







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
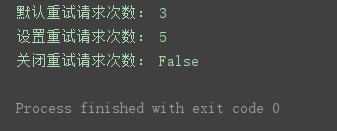
程序运行结果:
可通过info()方法获取响应头信息。
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = ‘https://www.httpbin.org/get’ # get请求测试地址
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request(‘GET’, url) # 发送GET请求,默认重试请求
response_header = r.info() # 获取响应头
for key in response_header.keys(): # 循环遍历打印响应头信息
print(key, ‘:’, response_header.get(key))

处理服务器返回的JSON信息
通过json模块的 loads() 方法将响应json数据转换为字典类型。
import urllib3 # 导入urllib3模块
import json # 导入json模块
urllib3.disable_warnings() # 关闭ssl警告
url = ‘https://www.httpbin.org/post’ # post请求测试地址
params = {‘name’: ‘Jack’, ‘country’: ‘中国’, ‘age’: 30} # 定义字典类型的请求参数
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request(‘POST’, url, fields=params) # 发送POST请求
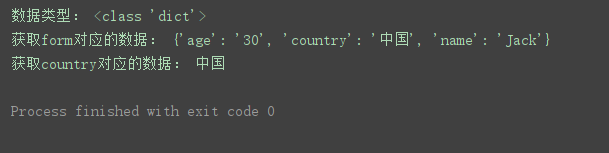
j = json.loads(r.data.decode(‘unicode_escape’)) # 将响应数据转换为字典类型
print(‘数据类型:’, type(j))
print(‘获取form对应的数据:’, j.get(‘form’))
print(‘获取country对应的数据:’, j.get(‘form’).get(‘country’))
二进制数据
如果响应数据为二进制数据,则可以使用open()函数将二进制数据转换为图片。
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = ‘http://sck.rjkflm.com:666/spider/file/python.png’ # 图片请求地址
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request(‘GET’, url) # 发送网络请求
print(r.data) # 打印二进制数据
f = open(‘python.png’, ‘wb+’) # 创建open对象
f.write(r.data) # 写入数据
f.close() # 关闭
运行结果省略。生成图片文件如下:

==============================================================================
示例如下:
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
url = ‘https://www.httpbin.org/get’ # get请求测试地址
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36’}
http = urllib3.PoolManager() # 创建连接池管理对象
r = http.request(‘GET’, url, headers=headers) # 发送GET请求
print(r.data.decode(‘utf-8’)) # 打印返回内容
超时的参数与时间可以写在request()方法中,也可以写在PoolManager()实例对象中。
示例:
import urllib3 # 导入urllib3模块
urllib3.disable_warnings() # 关闭ssl警告
baidu_url = ‘https://www.baidu.com/’ # 百度 超时请求测试地址
python_url = ‘https://www.python.org/’ # Python 超时请求测试地址
http = urllib3.PoolManager() # 创建连接池管理对象
try:
r = http.request(‘GET’, baidu_url, timeout=0.01) # 发送GET请求,并设置超时时间为0.01秒
except Exception as error:
print(‘百度超时:’, error)
http2 = urllib3.PoolManager(timeout=0.1) # 创建连接池管理对象,并设置超时时间为0.1秒
try:
r = http2.request(‘GET’, python_url) # 发送GET请求
except Exception as error:
print(‘Python超时:’, error)

如果需要更精准,则可以使用 Timeout 实例对象设置连接超时与读取超时。
示例代码:
import urllib3
from urllib3 import Timeout
urllib3.disable_warnings()
timeout = Timeout(connect=0.5, read=0.1)
http = urllib3.PoolManager(timeout=timeout)
http.request(‘GET’, “https://www.python.org/”)
或者
import urllib3
from urllib3 import Timeout
urllib3.disable_warnings()
timeout = Timeout(connect=0.5, read=0.1)
http = urllib3.PoolManager()
http.request(‘GET’, “https://www.python.org/”, timeout=timeout)
设置代理IP需要创建ProxyManager对象,该对象需要有两个参数;proxy_url表示需要使用的代理IP,headers即请求头。
import urllib3 # 导入urllib3模块
url = “http://httpbin.org/ip” # 代理IP请求测试地址
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36’
}
创建代理管理对象
proxy = urllib3.ProxyManager(‘xxxxxxxxxxxx’, headers=headers)
r = proxy.request(‘get’, url, timeout=2.0) # 发送请求
print(r.data.decode()) # 打印返回结果
(代理IP自行设置)
============================================================================
request()方法提供了两种比较常用的文件上传方式:
①一种是通过fields参数以元组的形式分别指定文件名、文件内容以及文件类型
②另一种指定body参数,该参数对应值为图片的二进制数据,然后还需要headers参数指定文件类型
- 上传文本文件
创建一个test.txt文件放在相同目录下进行测试。
import urllib3 # 导入urllib3模块
import json # 导入json模块
with open(‘test.txt’) as f: # 打开文本文件
data = f.read() # 读取文件
http = urllib3.PoolManager() # 创建连接池管理对象
发送网络请求
r = http.request(‘POST’, ‘http://httpbin.org/post’, fields={‘filefield’: (‘example.txt’, data),})
files = json.loads(r.data.decode(‘utf-8’))[‘files’] # 获取上传文件内容
print(files)
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
。
成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-8m5d0KRi-1713370582705)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









