







前言:链式表可以比较锻炼一个人的逻辑能力
目录
一、链式表简介
将线性表L=(a0,a1,……,an-1)中各元素分布在存储器的不同存储块,称为结点。通过地址或指针建立元素之间的联系。结点的data域存放数据元素ai,而next域是一个指针,指向ai的直接后继ai+1所在的结点。最后一个节点指针指向NULL。
| data | next |
优点,对于内存的使用要求没有顺序表那么高,对于插入删除等操作只需要改一下指针,效率也高一些。
二、链式表存储结构
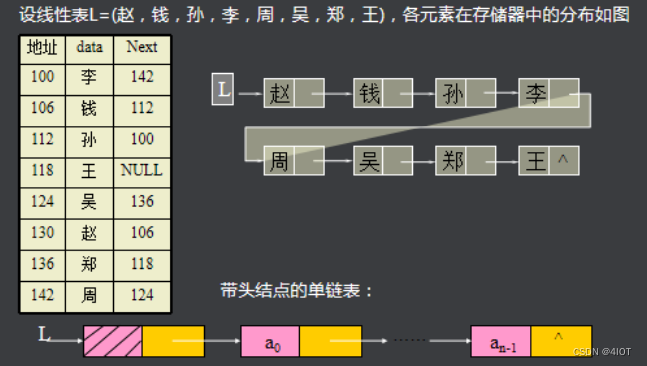
通过观察,链式表的头节点很难找,一般都会设置一个指定的头结点。
三、链式表的算法实现
1、结点类型描述:
typedef int data_t
typedef struct node
{
data_t data; //结点的数据域//
struct node *next; //结点的后继指针域//
}listnode, *linklist;
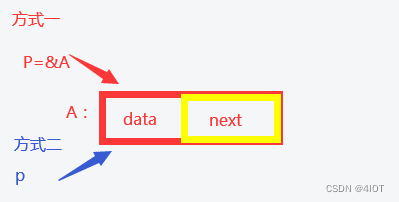
这种数据机构也需要分配内存,分配内存有两种定义方式
(1)定义在栈上
//方式一
listnode A; //typedef struct node listnode是个别名
linklist p = &A;
(2)定义在堆上,程序员可以自己控制,什么时候需要就插入,不需要不增加。通过动态内存方式,这种更实用。可调用C语言中malloc()函数向系统申请结点的存储空间。
//方式二
linklist p;
p = (linklist)malloc(sizeof(listnode));我们用图来描述一下:创建一个类型为linklist的结点,且该结点的地址已存入指针变量p中:
设P指向链表中节点ai
获取Ai,写作:p->data;
而取Ai+1,写作:p->next->data
若指针p的值为NULL,则它不指向任何节点,此时取p->data或p->next是错误的。段错误一般是指针越界访问,或者内存越界访问的错误。
2、基本运算的相关算法
思路:一般编程会写4个文件
- linklist.h //数据结构定义,运算
- linklist.c // 运算的实现
- test.c //根据应用提供接口
- makefile //因为gcc 编译每次需要敲很多命令,通过make可以更便捷,需要了解可参考
-------------->makefile管理工具
这样布局的好处:
- 结构清晰
- 软件复用(给自己用,给同事,外包,包括.h和.o文件,源码自己保留)
先把linklist.h完成,定义节点的结构体,把函数的名称、参数、返回值定义好,根据功能一步步实现算法。
typedef int data_t;
typedef struct node
{
data_t data;
struct node *next;
}listnode,*linklist;
linklist list_create();
int list_locate(linklist H,data_t value);
int list_search_pos(linklist H,data_t value);
linklist list_get(linklist H,int pos);
int list_tail_insert(linklist H,data_t value);
int list_show(linklist H);
int list_insert(linklist H,data_t value,int pos);
int list_delete(linklist H,int pos);
linklist list_free(linklist H);
int list_sort(linklist H);
int list_reverse(linklist H);
linklist list_largest_neighbor_node(linklist H);
