







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
本次选题是先写好代码再写的文章,绝对可以用到页面元素解析,并且还需要对网站的数据加载有一定的分析,才能得到最终的数据,并且小编找的这两个数据源无 ip 访问限制,质量有保证,绝对是小白练手的绝佳之选。
郑重声明: 本文仅用于学习等目的。
首先要爬取股票数据,肯定要先知道有哪些股票吧,这里小编找到了一个网站,这个网站上有股票的编码列表:https://hq.gucheng.com/gpdmylb.html 。

打开 Chrome 的开发者模式,将股票代码一个一个选出来吧。具体过程小编就不贴了,各位同学自行实现。
我们可以将所有的股票代码存放在一个列表中,剩下的就是找一个网站,循环的去将每一只股票的数据取出来咯。
这个网站小编已经找好了,是同花顺,链接: http://stockpage.10jqka.com.cn/000001/ 。
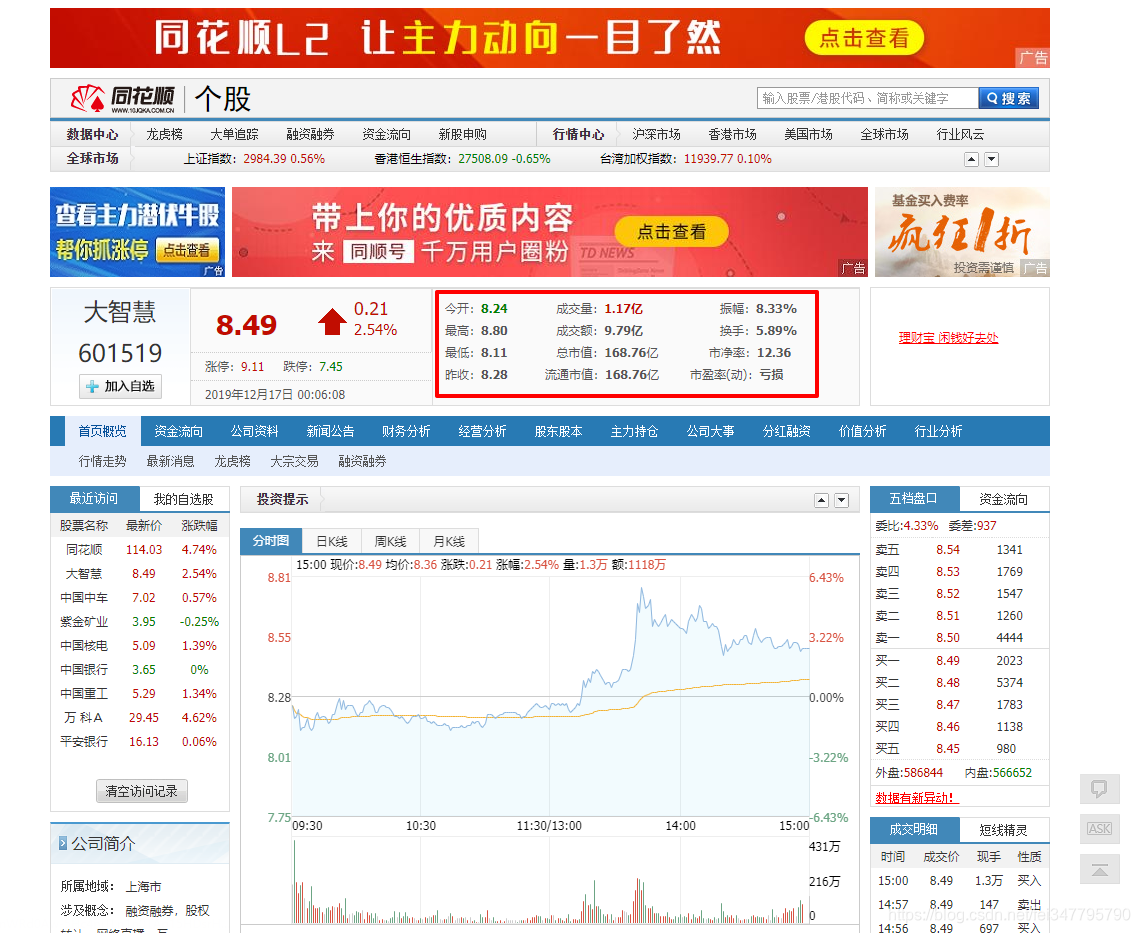
想必各位聪明的同学已经发现了,这个链接中的 000001 就是股票代码。
我们接下来只需要拼接这个链接,就能源源不断的获取到我们想要的数据。
首先,还是先介绍一下本次实战用到的请求库和解析库为: Requests 和 pyquery 。数据存储最后还是落地在 Mysql 。
获取股票代码列表
第一步当然是先构建股票代码列表咯,我们先定义一个方法:
def get_stock_list(stockListURL):
r =requests.get(stockListURL, headers = headers)
doc = PyQuery(r.text)
list = []
获取所有 section 中 a 节点,并进行迭代
for i in doc(‘.stockTable a’).items():
try:
href = i.attr.href
list.append(re.findall(r"\d{6}", href)[0])
except:
continue
list = [item.lower() for item in list] # 将爬取信息转换小写
return list
将上面的链接当做参数传入,大家可以自己运行下看下结果,小编这里就不贴结果了,有点长。。。
详情的数据看起来好像是在页面上的,但是,实际上并不在,实际最终获取数据的地方并不是页面,而是一个数据接口。
http://qd.10jqka.com.cn/quote.php?cate=real&type=stock&callback=showStockDate&return=json&code=000001
至于是怎么找出来,小编这次就不说,还是希望各位想学爬虫的同学能自己动动手,去寻找一下,多找几次,自然就摸到门路了。
现在数据接口有了,我们先看下返回的数据吧:
showStockDate({“info”:{“000001”:{“name”:“\u5e73\u5b89\u94f6\u884c”}},“data”:{“000001”:{“10”:“16.13”,“8”:“16.14”,“9”:“15.87”,“13”:“78795234.00”,“19”:“1262802470.00”,“7”:“16.12”,“15”:“40225508.00”,“14”:“37528826.00”,“69”:“17.73”,“70”:“14.51”,“12”:“5”,“17”:“945400.00”,“264648”:“0.010”,“199112”:“0.062”,“1968584”:“0.406”,“2034120”:“9.939”,“1378761”:“16.026”,“526792”:“1.675”,“395720”:“-948073.000”,“461256”:“-39.763”,“3475914”:“313014790000.000”,“1771976”:“1.100”,“6”:“16.12”,“11”:“”}}})
