
因为编程语言都有默认的标识,在发起网络请求的时候,这个标识在你毫不知情的情况下,作为请求头参数中的 User-Agent 值一并发送到服务器。比如 Python 语言通过代码发起网络请求时, User-Agent 的值中就包含 Python 。同样的,Java 和 PHP 这些语言也都有默认的标识。
反爬虫的黑名单策略
既然知道编程语言的这个特点,再结合实际的需求,那么反爬虫的思路就出来了。这是一中黑名单策略,只要出现在黑名单中的请求,都视为爬虫,对于此类请求可以不予处理或者返回相应的错误提示。
为什么用黑名单策略不用白名单策略?
现实生活中,浏览器类型繁多(火狐浏览器、谷歌浏览器、360 浏览器、傲游浏览器、欧普拉浏览器、世界之窗浏览器、QQ 浏览器等),
想要将所有的浏览器品牌、类型以及对应的标识收集并放到名单中,那是不实际的,假如漏掉了哪一种,那么对网站来说是一种损失。
再者说来,很多的服务并不仅仅开放给浏览器,有些时候这些服务以 API 的形式向应用程序提供服务,比如安卓软件的后端 API ,为安卓软件程序提供数据服务,而软件本身只承担界面和结构的任务,而数据则从后端 API 获取。这个时候,发起的请求中, User-Agent 就会变成 Android 。
以上就是不能使用白名单策略的原因。