linklist list_adjmax(linklist H, data_t *value);
int list_merge(linklist H1, linklist H2);举例分析
设L={2,4,8,-1),则建表过程如下:

链表的结构是动态形成的,即算法运行钱,表结构是不存在的。
(1)建立单链表思路过程:
依次读入表L=(a0,.....,an-1)中每一元素ai(假设为整型),若ai≠结束符(-1),则为ai创建一结点,然后插入表尾,最后返回链表的头结点指针H。
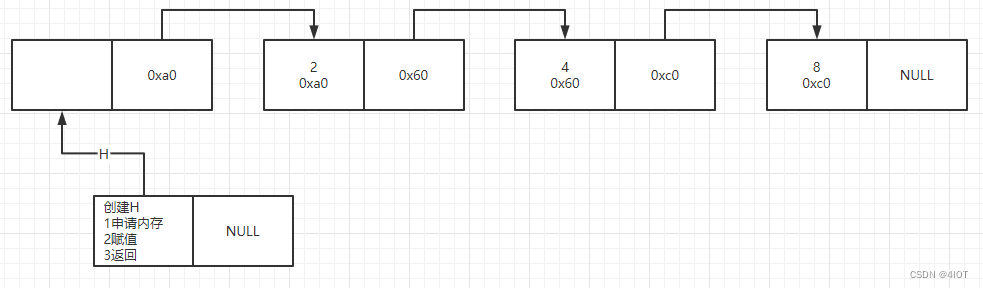
linklist list_create(){
//1.malloc
linklist H;
H =(linklist) malloc(sizeof(listnode));
if( H == NULL)
{
printf("malloc failed");
return H;
}
//2.assignment
H->data = 0;
H->next = NULL;
//3.return
return H;
}
(2)尾部插入
尾部插入,头部插入等等往往都是找到要插入节点的前一个位置。
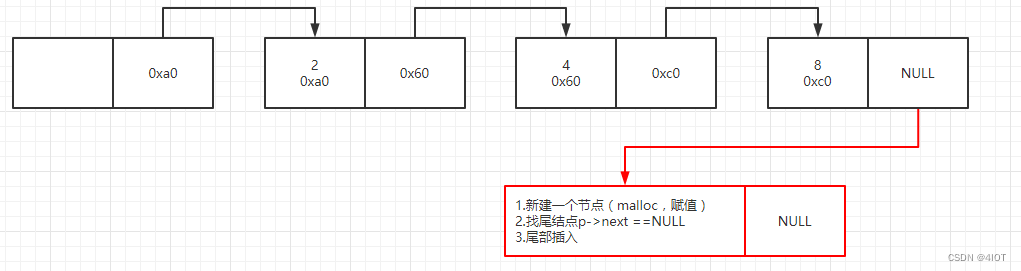
int list_tail_insert(linklist H,data_t value){
linklist p;
linklist q;
if(H == NULL){
printf("H is NULL");
return -1;
}
//1.new node p malloc
if((p = (linklist)malloc(sizeof(listnode))) == NULL)
{
printf("malloc failed");
return -1;
}
p->next = NULL;
p->data = value;
//2,if H == NULL ,q->next = NULL.locate tail node
q = H;
while(q->next != NULL)
{
q = q->next;
}
q->next = p;
return 0;
}(3)链表遍历
头节点开始,指针++直到为NULL,完成遍历。
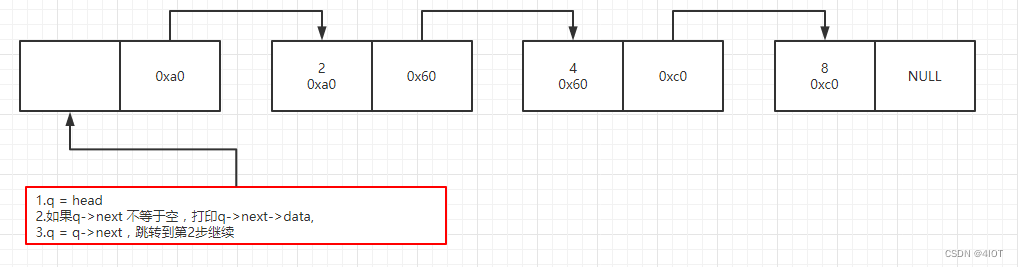
int list_show(linklist H){
linklist q = H;
while( (q->next) != NULL){
printf("%d ",q->next->data);
q = q->next;
}
puts("");
return 1;
}
(4)按位置插入
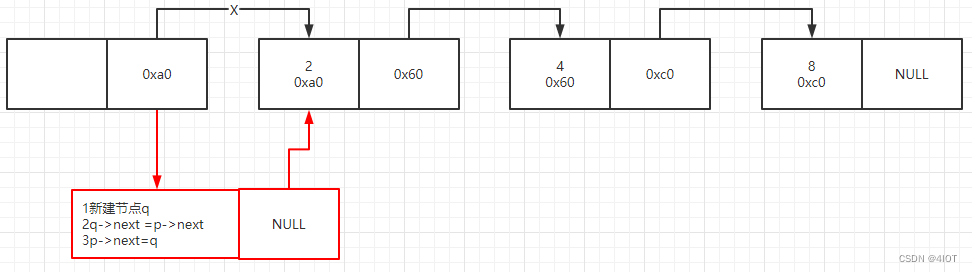
int list_insert(linklist H, data_t value, int pos){
linklist p,q;
p = H;
//1.malloc
q = (linklist)malloc(sizeof(listnode));
q->data = value;
//2.chech parameter
int i = -1;
if(H == NULL)
{
printf("linklist is NULL\n");
return 0;
}
if(pos<-1)
{
printf("pos is out of range\n");
return 0;
}
//3.find pos and insert
while(H->next != NULL)
{
if(i == pos-1 )
{
break;
}
else
{
i++;
H = H->next;
}
}
if(H->next == NULL)
{
printf("pos is out of range\n");
return -1;
}
else
{
q->next = H->next;
H->next = q;