很明显,这个结果并不是标准的 json 数据,但这个是 JSONP 返回的标准格式的数据,这里我们先处理下头尾,将它变成一个标准的 json 数据,再对照这页面的数据进行解析,最后将分析好的值写入数据库中。
def getStockInfo(list, stockInfoURL):
count = 0
for stock in list:
try:
url = stockInfoURL + stock
r = requests.get(url, headers=headers)
将获取到的数据封装进字典
dict1 = json.loads(r.text[14: int(len(r.text)) - 1])
print(dict1)
获取字典中的数据构建写入数据模版
insert_data = {
“code”: stock,
“name”: dict1[‘info’][stock][‘name’],
“jinkai”: dict1[‘data’][stock][‘7’],
“chengjiaoliang”: dict1[‘data’][stock][‘13’],
“zhenfu”: dict1[‘data’][stock][‘526792’],
“zuigao”: dict1[‘data’][stock][‘8’],
“chengjiaoe”: dict1[‘data’][stock][‘19’],
“huanshou”: dict1[‘data’][stock][‘1968584’],
“zuidi”: dict1[‘data’][stock][‘9’],
“zuoshou”: dict1[‘data’][stock][‘6’],
“liutongshizhi”: dict1[‘data’][stock][‘3475914’]
}
cursor.execute(sql_insert, insert_data)
conn.commit()
print(stock, ‘:写入完成’)
except:
print(‘写入异常’)
遇到错误继续循环
continue
这里我们加入异常处理,因为本次爬取的数据有些多,很有可能由于某些原因抛出异常,我们当然不希望有异常的时候中断数据抓取,所以这里添加异常处理继续抓取数据。
我们将代码稍作封装,完成本次的实战。
import requests
import re
import json
from pyquery import PyQuery
import pymysql
数据库连接
def connect():
conn = pymysql.connect(host=‘localhost’,
port=3306,
user=‘root’,
password=‘password’,
database=‘test’,
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
c4b6713f686ddd3fe5aff.png)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-fIpLkiZI-1713372238507)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1060
1060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