而黑名单在于简单,当你希望屏蔽来自于 Python 代码的请求或者来自于 Java 代码的请求时,只需要将其加入黑名单中即可。
通过 Nginx 服务日志来查看请求头中的 User-Agent
Nginx 是一款轻量级的 Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其特点是占有内存少,并发能力强,事实上 Nginx 的并发能力确实在同类型的网页服务器中表现较好,使用 Nginx 企业有:百度、京东、新浪、网易、腾讯、淘宝等。

Nginx 的安装与启动
通常可以使用系统本身的安装工具(Centos 的 yum、Debian 系的 apt-get 以及 MacOS 的 brew)安装 Nginx,以 linux 系统为例,在终端中输入:
sudo apt-get install nginx
接下来根据提示选择,即可完成 Nginx 的安装。
接着在终端通过命令:
sudo systemctl start nginx
即可启动 Nginx 服务。
备注:由于各个系统差别以及版本差异,安装和启动命令略有差别,解决办法自行搜索
Nginx 的日志
Nginx 为用户提供了日志功能,其中记录了每次服务器被请求的状态和其他信息,包括 User-Agent。 Nginx 的默认日志存放路径为:
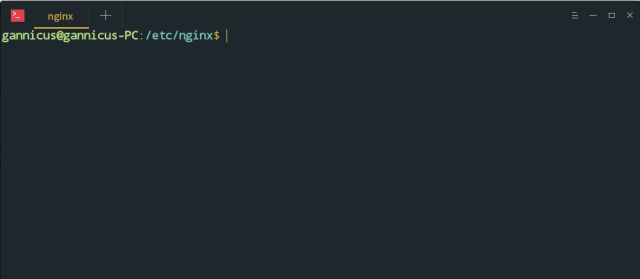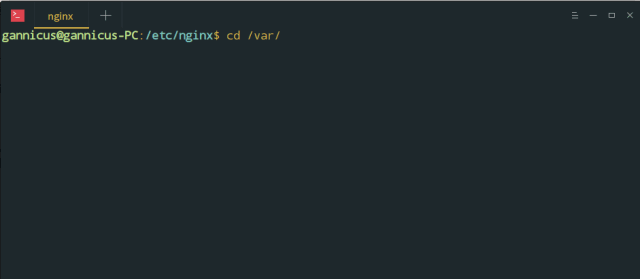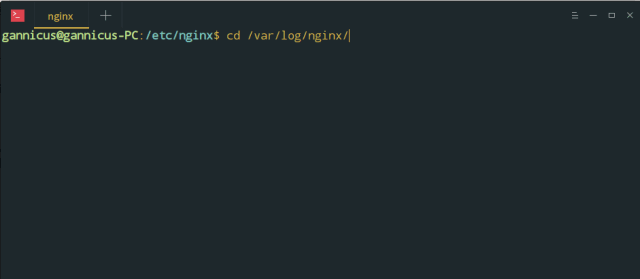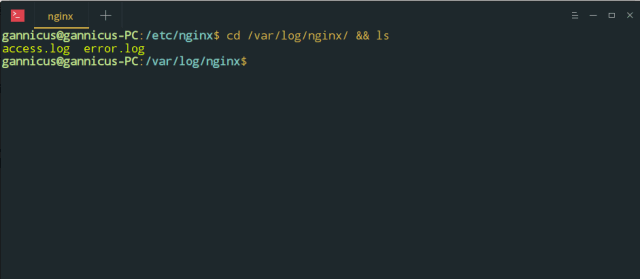
/var/log/nginx/
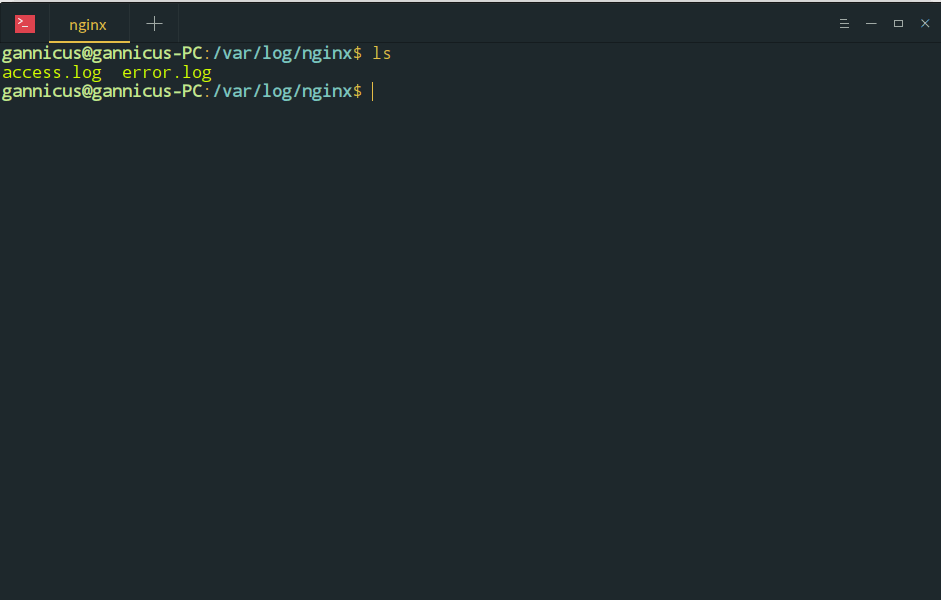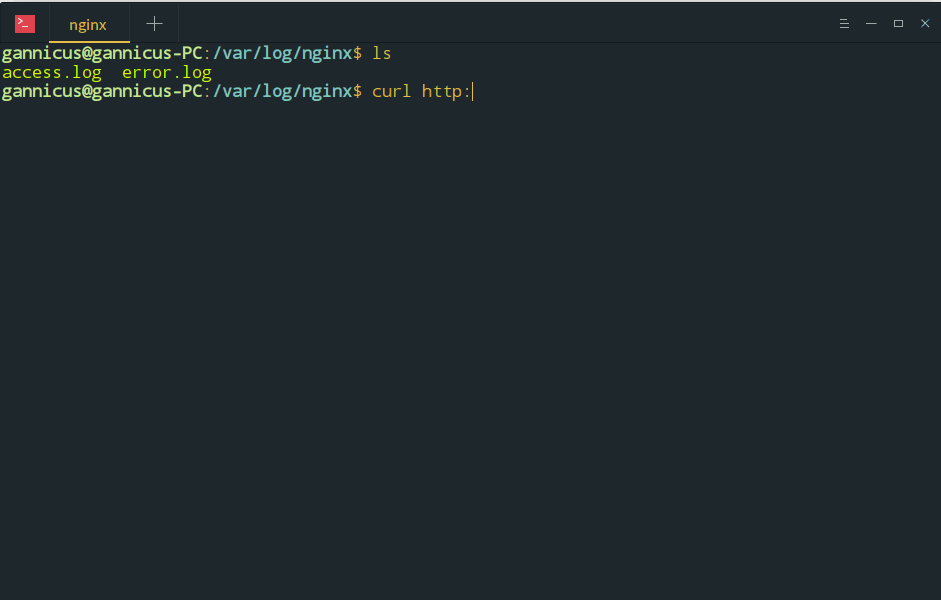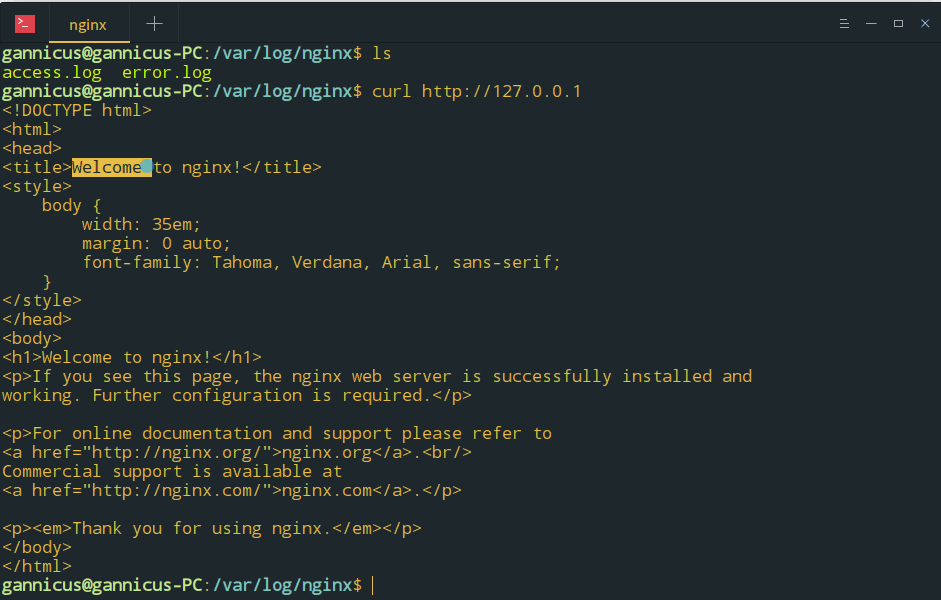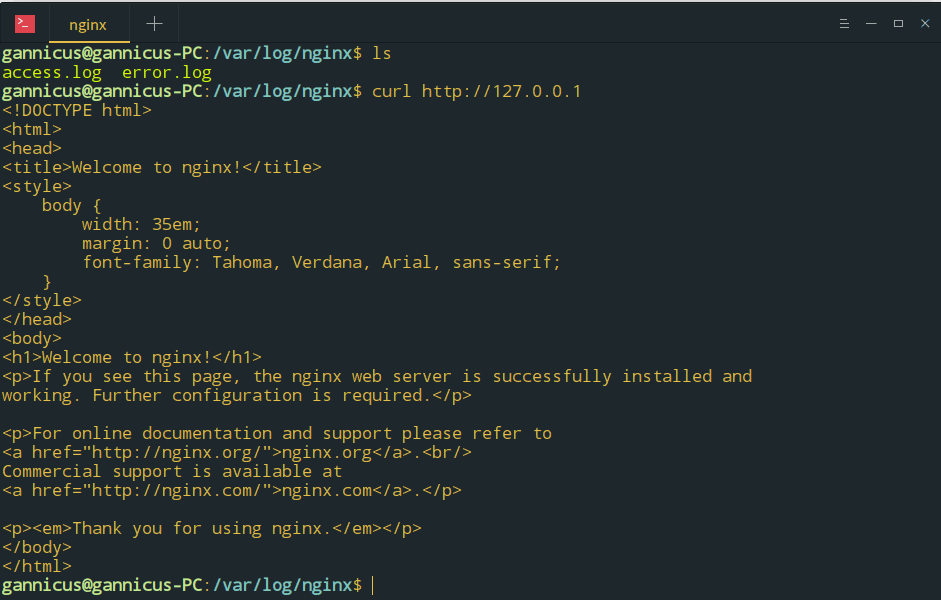
在终端通过命令
cd /var/log/nginx && ls
可以进入到日志存放目录并列出目录下的文件,可以看到其中有两个主要的文件,为 access.log 和 error.log
它们分别记录着成功的请求信息和错误信息。我们通过 Nginx 的访问日志来查看每次请求的信息。
发起请求的几种办法
浏览器
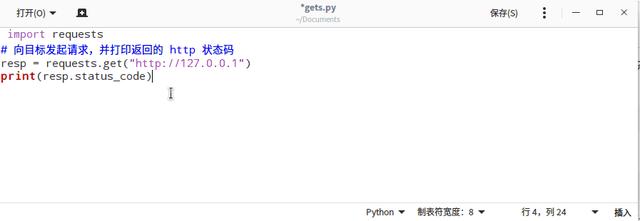