return 1;
}
}(5)链表按编号查找
头结点编号为-1,按序号循环找
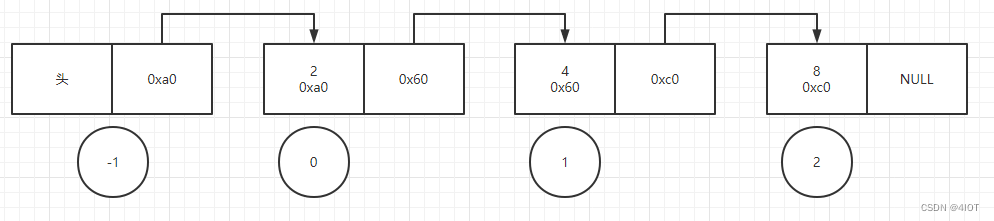
linklist list_get(linklist H,int pos){
linklist p;
int i;
if(H == NULL){
printf("H is NULL");
return NULL;
}
if(pos == -1){
return H;
}
if(pos < -1){
printf("pos is invalid\n");
return NULL;
}
p = H;
i = -1;
while(i < pos){
p = p->next;
if(p == NULL){
printf("pos is invalid\n");
return NULL;
}
i++;
}
return p;
}(6)链表按值查找
同上
int list_locate(linklist H,data_t value){
linklist p;
p = H;
int pos = -1;
if(H == NULL){
printf("H is NULL");
return 0;
}
while(p->next != NULL){
if(p->data == value){
break;
}
pos++;
p = p->next;
}
if(p->next == NULL){
printf("not find;");
return -1;
}
return pos ;
}(7)链表删除

int list_delete(linklist H,int pos){
linklist p,q;
//1.check
if(H == NULL)
{
printf("linklist is NULL\n");
return -1;
}
//2.find pos and delete
p = list_get(H, pos -1);
if( p == NULL){
printf("delete pos is invalid\n");
return -1;
}
//3.delete
q = p->next;
p->next = q->next;
//4.free
printf("free:%d\n",q->data);
free(q);
q = NULL;
return 0 ;
}(8)链表释放
linklist list_free(linklist H) {
linklist p;
if (H == NULL)
return NULL;
p = H;
printf("free:");
while (H != NULL) {
p = H;
printf("%d ", p->data);
free(p);
H = H->next;
}
puts("");
return NULL;
}(9)链表的反转或倒置
算法思路:依次取原链表中各结点,将其作为新链表首结点插入H结点之后
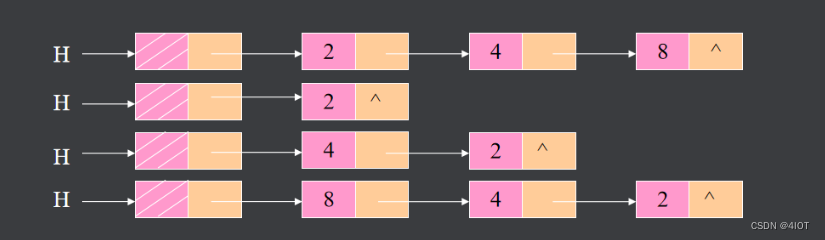
int list_reverse(linklist H) {
linklist p;
linklist q;
if (H == NULL) {
printf("H is NULL\n");
return -1;
}
if (H->next == NULL || H->next->next == NULL) {
return 0;
}
p = H->next->next;
H->next->next = NULL;
while (p != NULL) {
q = p;
p = p->next;
q->next = H->next;
H->next = q;
}
return 0;
}(10)链表的排序
算法思路:最通用的冒泡排序,还有其他很多效率更高的算法可以自己尝试。
int list_sort(linklist H){
//check
if (H == NULL)
{
printf("list is NULL\n");
return 0;
}
if (H->next ==NULL)
{
printf("list has no parameter");
return 1;
}
//sort
linklist p1 = H;//
linklist p2;
int temp;
while(p1->next !=NULL){
p2 = p1->next;
while( p2 != NULL)
{
if(p1->data > p2->data)
{
//
temp = p1->data;
p1->data = p2->data;
p2->data = temp;
//move p1 p2
}
p2 = p2->next;
}
p1 = p1->next;
}
return 1;
}(11)相邻节点最大的第一个节点的指针
设结点data域为整型,求链表中相邻两结点data值之和为最大的第一结点的指针。
算法思路:设p,q分别为链表中相邻两结点指针,求p->data+q->data为最大的那一组值,返回其相应的指针p即可。
linklist list_adjmax(linklist H, data_t *value) {
linklist p, q, r;
data_t sum;
if (H == NULL){
printf("H is NULL\n");
return NULL;
}
if (H->next == NULL || H->next->next == NULL || H->next->next->next == NULL) {
return H;
}
q = H->next;
p = H->next->next;//p = q->next;
r = q;
sum = q->data + p->data;
while (p->next != NULL) {
p = p->next;
q = q->next;
if (sum < q->data + p->data) {
sum = q->data + p->data;
r = q;
}
}
*value = sum;
return r;
}(12)2个递增有序的链表合并,A也递增有序
设两单链表A、B按data值(设为整型)递增有序,将表A和B合并成一表A,且表A也按data值递增有序。
算法思路∶设指针p、q分别指向表A和B中的结点,若p->data sq->data则p结点进入结果表,否则q结点进入结果表。
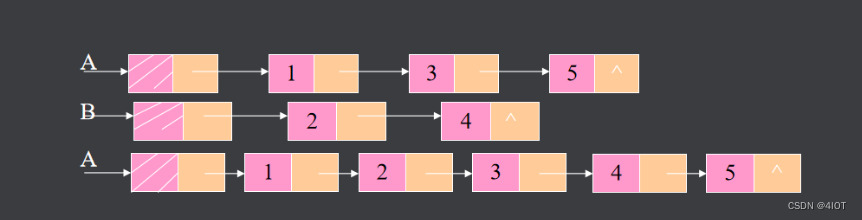
int list_merge(linklist H1, linklist H2) {
linklist p, q, r;
if (H1 == NULL || H2 == NULL) {
printf("H1 || H2 is NULL\n");
return -1;
}
p = H1->next;
q = H2->next;
r = H1;
H1->next = NULL;
H2->next = NULL;
while (p && q) {
if (p->data <= q->data) {
r->next = p;
p = p->next;
r = r->next;
r->next = NULL;
} else {
r ->next = q;
q = q->next;
r = r->next;
r->next = NULL;
}
}
if (p == NULL) {
r->next = q;
}else {
r->next = p;
}
return 0;
}
上面的功能需要自己完成一下,还有很多功能可以自己探索:去重等。
总结
单链表优点
- 任意位置插入删除时间复杂度为O(1)。
- 没有增容问题,插入一个开辟一个空间。
单链表缺点:
- 以节点为单位存储,不支持随机访问。


















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