Nginx 启动后,默认监听 80 端口,你只需要访问 IP 地址或者域名即可。假设 IP 地址为 127.0.0.1,那么可以在浏览器输入:
http://127.0.0.1
回车后,浏览器就会向服务器发起请求,和你平时上网是一样的。

Postman
Postman是一款功能强大的网页调试与发送网页HTTP请求的工具(Postman下载地址),它可以模拟浏览器,访问指定的 Url 并输出返回内容,实际使用如下图所示:
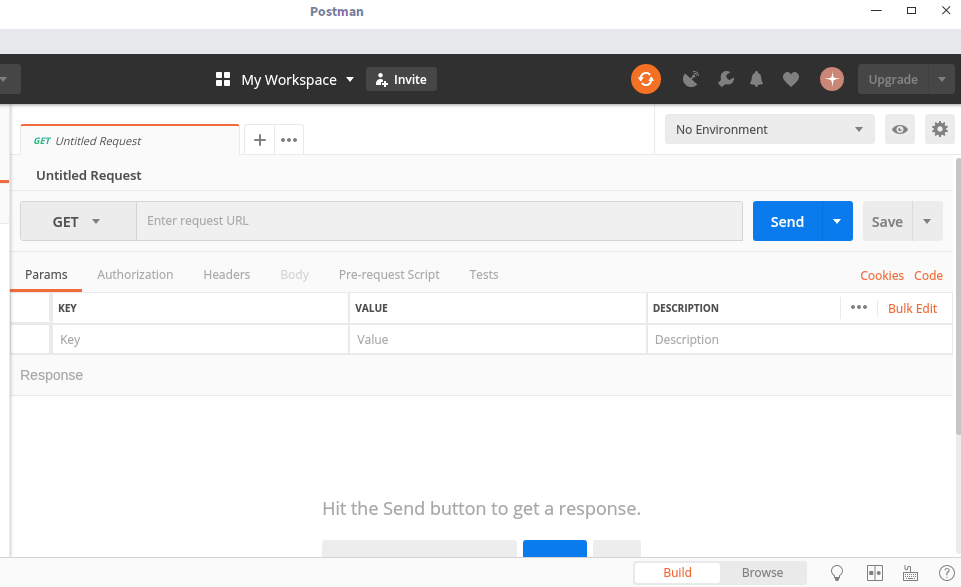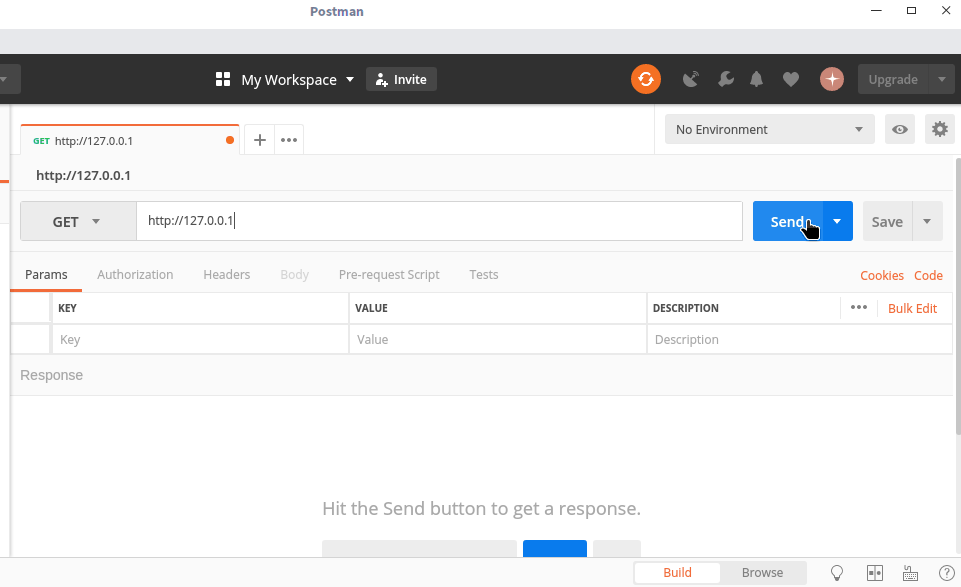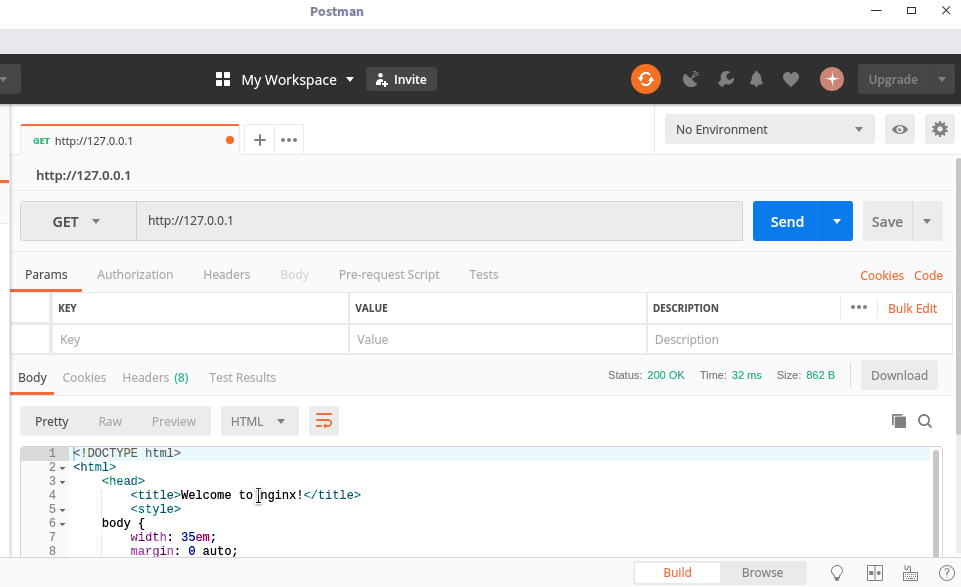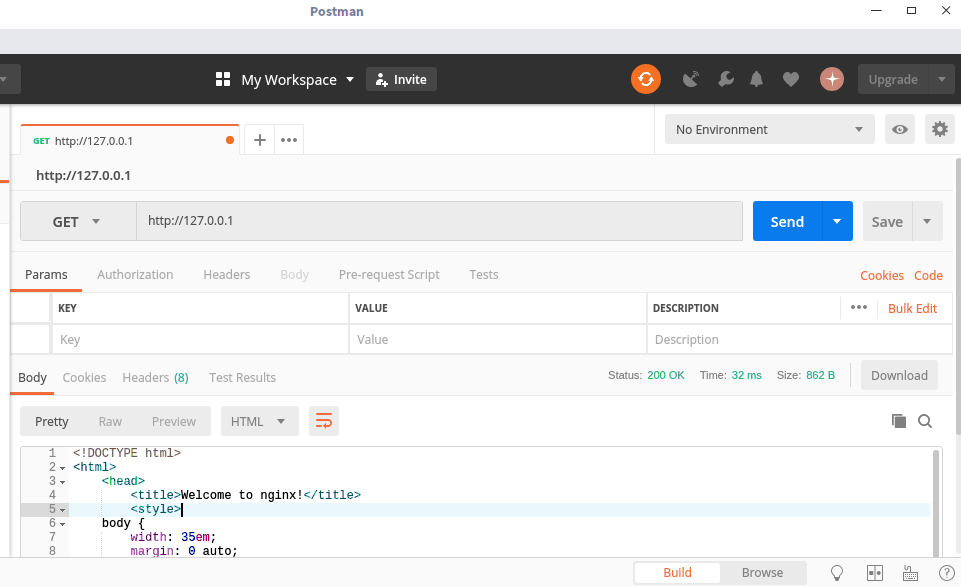
Curl
这是一个利用URL语法在命令行下工作的传输工具,它不仅支持 url 地址访问还支持文件上传和下载,所以可以称它为综合传输工具。他也可以模拟浏览器,访问指定的 Url,实际使用如下图所示:
Nginx 日志记录结果
上面使用了 4 种方法来向服务器发起请求,那么我们看看 Nginx 的日志中,记录了什么样的信息。在终端通过命令:
sudo cat access.log
来查看日志文件。可以看到这几次的请求记录:

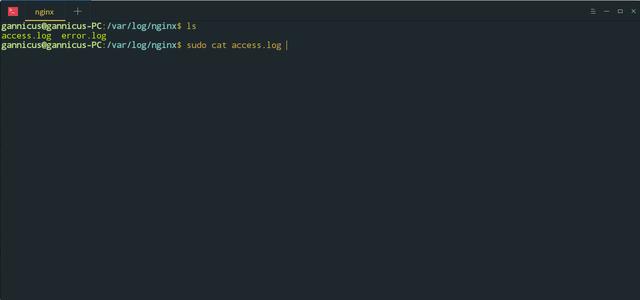
无论是 Python 还是 Curl 或者浏览器以及 Postman 的请求,都被记录在日志文件中,说明 Nginx 可以识别发起请求的终端类型。
实现反爬虫
之前的理论和逻辑,在实验中都得到了验证,那么接下来我们就通过黑名单策略将 Python 和 Curl 发起的请求过滤掉,只允许 Firefox 和 Postman 的请求通过,并且对被过滤的请求返回 403 错误提示。
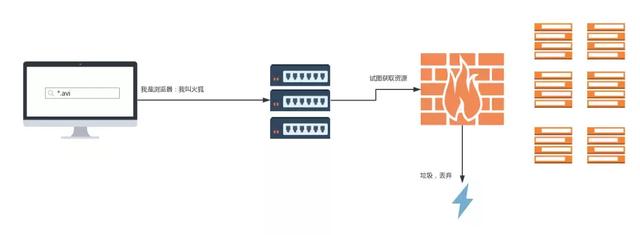
反爬虫的过程如上图所示,相当于在服务器和资源之间建立了一道防火墙,在黑名单中的请求将会被当成垃圾丢弃掉。
配置 Nginx 规则
Nginx 提供了配置文件以及对应的规则,允许我们过滤掉不允许通过的请求,本次反爬虫我们使用的就是它。Nginx 的配置文件通常放在/etc/nginx/目录下,名为nginx.conf,我们通过查看配置文件来看一看,站点的配置文件在什么地方。再通过系统自带的编辑器(笔者所用系统自带 Nano,其他系统可能自带 Vim)来编辑配置文件。在配置文件中找到站点配置文件地址(笔者所用电脑存放路径为/etc/nginx/sites-enable),再到站点配置文件中找到local级别的配置,并在其中加上一下内容:
if ($http_user_agent ~* (Python|Curl)) {
return 403;
}
这段配置的释义是判断请求中请求头字符串中是否包含有 Python或者 Curl,如果包含则直接返回 403 错误,否则返回正常的资源。完成配置后保存,再通过命令:
sudo nginx -s reload
整个操作过程如上图所示,让 Nginx 服务器重新载入配置文件,使得刚才的配置生效。
反爬虫效果测试
重复上面访问的步骤,通过浏览器、Python 代码、Postman 工具和 Curl发起请求。从返回的结果就可以看到,与刚才是有所区别的。
- 浏览器返回的是正常的页面,说明没有收到影响;
- Python 代码的状态码变成了 403,而不是之前的 200
- Postman 跟之前一样,返回了正确的内容;
- Curl 跟 Python 一样,无法正确的访问资源,因为它们发起的请求都被过滤掉了。


提示:你可以继续修改 Nginx 的配置来进行测试,最终会发现结果会跟现在的一样:只要在黑名单中,请求就会被过滤掉并且返回 403 错误。

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









